Meta-data of ndarrays
왜 ndarray의 메타데이터를 알아야할까?
numpy를 이용해 코딩을 할 때 많이 실수하는 부분을 메타데이터를 앎으로써 개선할 수 있다.
우리가 numpy를 이용한 텐서를 계산할 때 모든 데이터를 다 확인할 수 없는 경우가 대부분이다. 연산이 제대로 이루어졌는지 알기 어렵다는 것이다.
대부분 데이터는 floating point 데이터이다.
ndarray는 어떤 데이터를 가지고 있을까?
- ndarray.ndim & ndarray.shape & ndarray.size
원소의 개수와 관련된 정보를 나타낸다.
shape을 따지는 이유는 무엇일까?
예를 들어 100x200의 컬러 이미지 1000장을 전부 흑백으로 바꿔준다고 가정하면
(1000,100,200,3) -> (1000,100,200)으로 shape이 변하기를 예상할 수 있고
만약 이결과가 안나온다면 연산이 의도한대로 이루어지지 않았음을 알 수 있다.
구체적으로 언제 도움이 될까?
ndarray.reshape & ndarray.resize & ndarray.flatten & ndarray.ravel등의 중요한 함수를 사용할 때 실수하지 않게 도움이 된다 - ndarray.dtype & ndarray.itemsize & ndarray.nbytes
구체적으로 언제 도움이 될까?
ndarry.astype 함수를 사용할 때 도움이 된다.
shape
import numpy as np
scalar_np = np.array(3.14)
vector_np = np.array([1, 2, 3])
matrix_np = np.array([1,2], [3,4])
print(scalar_np.ndim) 0
print(vector_np.ndim) 1
print(matrix_np.ndim) 2
print('shape/ dimension')
print('{} /{}".format(scalar_np.shape, len(scalar_np.shape))) ()/0
print('{} /{}".format(vector_np.shape, len(vector_np.shape))) (3,)/1
print('{} /{}".format(matrix_np.shape, len(matrix_np.shape))) (2,2)/2shape이 다른 벡터
import numpy as np
a = np.array([1, 2, 3]) #1d tensor
b = np.array([[1,2,3]]) #2d tensor
c = np.array([[1],[2],[3]]) #2d tensor
print(f'a: {a.shape} {a}") a: (3,) [1 2 3]
print(f'b: {b.shape} {b}") b: (1,3) [[1 2 3]]
print(f'c: {c.shape} {c}") c: (3,1) [[1]
[2]
[3]]웨에서 보다시피 a와 b,c는 차원이 다르다. a는 1d tensor이지만 b와 c는 2d tensor이고 b는 수학적으로 row vector c는 수학적으로 column vector라는 해석이 가능하다. 이것을 구분하지 못하면 추후에 나올 broadcasting을 할때 문제가 생길 수 있다.
size
import numpy as np
M = np.ones(shape = (10,))
N = np.ones(shape = (3,4))
O = np.ones(shape = (3,4,5))
print("Size of M: ",M.size) size of M : 10
print("Size of N: ",M.size) size of N : 12
print("Size of O: ",M.size) size of O : 120size는 원소의 개수를 나타낸다. 각 차원의 크기의 곱으로 구한다.
Data types in Numpy
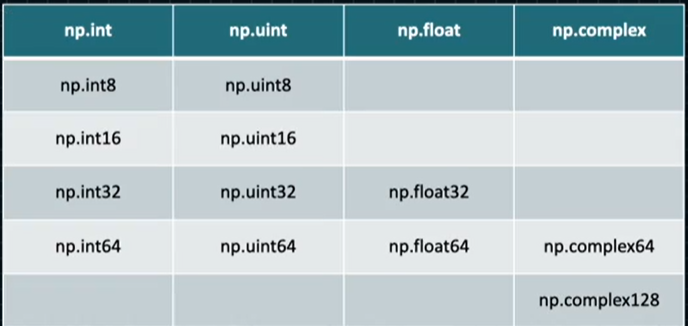
Numpy에는 숫자관련 크게 4개의 자료형이 존재한다. 그중에서 int, uint, float를 가장 많이 사용한다. 자료형에 붙어있는 숫자는 비트 수를 나타내는 값이다. 비트 수가 많아질수록 표현할 수 있는 수의 범위가 늘어나지만 단점으로 데이터의 크기가 커지고 프로그램이 느려지는 단점이 있다. 따라서 최적화의 입장에서 적절한 비트 수를 설정하는 것이 필요하다.
import numpy as np
int_np = np.array([1, 2, 3])
float_np = np.array([1., 2., 3.])
print(int_np.dtype) int64
print(float_np.dtype) float64
int8_np = np.array([1,2,3],dtype=np.int8)
int16_np = np.array([1,2,3],dtype=np.int16)
int32_np = np.array([1,2,3],dtype=np.int32)
int64_np = np.array([1,2,3],dtype=np.int64)int64가 default 자료형이지만 최적화를 위해 명시적으로 비트 수를 설정할 수도 있다.
import numpy as np
int8_np = np.array([1.5, 2.5, 3.5], dtype = np.int8)
uint8_np = np.array([1.5, 2.5, 3.5], dtype = np.uint8)
print(int8_np) [1 2 3]
print(uint8_np) [1 2 3]int형으로 type을 바꾸면 소수점이 날아간다
import numpy as np
M = np.ones(shape = (2, 3), dtype = np.float32)
N = np.zeros_like(M, dtype = np.float64)M과 N은 둘다 floating point형 ndarray를 나타내는것 같지만 둘의 용량 차이는 2배가 난다
itemsize
가장 작은 단위인 원소의 Byte 수를 출력해준다.
int8 = 1Byte, int16 = 2Byte, int32 = 4Byte ...etc
import numpy as np
normal = np.random.normal(size = (50,50, 32,2))
print("size: ", normal.size) 40000
print("dtype/itemsize: {}/{}".format(normal.dtype, normal.itemsize)) dtype/ itemsize: float64/8
m_cap = normal.size * normal.itemsize
print("Memory capacity in B: ", m_cap)) 3200000B
print(normal.nbytes) 3200000B