
- Delta Lake 이론 - 🌊 Delta Lake 입문자를 위한 가이드 - 이론편
- Delta Lake 실전 Part 1 - 🌊 Delta Lake 입문자를 위한 가이드 - 실전편(Part 1. 로컬 환경)
- Delta Lake 실전 Part 2 - 🌊 Delta Lake 입문자를 위한 가이드 - 실전편(Part 2. delta-spark 라이브러리 활용)
0. INTRO
- 앞선 글 🌊 Delta Lake 입문자를 위한 가이드 - 실전편(Part 1. 로컬 환경)에서는 Pyspark Docker Container 환경에서 Pyspark를 활용하여 delta 유형의 파일들을 생성하고 다뤄보는 실습을 진행하였습니다.
- 이번 Part 2 실습에서는 세부 내용은 유사하지만, Delta 형식의 데이터를 Spark로 보다 간편하게 다룰 수 있도록 도와주는
delta-spark라이브러리를 활용해보는 내용을 담았습니다. - 실습 환경의 경우
hyunsoolee0506/pyspark-cloud:3.5.1이미지로 컨테이너를 생성하시는 것을 권장드립니다만 이번 실습의 경우는 Google Colab에서 진행해도 무방합니다. - 실습에서는 아래
delta_data.zip파일 안에 있는 두 가지 CSV 파일 데이터를 사용하였습니다.
1️⃣ 기본 환경 세팅
▪ 1) Docker Container 생성
- 사용자의 컴퓨터에서 volume으로 사용할 디렉토리와 컨테이너 내부
/workspace/spark디렉토리가 매핑되도록 설정합니다.
docker run -d \
--name pyspark \
-p 8888:8888 \
-p 4040:4040 \
-v [사용자 디렉토리]:/workspace/spark \
hyunsoolee0506/pyspark-cloud:3.5.1- 위 명령어 실행 후
8888포트로 접속하면 juypter lab 개발 환경에 접속할 수 있습니다.
▪ 2) 라이브러리 설치
- 실습에 필요한 라이브러리들을 설치합니다.
hyunsoolee0506/pyspark-cloud:3.5.1이미지에는 이미 설치되어 있지만 colab의 경우 아래 코드 실행을 통해 라이브러리들을 설치해야 합니다.
pip install pyspark==3.5.1 delta-spark==3.2.0 pyarrow findspark▪ 3) Pyspark delta lake 환경 설정
- https://docs.delta.io/latest/quick-start.html#set-up-apache-spark-with-delta-lake
- pyspark에서 delta lake를 사용하기 위해서 SparkSession 생성시 관련 extension들에 대한 설정을 합니다.
from delta import *
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
builder = SparkSession.builder.appName("DeltaLakeLocal") \
.enableHiveSupport() \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
spark = configure_spark_with_delta_pip(builder).getOrCreate()2️⃣ delta 형식 테이블 생성
▪ 1) 데이터베이스 생성
spark.sql("CREATE DATABASE IF NOT EXISTS deltalake_db")
spark.sql("SHOW DATABASES").show()
---
+------------+
| namespace|
+------------+
| default|
|deltalake_db|
+------------+▪ 2) 일반 테이블 생성
"""
테이블 이름 : trainer
스키마 :
- id → INT
- name → STRING
- age → INT
- hometown → STRING
- prefer_type → STRING
- badge_count → INT
- level → STRING
"""
spark.sql(f"""
CREATE TABLE IF NOT EXISTS deltalake_db.trainer (
id INT,
name STRING,
age INT,
hometown STRING,
prefer_type STRING,
badge_count INT,
level STRING
)
USING csv
OPTIONS (
path '/workspace/spark/deltalake/dataset/trainer_data.csv',
header 'true',
inferSchema 'true',
delimiter ','
)
""")
spark.sql("SHOW TABLES FROM deltalake_db").show()
---
+------------+-------------+-----------+
| namespace| tableName|isTemporary|
+------------+-------------+-----------+
|deltalake_db| trainer| false|
+------------+-------------+-----------+▪ 3) delta 테이블 생성
LOCAL_DELTA_PATH 변수에 delta 테이블이 저장될 디렉토리를 저장합니다. 이 디렉토리는 로컬 디렉토리가 될 수도 있고 s3나 GCS 같은 클라우드 스토리지의 경로가 될 수도 있습니다.
