
1. 서론
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Hadoop의 경우 하둡 완벽 가이드 책을 많이 참고하여 운영을 하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. HDFS 란?
HDFS(Hadoop Distributed File System)는 말 뜻 그대로 Hadoop 분산 파일 시스템입니다.
아래는 Apache Hadoop 공식 문서에서 설명하는 HDFS 입니다.
" The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets.... "
HDFS는 어플라이언스 와는 다르게 범용 서버들에 JVM이 동작한다면 Hadoop을 설치 구동할 수 있어
저렴한 비용으로 확장시킬 수 있는 분산 파일 시스템입니다.
3. HDFS 구조
HDFS 는 NameNode, DataNode 들로 클러스터를 이룹니다.
아래는 HDFS 아키텍처에 관련된 이미지 입니다.
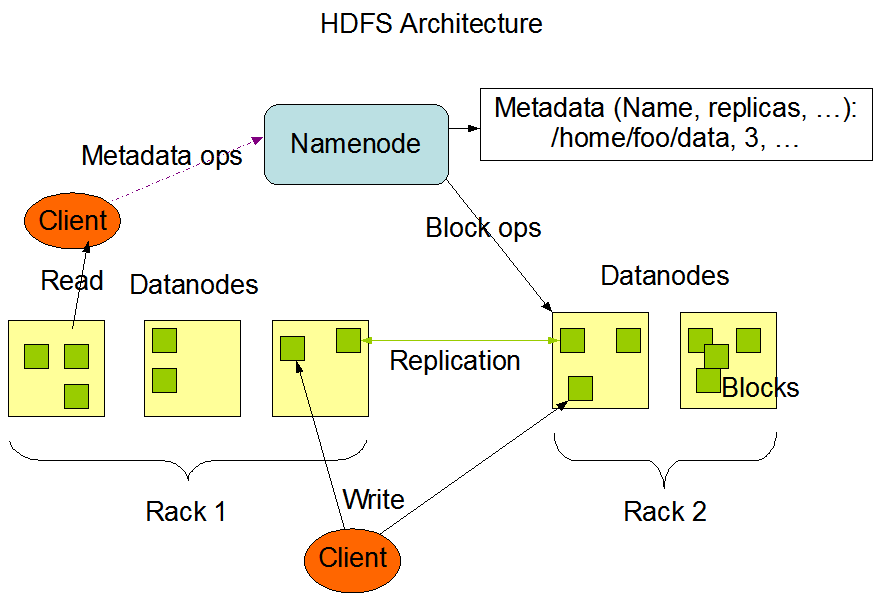
해당 아키텍처에서 주요 부분들을 설명드리겠습니다.
1. NameNode
HDFS의 NameNode는 파일시스템의 네임스페이스를 관리합니다.
즉 파일과 디렉터리에 대한 메타데이터를 보관합니다.
그렇기 때문에 NameNode 가 죽으면 Hadoop 서비스 전체에 영향이 미치므로 상당히 장애 복구에 신경을 써야 합니다.
NameNode는 모든 변경사항(파일 삭제/생성, 디렉터리 삭제/생성 등)이 발생하면 edit log라는 파일(disk)에 가장 먼저 작성을 하고 메모리에 반영을 합니다.
그리고 일정량이 edit log에 쌓이게 되면 fsimage 라는 형태의 스냅샷에 병합하게 됩니다.
NameNode는 메타데이터 정보를 메모리에 올려놓기 때문에 파일 개수가 많아지게 된다면 메모리 사이즈에 가장 먼저 영향을 미칩니다.
이 때 발생하는 메모리 사이즈 문제는 HDFS Federation을 통해 해결할 수도 있습니다.
2. Secondary NameNode
보조 네임노드라고 부르며 NameNode의 역할을 하는 것이 아닙니다. NameNode의 edit log가 일정량 차게 되면 Secondary NameNode는 fsimage로 병합하는 역할을 합니다. 보통 NameNode HA (Active - Standby)구성을 하게 되는데 이 때 Standby NameNode가 Secondary NameNode 역할을 함께 합니다.
