
- Delta Lake 이론 - 🌊 Delta Lake 입문자를 위한 가이드 - 이론편
- Delta Lake 실전 Part 1 - 🌊 Delta Lake 입문자를 위한 가이드 - 실전편(Part 1. 로컬 환경)
- Delta Lake 실전 Part 2 - 🌊 Delta Lake 입문자를 위한 가이드 - 실전편(Part 2. delta-spark 라이브러리 활용)
0. INTRO
- 앞선 글 🌊 Delta Lake 입문자를 위한 가이드 - 이론편에서는 Delta Lake에 대한 이론적인 내용을 상세하게 다루어 보았습니다. 이번 글에서는 Pyspark Docker Container 환경에서 Delta Lake의 기능을 실습해보도록 하겠습니다.
- 이번 실습에서는 데이터를 다루는 도구로 Pyspark를 사용하며, delta 유형의 파일들은 로컬 디렉토리에 저장되어 관리됩니다.
- 도커 컨테이너의 경우 이후 클라우드 환경을 연동한 실습까지 고려하였을 때 제가 따로 생성한
hyunsoolee0506/pyspark-cloud:3.5.1이미지로 생성하시는 것을 권장드립니다. 하지만 이번 로컬 환경 실습의 경우는 Google Colab에서 진행해도 무방합니다. - 실습에서는 아래
delta_data.zip파일 안에 있는 두 가지 CSV 파일 데이터를 사용하였습니다.
1️⃣ 실습 환경 설정
▪ 1) Docker Container 생성
- 사용자의 컴퓨터에서 volume으로 사용할 디렉토리와 컨테이너 내부
/workspace/spark디렉토리가 매핑되도록 설정합니다.
docker run -d \
--name pyspark \
-p 8888:8888 \
-p 4040:4040 \
-v [사용자 디렉토리]:/workspace/spark \
hyunsoolee0506/pyspark-cloud:3.5.1- 위 명령어 실행 후
8888포트로 접속하면 juypter lab 개발 환경으로 들어올 수 있습니다.
▪ 2) 라이브러리 설치
- 실습에 필요한 라이브러리들을 설치합니다.
hyunsoolee0506/pyspark-cloud:3.5.1이미지에는 이미 설치되어 있지만 colab의 경우 아래 코드 실행을 통해 라이브러리들을 설치해야 합니다.
pip install pyspark==3.5.1 delta-spark==3.2.0 pyarrow findspark▪ 3) Pyspark delta lake 환경 설정
- https://docs.delta.io/latest/quick-start.html#set-up-apache-spark-with-delta-lake
- pyspark에서 delta lake를 사용하기 위해서 SparkSession 생성시 관련 extension들에 대한 설정을 합니다.
from delta import *
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
builder = SparkSession.builder.appName("DeltaLakeLocal") \
.enableHiveSupport() \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
spark = configure_spark_with_delta_pip(builder).getOrCreate()2️⃣ 데이터베이스 및 테이블 생성
▪ 1) 데이터베이스 생성
deltalake_db라는 이름의 새로운 데이터베이스를 생성합니다.
spark.sql("CREATE DATABASE IF NOT EXISTS deltalake_db")
spark.sql("SHOW DATABASES").show()
---
+------------+
| namespace|
+------------+
| default|
|deltalake_db|
+------------+▪ 2) csv 타입 테이블 생성
trainer_data.csv파일의 데이터가 저장될trainer테이블을 생성합니다.
- 테이블 이름 : trainer
- 스키마 :
- id → INT
- name → STRING
- age → INT
- hometown → STRING
- prefer_type → STRING
- badge_count → INT
- level → STRINGquery = f"""
CREATE TABLE IF NOT EXISTS deltalake_db.trainer (
id INT,
name STRING,
age INT,
hometown STRING,
prefer_type STRING,
badge_count INT,
level STRING
)
USING csv
OPTIONS (
path '[trainer_data.csv 파일 경로]',
header 'true',
inferSchema 'true',
delimiter ','
)
"""
spark.sql(query)
# 테이블 생성 확인
spark.sql("SHOW TABLES FROM deltalake_db").show()
---
+------------+---------+-----------+
| namespace|tableName|isTemporary|
+------------+---------+-----------+
|deltalake_db| trainer| false|
+------------+---------+-----------+3️⃣ delta 타입 테이블 생성
- 기존에 있는
csv파일의 데이터를 바로delta유형의 테이블 생성과 동시에 넣을 수는 없기 때문에 아래와 같이 두 단계를 거쳐delta테이블을 생성하여야 합니다.delta유형 빈 테이블 생성delta테이블에csv테이블 데이터 삽입
▪ 1) 테이블 생성
trainer_delta라는 이름의delta테이블을 생성합니다./workspace/spark/deltalake/delta_local/trainer_delta/해당 경로 아래에delta테이블 관련 데이터가 저장되도록 설정하였습니다.
