우리가 딥러닝과 함께 다루는 데이터에는 sequential data가 많이 포함되어 있다. sequential data는 순서가 의미를 가지는 데이터를 의미한다. 텍스트, 이미지 등등 대부분의 데이터에서 순서는 어떠한 의미를 가지고 있고 이를 다루는 모델들이 많이 등장했다. 그 중 이미지를 다루는 데에는 CNN 계열의 모델들이 많이 활용되었다면, 텍스트와 같은 데이터에서는 RNN계열의 모델을 많이 활용되었다. 현재는 트랜스포머의 등장과 함께 관심이 약간은 식었지만 여전히 시계열성이 있는 데이터에서는 많이 활용되는 RNN 계열의 모델들을 소개하고자 한다.
RNN
Recurrent Neural Network의 약자로, 이름에서도 알 수 있듯이 Recurrent 즉 특정 모듈이 반복적으로 나타나는 모습을 보이고 있다.
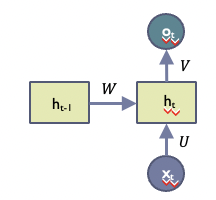
해당 모듈을 Cell이라고 불리며 RNN 모델 구조에서 반복적으로 나타난다. 이 모듈을 이해하기 위해서는 해당 모델에서 학습하는 데이터가 time step에 따라 존재하는 x에 대하여 각각의 output을 가지는 구조라는 것을 이해할 필요가 있다. 즉 에 대해 대응하는 가 존재한다. 그리고 기존의 mlp(multi-layer perceptron)의 경우 각 x와 o의 관계성만을 학습한다. 하지만 RNN에서는 해당 데이터가 sequential한 데이터이므로 이전 time step인 t-1의 요소들이 현재 t에 대해서 어떤 관계를 가진다는 것을 가정한다. 그리고 이를 모델에서 학습할 수 있도록 하기 위해 이전 time step에서의 계산 결과를 전달하고자 한다. 위의 그림에서도 t-1에서의 계산인 를 로 전달하는 것을 볼 수 있다. 이러한 해당 모듈을 반복적으로 넣어 모델을 구성한다.
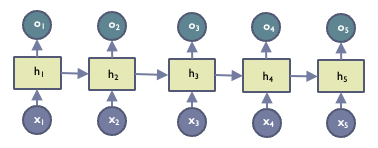
하지만 이렇게 sequential한 정보를 담을 수 있도록 구성한 RNN 모델이지만, standard RNN은 그 길이가 길어질수록 이전 time step의 정보가 vanshing하거나 exploding한다는 문제가 있다.
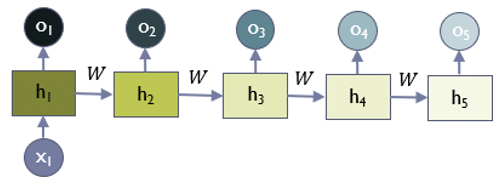
위의 그림에서 알 수 있듯 에는 W라는 가중치가 계속해서 곱해지기 때문에 그 크기에 따라서 vanishing 혹은 exploding하는 것이다. 또한 back propagation에서도 gradient vanishing이 발생하는 문제가 있어 일반적으로 10 step 이내의 데이터에서만 좋은 성능을 보인다는 문제가 있다.
LSTM
위에서 언급한 RNN의 문제점을 극복하기 위해 LSTM이라는 모델이 등장했다. Long Short-Term Memory Network의 줄임말로 Long과 Short term의 데이터에 대한 정보를 모두 잘 반영한다는 것을 장점으로 내세운다. 최근 이루어지는 연구에서 RNN을 활용했다고 언급하면 대부분 LSTM을 활용하고 있다고 볼 수 있다.