LOCAL_DELTA_PATH = '/workspace/spark/deltalake/delta_local/trainer_delta/'
query = f"""
CREATE TABLE IF NOT EXISTS deltalake_db.trainer_delta (
id INT,
name STRING,
age INT,
hometown STRING,
prefer_type STRING,
badge_count INT,
level STRING
)
USING delta
LOCATION '{LOCAL_DELTA_PATH}'
"""
spark.sql(query)
spark.sql("SHOW TABLES FROM deltalake_db").show()
---
+------------+-------------+-----------+
| namespace| tableName|isTemporary|
+------------+-------------+-----------+
|deltalake_db| trainer| false|
|deltalake_db|trainer_delta| false|
+------------+-------------+-----------+▪ 4) delta 테이블에 데이터 삽입
- CSV로 생성한 일반 테이블의 데이터를
delta테이블에 삽입합니다.
query = """
INSERT INTO deltalake_db.trainer_delta
SELECT * FROM deltalake_db.trainer;
"""
spark.sql(query)
spark.sql('SELECT * FROM deltalake_db.trainer_delta').show(5)
---
+---+-----------+---+--------+-----------+-----------+------------+
| id| name|age|hometown|prefer_type|badge_count| level|
+---+-----------+---+--------+-----------+-----------+------------+
| 1| Brian| 28| Seoul| Electric| 8| Master|
| 2| Sabrina| 23| Busan| Water| 6| Advanced|
| 3| Susan| 18| Gwangju| Rock| 7| Expert|
| 4| Martin| 20| Incheon| Grass| 5| Advanced|
| 5| Gabrielle| 30| Daegu| Flying| 6| Advanced|
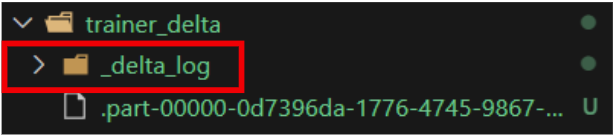
+---+-----------+---+--------+-----------+-----------+------------+- 디렉토리를 확인하면 아래와 같이
_delta_log폴더가 생성된 것을 확인할 수 있습니다.
3️⃣ DeltaTable로 데이터 읽기
▪ 1) delta 형식인지 확인
- 디렉토리에 저장된 파일이
delta형식인지 확인합니다. - 여기서 파라미터에 들어가는
spark는 위에 생성한 SparkSession에 대한 값이 담겨있는 변수입니다.
DeltaTable.isDeltaTable(spark, LOCAL_DELTA_PATH)
---
True▪ 2) delta 테이블 읽기
- delta 테이블을 읽은 방식은 두 가지가 있습니다.
1) 저장된 테이블 이름으로 읽어오기
dt = DeltaTable.forName(spark, "deltalake_db.trainer_delta")2) 테이블이 저장된 경로로 읽어오기
dt = DeltaTable.forPath(spark, LOCAL_DELTA_PATH)▪ 3) DeltaTable을 spark dataframe으로 변환
- 위의 코드로 읽어오게 되면
delta.tables.DeltaTable타입으로 저장됩니다. 따라서 데이터를 조회하기 위해서는 spark dataframe으로 변환 후show()메소드로 조회합니다.