query = f"""
CREATE TABLE IF NOT EXISTS deltalake_db.trainer_delta (
id INT,
name STRING,
age INT,
hometown STRING,
prefer_type STRING,
badge_count INT,
level STRING
)
USING delta
LOCATION '/workspace/spark/deltalake/delta_local/trainer_delta/'
"""
spark.sql(query)▪ 2) 데이터 삽입
- 위에서 생성하였던
trainer테이블의 데이터를trainer_delta테이블에 삽입합니다.
query = """
INSERT INTO deltalake_db.trainer_delta
SELECT * FROM deltalake_db.trainer;
"""
spark.sql(query)- 데이터 삽입이 완료가 되면 delta 테이블 디렉토리에
_delta_log/폴더와 parquet 파일이 새롭게 생성이 된 것을 확인해볼 수 있습니다.

4️⃣ delta 타입 테이블 읽기
- pyspark에서는 조금씩 다른 방식으로 저장된 테이블을 읽어올 수 있습니다.
▪ 1) spark에서 기본 읽기
LOCAL_DELTA_PATH = '/workspace/spark/deltalake/delta_local/trainer_delta'
df = spark.read.format("delta").load(LOCAL_DELTA_PATH)
df.show(5)
---
+---+------+---+--------+-----------+-----------+------------+
| id| name|age|hometown|prefer_type|badge_count| level|
+---+------+---+--------+-----------+-----------+------------+
| 1| Brian| 28| Seoul| Electric| 8| Master|
| 3| Susan| 18| Gwangju| Rock| 7| Expert|
| 6| Vicki| 17| Daejeon| Ice| 4|Intermediate|
| 9|Olivia| 45| Incheon| Psychic| 3|Intermediate|
| 10| Mark| 16| Gangwon| Fire| 4|Intermediate|
+---+------+---+--------+-----------+-----------+------------+
only showing top 5 rows▪ 2) delta.으로 읽기
query = f"SELECT * FROM delta.`{LOCAL_DELTA_PATH}`"
spark.sql(query)▪ 3) hive catalog에서 읽기
spark.table('deltalake_db.trainer_delta')5️⃣ 테이블 수정 후 저장
- 이번에는 테이블 내용을 수정하여 기존에 저장되어 있던 디렉토리에 덮어쓰는 과정을 진행합니다. 이후에 있을 테이블 변경 이력 조회나 delta lake의 핵심 기능인 Time Travel 쿼리를 실습해보기 위한 과정입니다.
▪ 1) 'Beginner' 제외 후 저장
# Beginner 제외한 dataframe 생성
df_1 = df.filter(F.col('level') != 'Beginner')
# 기존 경로에 덮어쓰기
df_1.write \
.format('delta') \
.mode('overwrite') \
.save(LOCAL_DELTA_PATH)
# 데이터 확인
df = spark.read.format("delta").load(LOCAL_DELTA_PATH)
df.select('level').distinct().show()
---
+------------+
| level|
+------------+
| Expert|
| Advanced|
| Master|
|Intermediate|
+------------+▪ 2) 'Advanced' 제외 후 저장
# Advanced 제외한 dataframe 생성
df_2 = df_1.filter(F.col('level') != 'Advanced')
# 기존 경로에 덮어쓰기
df_2.write \
.format('delta') \
.mode('overwrite') \
.save(LOCAL_DELTA_PATH)
# 데이터 확인
df = spark.read.format("delta").load(LOCAL_DELTA_PATH)
df.select('level').distinct().show()
---
+------------+
| level|
+------------+
| Expert|
| Master|
|Intermediate|
+------------+- 데이터가 덮어씌워짐에 따라 parquet 파일이 추가되고,
_delta_log/폴더 내에 메타데이터(.json파일) 역시 추가되는 것을 확인할 수 있습니다.
