
ElasticSearch
💡 ElasticSearch는 Apache Lucene(library) 기반의 JAVA 오픈소스 분산 검색 엔진이다. 코어 검색 로직은 Apache Lucene으로 하면서 분산 아키텍처를 적용하고 REST API 등과 같이 사용성을 높이는 추가 기능들이 포함되어 있다.목표
- ElasticSearch가 무엇인지 안다.
- ElasticSearch의 특징과 핵심 용어들을 안다.
- ElasticSearch를 실무적으로 사용하기 위해 최소한의 내부 동작 원리를 파악한다.
ElasticSearch의 특징
- Scale out, Availability - 분산 시스템이기 때문에 수평적으로 확장 가능하다. Replica를 사용하기 때문에 안정성이 높다.
- Restful - Data의 CRUD 작업이 HTTP Restful API를 통해 수행된다.
- 오픈소스
- NRT(Near Realtime) - 새로운 문서를 indexing할 때부터 검색 가능한 대기 시간이 1초 정도 걸림.
- schema X, Json으로 문서를 다룸.
단점
- Learning Curve, 진입 장벽
- Join X
- Transaction and Rollback X
- 데이터 변경에 효율적이지 않음.
ELK
ELK stack이란 elasticsearch를 포함해서 자주 함께 쓰이는 기술 stack들이다. Elasticsearch Logstash Kibana 세가지 오픈소스 프로젝트의 이니셜을 합쳐 만든 말이다. 최근 Beats가 새롭게 포함된다.
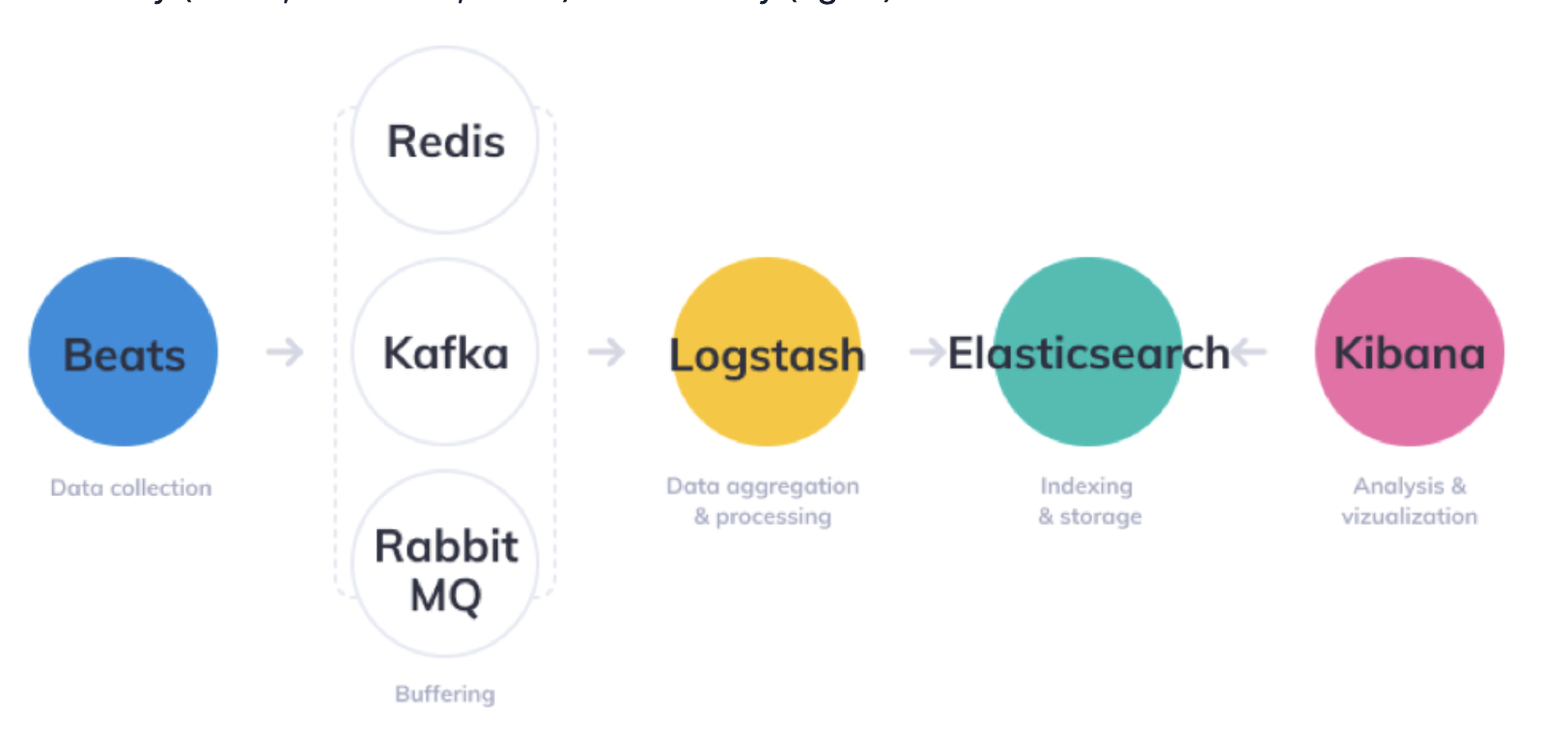
- Beats - Beats는 로그 혹은 메트릭이 발생하는 서버에 에이전트로 설치되어 데이터를 수집하고, 이 데이터를 Logstash로 전송한다. 위 다이어그램에는 Beats와 Logstash 사이에 메시지 큐가 위치하는 것을 확인할 수 있는데, 이는 안정성 또는 확장성 등을 위함이다.
- Logstash - 데이터 처리 파이프라인 도구. Logstash는 데이터를 적절히 필터링, 가공하여 Elastic Search로 전달한다.
