
1. 서론
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
Hadoop의 경우 하둡 완벽 가이드 책을 많이 참고하여 운영을 하고 있습니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. Hadoop 이란?

이미지 출처 : https://www.apache.org/logos/#hadoop
Hadoop 은 더그 커팅에 의해 개발 된 자원 관리 & 분산 병렬 처리 & 파일 시스템이 결합 된 프레임워크 덩어리 입니다.
확실하게 구분 지어야 할 것으로 Hadoop 은 DataBase가 아닙니다.
DB Ranking 을 매기는 사이트가 있는데, 다음은 해당 사이트에서 Hadoop 자체만은 랭킹을 매길 수 없다고 내놓은 공식 입장입니다.
"However, we understand Hadoop as a system providing a (distributed) file system (HDFS) coming along with a comprehensive ecosystem (MapReduce, Yarn, ZooKeeper, Pig, Hive etc.). From a methodical point of view Hadoop could be compared to a distributed file system like NFS or to a 'file server software' like Samba. (We don't dare to mention VSAM here...)"
당연히 Oracle 또한 마찬가지로 Oracle Block 이나 Extent 만 관리하는 부분을 DB 라고 말할 수 없듯이, Hadoop 또한 DB의 가장 최하단인 파일시스템 영역이기 때문에 종종 다른 분야에서 업무 하시는 분들께서는 헷갈려 하시기도 합니다.
그리고 이와 같은 이유로 Hadoop을 설치하여 빅데이터 분야에서 사용할 때 ECO 시스템들이 같이 설치가 되어야 합니다.
하둡은 아래 3가지의 프레임워크로 이루어져 있습니다.
- YARN(Yet Another Resource Negotiator)
- MapReduce
- HDFS(Hadoop Distributed File System)
Hadoop 을 다운 받을 때 위 3가지가 모두 들어 있습니다.
실행 시 HDFS 와 YARN 은 따로 실행이 가능하며, MapReduce의 경우 데이터를 처리하는 방식이므로 따로 실행을 해야만 동작을 하는 것은 아닙니다.
3. 운영하면서 느끼는 Hadoop 의 장점들
데이터 분석 플랫폼을 운영하며 느끼거나 또는 기존에 잘 알려진 Hadoop 의 장점들을 기술 해봅니다.
1. 고가용성
Hadoop 은 크게 NameNode와 DataNode 이 두 가지로 구성 됩니다.
아래와 같은 고가용성 구조를 띄고 있는데요.
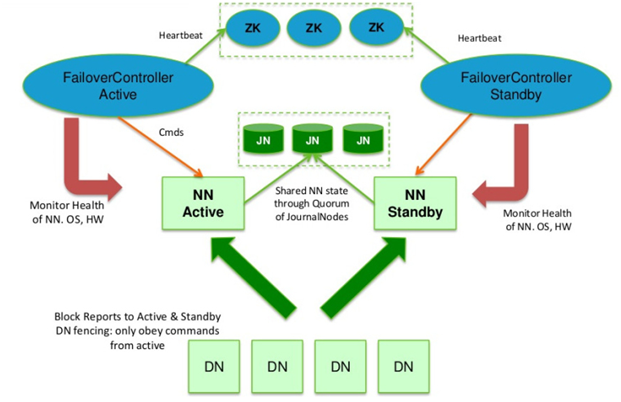
Zookeeper 앙상블을 활용하여 이중화된(A - S) NameNode 를 사용할 수 있습니다.
그러나 Zookeeper 에서 ZKFC(Zookeeper Failover Controller)를 활용하여 Active - Standby 를 구분한다고 하더라도,
매 트랜젝션 당 발생한 Edit log 가 일시적인 장애로 인해 유실될 수도 있습니다.
그렇기에 Journal Node 를 클러스터로 구성하여 edit log 유실을 방지하는 상당히 견고한 장애 대비 구조를 취하고 있습니다.
참고 1 : Fault Tolerant
참고 2 : 하둡 네임 노드 2중화
2. 계속 발전하는 Eco 시스템
Hadoop 을 기점으로 수 많은 Eco 시스템들이 오픈 소스로 만들어지고 있습니다.
데이터를 안전하게, 많이, 저렴하게 저장할 수 있는 구조를 취할 수 있는 덕분에 아래와 같은 구분으로 Eco 들이 만들어지고 있습니다.
- 데이터 분석 & 관리: Spark, Impala, Trino, Hive 등
- 데이터 수집 : Sqoop (수집 솔루션 들은 Hadoop Eco 에 속하는 것이 거의 없습니다. kafka, nifi, flume 등)
- 메타 데이터, 권한 관리 : Atlas, Ranger 등
- 사용자 서비스 : Hue, Zeppelin 등
이 모든 것들이 오픈 소스로 가격 정책 없이 설치할 수 있고, 발전시켜 나갈 수 있다는 점이 매력적인 장점입니다.
물론 저렇게 많은 어플리케이션들을 모두 넣게 된다면 당연히 관리하는 유료 패키징 & 관리 툴이 필요합니다.
보통 운영할 때는 안정성을 유지를 위해 어플리케이션 업체의 보장 된 라이선스를 통하여 운영을 하려고 하지만,
빅데이터의 경우 예외성을 띄고 사용자들이 발전시켜 가는 환경은 상당히 만족스럽습니다.
3. 자원 관리와 데이터 저장을 한 번에
처음 데이터 분석 플랫폼이나 빅데이터 시스템을 도입하는 회사는 데이터 엔지니어(개발/운영) 인력들을 모집하기에는 상당히 시간이 많이 소요될 것입니다.
그러나 한 사람이 수 많은 노드들 & 솔루션들을 관리하기라는 것은 상당히 힘든 일 입니다.
그렇기에 처음 데이터 분석 플랫폼이나 빅데이터 시스템을 도입하는 회사 입장에서 Hadoop은 나쁘지 않은 선택이 될 수 있습니다.
데이터를 분산 저장(HDFS) 하고 저장된 데이터를 병렬 분산 처리(MapReduce) 하고 병렬 처리 어플리케이션들의 자원 관리(YARN) 를 해주는 통합 프레임워크 또는 솔루션이기 때문에 Hadoop 하나만 가지고도 많은 부분들이 해결 될 수 있습니다.
물론 Hadoop NameNode의 메모리 한계를 인정하고 더욱 고도화 시키는 방향을 모색해야겠지만, 매일 같이 쏟아지는 데이터 양이 그렇게 많지 않다면 Hadoop & Hadoop Eco 만으로도 충분히 괜찮은 설계를 할 수 있을 거라고 생각 됩니다.
4. 결론
Hadoop 은 2006년에 발표 되어 나온지 벌써 10년이 넘어가는 오픈소스 입니다.
도입에 있어서 안정성을 논하기에는 충분히 검토되고 발전되어 가고 있는 프레임워크 라고 생각합니다.
만약 Data Warehouse로 활용하고 있는 기존 RDB의 Scale UP 비용과 라이선스 비용이 너무 많이 과금 된다고 생각이 든다면 Hadoop 을 활용한 시스템도 충분히 고려해 볼만하다고 생각합니다.
