
1. 서론
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Hadoop의 경우 하둡 완벽 가이드 책을 많이 참고하여 운영을 하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. YARN 이란?
YARN(Yet Another Resource Negitiator)은 Hadoop 에서 자원을 관리 및 할당하는 역할을 합니다.
아래는 Apache Hadoop 공식 문서에서 설명하는 YARN 입니다.
" Yarn Service framework provides first class support and APIs to host long running services natively in YARN. In a nutshell, it serves as a container orchestration platform for managing containerized services on YARN. It supports both docker container and traditional process based containers in YARN. "
Hadoop 은 계산 계층과 저장 계층 이 2가지로 나눌 수 있는데요. YARN 은 여기서 계산 계층을 담당합니다.
YARN은 Hadoop 을 다운 받으면 HDFS 와 함께 들어있기 때문에 별도의 컨테이너 오케스트레이션 툴(ex. k8s)을 도입하지 않더라도 Hadoop ECO 어플리케이션(ex. Spark)을 컨테이너로 관리 할 수 있습니다.
3. YARN 구조
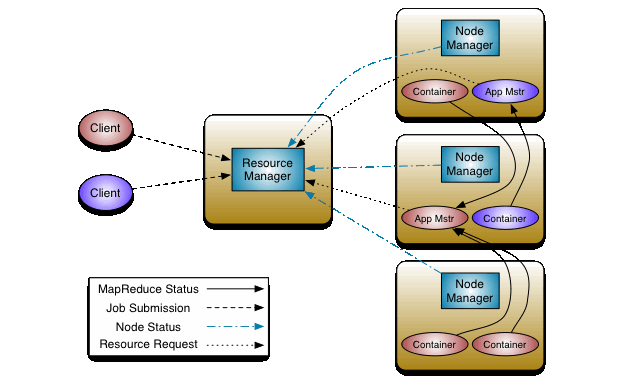
YARN은 Resource Manager 와 Node Manger를 통해서 핵심 서비스를 제공합니다.
해당 아키텍처에서 주요 부분들을 설명 드리겠습니다.
1. Resource Manager
클러스터의 전체 자원의 사용량을 관리합니다.
모든 어플리케이션들은 Resource Manager를 반드시 거쳐야 합니다. 그렇기에 단일 장애점이 되면 안됩니다.
아키텍처 그림은 Resource 매니저가 유일하게 나오는데, HA를 하는 방법이 존재합니다.
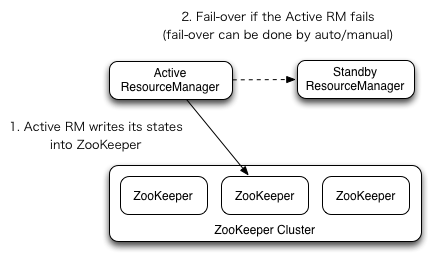
역시나 상태는 Zookeeper 에 상태를 기록하며 Fail-over가 가능하도록 A-S 구조를 취할 수 있습니다.
HA는 쉽게 xml config 을 수정하면 설정할 수 있고 Hadoop 의 NameNode 위에 Resource Manager Daemon을 주로 구동 시킵니다.
2. Node Manager
Resource Manager로 부터 전달받은 application(container) 를 구동하고 모니터링하는 역할을 맡습니다.
그리고 모니터링은 application 뿐만 아니라 실행 중인 노드의 상태 또한 확인 합니다.
3. Application Master
Node Manager 에서 실행되고 단순한 계산의 경우 단일 컨테이너에서 수행 후 그 결과를 클러이언트에 반환 후 종료되지만, Resource Manager 에서 더 많은 컨테이너를 요청하면 분산 처리를 위해 다른 노드로 더 많은 컨테이너를 띄우기도 합니다.
4. YARN Scheduling
YARN 은 병렬 분산 처리를 여러 컨테이너를 활용하여 제공합니다. 그러나 서로 다른 목적의 어플리케이션들이 우후죽순 뜨게 되고, 한 어플리케이션이 대부분의 자원을 점유해버리면 정작 꼭 필요한(ex. 일일 배치) 어플리케이션들이 동작하지 못하는 경우가 발생합니다.
이를 사전에 방지하기 위해 YARN 에서는 Scheduling이라는 3가지 설정이 존재합니다.