dt.toDF().show(5)
---
+---+---------+---+--------+-----------+-----------+--------+
| id| name|age|hometown|prefer_type|badge_count| level|
+---+---------+---+--------+-----------+-----------+--------+
| 1| Brian| 28| Seoul| Electric| 8| Master|
| 2| Sabrina| 23| Busan| Water| 6|Advanced|
| 3| Susan| 18| Gwangju| Rock| 7| Expert|
| 4| Martin| 20| Incheon| Grass| 5|Advanced|
| 5|Gabrielle| 30| Daegu| Flying| 6|Advanced|
+---+---------+---+--------+-----------+-----------+--------+4️⃣ DeltaTable 형식 테이블 생성
▪ 1) create
delta.tables.DeltaTable타입의 비어있는 테이블을 생성합니다.- create 관련해서는 아래 세 가지 종류가 있는데 활용법이 비슷하므로
create메소드만 실습해보도록 하겠습니다.create: 새로운 DeltaTable을 생성합니다. 테이블이 이미 존재하면 오류가 발생합니다.createIfNotExists: 새로운 DeltaTable을 생성합니다. 테이블이 이미 존재해도 오류가 나지 않습니다.createOrReplace: 새로운 DeltaTable을 생성하거나 동일한 이름의 기존 테이블을 대체합니다.
my_dt = DeltaTable.create(spark) \
.tableName("my_table") \
.addColumn("id", "INT") \
.addColumn("name", "STRING") \
.addColumn("age", "INT") \
.execute()
my_dt.toDF().show()
---
+---+----+---+
| id|name|age|
+---+----+---+
+---+----+---+▪ 2) replace
- 위의
createOrReplace메소드와 비슷하게 기존 DeltaTable을 새로운 스키마의 테이블로 대체할 때 사용합니다.
df = spark.createDataFrame([('Ryan', 31), ('Alice', 27), ('Ruby', 24)], ["name", "age"])
my_dt = DeltaTable.replace(spark) \
.tableName("my_table") \
.addColumns(df.schema) \
.execute()
my_dt.show()
---
+----+---+
|name|age|
+----+---+
+----+---+5️⃣ DeltaTable 업데이트, 삭제, 병합
▪ 1) UPDATE
- dataframe에서 id가 5~10에 해당하는 row의 level 컬럼을 'Delta_Update'로 변경합니다.
dt.update(
condition="id >= 5 AND id <= 10",
set={'level' : "'Delta_Update'"}
)▪ 2) DELETE
prefer_type 컬럼에서 데이터가 `Rock'인 행을 모두 삭제합니다.
dt.delete(
condition="prefer_type = 'Rock'"
)▪ 3) MERGE
merge()는 테이블에 데이터를 upsert(업데이트 또는 삽입)하거나 삭제하는 데 매우 유용한 기능입니다.- merge 메소드의 옵션
whenMatchedDelete: 소스와 대상 테이블의 레코드가 매칭될 때, 해당 레코드를 삭제whenMatchedUpdate: 소스와 대상 테이블의 레코드가 매칭될 때, 해당 레코드를 업데이트whenMatchedUpdateAll: 소스와 대상 테이블의 레코드가 매칭될 때, 모든 컬럼을 소스 데이터로 업데이트whenNotMatchedBySourceDelete: 소스 데이터에 없는 대상 테이블의 레코드를 삭제whenNotMatchedBySourceUpdate: 소스 데이터에 없는 대상 테이블의 레코드를 업데이트whenNotMatchedInsert: 소스 데이터가 대상 테이블에 없는 경우, 새로운 레코드를 삽입whenNotMatchedInsertAll: 소스 데이터가 대상 테이블에 없는 경우, 모든 컬럼을 삽입withSchemaEvolution: 스키마가 변경된 경우(예: 소스 데이터에 새로운 컬럼이 추가됨), 대상 테이블의 스키마를 자동으로 업데이트
1) 대상 테이블과 소스 테이블 생성
# 대상 테이블 → 기존 trainer 테이블에서 5개 행만 추출
dt.delete(
condition="id > 5"
)
# 소스 테이블
data = [
(1, "Brian", 29, "Seoul", "Electric", 9, "GrandMaster"),
(3, "Susan", 19, "Gwangju", "Rock", 8, "Master"),
(7, "Alex", 25, "Jeju", "Fire", 3, "Beginner"),
(8, "Emily", 22, "Ulsan", "Psychic", 5, "Intermediate")
]
columns = ["id", "name", "age", "hometown", "prefer_type", "badge_count", "level"]
source_df = spark.createDataFrame(data, columns)2) merge 작업 수행
source_df테이블 데이터 중 기존dt와 id가 겹치는 행은 업데이트, id가 없는 행은 추가하는 작업을 수행합니다.