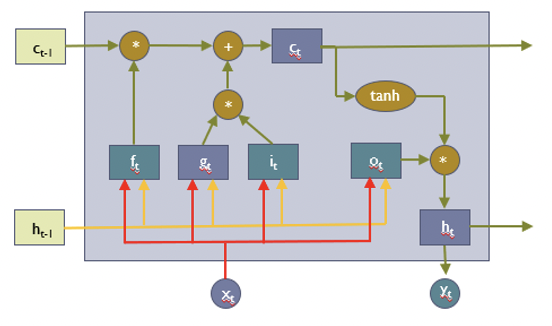
위 그림은 LSTM에서 가지고 있는 cell의 형태이다. Recurrent와 같이 해당 cell의 구조가 반복적으로 등장한다. 그럼 해당 cell이 RNN의 cell과 다른 것은 무엇일까? 크게 두가지가 존재한다. 해당 그림에서 로 등장하는 Cell state와 정보의 흐름을 통제하는 gate이다.
Cell state
Cell state도 결국은 이전 time step에 대한 정보를 담고 있다. 하지만 다음 cell로 전달이 될 때 이루어지는 계산이 다르다는 것을 알 수 있다. RNN에서는 이전 time step의 정보가 곱연산을 통해서 전달이 되기에 vanishing 문제가 발생했다면, cell state는 곱 연산이 거의 없는 highway computation으로 다음 time step으로 전달 되기에 gradient vanishing을 예방할 수 있다.
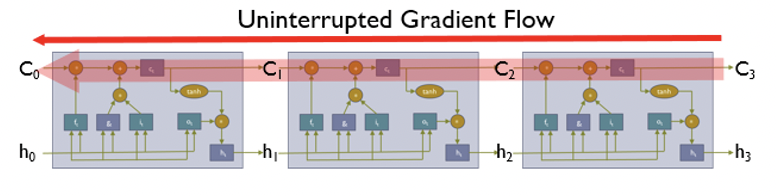
Gate
Gate는 앞에서도 설명했듯이 정보의 흐름을 통제하는 역할을 한다. Sigmoid activation을 거쳐 0~1의 값을 가지며 해당 gate를 거치는 정보와 곱해지기에 1에 가까울 수록 더 많이 반영되고 0에 가까울수록 적게 반영이 된다고 할 수 있다. RNN에서는 이런 gate를 3종류를 포함하고 있고 각각이 이전의 정보와 현재의 정보에 대한 흐름을 통제하게 된다.
GRU
Gated Recurrent Unit의 줄임말로 LSTM과 비슷한 구조를 지니지만 이름에서도 알 수 있듯이 Cell state는 활용하지 않고 Gate만을 활용하는 구조이다. LSTM이 sequential data에 대해서 충분히 좋은 성능을 보이고 있지만 계산량이 많다는 단점이 이를 위해 등장한 조금 더 간단한 구조의 모델이라고 할 수 있다.
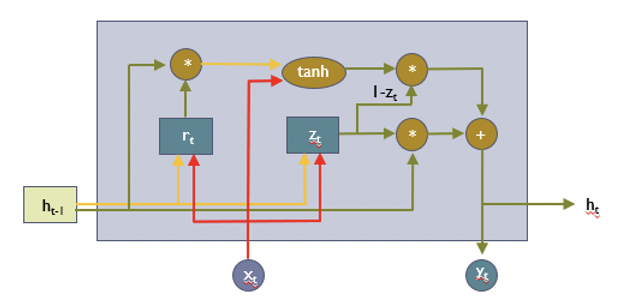
그리고 위 그림에서도 볼 수 있듯이 gate의 수도 LSTM과 달리 두개만 존재하는 것을 알 수 있다. 이걸 가능하도록 한 것은 Update gate의 계산 값 z를 input gate와 ouput gate에 모두 활용하기 때문이다. z를 input gate로 사용하고 (1-z)를 forget gate로 활용함으로써 gate의 수도 두개로 줄이게 된 것이다. GRU는 성능 면에서는 LSTM보다 좋지 않은 경우들이 있지만, 계산량의 효율성 측면에서 LSTM을 대신해 사용되는 경우들이 있다.
