Vector DB
LLM, Generative AI, semantic search 등을 포함하는 기술이 발전하면서 Vector DB의 중요성도 커졌다. AI는 벡터로 Data를 이해한다. 여기서 말하는 vector는 간단하게는 다차원 공간에서 존재하는 한 점 혹은 좌표라고 상상하면 된다.
그래서 Vector DB가 뭐냐? vector를 다루는데에 특화된 Database이다. 대표적으로는 일반적인 RDB나 NoSQL에서 제공하지 않는 vector embeddings의 search나 retrieval을 효과적으로 수행할 수 있는 알고리즘 및 시스템을 제공한다.
Vector Index
Vector Index랑 Vector DB가 혼용돼서 쓰이곤 하는데, Vector Index는 Vector DB의 핵심 기능이자 포함되는 기능이다.
대표적인 Vector Index는 FAISS(Facebook AI Similarity Search).
FAISS는 facebook research에서 개발한, dense vector들의 클러스터링과 유사도를 구할때 사용하는 Standalone vector index 라이브러리이다. C++로 작성되었으며 python에서 지원된다. 그리고 GPU 상에서도 효율적으로 동작하도록 개발 되었다. 구체적인 알고리즘은 뒤에서 살펴보자.
어쨌든 Vector Index에 추가로 일반적인 Database이 하는 다음과 같은 일들도 해준다.
- Data management : CRUD와 같은 기능들.
- Metadata storage and filtering : vector 뿐만 아니라 일반적인 형태의 데이터(meta data)들도 함께 다룰 수 있다.
- Scalability : Support for distributed and parallel processing.
- Backup, 다른 tool들과 integration, Security, Access control
In short, a vector database provides a superior solution for handling vector embeddings by addressing the limitations of standalone vector indices, such as scalability challenges, cumbersome integration processes, and the absence of real-time updates and built-in security measures, ensuring a more effective and streamlined data management experience.
How does vector DB work?
Vector DB가 잘 해야하는 일은 Approximate Nearest Neighbor(ANN) search이다. 이를 위해서 Hashing, quantization, graph-based search 등의 기법을 사용한다. 때로는 조합해서!
일반적인 Flow
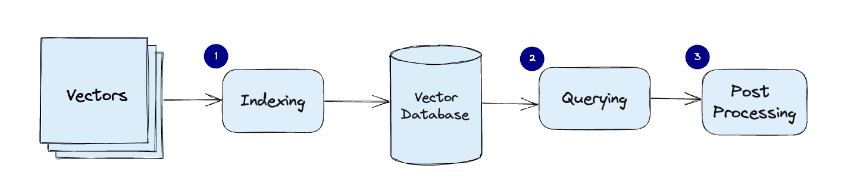
-
Indexing: The vector database indexes vectors using an algorithm such as PQ, LSH, or HNSW (more on these below). This step maps the vectors to a data structure that will enable faster searching.
-
Querying: The vector database compares the indexed query vector to the indexed vectors in the dataset to find the nearest neighbors (applying a similarity metric used by that index)
-
Post Processing: In some cases, the vector database retrieves the final nearest neighbors from the dataset and post-processes them to return the final results. This step can include re-ranking the nearest neighbors using a different similarity measure.
Algorithms
Prerequisite
K-means algorithm
데이터를 k개의 cluster로 묶는 알고리즘.
Random Projection
가장 간단한 알고리즘. 기본 아이디어는 Random Projection Matrix을 사용하여 고차원 벡터를 저차원 공간으로 투영하는 것입니다. 우리는 random number로 matrix를 만든다. 행렬의 크기는 원하는 저차원 공간의 크기로 한다. 그런 다음 입력 벡터와 행렬의 Dot product을 계산하고, 그 결과 원래 벡터보다 더 적은 차원을 가지지만 여전히 유사성을 유지할 것이라고 기대한다.
