안녕하세요.
넥스트도어 장우일입니다.
지난 시간에 이어, MAX PLANCK 연구소의 2022년 Pose Estimation 논문들 중 Whole Body, Hand 분야 논문들에 대해 알아보겠습니다.
2. Whole Body
2-1) Capturing and inferring dense full-body human-scene contact
코드 링크
논문 링크
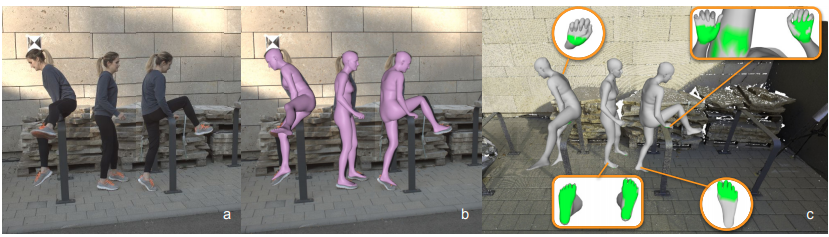
위 그림의 초록색 영역처럼 contact (신체 중 다른 어떤 것에 닿는 부분)를 추론하는 모델입니다.
이런 분야를 human-scene contact(HSC)라고 합니다.
이 논문에서 지적하는 기존 HSC 방법들의 문제점은 다음과 같습니다.
- 단순화된 몇 가지의 가정만을 고려한다 : 발과 지면과의 접촉(지면을 평평한 평면으로 가정)만을 다루는 경우가 많은데, 이는 데이터 부족 문제도 있다. 그래서 이를 해결하기 위해 새로운 데이터셋인 RICH를 이용해서 학습한다. (실외 장면 스캔 + 이미지)
- 3D 신체가 아닌, 2D 영역만 다루는 경우가 많다.
[RICH Dataset]
1) AlphaPose로 각 비디오의 Subject 추정
2) MvPose로 multi-view 3D Pose 추정해서 view별 tracklet을 매칭시킨다
tracklet : 1, 2, 3, 4, 5 프레임이 있다고 했을 때, 1에서 5까지 갈 동안의 사람 A가 이동한 짧은 경로를 말합니다.
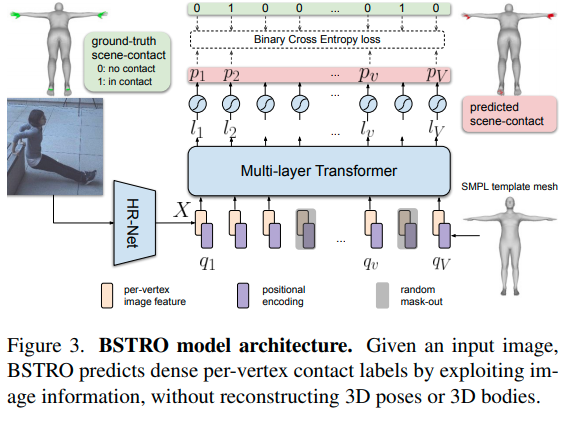
그림에서 볼 수 있듯이, 이미지 1장이 주어지면, vertex 별로 (SMPL 기준, 6890개) contact label을 예측합니다.
(0: no contact, 1: in contact)
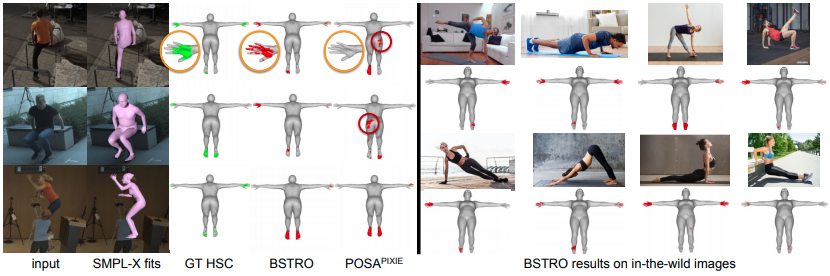
human scene contact 작업이 어떤 점에 도움이 될 수 있을까요?
- 결과 이미지에 많이 등장하는 것처럼 운동 쪽에 도움이 될 것 같습니다.
운동을 할 때, 기구를 제대로 잡고 있는지, 발의 위치 등을 파악하면 부상 방지에도 활용이 될 수도 있을 것 같네요.
