저번에 다뤘던 LSTM과 같은 모델들로 Sequential data를 다루기 시작하며, sequence generator에 대한 연구들이 이루어지기 시작했다. sequence generator란 말 그대로 sequence를 생성하는 모델들인데, 주로 sequence를 입력으로 받고 결과물로 sequence를 생성한다. 가장 대표적인 예로는 translation task가 있다. input으로 문장이 들어가고, output으로 생성된 문장이 나오게 되는 형태이다. 기존 RNN 구조의 모델에서도 이런 sequence generator를 만드는 것은 가능하다. 흔히 이야기 하는 encode-decoder 형태를 차용해 input sentence에 대한 하나의 대표값을 만들어내고 그것을 다시 decoder를 활용해 문장을 생성해내는 것이다. 하지만 이런 RNN을 활용한 모델들은 sequential하게 계산이 이루어지기 때문에 병렬화가 불가능하고 오랜 시간이 걸린다는 단점이 있다. 그리고 이를 해결하기 위해 Transformer라는 모델이 등장했다.
Transformer
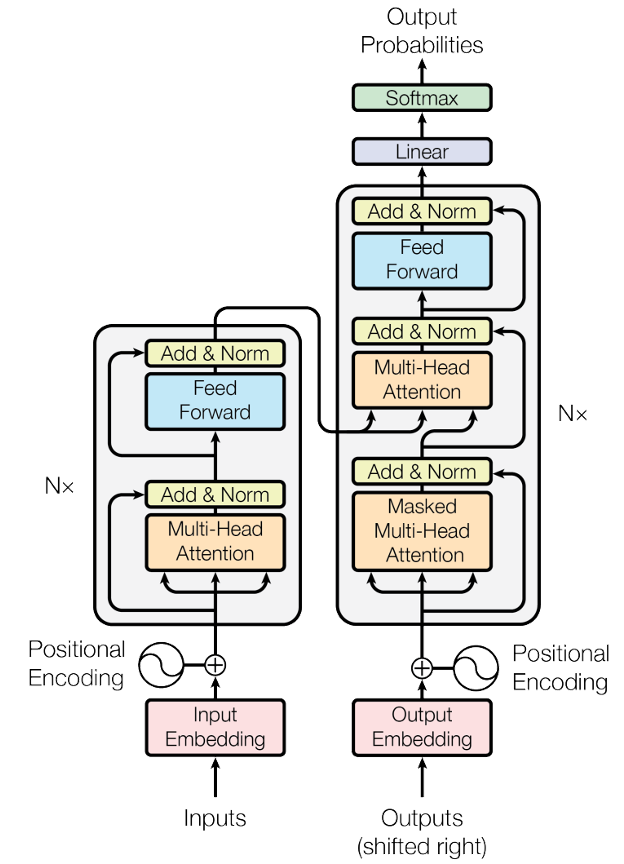
트랜스포머는 앞에서 언급했듯 sequence generator를 위한 encode-decoder 구조의 접근이다. 그리고 각각의 유닛에서 새로운 형태의 어텐션 매커니즘을 활용한다. 이러한 구조를 활용해 번역이 된 다음 단어들을 예측하는 형식으로 모델이 작동하게 된다.
Attention Mechanism
트랜스포머에 대해서 설명할 때 어텐션에 대한 설명 없이는 이루어질 수 없기에 우선 어텐션에 대해 설명해보고자 한다.