쿼리가 들어오면 마찬가지로 쿼리도 같은 Projection Matrix을 사용해서 저차원 벡터로 projection하고 저차원 vector를 기반으로 nearest neighbors를 찾는다. 차원을 줄였기 때문에 Search process의 속도를 개선할 수 있다.
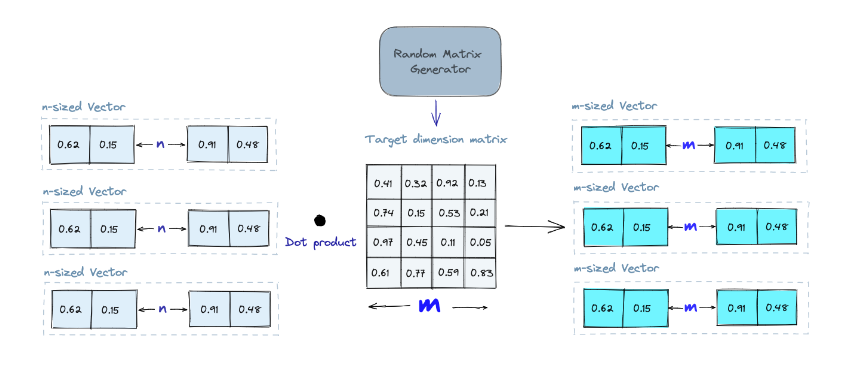
이미 느껴졌을테지만, Random Projection은 Approximate method이다. 그리고 참고로 matrix가 random할수록 성능이 좋다고 한다.
Product Quantization(PQ)
PQ는 제품 고차원 벡터에 대한 Lossy Compression 기술이다. 원본 벡터를 작은 청크들로 나누고 각 청크에 대한 대표 "코드"를 만들어 각 청크의 표현을 단순화한 다음 유사성 작업에 필수적인 정보를 잃지 않고 모든 청크를 다시 결합합니다.
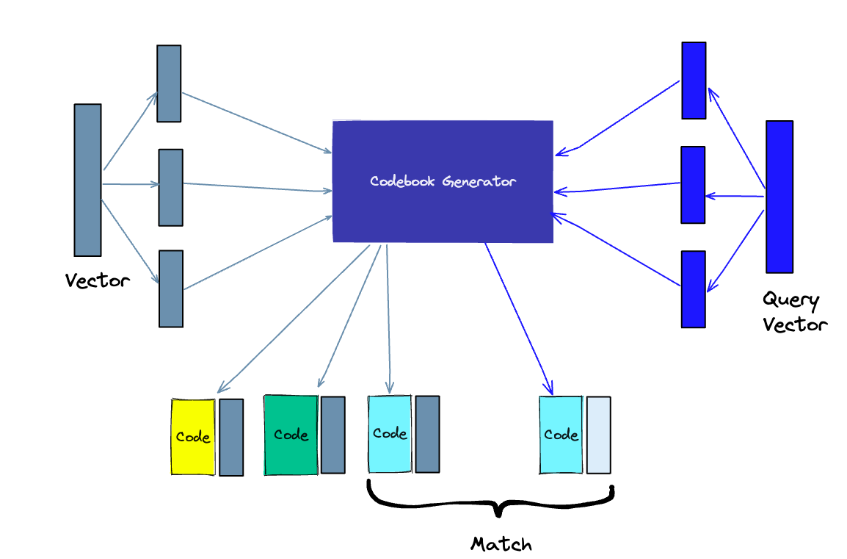
-
Splitting -The vectors are broken into segments.
-
Training - we build a “codebook” for each segment. Simply put - the algorithm generates a pool of potential “codes” that could be assigned to a vector. In practice - this “codebook” is made up of the center points of clusters created by performing k-means clustering on each of the vector’s segments. We would have the same number of values in the segment codebook as the value we use for the k-means clustering.
-
Encoding - The algorithm assigns a specific code to each segment. In practice, we find the nearest value in the codebook to each vector segment after the training is complete. Our PQ code for the segment will be the identifier for the corresponding value in the codebook. We could use as many PQ codes as we’d like, meaning we can pick multiple values from the codebook to represent each segment.