3. DataNode
DataNode는 NameNode 의 요청이 있을 때 데이터 블록을 저장 & 검색하고 주기적으로 NameNode에 보고 합니다.
4. Data Replication
HDFS는 여러 노드에 한 파일을 여러 개로 분산 저장할 수 있기 때문에 별도의 백업 정책을 요하지는 않습니다.
그렇기에 DataNode의 Disk 는 RAID 구성을 하지 않고 포맷은 JBOD 를 권장합니다.
그러나 반대로 NameNode는 장애 시 Hadoop 전체 서비스에 영향을 미치기 때문에 RAID 구성을 권장합니다.
4. HDFS 구성
HDFS 를 구성하기 전에 아래 설치 과정이 필요합니다.
JDK 설치
반드시 java-version-openjdk 가 아닌 java-version-openjdk-devel 을 설치해주세요. jps 명령어가 듣지 않습니다.
Hadoop 설치
설치 이후 HDFS를 잘 동작시키기 위해 xml 수정을 통해 configuration 을 진행해줘야 합니다.
이번에 운영중인 하둡 버전 교체 작업을 진행하면서 세팅한 값들을 공유 드립니다.
더 괜찮은 세팅이 있으면 댓글로 공유 주시면 더 좋을 듯 합니다.
1. core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://culsterName</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>Zookeeper1:2181,Zookeeper2:2181,Zookeeper3:2181</value>
</property>
<property>
<name>hadoop.proxyuser.user1.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.user1.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.user2.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.user2.groups</name>
<value>*</value>
</property>
</configuration>2. hdfs-site.xml
<configuration>
<property>
<name>dfs.client.failover.proxy.provider.clusterName</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data01/dfs/dn,/data02/dfs/dn,/data03/dfs/dn,/data04/dfs/dn,/data05/dfs/dn,/data06/dfs/dn</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/hadoop/jn</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>clusterName</value>
</property>
<property>
<name>dfs.ha.namenodes.clusterName</name>
<value>namenode148,namenode192</value>
</property>
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.namenode.rpc-address.clusterName.namenode148</name>
<value>{내부 IP}:8020</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.clusterName.namenode148</name>
<value>{내부 IP}:8022</value>
</property>
<property>
<name>dfs.namenode.http-address.clusterName.namenode148</name>
<value>0.0.0.0:9870</value>
</property>
<property>
<name>dfs.namenode.https-address.clusterName.namenode148</name>
<value>0.0.0.0:9871</value>
</property>
<property>
<name>dfs.namenode.rpc-address.clusterName.namenode192</name>
<value>{내부 IP}:8020</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.clusterName.namenode192</name>
<value>{내부 IP}:8022</value>
</property>
<property>
<name>dfs.namenode.http-address.clusterName.namenode192</name>
<value>0.0.0.0:9870</value>
</property>
<property>
<name>dfs.namenode.https-address.clusterName.namenode192</name>
<value>0.0.0.0:9871</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://NameNode1:8485;NameNode2:8485NameNode3:8485/clusterName</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence(Hadoop OS User:22)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/user/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>fs.permissions.umask-mode</name>
<value>022</value>
</property>
<!-- datanode web config -->
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:9864</value>
</property>
<property>
<name>dfs.datanode.https.address</name>
<value>0.0.0.0:9865</value>
</property>
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:9866</value>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:9867</value>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.inode.attributes.provider.class</name>
<value>org.apache.ranger.authorization.hadoop.RangerHdfsAuthorizer</value>
</property>
<property>
<name>dfs.permissions.ContentSummary.subAccess</name>
<value>true</value>
</property>
</configuration>4. 결론
결론적으로 HDFS 자체를 구축 & 운영할 때 신경 써줘야 할 부분이 많은데요.
상당히 문서를 탐독하는데 시간을 많이 보내게 되네요.
그래도 재밌으니 더욱 정독하는 듯 합니다.
신경 쓴 만큼 시스템은 장애에 대해 견고해진다고 생각합니다.
