Reshape과 Resize
Reshape
Numpy.reshape
numpy.reshape(a, newshape, order='C')
a 를 newshape 모양으로 바꿔서 반환한다.
import numpy as np
a = np.arange(6)
b = np.reshape(a,(2,3))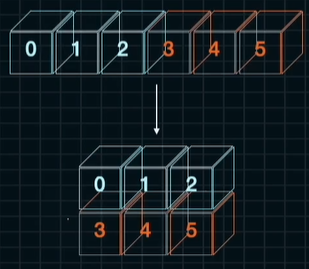
import numpy as np
a = np.arange(24)
b = np.reshape(a,(2,3,4))바깥쪽 차원부터 채우는 원칙
(2,)모양의 ndarray가 있고 각각은 (3,) 모양의 ndarray이다. 3개의 ndarray는 각각 (4,)짜리의 ndarray이다. b[0]부터 채우기 시작해야 한다. b[0]은 3개의 ndarray가 있기 때문에 b[0][0]부터 채운다.
ndarray.reshape
ndarray.reshape(shape, order='C')
import numpy as np
a = np.arange(6)
b = a.reshape((2,3))import numpy as np
a = np.random.randint(0,100, (100,))
print(a.reshape((20,5)).mean(axis=0).max())
print(np.max(mean(np.reshape(a, (20,5)), axis=0)))위의 결과는 같다. 그러나 위의 a.reshape이 가독성 측면에서 낫기 때문에 위의 코드처럼 하도록 하자.
-1을 np.reshape에서 사용하는 방법
import numpy as np
a = np.arange(12)
b = a.reshape((2,-1)) ->(2,6)
c = a.reshape((3,-1)) ->(3,4)
d = a.reshape((-1,2)) ->(6,2)
e = a.reshape((-1,3)) ->(4,3)2x(모르는 값)을 자동으로 (2,6)의 shape으로 계산해준다
고차원 tensor에서 사용할 때 직접 차원 값을 계산하지 않아도 되는 장점
row vector, column vector 만드는 법
row_vector = a.reshape(1,-1)
column_vector = a.reshape(-1,1)Resize
Reshape은 원소의 개수를 바꾸지 않고 모양을 바꾸지만 Resize는 원소의 개수를 바꾸게 될 수도 있기 때문에 조심해서 써야한다. Shape의 부족한 부분은 초기 array의 반복을 통해 채운다. Reshape이 더 안전한 API이다. Size가 원래 array보다 큰 경우에는 다음과 같이 np.reshape이 동작한다.
import numpy as np
a = np.arange(6)
#b = np.reshape(a, (9,)) -> ValueError
b = np.resize(a, (9,))
print("original ndarray: ", a) [0 1 2 3 4 5]
print("resized ndarray: ", b) [0 1 2 3 4 5 0 1 2]Size가 array보다 작은 경우에는 다음과 같이 동작한다.
import numpy as np
a = np.arange(9)
b = np.resize(a, (2,2))
print("original : ", a) [0 1 2 3 4 5 6 7 8]
print("resized : ", b) [[0 1]
[2 3]]ndarray.resize(new_shape, refcheck=True) array를 파괴적으로 shape과 size를 바꾼다. 또한 in-place operation이기에 return을 하지 않는다.
import numpy as np
a = np.arange(9)
b = a.resize((2,2))
print("original : ", a) [[0 1]
[2 3]]
print("resized : ", b) Nonea.size는 a를 자체적으로 size를 바꿔준다.
Flatten과 Ravel
Flatten과 Ravel은 Reshape과 Resize의 반대 연산이라고 생각하면 된다.
Flatten
ndarray.flatten(order = 'C')
Flatten은 tensor를 vector로 만들어주는 것이다.
import numpy as np
M = np.arange(9)
N = M.reshape((3,3))
O = N.flatten()
print(M) [0 1 2 3 4 5 6 7 8]
print(N) [[0 1 2] [3 4 5] [6 7 8]]
print(O) [0 1 2 3 4 5 6 7 8]Flatten 하는 방법 : 가장 바깥쪽 차원부터 접근하여 flatten시켜준다.
예를들어 (3,3,3) shape의 경우 3개의 (3,3) tensor로 구성되어 있다. [0]번째 (3,3)을 flatten하여 (9,)로 만들고 그 다음으로 [1]번째 (3,3)을 flatten한다.
Ravel
얼핏 보기에는 flatten과 차이가 없어보인다.
ndarray.ravel([order])
import numpy as np
M = np.arange(9) [0 1 2 3 4 5 6 7 8]
N = M.reshape((3,3)) [[0 1 2] [3 4 5] [6 7 8]]
O = N.ravel() [0 1 2 3 4 5 6 7 8]Numpy의 메모리 최적화
변수에 데이터를 할당하는 방법은 copy와 view가 있다.
copy : 새로 데이터를 할당할 때 source에서 copy해서 메모리상의 다른 공간에 개별적으로 저장한다.
메모리를 많이 차지한다
하나의 변수의 값을 변경해도 다른 변수에 영향이 없다
view : 같은 데이터는 메모리 주소값을 통해 중복하여 저장하지 않는다.
메모리를 최대한 적게 사용할 수 있다
하나의 변수를 수정하면 다른 변수에 영향이 생긴다.
-> numpy가 택하고 있는 방식
import numpy as np
a = np.arange(5)
b = a.view()
b[0] = 100
a -> [100 1 2 3 4]
b -> [100 1 2 3 4]
------------------------
a = np.arange(5)
b = a[0:3]
b[...] = 10
a -> [10 10 10 3 4]
b -> [10 10 10]
-------------------------
a = np.arange(5)
b = a.copy()
b[0] = 100
a -> [0 1 2 3 4]
b -> [100 1 2 3 4]view를 통해 생성된 b는 a와 같은 메모리 주소를 사용하기 때문에 b를 변경하면 a도 같이 변경된다. 또한 Slicing을 통해 생성된 array도 메모리 주소를 공유한다. 만약 다루는 변수가 데이터에 영향을 미치지 않기를 원한다면 copy를 사용해야 한다.