dt.alias("target") \
.merge(
source=source_df.alias("source"),
condition="target.id = source.id"
) \
.whenMatchedUpdate(
set={
"name": "source.name",
"age": "source.age",
"hometown": "source.hometown",
"prefer_type": "source.prefer_type",
"badge_count": "source.badge_count",
"level": "source.level"
}
) \
.whenNotMatchedInsert(
values={
"id": "source.id",
"name": "source.name",
"age": "source.age",
"hometown": "source.hometown",
"prefer_type": "source.prefer_type",
"badge_count": "source.badge_count",
"level": "source.level"
}
) \
.execute()
dt.toDF().show()
---
+---+---------+---+--------+-----------+-----------+------------+
| id| name|age|hometown|prefer_type|badge_count| level|
+---+---------+---+--------+-----------+-----------+------------+
| 1| Brian| 29| Seoul| Electric| 9| GrandMaster|
| 2| Sabrina| 23| Busan| Water| 6| Advanced|
| 3| Susan| 19| Gwangju| Rock| 8| Master|
| 4| Martin| 20| Incheon| Grass| 5| Advanced|
| 5|Gabrielle| 30| Daegu| Flying| 6| Advanced|
| 7| Alex| 25| Jeju| Fire| 3| Beginner|
| 8| Emily| 22| Ulsan| Psychic| 5|Intermediate|
+---+---------+---+--------+-----------+-----------+------------+6️⃣ DeltaTable 메타데이터 조회
▪ 1) detail
- Delta 테이블의 상세 정보(스키마, 속성, 메타데이터 등)를 확인할 때 사용합니다.
dt.detail().show(truncate=False)
---
+------+------------------------------------+----+-----------+---------------------------------------------------------+-----------------------+-----------------------+----------------+-----------------+--------+-----------+----------+----------------+----------------+------------------------+
|format|id |name|description|location |createdAt |lastModified |partitionColumns|clusteringColumns|numFiles|sizeInBytes|properties|minReaderVersion|minWriterVersion|tableFeatures |
+------+------------------------------------+----+-----------+---------------------------------------------------------+-----------------------+-----------------------+----------------+-----------------+--------+-----------+----------+----------------+----------------+------------------------+
|delta |e3db23a9-cc4c-4700-95ee-a8b4e06dfbf9|NULL|NULL |file:/workspace/spark/deltalake/delta_local/trainer_delta|2025-03-28 07:31:56.941|2025-04-01 01:15:22.165|[] |[] |1 |3984 |{} |1 |2 |[appendOnly, invariants]|
+------+------------------------------------+----+-----------+---------------------------------------------------------+-----------------------+-----------------------+----------------+-----------------+--------+-----------+----------+----------------+----------------+------------------------+▪ 2) history
- Delta 테이블에 수행된 작업 기록(쓰기, 업데이트, 삭제 등)을 확인할 때 사용합니다.