- ElasticSearch - 검색
- Kibana - REST API를 통해 Elastic Search로부터 데이터를 가져와 유저에게 시각화와 간편한 데이터 검색 기능 등을 제공한다.
검색은 어떤 과정을 통해서 이뤄질까?
유사도 알고리즘
TF/IDF
ES 5.0 버전부터 default 알고리즘이 TF/IDF에서 BM25로 변경되었다. BM25는 TF/IDF의 variation이면서 좀 더 복잡하기 때문에 여기서는 TF/IDF로 만족하자.
TF = Term Frequency, 문서 내 특정 단어의 등장 빈도를 의미한다.
IDF = Inverse Document Frequency, 얼마나 특이한 단어인지를 의미한다. 특성 없는 단어들보다 중요한 단어에 가중치를 주기 위함이다.

검색을 위해서는 키워드와 문서들의 TF/IDF와 같은 Metric을 계산하게 된다.
대용량 텍스트 데이터가 있고 검색어와 문서들과의 TF/IDF를 계산한다고 가정해보자. RDB에 데이터가 있다고 가정하면 모든 문서를 돌면서 단어의 등장 여부를 count 해야 한다. ES는 어떻게 이걸 빨리 할 수 있을까?
Apache Lucene
Apache Lucene은 검색 엔진 라이브러리이다. ES가 대용량 텍스트 데이터 검색을 빠른 속도로 할 수 있는 것은 Lucene을 사용하기 때문이다. 위에서 말했듯이 Lucene이 ElasticSearch의 코어이기 때문에 Lucene의 내부동작을 알면 ElasticSearch의 내부동작의 상당 부분 이해할 수 있다.
Inverted Index
ES가 RDB보다 더 효과적인 텍스트 검색이 가능한 이유가 뭘까
ES는 Inverted Index를 사용한다. 이는 책 젤 뒤에 있는 찾아보기와 유사하며 단어사전이라도 부른다. 키워드를 키로 하고 키워드가 등장하는 위치를 기록하는 방식이다.

RDB에 있는 책 데이터에서 “과적합”(키워드)가 등장하는 문서를 검색한다고 가정해보자. like %과적합%와 같은 쿼리를 사용하게 될텐데 이는 인덱스를 타지 못하며 대용량 데이터에서 매우 느리다.