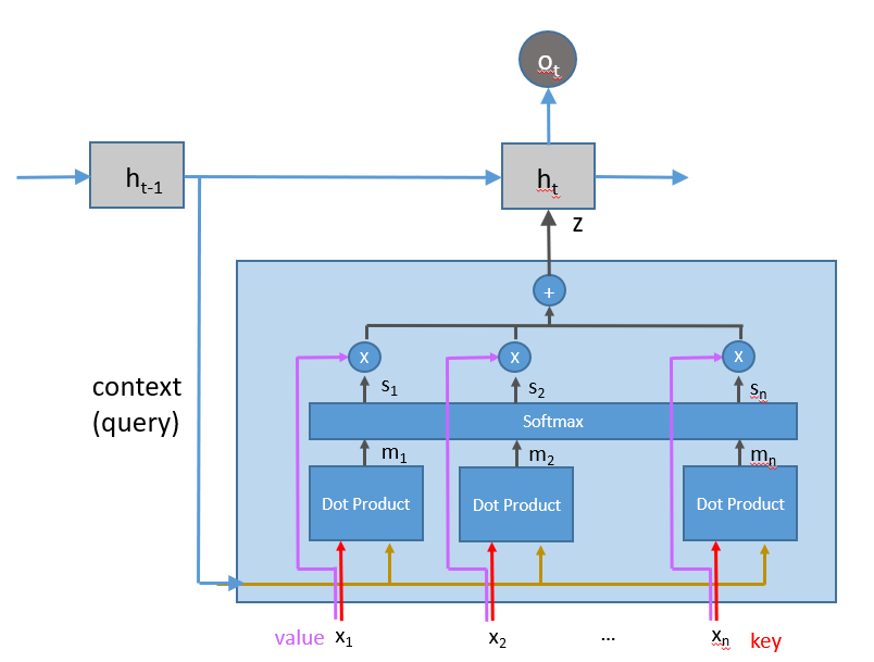
위 그림은 RNN과 결합된 형태의 어텐션 모듈이다. 가운데 박스에서 연산이 이루어져 z값을 전달해주는 것이 어텐션 모듈이라고 보면 될 것 같다. 이전의 RNN과 무엇이 다르냐고 하면 어텐션 모듈에서는 input x에 대해서 모두 고려한다는 것이 가장 큰 차이점이라고 할 수 있다. 기존의 RNN은 해당 time step에서의 만을 전달하는 형태라면 어텐션에서는 input값 모두와의 내적 계산을 통해 반영될 정도를 softmax로 계산하여 전달한다고 할 수 있다. 그래서 기존 original dot-product attention은 의 식을 가진다. 어텐션은 Query, Key, Value를 입력값으로 받게 되고 Value에 대한 값을 Query, Key 유사도 계산을 통해 조작을 가해 전달하는 거라고 직관적으로 이해할 수 있을 것 같다. 기존의 어텐션 수식에서 트랜스포머에서는 dimension의 크기로 나누는 scaled dot-product attention을 사용해 dimension의 크기가 내적의 결과에 끼치는 영향을 조절한다.
Self-Attention
트랜스포머에서는 기존의 어텐션을 약간 다른 형태로 활용하게 되고, 이를 Self-Attention이라는 구조로 설명할 수 있다. 사실 기존의 어텐션과 달라지는 점은 Queyr, Key, Value가 모두 X로 들어간다는 점 뿐이다. 즉 가 적용되는 것이라고 할 수 있다. 이러한 구조를 활용해 아래 그림에서 보는 것처럼 input sentence에 대한 정보를 input에 대한 정보를 바탕으로 재구성하여 전달할 수 있다. 그리고 sequence에 대한 길이가 증가하더라도 차례대로 계산이 진행되는 것이 아니라 모든 input의 구성요소에 대해 한꺼번에 연산이 이루어지기에 long-range dependency를 학습하고, 병렬적 계산 또한 가능해진다.
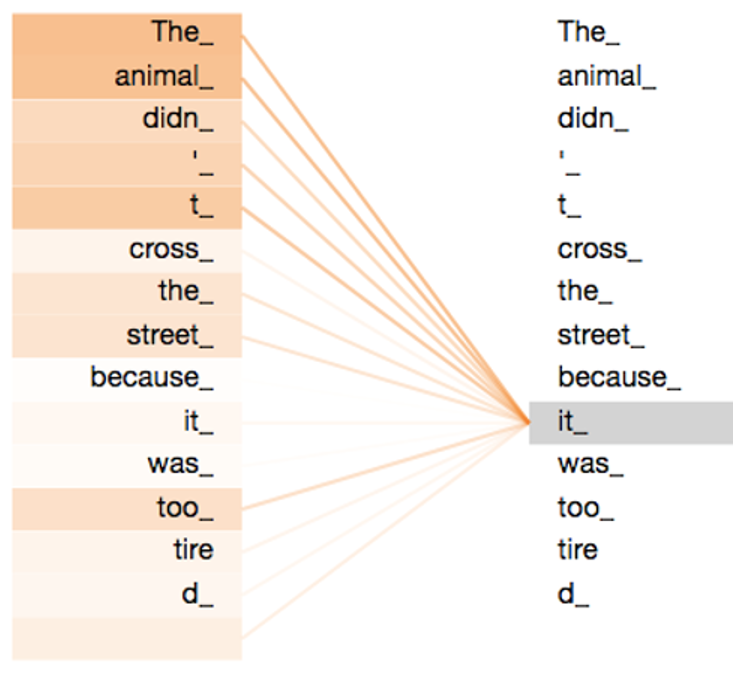
위 그림에서 보이는 것처럼 해당 문장에서 it이라는 요소가 어떤 요소들과 관계가 있는지를 계산해서 재구성하여 같은 뜻의 문장을 전달하지만 조금 더 다양한 정보가 포함된 형태로 재구성 되는 것이라고 생각할 수 있다.