-
Querying - When we query, the algorithm breaks down the vectors into sub-vectors and quantizes them using the same codebook. Then, it uses the indexed codes to find the nearest vectors to the query vector.
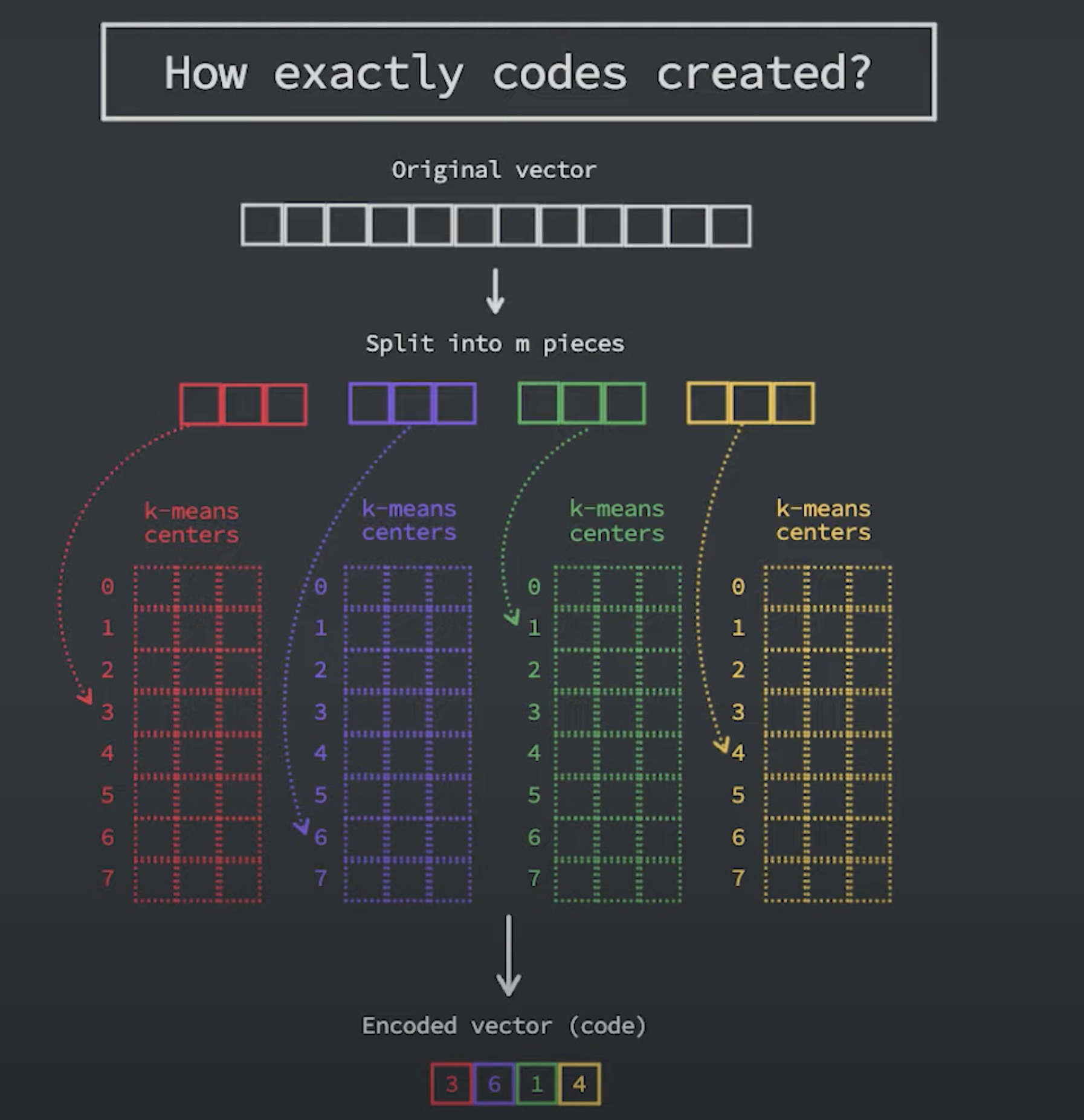
PQ알고리즘도 결국 Approximate하는 방식이다. 따라서 K-means 알고리즘에 쓰인 K의 값에 따라 accuracy와 latency의 trade-off가 발생한다.