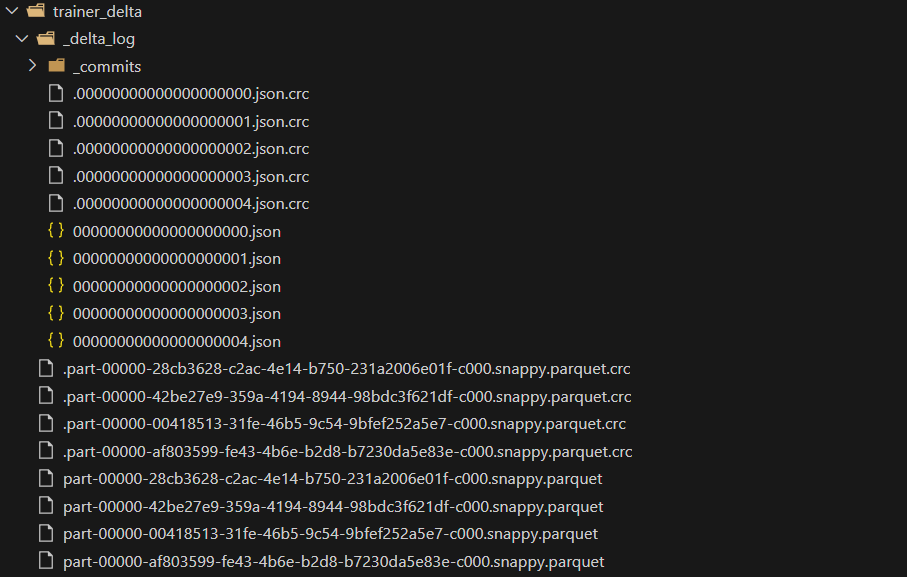
6️⃣ 변경 이력(history) 조회 및 Time Travel 쿼리
▪ 1) History 조회
delta테이블에 대한 변경 이력을 조회합니다.- 현재까지 테이블은 처음 생성(CREATE) 후 WRITE 가 총 3번 발생한 구조입니다. 따라서 version 역시 0,1,2,3 이렇게 존재합니다.
- VERSION 0 →
trainer_delta테이블 생성 상태, 데이터 X - VERSION 1 →
trainer테이블에서 데이터 삽입된 최초 상태 - VERSION 2 → 'Beginner' 행 제외 후 저장된 상태
- VERSION 3 → Advanced' 행 제외 후 저장된 상태
- VERSION 0 →
query = "DESCRIBE HISTORY deltalake_db.trainer_delta"
spark.sql(query).show(vertical=True, truncate=False)
---
-RECORD 0--------------------------------------------------------------------------------------------------------------
version | 3
timestamp | 2025-03-21 02:09:39.085
userId | NULL
userName | NULL
operation | WRITE
operationParameters | {mode -> Overwrite, partitionBy -> []}
job | NULL
notebook | NULL
clusterId | NULL
readVersion | 2
isolationLevel | Serializable
isBlindAppend | false
operationMetrics | {numFiles -> 1, numOutputRows -> 42, numOutputBytes -> 3125}
userMetadata | NULL
engineInfo | Apache-Spark/3.5.1 Delta-Lake/3.2.0
-RECORD 1--------------------------------------------------------------------------------------------------------------
version | 2
timestamp | 2025-03-21 02:08:32.646
userId | NULL
userName | NULL
operation | WRITE
operationParameters | {mode -> Overwrite, partitionBy -> []}
job | NULL
notebook | NULL
clusterId | NULL
readVersion | 1
isolationLevel | Serializable
isBlindAppend | false
operationMetrics | {numFiles -> 1, numOutputRows -> 85, numOutputBytes -> 3868}
userMetadata | NULL
engineInfo | Apache-Spark/3.5.1 Delta-Lake/3.2.0
-RECORD 2--------------------------------------------------------------------------------------------------------------
version | 1
timestamp | 2025-03-21 01:46:21.446
userId | NULL
userName | NULL
operation | WRITE
operationParameters | {mode -> Append, partitionBy -> []}
job | NULL
notebook | NULL
clusterId | NULL
readVersion | 0
isolationLevel | Serializable
isBlindAppend | true
operationMetrics | {numFiles -> 1, numOutputRows -> 90, numOutputBytes -> 3980}
userMetadata | NULL
engineInfo | Apache-Spark/3.5.1 Delta-Lake/3.2.0
-RECORD 3--------------------------------------------------------------------------------------------------------------
version | 0
timestamp | 2025-03-21 01:43:25.471
userId | NULL
userName | NULL
operation | CREATE TABLE
operationParameters | {partitionBy -> [], clusterBy -> [], description -> NULL, isManaged -> false, properties -> {}}
job | NULL
notebook | NULL
clusterId | NULL
readVersion | NULL
isolationLevel | Serializable
isBlindAppend | true
operationMetrics | {}
userMetadata | NULL
engineInfo | Apache-Spark/3.5.1 Delta-Lake/3.2.0 ▪ 2) Time Travel - Version
- 테이블 변경시마다 부여된 버전 번호를 기반으로 특정 버전에 해당하는 테이블의 내용을 불러옵니다.