반면, Inverted Index를 사용한다고 할 때는 “과적합”이 등장하는 문서를 검색한다고 하면, Inverted Index에서 과적합의 value인 077, 099, 105, 108, 111, 126임을 매우 빠르게 알 수 있다.
사실 Inverted Index를 만드는 것이 이렇게 간단하지는 않고 실제로는 많은 복잡한 처리가 수행된다.
- term 단위로 쪼갠다(tokenizing) token이 항상 단어가 되는 것은 아니다(whitespace tokenizer)
- 대소문자 처리
- 동의어 처리
- a, the 같은 불용어 처리
- 형태소 분석을 통한 ~s, ~ing 처리
- 유사어 사전 제작 등
여기까지 어떻게 ES가 검색을 빨리할 수 있는지에 대해 큰 그림은 이해할 수 있었다.
Architecture와 용어

아래의 설명들은 분산 시스템에 익숙한 분들에겐 익숙한 개념일테니 빠르게 넘어가셔도 좋습니다.
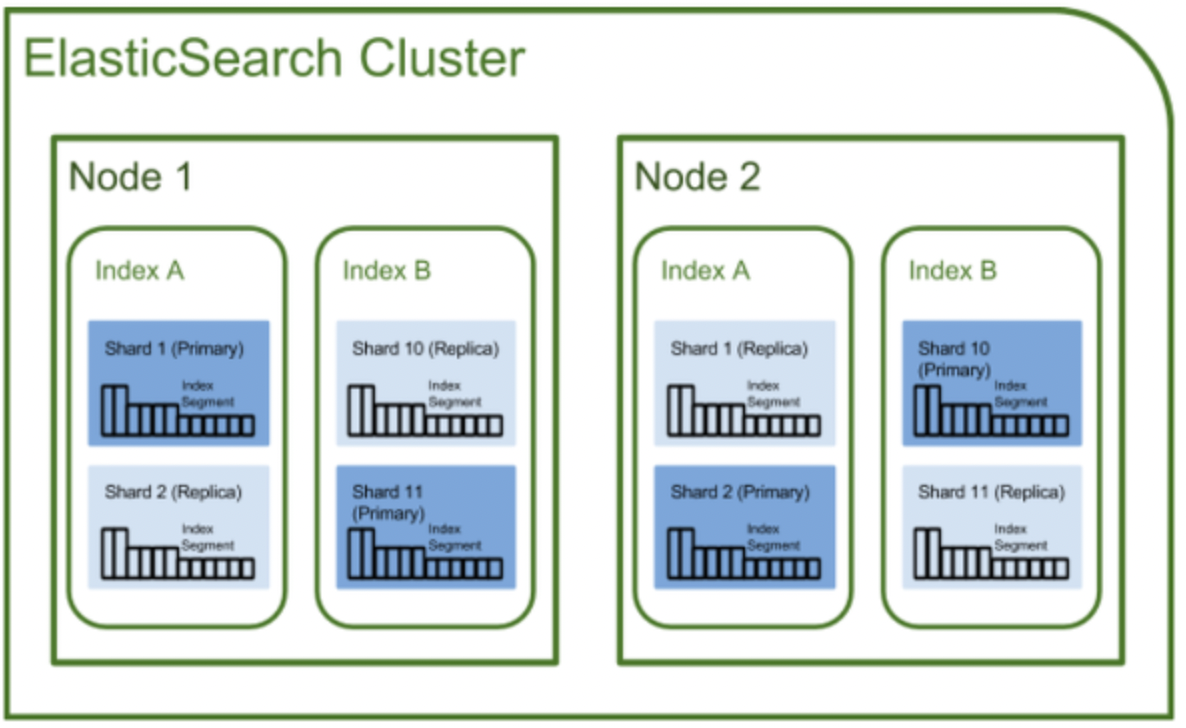
클러스터(cluseter)
- 가장 큰 시스템 단위로, 최소 하나 이상의 노드로 이루어진 노드들의 집합
- 서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지됨
- 여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재할 수도 있음
노드(node)
- Elasticsearch를 구성하는 하나의 단위 프로세스
- 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분
- master-eligible node : 클러스터를 제어하는 마스터로 선택할 수 있는 노드
- master-eligible node 역할 : 인덱스 생성, 삭제 / 클러스터 노드들의 추적, 관리 / 데이터 입력 시 어느 샤드에 할당할 것인지 결정
- Data node : 데이터와 관련된 CRUD 작업과 관련있는 노드 / CPU, 메모리 등 자원을 많이 소모하므로 모니터링이 필요 / master 노드와 분리되는 것이 좋음
- Ingest node: 데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할
- Coordination only node : data node와 master-eligible node의 일을 대신하는 노드 / 대규모 클러스터에서 큰 이점이 있음 / 로드밸런서와 비슷한 역할
인덱스(Index)
- RDBMS에서 database와 대응하는 개념.