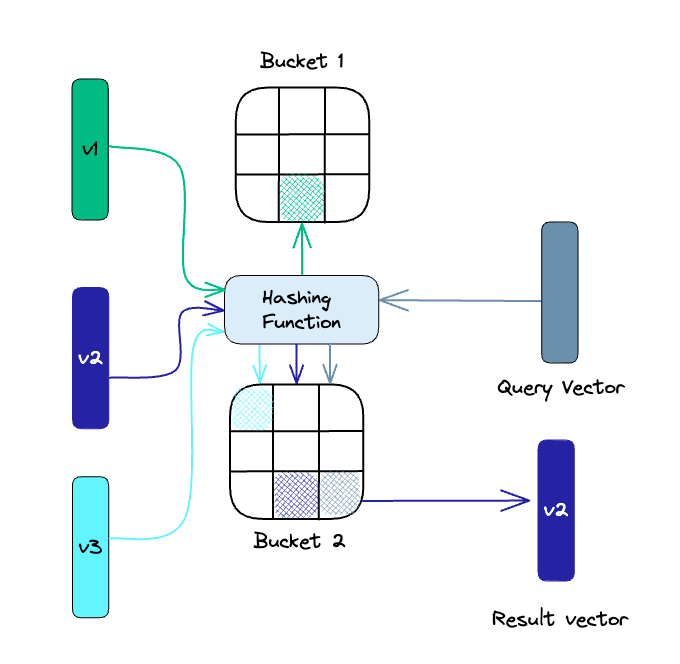
Locality-sensitive hashing(LSH)
요거도 비슷하다. vector들을 Locality를 보존하는 hash function을 사용해 bucketdㅡ로 분류하여 저장한다. 그리고 쿼리 또한 같은 hash function으로 해당하는 bucket을 찾는다. 그리고 그 버킷 안에 있는 벡터들과 거리를 계산한다. 버킷을 통해 한번 걸러서 비교해야할 벡터들의 모수를 줄이는 방식.
Hierarchical Navigable Small World (HNSW)