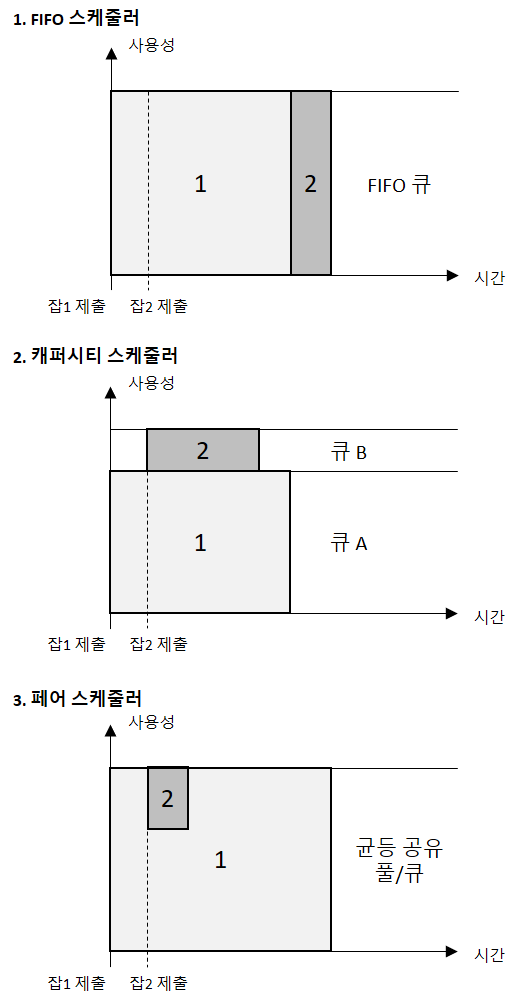
출처 : 하둡 완벽 가이드 - 대형 job과 작은 job을 순서대로 실행할 때의 클러스터 효율성 비교.
저희는 Capacity Scheduler 를 사용하고 있습니다.
Capacity Scheduler 는 각 성격에 맞게 (배치, 분석) 큐를 정한 후 가용량을 미리 할당하는 방식입니다. 가용량이 지정된 큐 내에서만 사용할수도 있지만, 각 큐의 yarn.scheduler.capacity.root.{queuename}.maximum-capacity 설정을 지정해주지 않는다면, 큐의 가용량을 넘어 다른 큐의 자원을 사용 후 반납할 수 있습니다.
이것을 큐의 탄력성이라고 책에서는 표현하는데, 배치가 돌아가는 큐에 이런 영역 침범이 일어나게 되면 상당히 민감한 일이 일어날 수도 있으므로 주의해야 합니다.
Capacity Scheduler 는 트리 형태로 root 에서 가지를 쳐서 나온 queue 에서 다시 가지를 칠 수 있는데, 여기서 부터는 FIFO Scheduling 정책을 따릅니다.
그리고 큐에 작업을 올리는 계정을 매칭하여 해당 계정만 큐를 사용하게 할 수도 있는데, 저희의 경우 배치 작업을 동작시키는 큐는 배치 계정을 별도로 매핑하여 운영하고 있습니다.
더 깊은 내용은 아래 공식 문서 링크를 확인하면 됩니다.
5. Using GPU On YARN & Node Labels
빅데이터 Stack을 기업에서 도입하는 가장 큰 이유는 성능 좋은 ML/DL을 학습하고 서비스하는 것이 가장 큰 목적일 것입니다.
현재 실트론에서 공정마다 Deep Learning 모델을 만들어 내고 있으며, 해당 모델을 통해 예측 또는 분류 서비스를 진행하고 싶어합니다.
그렇기 때문에 Spark 어플리케이션을 YARN에 올렸을 경우 Machine Learning 에서는 문제가 발생하지 않겠지만(오히려 더 좋은 성능을 기대하겠지만), Deep Learning 모델의 경우 서비스를 할 수 없을 정도의 지연 문제가 발생할 수도 있습니다.
그러나 GPU 노드를 YARN 에 포함 시켜 활용할 수 있는 방법이 있다고 합니다.
아직 GPU 노드를 발주한 상태지만 받지를 못 해서 이렇다 할 테스트를 해보지는 못 했지만 아래 링크를 통해 GPU 활용을 도모해 볼 수 있을 듯 합니다.
어느 정도의 제약사항은 있으며 Nvidia GPU 들만 지원을 한다고 합니다.
그리고 Docker 가 컨테이너 컨텍스트로 활용된다면 1.0 버전만 지원을 한다고 합니다.
물론이겠지만 해당 노드에는 Nvidia 드라이버도 설치가 되어 있어야 한다고 합니다.
GPU 는 아래와 같은 세팅으로 자동 설정 된다고 합니다.
- yarn-site.xml
<configuration>
<property>
<name>yarn.resource-types</name>
<value>yarn.io/gpu</value>
</property>
</configuration>그리고 Capacity Scheduler 의 경우는 DominantResourceCalculator 를 별도로 설정 해줘야 한다고 하는데 아래와 같습니다.
- capacity-scheduler.xml
<configuration>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
</property>
</configuration>그리고 노드 매니저에 아래와 같은 설정을 넣으면 자동으로 YARN 에서 GPU를 감지한다고 합니다.
<property>
<name>yarn.nodemanager.resource-plugins</name>
<value>yarn.io/gpu</value>
</property>이렇게 GPU를 YARN 에서 사용할 수 있다는 문서를 확인할 수 있습니다.
그러나 어플리케이션이 GPU가 동작하는 노드를 찾아갈 수 있도록 해야 합니다. 그렇기에 Node Labeling 기능을 YARN 에서는 제공하고 있습니다.
Spark 에서는 Labeling 된 노드를 옵션을 통해서 application master 와 executor 들이 노드를 찾아갈 수 있도록 설정하는 기능도 있습니다.
해당 기능 들은 새로운 노드가 추가되기 전에 테스트 해서 따로 글을 작성해 보도록 하겠습니다.