👉 최초 버전(version 0) 테이블 불러오기
df_pre = spark.read \
.format("delta") \
.option("versionAsof", 0) \
.load(LOCAL_DELTA_PATH)
df_pre.select('level').distinct().show()
---
+-----+
|level|
+-----+
+-----+👉 version 2 테이블 불러오기
df_pre = spark.read \
.format("delta") \
.option("versionAsof", 2) \
.load(LOCAL_DELTA_PATH)
df_pre.select('level').distinct().show()
---
+------------+
| level|
+------------+
| Expert|
| Advanced|
| Master|
|Intermediate|
+------------+👉 SQL로 Time Travel 쿼리하기
df_pre = spark.sql("SELECT * FROM deltalake_db.trainer_delta VERSION AS OF 3")
df_pre.select('level').distinct().show()
---
+------------+
| level|
+------------+
| Expert|
| Master|
|Intermediate|
+------------+▪ 3) Time Travel - Timestamp
- 테이블 변경 시간을 기준으로 조회하는 방법으로, 지정한 시간(TIMESTAMP) 기준으로 해당 시점에 존재했던 Delta 테이블의 상태(버전)를 조회합니다.
👉 지정한 시간대의 테이블 상태 불러오기
TABLE_TIMESTAMP = "2025-03-21T02:09:00"
spark.read.format("delta") \
.option("timestampAsOf", TABLE_TIMESTAMP) \
.table("deltalake_db.trainer_delta")👉 SQL로 지정 시간대의 테이블 불러오기
TABLE_TIMESTAMP = "2025-03-21T02:09:00"
spark.sql(f"SELECT * FROM deltALake_db.trainer_delta TIMESTAMP AS OF '{TABLE_TIMESTAMP}'")7️⃣ 스키마 변경 작업
- Delta Lake는 기존 테이블 스키마와 다른 데이터를 쓰려고 하면 에러가 나도록 하는 '스키마 강제(Strict Schema Enforcement)' 옵션을 사용합니다. 따라서 기존 작업하던 테이블의 스키마 변경이 일어났다면, 특정 옵션을 추가해주어야 덮어쓰기가 가능합니다.
- 실습 내용은 아래와 같습니다.
- 기존 컬럼 : ['id', 'name', 'age', 'hometown', 'prefer_type', 'badge_count', 'level']
- 변경된 테이블 컬럼 : ['id', 'name', 'age', 'hometown', 'prefer_type', 'badge_count', 'level', 'dummy_col']
👉 'dummy_col' 이라는 컬럼이 추가되어 스키마가 변경된 테이블 덮어쓰기▪ 1) 표준 쓰기 - 작업 실패
LOCAL_DELTA_PATH = '/workspace/spark/deltalake/delta_local/trainer_delta'
# 테이블 불러오기
df = spark.table("deltalake_db.trainer_delta")
# 'dummy_col' 컬럼 추가
df_diff = df.withColumn('dummy_col', F.lit(1))
# 스키마 합치기 시도
df_diff.write \
.format('delta') \
.mode('overwrite') \
.save(LOCAL_DELTA_PATH)
# 덮어쓰려는 테이블의 스키마가 달라 아래의 에러 발생
# 👇👇👇👇👇
---
AnalysisException: [_LEGACY_ERROR_TEMP_DELTA_0007] A schema mismatch detected when writing to the Delta table (Table ID: 31dbae5e-d042-467b-9454-e483fdad97bb).