- shard와 replica는 Elasticsearch에만 존재하는 개념이 아니라, 분산 데이터베이스 시스템에도 존재하는 개념.
샤드(Shard)
- 데이터를 분산해서 저장하는 방법.
- Elasticsearch에서 스케일 아웃을 위해 index를 여러 shard로 쪼갠 것.
- 기본적으로 1개가 존재하며, 검색 성능 향상을 위해 클러스터의 샤드 갯수를 조정하는 튜닝을 하기도 함.
복제(Replica)
- 또 다른 형태의 shard라고 할 수 있음
- 노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드들을 복제하는 것
- 따라서 replica는 서로 다른 노드에 존재할 것을 권장
- 아래 사진에서 보는 바와 같이 Replica1은 Node2에 존재하는 것을 확인할 수 있음
새로운 데이터가 들어오면 어떤 일이 일어날까
Segment
Segment : 실제 데이터가 담겨있는 조각. 실제 document와 Inverted Index가 모두 포함되어 있다. 각 노드에는 다수의 segment가 있을 수 있고 검색이 발생하면 모든 segment를 차례로 검색하고 결과를 합치게 된다.
segment의 수가 많으면 당연하게도 성능이 떨어지기 때문에 Lucene은 background에서 주기적으로 segment 파일들을 merge한다. 더 이상 추가 색인이 없이 일정 시간이 지나면 결과적으로 1개의 큰 segment만 남게된다.
새로운 document가 insert 되면 벌어지는 일
- 인메모리 버퍼에 쌓인다.
- 정책에 따라 내부 버퍼(큐)에 일정 크기 이상의 데이터가 쌓이거나 일정 시간이 흐를 경우 버퍼에 쌓은 데이터를 한꺼번에 모아 처리한다. (ElasticSearch가 NRT인 이유)
- 모인 데이터를 indexing하고 새로운 하나의 segment를 추가한다.
- fsync가 아닌 write로 Disk가 아닌 메모리에만 쓴다. (Disk 쓰는 작업이 cost가 크기 때문에)
- 일정 주기마다 Disk로 flush해준다.
Segment의 불변성
루씬에선 세그먼트가 주기적인 merge 작업에 의해 통합되기 전까지 수정을 허용하지 않는 불변성 (Immutability) 을 지님.
그렇기 때문에 update 연산은 기존 데이터 삭제 후 다시 생성하게 된다.
Delete 연산이 발생하면 flag만 up해서 검색 대상에서 제외를 시키지만 바로 삭제하진 않는다. 실제로 삭제되는 시점은 주기적으로 진행되는 segment merge 시점.
이로 인해 얻을 수 있는 것
- 동시성 문제 회피 가능
- Cache 활용성
- 만약 불변성을 정책이 없다면, 수정이 발생하면 inverted index 다시 전면 수정해야함.
Reference
https://amazoneberea.tistory.com/41
https://m.blog.naver.com/occidere/222855273511
https://amazoneberea.tistory.com/41
https://loosie.tistory.com/833
https://jaemunbro.medium.com/elastic-search-기초-스터디-ff01870094f0
https://velog.io/@soyeon207/이론-Elasticsearch-란
https://velog.io/@mayhan/Elasticsearch-유사도-알고리즘
https://wikidocs.net/31698
https://blog.naver.com/occidere/222855568900
https://hudi.blog/elk-stack-overview/
https://icarus8050.tistory.com/52
https://ksk-developer.tistory.com/24