3. Hand
3-1) Articulated Objects in Free-form Hand Interaction
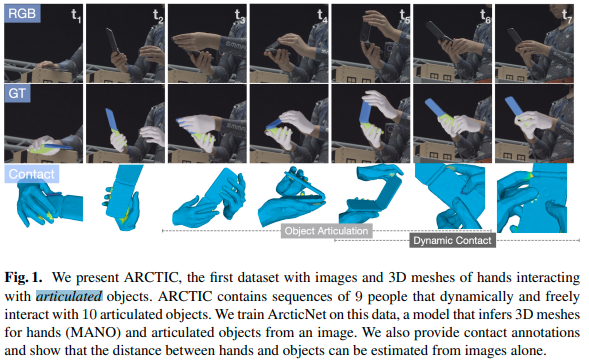
이 논문은 데이터셋을 소개하는 논문인데요.
손과 물체가 닿아서 상호작용하고 있는 3D mesh와 이미지가 포함된 데이터셋입니다.
이 데이터셋을 학습하기 위해 ArcticNet 모델을 학습해서 hand mesh (MANO)와 이미지 상의 물체들을 추론하도록 하고 있습니다.
여기에 추가적으로 contact annotation(접촉된 부분), 물체와 손 간의 거리도 이미지에서 측정될 수 있게 했다고 합니다.
ARCTIC dataset
- Multi-view RGB 프레임 시퀀스로 구성되고, 각 프레임은 손과 인접한 물체에 대한 정확한 3D mesh를 가지고 있습니다.
- 9명, 10개의 인접 물체와 상호작용하여 얻은 데이터로, 총 120만개의 RGB 이미지가 있다.
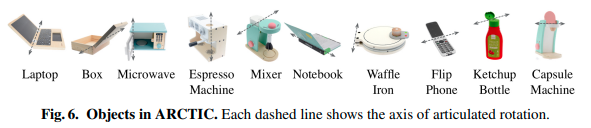
ARTIC dataset에 사용된 물건들(Objects)
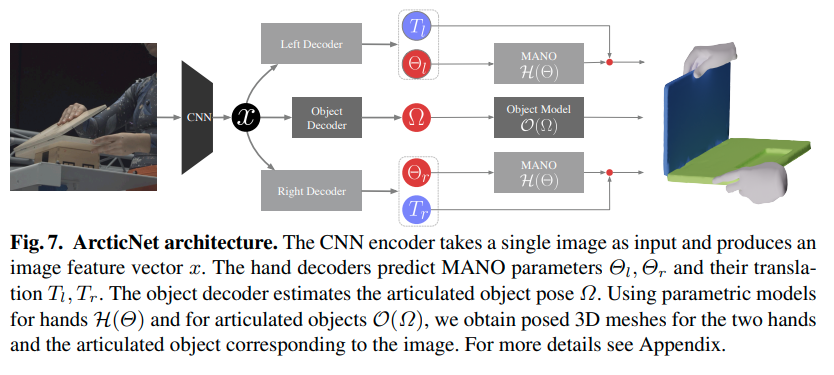
Left, Right hand에 맞게 나누고, Object는 Object Model로 별도로 분리해서 처리한다.