6. YARN 구성
YARN 구성 시 아래와 같이 config을 작성했는데요.
YARN config 들은 계속해서 실험을 하며 configuration 중이므로 더 나은 설정들이 자주 공유 될 수 있으면 좋겠습니다.
1. mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx2048m</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx4096m</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>256</value>
</property>
<!-- jobhistory server web config -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.https.address</name>
<value>0.0.0.0:19890</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
</configuration>2. yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data01/yarn/rm-local-dir,/data02/yarn/rm-local-dir,/data03/yarn/rm-local-dir,/data04/yarn/rm-local-dir,/data05/yarn/rm-local-dir,/data06/yarn/rm-local-dir</value>
</property>
<property>
<name>yarn.resourcemanager.fs.state-store.uri</name>
<value>/yarn/system/rmstore</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/opt/apps/hadoop-3.2.1/etc/hadoop,
/opt/apps/hadoop-3.2.1/share/hadoop/common/*,
/opt/apps/hadoop-3.2.1/share/hadoop/common/lib/*,
/opt/apps/hadoop-3.2.1/share/hadoop/hdfs/*,
/opt/apps/hadoop-3.2.1/share/hadoop/hdfs/lib/*,
/opt/apps/hadoop-3.2.1/share/hadoop/mapreduce/*,
/opt/apps/hadoop-3.2.1/share/hadoop/mapreduce/lib/*,
/opt/apps/hadoop-3.2.1/share/hadoop/yarn/*,
/opt/apps/hadoop-3.2.1/share/hadoop/yarn/lib/*
</value>
</property>
<!-- RM HA-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarnRM</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm159,rm199</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>{zookeeper1}:2181,{zookeeper2}:2181,{zookeeper3}:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<!-- rm159 configs -->
<property>
<name>yarn.resourcemanager.hostname.rm159</name>
<value>{내부 IP}</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm159</name>
<value>{내부 IP}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm159</name>
<value>{내부 IP}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm159</name>
<value>{내부 IP}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm159</name>
<value>{내부 IP}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm159</name>
<value>{내부 IP}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm159</name>
<value>{내부 IP}:8033</value>
</property>
<!-- rm199 configs -->
<property>
<name>yarn.resourcemanager.hostname.rm199</name>
<value>{내부 IP}</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm199</name>
<value>{내부 IP}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm199</name>
<value>{내부 IP}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm199</name>
<value>{내부 IP}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm199</name>
<value>{내부 IP}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm199</name>
<value>{내부 IP}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm199</name>
<value>{내부 IP}:8033</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>20</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>300000</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>48</value>
</property>
<property>
<name>yarn.scheduler.increment-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>204800</value>
</property>
<property>
<name>yarn.scheduler.increment-allocation-mb</name>
<value>512</value>
</property>
<!-- Timeline Service -->
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.generic-application-history.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>{내부 IP (별도 타임라인 서버)}</value>
</property>
<property>
<name>yarn.timeline-service.address</name>
<value>{내부 IP (별도 타임라인 서버)}:10200</value>
</property>
<property>
<name>yarn.timeline-service.webapp.address</name>
<value>{내부 IP (별도 타임라인 서버)}:8188</value>
</property>
<property>
<name>yarn.timeline-service.webapp.https.address</name>
<value>{내부 IP (별도 타임라인 서버)}:8190</value>
</property>
<property>
<name>yarn.timeline-service.http-cross-origin.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.webapp.ui2.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>false</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>{내부 IP (별도 jobhistory 서버)}:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
</configuration>3. capacity-scheduler.xml
<configuration>
<!--<property>
<name>yarn.scheduler.capacity.mapping-rule-json</name>
<value>{"rules":[{"type":"user","matches":"{배치 큐}","policy":"custom","fallbackResult":"skip","create":true,"customPlacement":"root.{배치 큐}"}]}</value>
</property>-->
<property>
<name>yarn.scheduler.capacity.root.{배치 큐}.capacity</name>
<value>70</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>0</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.{배치 큐}.maximum-capacity</name>
<value>70</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.{분석 큐}.capacity</name>
<value>30</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,{배치 큐},{분석 큐}</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.{분석 큐}.maximum-am-resource-percent</name>
<value>0.3</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.schedule-asynchronously.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>0</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.{배치 큐}.maximum-am-resource-percent</name>
<value>0.4</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.{분석 큐}.maximum-capacity</name>
<value>30</value>
</property>
<property>
<name>yarn.webservice.mutation-api.version</name>
<value>1669010862033</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-am-resource-percent</name>
<value>0.3</value>
</property>
<!--<property>
<name>yarn.scheduler.capacity.mapping-rule-format</name>
<value>json</value>
</property>-->
<property>
<name>yarn.scheduler.capacity.queue-mappings</name>
<value>u:{배치 큐}:{배치 큐}</value>
</property>
</configuration>7. 결론
Hadoop YARN 으로도 많은 서비스를 할 수 있을 듯 합니다.
특히 GPU를 활용한 Deep Learning 서비스를 YARN 에서도 띄워 사용할 수 있는 가능성이 보여 얼른 테스트 해보고 싶어집니다.