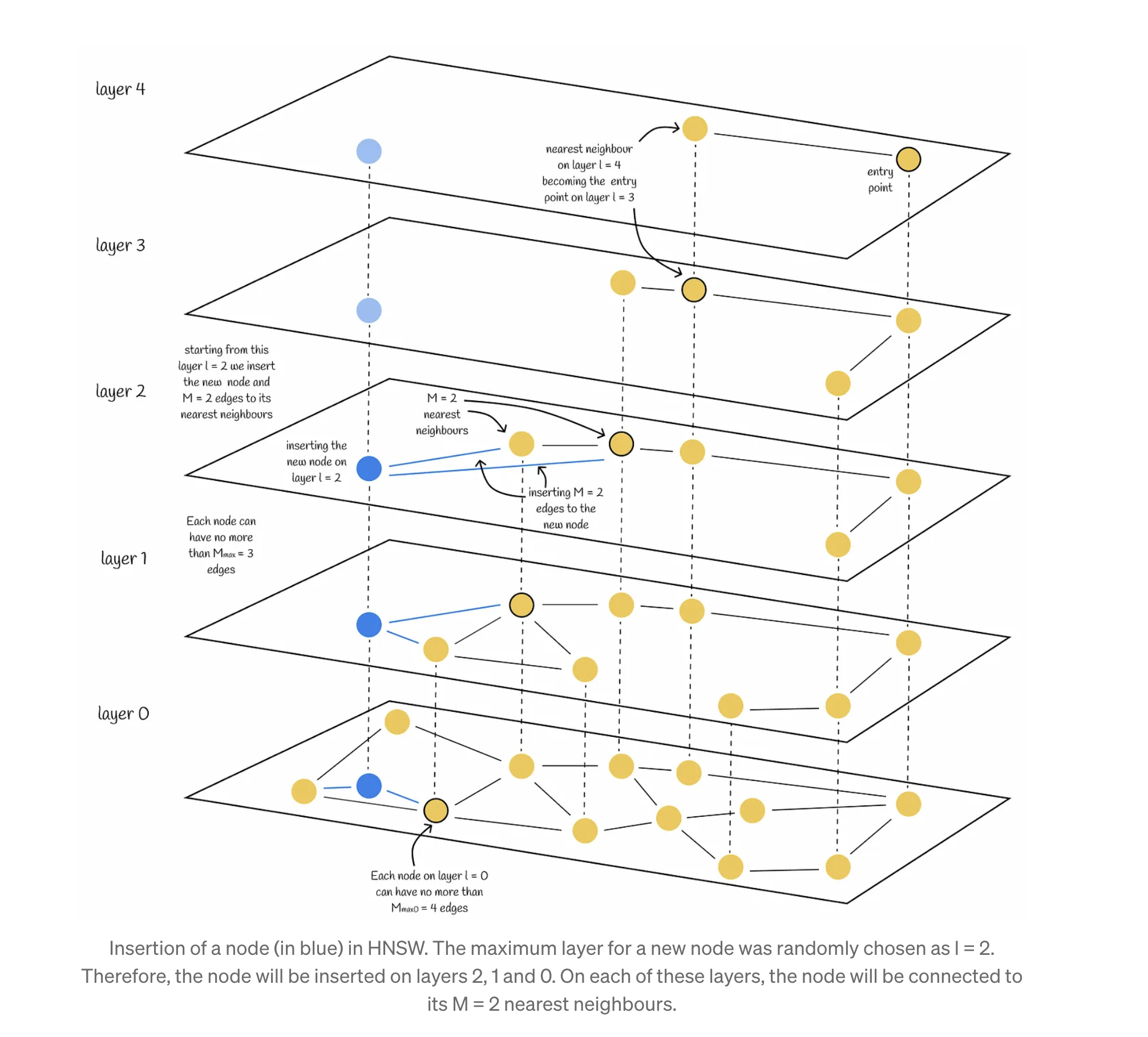
https://towardsdatascience.com/similarity-search-part-4-hierarchical-navigable-small-world-hnsw-2aad4fe87d37
https://www.pinecone.io/learn/series/faiss/hnsw/
Vector DB 종류 비교
| Qdrant | Milvus | Chroma | Pincone | Weaviate | |
|---|---|---|---|---|---|