dt.history().show(truncate=False)
---
+-------+-----------------------+------+--------+------------+-----------------------------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------+-----------------------------------+
|version|timestamp |userId|userName|operation |operationParameters |job |notebook|clusterId|readVersion|isolationLevel|isBlindAppend|operationMetrics |userMetadata|engineInfo |
+-------+-----------------------+------+--------+------------+-----------------------------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------+-----------------------------------+
|3 |2025-04-01 01:15:22.165|NULL |NULL |DELETE |{predicate -> ["(prefer_type#3178 = Rock)"]} |NULL|NULL |NULL |2 |Serializable |false |{numRemovedFiles -> 1, numRemovedBytes -> 3997, numCopiedRows -> 89, numDeletionVectorsAdded -> 0, numDeletionVectorsRemoved -> 0, numAddedChangeFiles -> 0, executionTimeMs -> 789, numDeletionVectorsUpdated -> 0, numDeletedRows -> 1, scanTimeMs -> 494, numAddedFiles -> 1, numAddedBytes -> 3984, rewriteTimeMs -> 294} |NULL |Apache-Spark/3.5.1 Delta-Lake/3.2.0|
|2 |2025-04-01 01:13:45.637|NULL |NULL |UPDATE |{predicate -> ["((id#3174 >= 5) AND (id#3174 <= 10))"]} |NULL|NULL |NULL |1 |Serializable |false |{numRemovedFiles -> 1, numRemovedBytes -> 3980, numCopiedRows -> 84, numDeletionVectorsAdded -> 0, numDeletionVectorsRemoved -> 0, numAddedChangeFiles -> 0, executionTimeMs -> 1604, numDeletionVectorsUpdated -> 0, scanTimeMs -> 984, numAddedFiles -> 1, numUpdatedRows -> 6, numAddedBytes -> 3997, rewriteTimeMs -> 618}|NULL |Apache-Spark/3.5.1 Delta-Lake/3.2.0|
|1 |2025-03-28 07:32:09.347|NULL |NULL |WRITE |{mode -> Append, partitionBy -> []} |NULL|NULL |NULL |0 |Serializable |true |{numFiles -> 1, numOutputRows -> 90, numOutputBytes -> 3980} |NULL |Apache-Spark/3.5.1 Delta-Lake/3.2.0|
|0 |2025-03-28 07:31:57.505|NULL |NULL |CREATE TABLE|{partitionBy -> [], clusterBy -> [], description -> NULL, isManaged -> false, properties -> {}}|NULL|NULL |NULL |NULL |Serializable |true |{} |NULL |Apache-Spark/3.5.1 Delta-Lake/3.2.0|
+-------+-----------------------+------+--------+------------+-----------------------------------------------------------------------------------------------+----+--------+---------+-----------+--------------+-------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------+-----------------------------------+▪ 3) generate
- Delta Lake 테이블의 데이터를 외부 시스템(예: Apache Hive, Presto, Amazon Athena 등)에서 읽을 수 있도록 매니페스트 파일을 생성하는 함수입니다.
generate함수를 실행하면 delta 테이블 디렉토리에_symlink_format_manifest디렉토리가 생성되고, 그 안에 현재 버전의 parquet 파일을 가리키는 메니페스트 파일이 작성됩니다.- Presto, Trino, Amazon Athena, Apache Hive와 같은 엔진은 Delta Lake의 로그 기반 트랜잭션 시스템을 직접 지원하지 않습니다. 하지만
_symlink_format_manifest를 사용하면 delta 테이블을 parquet 파일로 표현한 매니페스트를 제공하므로, 이러한 엔진에서 테이블을 쿼리할 수 있습니다.
