py30_pandas.ipynb
Pandas 기초
Pandas란?
엑셀과 같은 테이블 형태로 데이터를 다루는 파이썬 라이브러리(모듈)
데이터 분석을 위한 추상자료구조(DataFrame)를 제공하는 데이터 분석 도구
- 엑셀/CSV 데이터 읽어오기
- 데이터 처리
- 엑셀/CSV 데이터 저장하기
Pandas 용어
- DataFrame, Series
- Index, Columns, Values, (x, y) series
Pandas 사용
- Pandas 설치
pip install pandas (콘솔)
!pip install pandas (노트북)
pandas를 설치한다.
설치된 패키지 확인
!pip list현재 pandas(2023.06 기준) 2.0.2
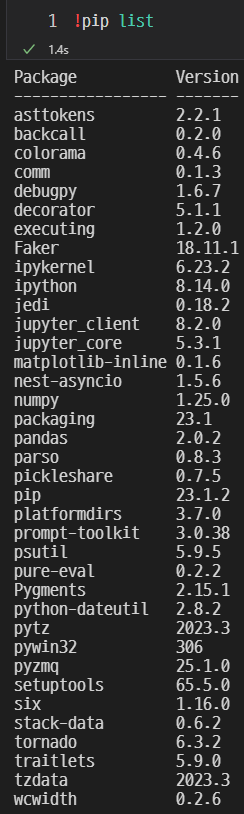
!pip list를 실행하여 설치된 패키지를 확인할 수 있다.
Pandas import
import pandas as pdSeries
Pandas 한행, 한열 나열해서 배열형식 데이터 타입

grade = pd.Series(data = ['길동이', 90, 50, 75, 100], index=['이름', '국어', '영어', '수학', '미술'])이렇게 실행한 후
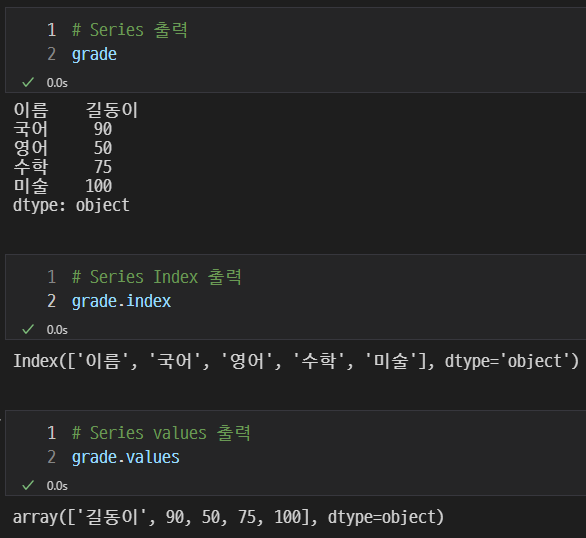
위 사진처럼 정보를 출력할 수 있다.
Series 재색인
컬럼 갯수 변경할 때
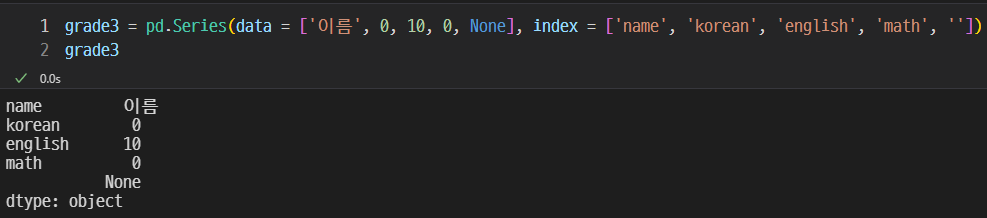
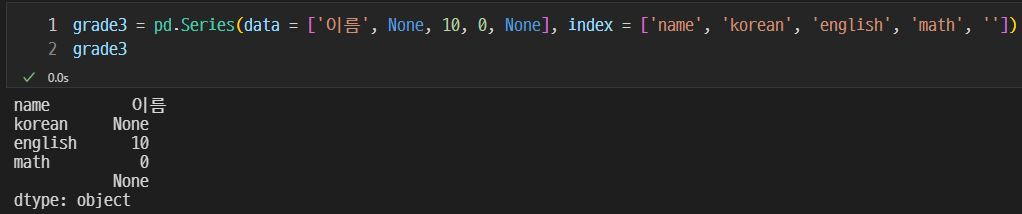
grade3 = pd.Series(data = ['이름', 10, 10, 10, 10], index = ['name', 'korean', 'english', 'math', ''])
grade3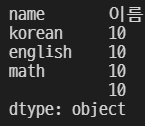
위 값을 수정해보자.