To enable schema migration using DataFrameWriter or DataStreamWriter, please set:
'.option("mergeSchema", "true")'.
For other operations, set the session configuration
spark.databricks.delta.schema.autoMerge.enabled to "true". See the documentation
specific to the operation for details.
Table schema:
root
-- id: integer (nullable = true)
-- name: string (nullable = true)
-- age: integer (nullable = true)
-- hometown: string (nullable = true)
-- prefer_type: string (nullable = true)
-- badge_count: integer (nullable = true)
-- level: string (nullable = true)
Data schema:
root
-- id: integer (nullable = true)
-- name: string (nullable = true)
-- age: integer (nullable = true)
-- hometown: string (nullable = true)
-- prefer_type: string (nullable = true)
-- badge_count: integer (nullable = true)
-- level: string (nullable = true)
-- dummy_col: integer (nullable = true)
To overwrite your schema or change partitioning, please set:
'.option("overwriteSchema", "true")'.
Note that the schema can't be overwritten when using
'replaceWhere'.▪ 2) 스키마 합치기 옵션과 함께 쓰기
- 스키마가 다른 테이블을 덮어쓰기 위해서는
option("mergeSchema", "true")옵션을 추가해주어야 합니다.
df_diff.write \
.format('delta') \
.mode('overwrite') \
.option("mergeSchema", "true") \
.save(LOCAL_DELTA_PATH)8️⃣ 파일 상태 최적화
-
https://docs.databricks.com/aws/en/sql/language-manual/delta-optimize
-
Delta 테이블은 기본적으로 계속 파일이 적재되는 형식이기 때문에 시간이 지남에 따라 작은 파일들이 많이 생기게 됩니다. 이렇게 되면 쿼리 성능 저하와 읽기 오버헤드 증가가 발생합니다. 이 때 OPTIMIZE를 통해 데이터를 큰 파일로 병합하여 성능을 향상시킬 수 있습니다.
최적화 방식 설명 기본 Optimize 작은 파일 병합, 읽기 성능 향상 Z-Ordering 자주 필터링하는 컬럼 기준 정렬 → 스캔 줄여 쿼리 성능 향상 파티션 기반 Optimize 특정 날짜/지역 등 자주 조회되는 파티션만 선택적 최적화
▪ 1) 표준 최적화
- delta lake가 기본적으로 수행하는 표준 최적화 방식을 적용합니다.
query = "OPTIMIZE deltalake_db.trainer_delta"
spark.sql(query)▪ 2) Z-Ordering 최적화
- 특정 컬럼 기준으로 데이터의 물리적 저장 순서를 최적화하는 기능.
- 자주 필터링하는 컬럼을 기준으로 Z-Order를 걸면 쿼리시 불필요한 파일 스캔을 줄일 수 있습니다.
query = """
OPTIMIZE deltalake_db.trainer_delta
ZORDER BY (trainer_id, region)
"""
spark.sql(query)▪ 3) 파티션 최적화
- 전체 테이블을 대상으로 최적화하지 않고, 파티셔닝된 특정 범위의 데이터만 병합합니다.
query = """
OPTIMIZE deltalake_db.trainer_delta
WHERE level = 'Master'
"""
spark.sql(query)9️⃣ 과거 데이터 삭제(VACUUM)
- https://docs.databricks.com/aws/en/sql/language-manual/delta-vacuum
- Delta Lake는 데이터의 수정이나 삭제 등이 발생하더라도 과거의 parquet 파일들은 다 남아있게 됩니다.