Multi-head Attention
그리고 트랜스포머에서 활용된 또 다른 형태의 어텐션은 Multi-head Attention이다. 조금 단순히 생각해보자면 어텐션 연산 자체를 같은 Q, K, V에 대해서 여러번 진행하는 것이라고 할 수 있다. 수식으로는 로 구성이 되며 W를 head라고 생각하면 된다. 결국은 Q, K, V에 대해서 여러 형태로 가중치를 주는 것이고 이를 다양한 view point 즉 관점이라고 할 수 있다. 즉 다양한 관점으로 Q, K, V를 구성해 어텐션 연산을 진행하고 해당 값들을 합쳐서 해당 view point들의 정보가 포함된 임베딩을 구성하게 된다.
Attentions in Transformer
이런 어텐션 유닛들을 트랜스포머에서는 3가지를 포함하게 된다.
1. Mult-Head Attention in Encoder (Q = K = V)
2. Multi-Head Attention in Decoder (Q : Decoder vector <-> K, V : Encoder vector)
3. Masked Multi-Head Attention in Decoder
1번과 3번의 attention 같은 경우는 각각 input과 output에 대한 정보를 담기 위한 어텐션 유닛이고, 2번의 경우 input과 output 간의 어텐션 연산을 진행해 관계성을 학습하게 된다. 그리고 3번에서 masking이 진행되는 이유는 output과 같은 경우는 차례대로 한 단어씩 생성이 되는데 그렇게 되면 입력으로 들어가는 길이가 맞지 않아 전체 output의 길이에 맞게 마스킹을 삽입해 입력의 형태를 유지해준다고 생각하면 될 것 같다.
Positional Encoding
이렇게 트랜스포머는 어텐션 모듈을 다양한 형태로 활용하며 병렬적 계산을 가능하게 했지만 이러한 형태의 어텐션들은 모두 sequential하게 이루어지지 않는 계산으로 인해 각 요소들의 위치 정보를 가지지 못한다는 문제가 있다. 하지만 sequential data의 경우 위치에 따라 가지고 있는 정보들이 달라지고 그에 맞는 입력과 결과물이 생성되어야 하므로 트랜스포머에서는 positional encoding이라는 방법을 사용한다.
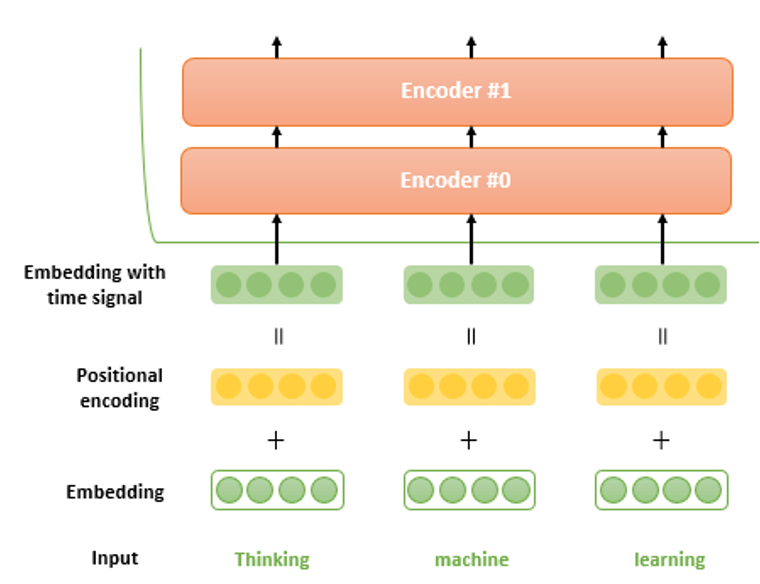
위 그림에서도 볼 수 있듯이 encoding한 벡터에 positional encoding 값을 noise로 주입하여 결국은 time signal 즉 위치에 대한 정보를 포함하는 임베딩을 만들어내게 된다.
Conclusion
이러한 모델 구조와 함께 좋은 성능을 보였고, 현재 대형 모델들에서는 대부분 트랜스포머를 활용하고 있을만큼 많이 사용되고 있으므로 이렇게 간단하게라도 트랜스포머 구조에 대한 지식을 가지고 있으면 좋을 것 같다. 물론 트랜스포머의 비효율성 등에 대한 연구들이 간혹 나오고는 있기는 하지만 아직은 대체되기 힘든 매우 중요한 한 부품이 되었고, 뛰어난 성능을 보이고 있다.