어쩔 수 없는 부분도 있겠지만, ARCTIC의 Object 부분은 10개로 한정되어 있어,
명시된 10개에 포함되지 않는 Object들은 인식이 안되는 점이 아쉽습니다.
이를 보완하기 위해, segmentation이나 2d heatmap, nerf 등
뭔가 다른 방법으로 해결해서 엮으면 더 좋은 결과가 나올 수도 있지 않을까 생각합니다.
3-2) GOAL: Generating 4D Whole-Body Motion for Hand-Object Grasping
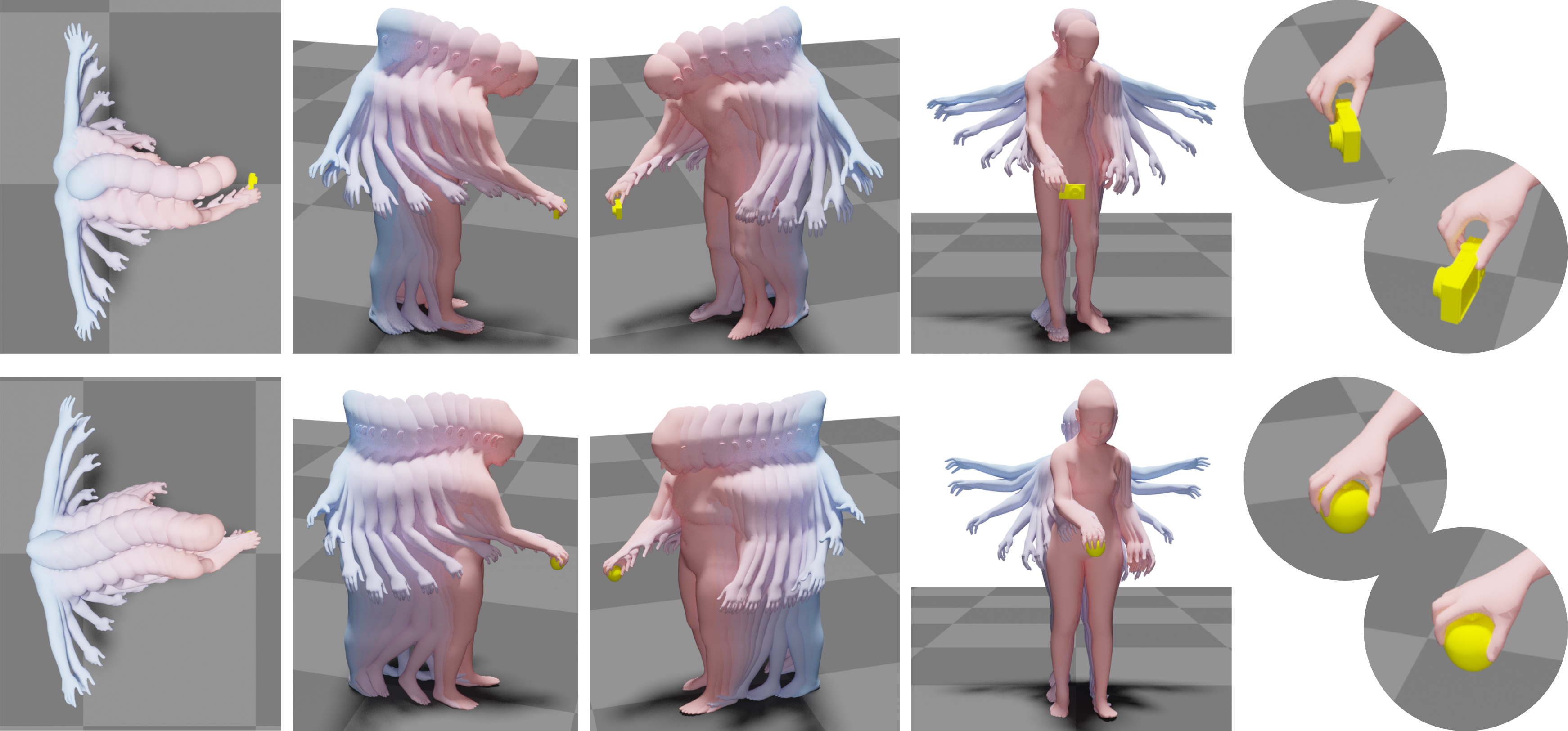
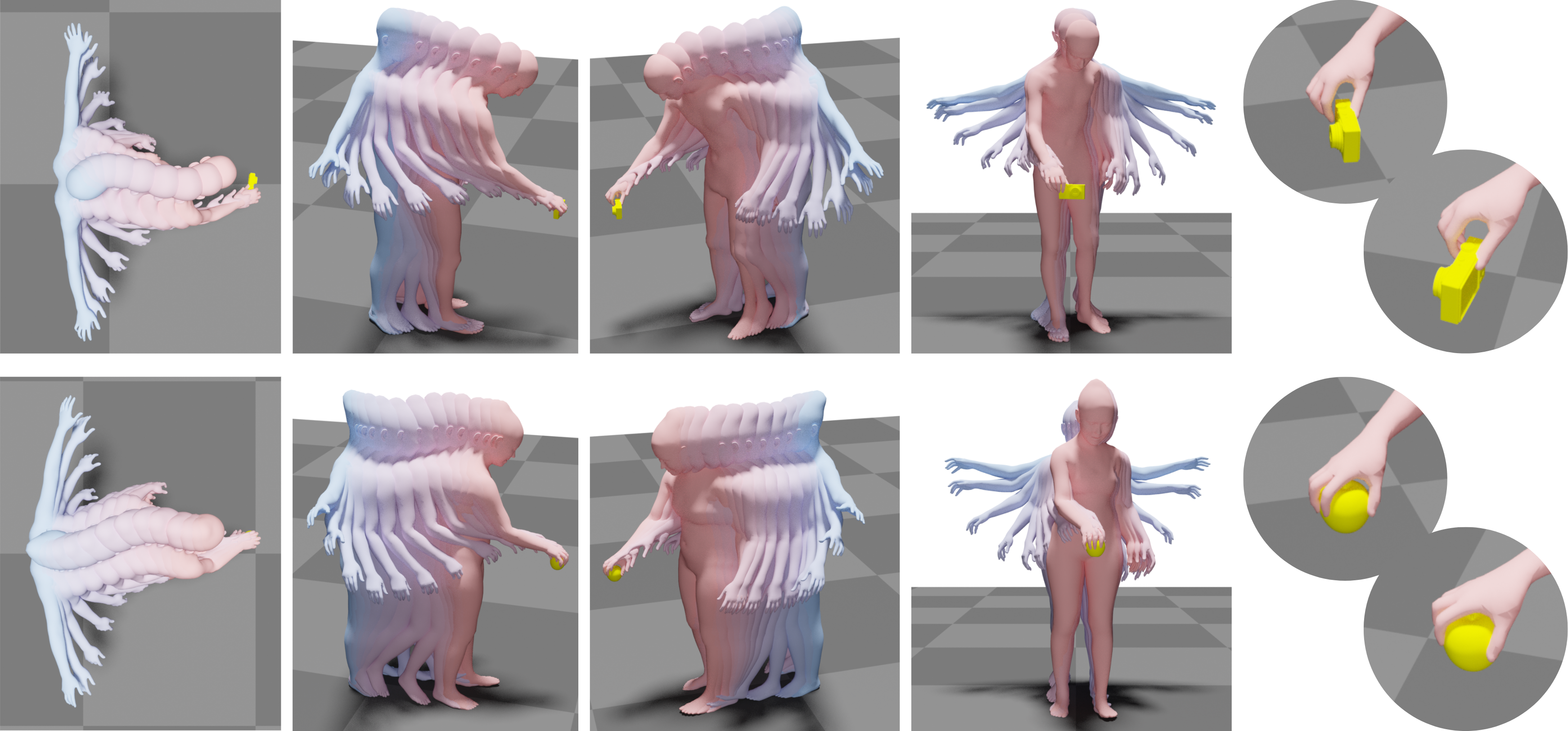
다소 기괴한 이미지입니다만, 논문의 내용을 잘 표현해주고 있습니다.
Whole Body 3D Mesh인데, 손으로 어떤 물체를 잡고 있는 상황을 고려한 모델인 것 같습니다.
손으로 어떤 물체를 잡고 있는 상황을 목표로 하고, 그 사람이 가만히 있을 때를 input으로 해서 물체를 잡게될 때까지의 모션 시퀀스(SMPL-X Body Model)를 생성하는 걸 목표로 하고 있습니다.
input을 다시 정리하면, 다음과 같은 3가지를 받고 있습니다.
1) 3D 물체 1개
2) 1번 물체의 위치, 방향
3) 시작하는 시점의, 사람 신체의 3D body pose, shape