| Opensource | O | O | O | x | O |
| Document | 좋음 | 보통 | 보통 | 좋음 | 보통 |
| Cloud | O | O | X(준비중) | O | O |
| Git stars | 13k | 23k | 8.7k | . | 7.6k |
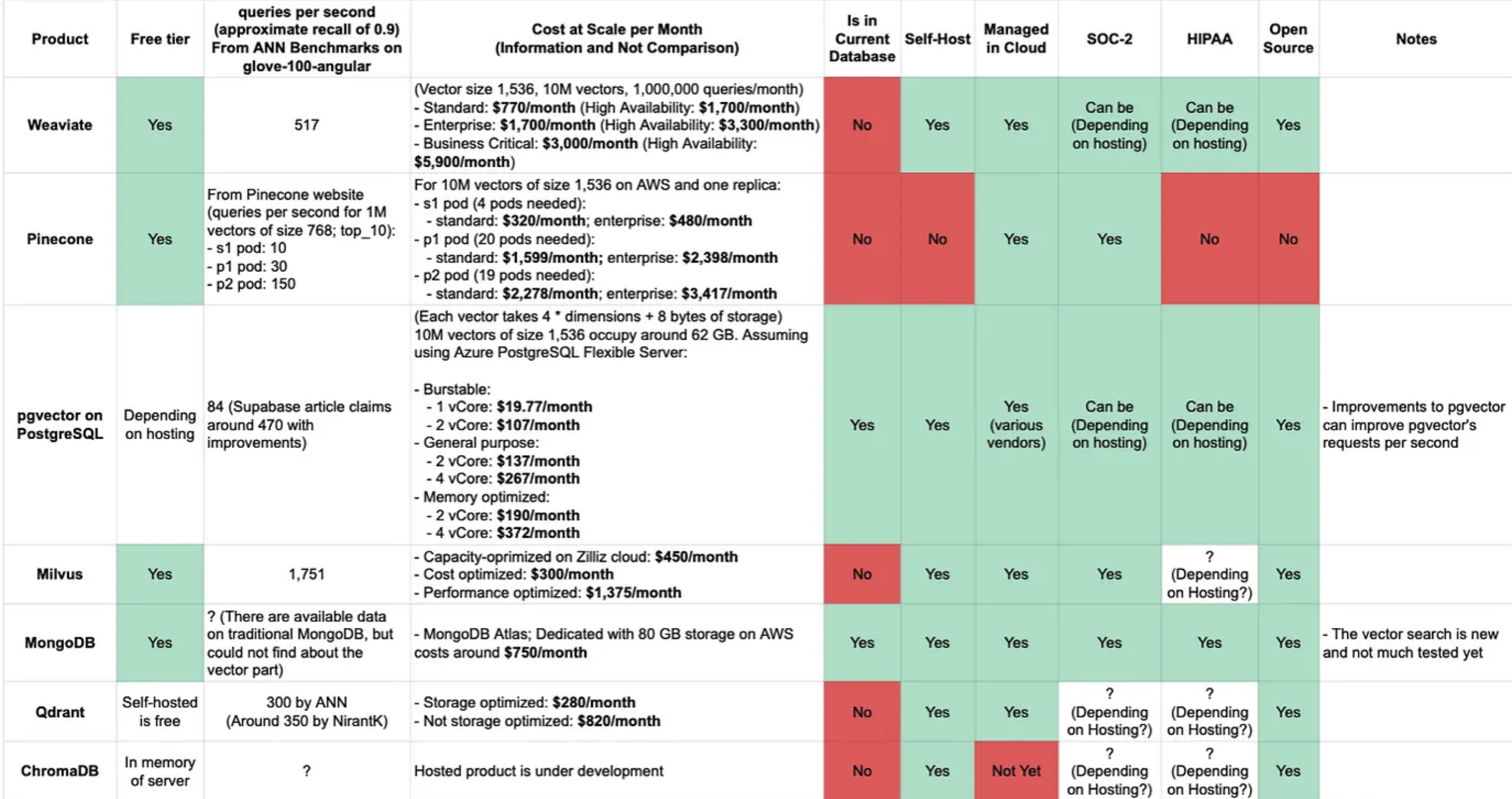
https://objectbox.io/2023_06_13_vector-databases.htm
Benchmark
gist-960-euclidean dataset, which consists of 1 million vectors.