- 과거 버전의 파일들을 더 이상 사용하지 않는데 계속 남겨놓는 것은 낭비이기 때문에 VACUUM 기능을 활용하여 특정 기간 이전의 데이터를 삭제하는 작업을 수행할 수 있습니다.
delta유형의 데이터의 경우 과거의 파일 데이터를 지울 때는 디렉토리에서 직접 삭제하면 안되고VACUUM명령을 통해 지워야 테이블의 정합성을 해치지 않고 이후에도 원활한 작업이 가능해집니다.VACUUM작업 발생시 삭제된 날짜 이전으로는 Time Travel 하여 조회하는 것이 불가능해집니다.- 파일의 기본 유지 기간은 168시간(7일)이며, spark config 수정을 통해 유지 기간을 조정할 수 있습니다.
▪ 1) 기본 유지 기간 설정 해제
- spark에 기본적으로 설정되어 있는 설정을 해제해 주어야 retention 기간을 커스텀하게 관리할 수 있습니다.
# 설정 확인
spark.conf.get("spark.databricks.delta.retentionDurationCheck.enabled")
-> 'true'
# 유지 기간 설정 해제
spark.conf.set("spark.databricks.delta.retentionDurationCheck.enabled", "false")▪ 2) VACUUM 명령어 실행
- 사용자가 지정한 기간 이전에 생성된 parquet 파일은 삭제하도록
VACUUM명령을 수행합니다. DRY RUN옵션은 실제로 작업은 되지 않도록 하는 설정입니다.
# 기본 VACUUM 명령 (168시간 이전의 파일 삭제)
spark.sql("VACUUM deltalake_db.trainer_delta").show(truncate=False)
# 현재 버전 이전의 파일들 삭제
spark.sql("VACUUM deltalake_db.trainer_delta RETAIN 0 HOURS DRY RUN").show(truncate=False)
# 2일 이전의 파일들 삭제
spark.sql("VACUUM deltalake_db.trainer_delta RETAIN 2 DAYS DRY RUN").show(truncate=False)▪ 3) 테이블 생성시 유지 기간 설정
delta유형 테이블 생성시 기본 retention 기간을 설정합니다.
query = f"""
CREATE TABLE IF NOT EXISTS deltalake_db.trainer_delta_2 (
id INT,
name STRING,
age INT,
hometown STRING,
prefer_type STRING,
badge_count INT,
level STRING
)
USING delta
LOCATION '/workspace/spark/deltalake/delta_local/trainer_delta_2/'
TBLPROPERTIES ('delta.deletedFileRetentionDuration' = 'interval 2 days');
"""
spark.sql(query)🔟 Parquet to Delta 변환
- https://docs.databricks.com/aws/en/sql/language-manual/delta-convert-to-delta
parquet형태로 저장되어 있던 데이터를delta유형의 테이블 데이터로 변환하는 기능입니다.
▪ 1) 일반 parquet 데이터 변환
👉 fish_data.csv 데이터를 parquet으로 저장합니다.
# csv 파일 읽어오기
fish = spark.read.option('header', 'true').csv('fish_data.csv')
# 로컬 디렉토리 저장 + Catalog 저장
fish.write \
.mode('overwrite') \
.format('parquet') \
.option('path', '/workspace/spark/deltalake/delta_local/fish_parquet/') \
.saveAsTable('deltalake_db.fish_parquet')👉 parquet으로 저장되어 있던 데이터를 delta로 변환
query = """
CONVERT TO DELTA
parquet.`/workspace/spark/deltalake/delta_local/fish_parquet/`
"""
spark.sql(query)▪ 2) 파티션 된 parquet 데이터 변환
👉 Species 컬럼으로 파티션 된 parquet 데이터 쓰기
fish_df.write.mode('overwrite')\
.format('parquet') \
.partitionBy('Species') \
.option('path', '/workspace/spark/deltalake/delta_local/fish_parquet_partitioned/') \
.saveAsTable('deltalake_db.fish_parquet_partitioned')👉 파티션 된 parquet 데이터를 delta로 변환
query = """
CONVERT TO DELTA
parquet.`/workspace/spark/deltalake/delta_local/fish_parquet_partitioned/`
PARTITIONED BY (Species STRING)
"""
spark.sql(query)참고자료

데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD
안녕하세요 좋은 글 잘봤습니다. 질문이 하나 있는데, 스키마를 강제병합하는 것 까지는 이해햇는데, 기존 데이터를 보존하면서 migration 할 때도 이 방식이 가능한건가요?