dt.generate("symlink_format_manifest")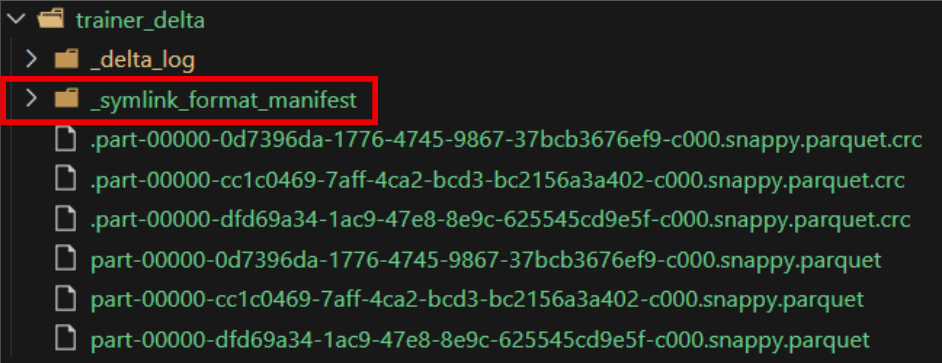
7️⃣ Time Travel 쿼리
- 데이터의 과거 버전을 조회하는 Time Travel 쿼리의 경우 특정 버전을 기준으로 조회하는 경우와 특정 시간(timestamp)을 기준으로 조회하는 경우, 이렇게 두 가지가 가능합니다.
▪ 1) Version
dt.restoreToVersion(1)
dt.toDF().show(10)▪ 2) Timestamp
SEARCH_TIME에 저장된 시간에 존재했던 테이블 모습을 조회합니다.
SEARCH_TIME = '2025-03-28 07:32:00'
dt.restoreToTimestamp(SEARCH_TIME)
dt.toDF().show(10)8️⃣ 파일 상태 최적화
- 작게 나눠서 저장된 parquet 파일들을 합쳐 용량은 크게, 파일 수는 적게 만들어 데이터를 관리합니다. 이 과정을 통해 Delta 테이블의 쿼리 성능을 향상시킬 수 있습니다.
executeZOrderBy옵션은 지정된 컬럼에 대해 Z-Order 클러스터링을 적용하여 데이터를 물리적으로 재배치시킵니다. 쿼리에서 해당 컬럼에 대한 필터링이나 조인이 빈번할 때 효과적입니다.
▪ 1) OPTIMIZE
# 표준 최적화 방법
dt.optimize().executeCompaction()
# 특정 컬럼을 대상으로 최적화
dt.optimize().executeZOrderBy('level')▪ 2) VACUUM
- 더 이상 필요 없는 오래된 데이터 버전을 삭제하여 저장 공간을 확보할 때 사용합니다.
- 기본은 7일(168시간)이며,
retentionHours파라미터를 통해 특정 시간 이후의 데이터를 지우도록 할 수 있습니다.
dt.vacuum(
retentionHours=10
)9️⃣ Parquet to Delta 변환
▪ 1) parquet 파일 저장
trainer_data.csv파일을 읽어와 테이블과 경로에parquet타입으로 저장합니다.
# 1. CSV 파일을 DataFrame으로 읽기
DATA_PATH = '/workspace/spark/deltalake/dataset/trainer_data.csv'
SAVE_PATH = '/workspace/spark/deltalake/delta_local/spark-warehouse/trainer_parquet/'
df = spark.read.csv(DATA_PATH, header=True, inferSchema=True)
# 2. 테이블 생성
query = f"""
CREATE TABLE IF NOT EXISTS deltalake_db.trainer_parquet (
id INT,
name STRING,
age INT,
hometown STRING,
prefer_type STRING,
badge_count INT,
level STRING
)
USING parquet
LOCATION '{SAVE_PATH}'
"""
spark.sql(query)
# 3. DataFrame을 테이블과 경로에 저장
df.write.mode("overwrite") \
.option("path", SAVE_PATH) \
.saveAsTable("deltalake_db.trainer_parquet")▪ 2) delta로 변환
# 저장된 테이블을 delta로 변환
DeltaTable.convertToDelta(spark, "deltalake_db.trainer_parquet")
# 디렉토리에 저장된 파일 데이터를 delta로 변환
DeltaTable.convertToDelta(spark, f"parquet.`{SAVE_PATH}`")참고자료

데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD