특정 shape의 numpy array 만들기
numpy.array의 datatype
int_py = 3
int_np = np.array(int_py)
print(type(int_py),type(int_np))
#<class 'int'> <class 'numpy.ndarray'>리스트도 numpy.array로 만들 수 있다
vec_py = [1,2,3] #1,2,3 dim list 모두 가능하다
vec_np = np.array(vec_py)
print(type(vec_py),type(vec_np))
#<class 'list'> <class 'numpy.ndarray'>ndarray의 shape
scala_np = np.array(3.14)
vec_np = np.array([1,2,3])
mat_np = np.array([[1,2],[3,4]])
tensor_np = np.array([[[1,2,3],
[4,5,6]],
[[7,8,9],
[10,11,12]]])
print(scala_np.shape) #()
print(vec_np.shape) #(3,)
print(mat_np.shape) #(2,2)
print(tensor_np.shape) #(2,2,3)ndarray with specific values
ndarray를 어떤 값으로 초기화시키기 위해서 shape만 알면 가능하다.
활용 방안 : 100x100의 이미지를 담을 공간을 초기화하는데 사용 가능
0으로 초기화하는 방법
numpy.zeros(shape, dtype = float, order = 'C')
print(M.shape(2,3) #(2,3)
print(M) #[[0. 0. 0.]
[0. 0. 0.]]floating point 0.으로 초기화 되었다, int 아니다.
활용 방안 : 어떤 데이터를 더하는 방식으로 누적해야할 때 0으로 초기화하여 누적한다.
1로 초기화하는 방법
numpy.ones(shape = (2,3))
활용 방안 : 어떤 데이터를 더하는 방식으로 누적해야할 때 0으로 초기화하여 누적한다.
원하는 값으로 초기화하는 방법
numpy.full(shape,fill_value, dtype=None,order='C')
M = np.full(shape=(2,3), fill_value=3.14)
3.14 * np.ones(shape=(2,3))똑같은 결과이지만 가독성이 달라지기 때문에 full 활용할 것 = 의미전달에 좋다
M = np.empty(shape(2,3))
#[[3.14 3.14 3.14]
[3.14 3.14 3.14]] np.empty
빈 공간을 메모리 상에 잡기만 할뿐 초기화 안된 쓰레기 값이 들어있다
따라서 이전에 쓰던 변수인 M의 값이 그대로 출력되었다.
활용 방법: np.empty(shape = (0,3))
column을 3으로 설정하였고 나중에 column의 크기가 3인 vector를 추가해줄 수 있다.
이미 있는 ndarray와 같은 shape array 만들기
np.zeros_like(M) == np.zeros(shape=M.shape)
이미 존재하는 M 이랑 같은 모양의 ndarray를 0으로 채운다
다양한 변형들
np.zeros_like(M)
np.ones_like(M)
np.full_like(M)
np.empty_like(M)Fixed Interval/Points ndarray 만들기
python 함수 range를 생각해보자
[0 ... 100]의 리스트를 만들수 있었다. numpy에도 비슷한 것이 있다.
Interval이 정해져있는 경우
numpy.arange([start,]stop,[step,]dtype=None,...)
print(np.arange(10)) [0 1 2 3 4 5 6 7 8 9]
print(np.arange(2,5)) [2 3 4]
print(np.arange(2,10,2)) [2 4 6 8]List와의 차이점 : dtype이 ndarray 타입이다.
start/end/step size가 소수점이 가능하다
print(np.arange(10.5)) 10을 포함하는 리스트가 생성됨
print(np.arange(1.5,10.5)) [1.5 2.5 3.5 4.5 ... 9.5] stepsize 1이 기본
print(np.arange(1.5,10.5,2.5)) [1.5 4 6.5 9. ]Fixed point가 있는 ndarray
numpy.linspace(start,stop,num=50,endpoint=True,retstep=False,dtype=None,axis=0)
print(np.linspace(0,1,5)) [0. 0.25 0.75 1. ]
기본적으로 시작점과 끝점을 포함한다
로그함수와 같은 점근선이 있는 함수에서 샘플링할 때는
endpoint=False로 시작점/ 끝점 포함 안하게 조작가능
여러 개의 linspace를 동시에 생성 가능하다
a = np.linspace([1,10,100] , [2,20,200], 5)
print(a)
[[ 1. 10. 100. ]
[1.25 12.5 125.]
[1.5 15. 150.]
[1.75 17.5 175]
[2 20 200]1~2, 10~20, 100~200를 5개로 나누는 것이 가능하다
arange와 linspace 비교
arange와 linspace는 상호교환이 가능하다
print(np.arange(10)) == print(np.linspace(0, 9, 10))
arange - interval/step size가 중요할때
linspace - 개수가 중요할 때
가독성을 최우선으로 생각하여 사용한다.
ndarray from Random distribution
Normal Distribution
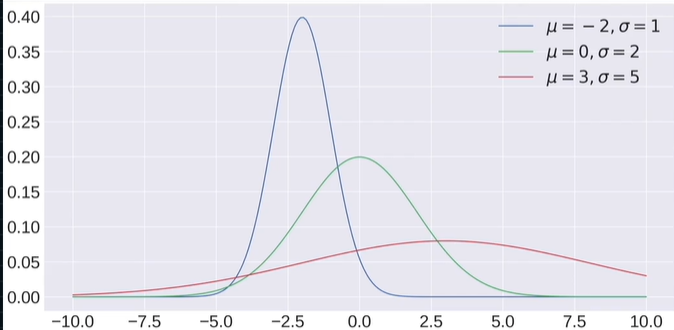
- 인공지능 모델을 테스트해볼 때 우리는 weight를 초기화해야 된다. 하지만 매번 실제 데이터를 사용할 수는 없다. 그럴때 특정한 값 근처의 가우시안 분포에서 샘플링한다.
- 데이터에 노이즈를 추가해줄 때 사용한다
- random.randn(d0,d1,...dn) : Standard Normal Distribution에서 추출
- random.normal(loc=0.0, scale=1.0, size=None) : 원하는 Distribution 선택가능
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('seaborn')
fig, ax = plt.subplots(figsize = (1,5))
random_values = np.random.randn(300) 300개 샘플링
ax.hist(random_values, bins=20)
print(random_values.shape) (300,)normal = np.random.normal(loc= [ ], scale = [ ],size())
normal = np.random.normal(loc=\[-2, 0, 3], scale=\[1, 2, 5], size = (200,3))
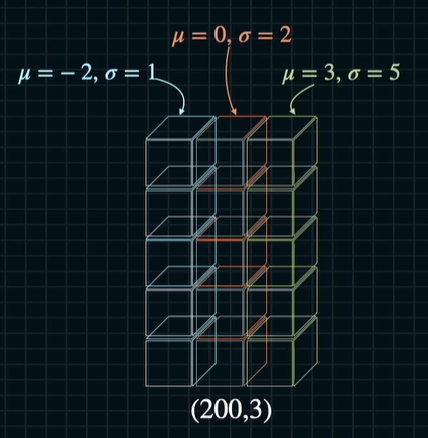
for loop을 사용하지 않고 여러개의 distribution을 합칠 수 있다는 장점이 있다.
활용 방안
np.random.normal(loc=-2, scale=1, size=(image size))
이미지에 화이트 노이즈를 섞어줄 수 있다.
Uniform distribution
1. random.rand(d0, d1, d2...dn) : [0,1) 0을 포함하고 1을 포함x
2. random.uniform(low=0.0, high=1.0, size=None)
3. random.randint(low, high=None, size=None, dtype=int)
import numpy as np
import matplot.pyplot as plt
fig, ax = plt.subplot(figsize=(10,5))
uniform = np.random.rand(1000)
ax.hist(uniform)
uniform = np.random.rand(2,3,4)
print(uniform.shape) (2 3 4)
randint = np.random.randint(low=0,high=7,size=(20,))
print(randint)np.random.uniform(low, high, size) & np.random.randint(low, high, size): high를 포함하지 않는 분포이다.