# 시리즈 재색인 - 원래 있는 값에서 컬럼 추가/제거
grade4 = grade3.reindex(index = ['name', 'korean', 'english'])
grade4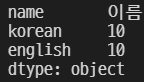
'math' 컬럼을 제거하였다.
# 시리즈 재색인 - 원래 있는 값에서 컬럼 추가/제거
grade4 = grade3.reindex(index = ['name', 'korean', 'english'])
grade4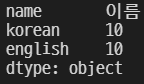
music 컬럼을 추가하였다. 값은 NaN으로 설정된다.
# 필요한 값을 추가할 때
grade3.reindex(index = ['name', 'korean', 'english', 'math', 'music'], fill_value=0)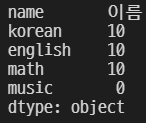
fill_value=0을 추가하여 NaN 자리에 0으로 채웠다.
컬럼 이름을 바꿀 때
# 컬럼명 변경
grade3.rename({'name' : '이름', 'korean' : '국어', 'english' : '영어', 'math' : '수학', '':'미술'})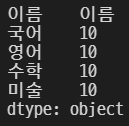
이렇게 변경된다.
index 번호로 조회
# index 번호로 조회
# list 사용할 때와 동일
grade[0]
index 명으로 조회
# index 명으로 조회
grade['국어']
loc 함수 조회
# loc 함수 조회 / Contents assistant에 출력
grade.loc['미술']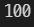
다중 index
# 다중 index
grade[['이름', '수학']]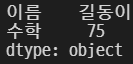
grade.reindex(index = ['이름', '수학'])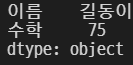
조건문
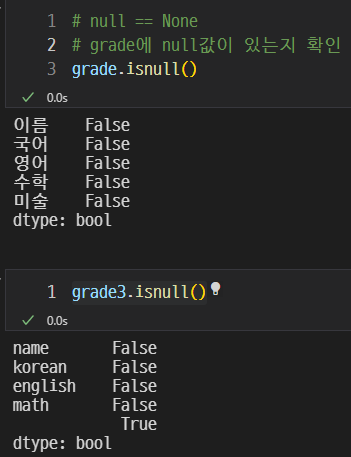
none 확인
값을 변경한 후
국어 점수도 null로 변경하였다.
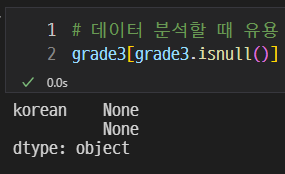
이렇게 null인 컬럼을 찾을 수 있다.
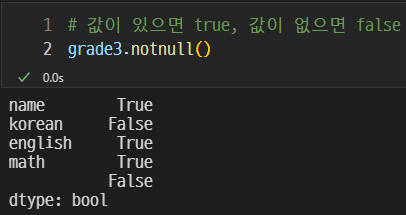
값이 있으면 True, 없으면 False를 출력하게 된다.
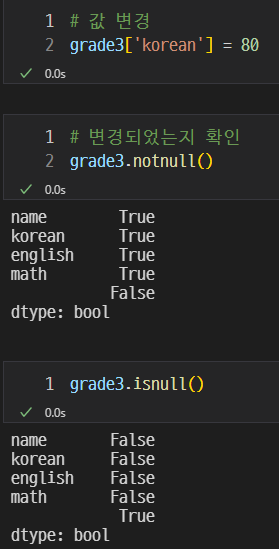
위 사진과 같이 'korean'의 값을 추가하고 출력하면 해당하는 조건에 맞게 출력된다.