client machine 4cores 8G
DB engine machine 16Cores 32G Ram
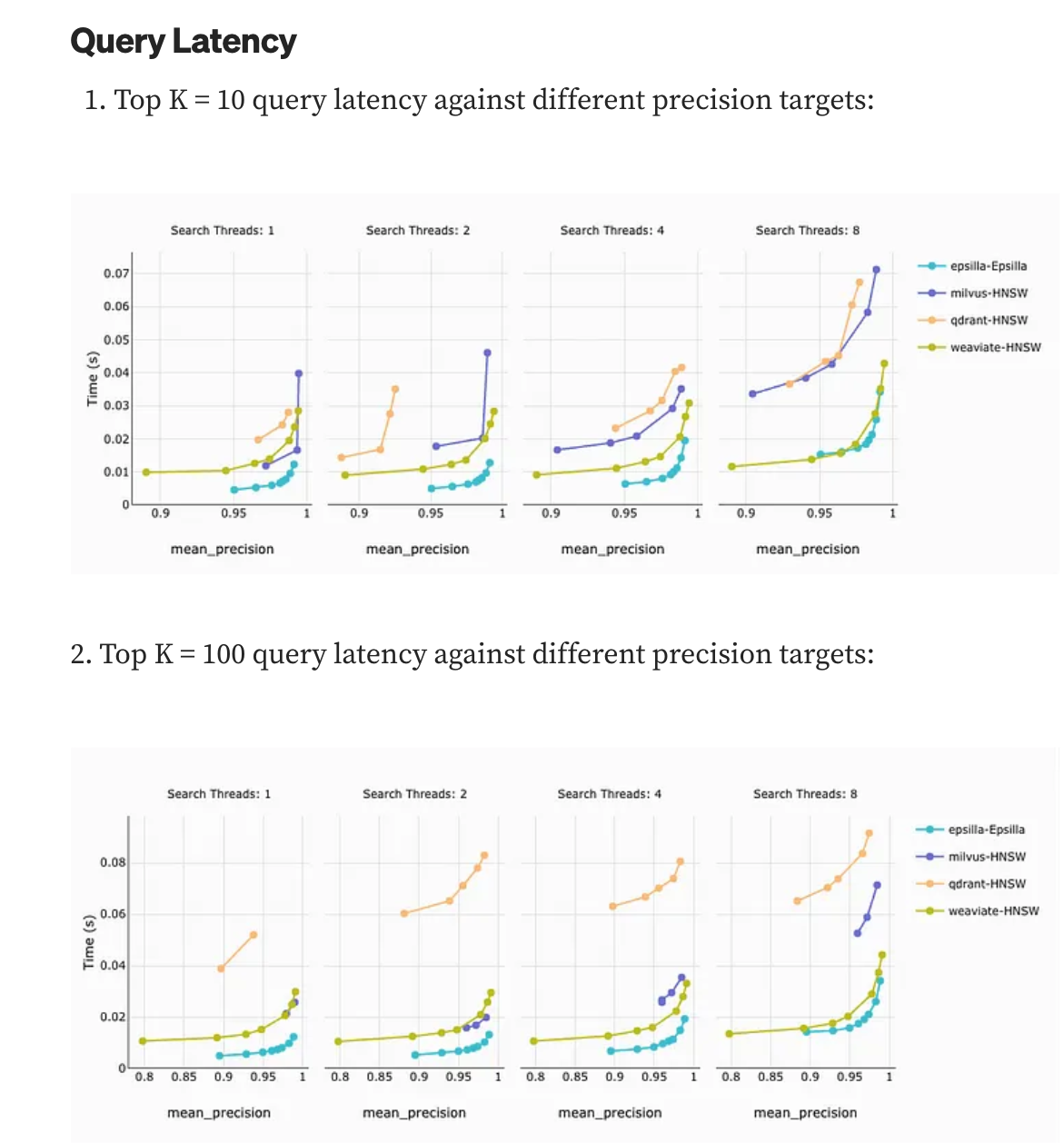
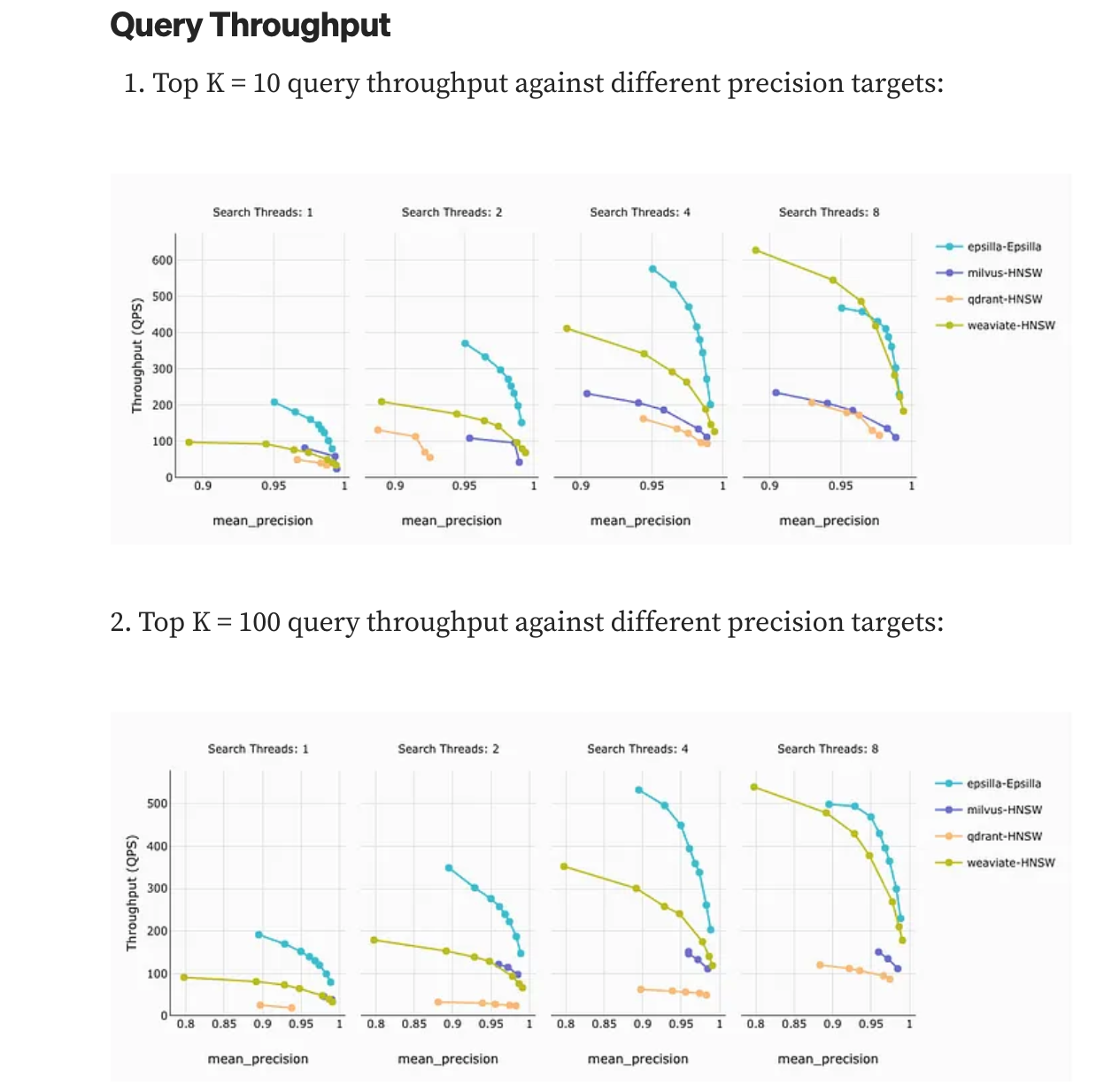
https://jina.ai/news/benchmark-vector-search-databases-with-one-million-data/
References
https://mccormickml.com/2017/10/13/product-quantizer-tutorial-part-1/
https://www.pinecone.io/learn/vector-database/
https://www.youtube.com/watch?v=PNVJvZEkuXo
https://www.pinecone.io/learn/series/faiss/product-quantization/

2개의 댓글

Looking for a powerful tool to manage your iPhone or iPad? Try 3uTools for a complete iOS management solution.
https://3utools.id/3utools-for-android/
Facing the same with this website: https://alldticodes.com/fav-aesthetic-dress-to-impress/