- VPN 권한
- 깃랩에 대한 권한을 얻기 위해 VPN 서버에 대한 권한을 받았다
- VPN은 계정 / 네트워크를 통해 권한 부여 받을 수 있다
- 계정을 생성하고 정해진 구역에 있어서 사용할 수 있게 된다
VPN서버를 통해 권한을 받아서 gitlab에 접속한다
- 깃랩 ssh
깃랩 로그인 외에도 나라는 것을 확인 받는 과정
ssh는 공개키, 비밀키를 만들어서 확인한다
깃랩에서 알려진 방법 사용 : .ssh/ 파일 안에 .pub이 공개키, 없는 게 비밀키
- passphrase를 설정하지 않는 것이 좋다!(enter치기)
- web-frontend
- 여러 서비스에서 공통으로 사용하고 있는 코드/데이터들을 git submodule로 사용하고 있다. git clone할 때 이것도 받아야 하므로 git submodule init, git submodule update를 통해 받아준다
- 이외 외부 패키지들도 받아야 하니까 npm install
(위에서 말한 passphrase를 설정하면 이런 거 설치할 때마다 계속 쳐줘야하므로 설정하지 말기!) - 개발 환경 / 배포 환경이 모두 다르기 때문에 개발환경에 맞는 json 파일을 cp한다
- server.ts파일에서 포트를 확인해서 볼 수 있다
- 이때 화면에 띄운 건 볼 수 있지만 cors 에러 때문에 localhost로 띄운 것은 보기 어렵다
- 그러므로 cors를 해결하기 위해 origin을 바꿔도 되지만 여기서는 cors의 origin으로 설정해둔 정규식을 만족하기 위해 해당 조건에 맞는 dns를 설정한다
- 해당 dns + port번호로 볼 수 있다!
- 로컬로 서버를 돌릴 때는 정해놓은 서버 주소를 바꿔줘야 개발 환경용 서버가 아닌 내가 수정한 서버를 통해 확인할 수 있다 (development.json의 apiServerUrl을 서버의 dns:port로 변경)
- web-backend
- BE도 모두 마찬가지지만 api에 대한 응답을 라우팅별로 받아야 하기 때문에 그냥 포트번호만 치면 별 내용이 나오지 않는다
(설정을 안해두면 not found가 나온다) - 그러므로 코드 잘 읽어서 확인해보거나 프론트 통해 확인
- 이외 유의할 점
- vue
- jquery
- handler
path별로 라우팅 따라서 잘 이해하고 코드를 보되 vue 위주로!
아예 새롭게 생성하는 부분은 vue로 할 거고 나머지는 유지보수 정도만
- 서비스 아키텍처
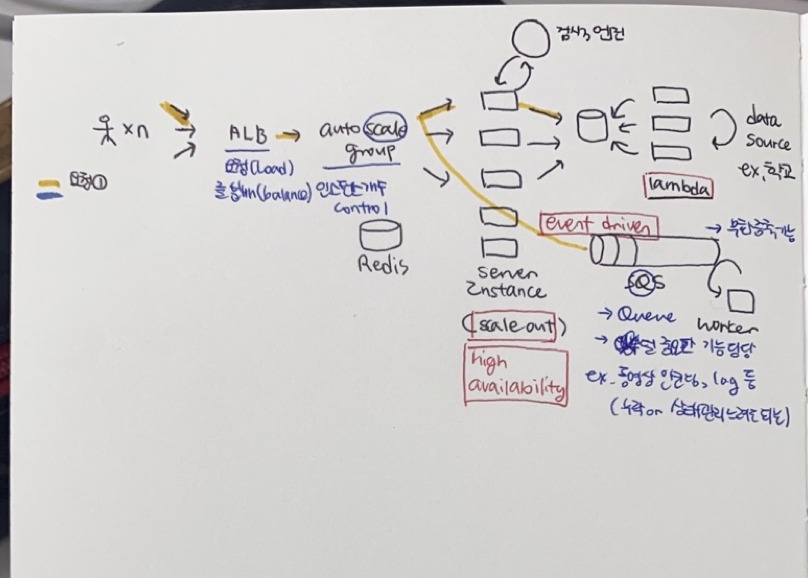
1)기본적인 구조
요청 - 서버 - 데이터베이스
2)생길 수 있는 문제
(1) 요청이 너무 많아지면?
해결 1) scale up
: 사용하고 있는 인스턴스(서버)의 스펙을 올린다 (속도, 성능, 용량 등)
: 하지만 한계가 있다
해결 2) scale out(권장)
: 인스턴스의 수를 늘린다.
: [high availability] - 서버가 하나라면 언제 꺼질지 모르는 위험이 있다. 여러 개면 이런 위험을 줄이고 가용성을 높일 수 있다
: 이때 생길 수 있는 문제 해결책
1. 균등한 분배 : ALB (AWS Load Balancer)
2. 사용할 인스턴스의 개수 조절 : auto scale group
(2) scale out 시 여러 서버가 공통으로 가져야 하는 정보를 어떻게 공유할까? ex. 로그인
방법 1) 데이터베이스
: 비효율적이다
: 로그인 정보만 가지고 있으면 되는데 쿼리, 로우 등등을 모두 뚫고 저장했다가 다시 조회하는 방식은 비효율적
방법 2) Redis
: 하드디스크가 아닌 인메모리 방식(비슷한 것으로 memcache가 있음)
: key-value store (가볍게 저장 가능)
: 휘발성 데이터 저장하기에 용이 (3) 검색 엔진처럼 주요 기능인 CRUD 외 기능은 어떻게 처리?
서버와 DB는 CRUD에 국한하는 것이 효율적이다.
부가적인 기능까지 서버, DB에 추가하면 매번 너무 많은 것들을 조회하는 등 비효율 발생
그러므로 검색엔진, 동영상 인코딩, 로그를 남기는 등의 부가적인 기능들은 SQS와 worker가 담당한다.
SQS는 말 그대로 Queue, 즉 CRUD와 같은 주요 기능 외 event단위로 일어나는 동작들을 큐에 담는다(event-driven). 그러면 worker가 큐를 확인하면서 하나씩 처리한다. 이때 처리하는 일들은 중요하지 않기 때문에 혹시 누락되거나 충돌해도 문제 없다. 검색엔진의 경우도 전체 데이터를 다 필요로 하지 않고 서버에 있는 내용들을 인덱싱해서 가져가는데 이 인덱싱을 sqs와 worker가 맡는다(추가 조사 필요)
(4) 주요 기능이 아니고 event-driven이 아닌 기능은 어떻게 처리?
예를 들어 게시판의 가장 인기 많은 글, 가장 최신 글 등의 이외 처리를 해줘야 하는 경우가 생겼을 때, CRUD 외의 조작을 해주는 lambda를 써준다. 외부에서 필요한 데이터를 끌어오는 등등의 부가적인 기능 등을 AWS의 lambda에 정의해주면 컴퓨팅의 일련으로 알아서 해결을 해준다.
시스템 아키텍처의 키워드
- scale up/out
- availability
- event-driven
- lambda