(1번 물체 근처로, 약 0.5~1.5m 이내에 위치하고 물체를 향하고 있도록 설정한다)
summary : 기존의 커뮤니티는 몸이나 손에만 집중했다면, 이 논문은 "시작" object와 human pose가 주어지면, 인간이 물체를 향해 절어가서 물체를 잡기 위한 전신 SMPL-X 모션을 생성하는 방법을 배운다.
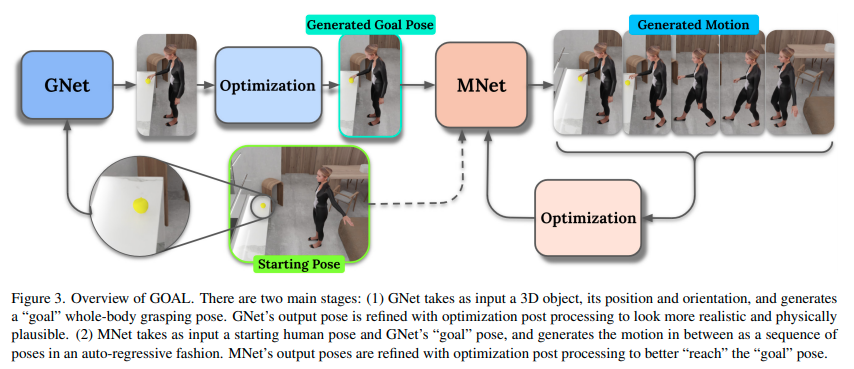
모델은 위의 그림과 같이 GNet과 MNet으로 구분되는데요.
GNet에서는 손과 Object의 interaction을 feature로 캐치해서 더 완성도있는 잡는 자세(목표 자세, GOAL Pose)를 만들도록 하고, MNet에서는 입력으로 받은 시작 자세에서 해당 자세로 가는 모션을 생성하게 됩니다.

출처 : https://www.youtube.com/watch?v=A7b8DYovDZY
GNet의 결과인데요. 위의 유튜브 영상을 보시면 이해가 빠를 것 같습니다.
refine(보정) 전에 비해 손의 위치가 더 자연스러운 걸 볼 수 있습니다.
PS. 넥스트도어에서는 자유로운 3D Body Pose Estimation을 함께 만들어갈 동료를 찾고 있습니다.
올해 엔업(N&UP) 프로그램에 선정되어, NVIDIA와 협업을 진행중입니다.
3D Pose Estimation 분야의 발전에 함께하고 싶다면, 지금 바로 지원해주세요.
지원 링크