두가지 값 한 번에 변경
grade3 = grade3.rename({'' : 'art'})
grade3[['korean', 'art']] = (90, 100)
grade3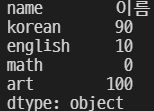
이렇게 변경된 값이 정상적으로 출력된다.
Series 삭제
del grade3['math']
grade3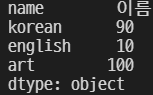
정상적으로 삭제된 것을 볼 수 있다.
# Series에서 잠시 드랍 -> 할당필요
# grade3.drop('art')를 할 경우 드랍되지만 이후에 출력하면 다시 생김
grade3 = grade3.drop('art')
grade3
설명 확인
Series 이름
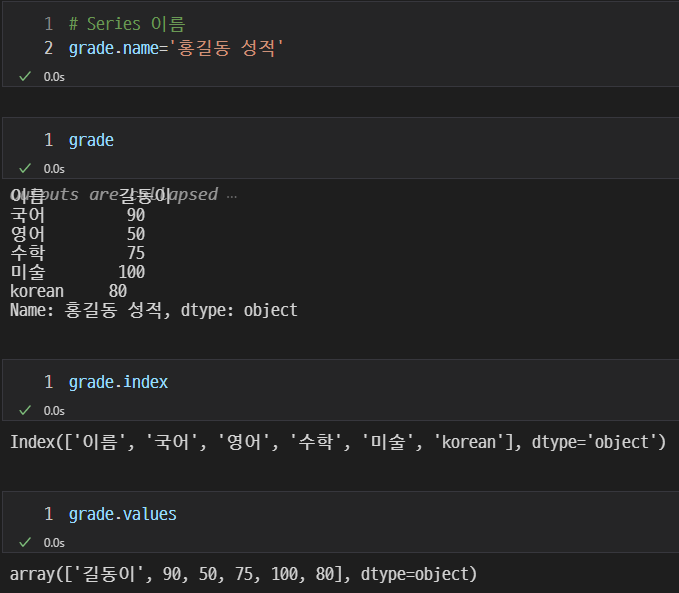
Series의 이름을 설정할 수 있다.
함수(통계함수)
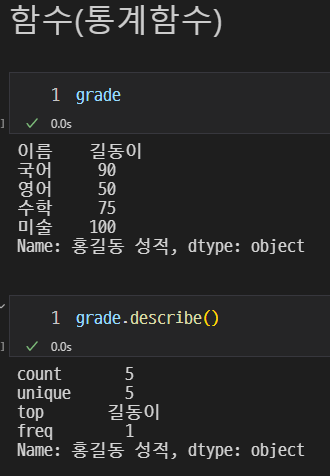
이렇게 나타낼 수 있다.
numpy
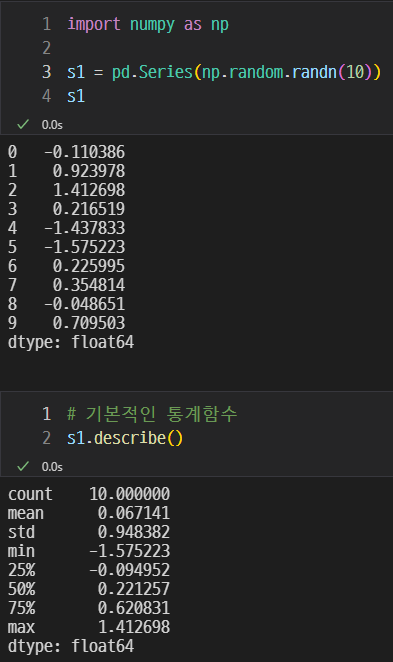
np.random.randn(10)은 무작위의 숫자 10개를 생성한다는 뜻이다.
count : 갯수
mean : 평균값
std : 표준편차
min : 최솟값
max : 최대값
25% : 1사분위 (하위 25%)
50% : 2사분위 (중간값)
75 : 3사분위 (하위 75%)
count (빈도 계산)
value_counts
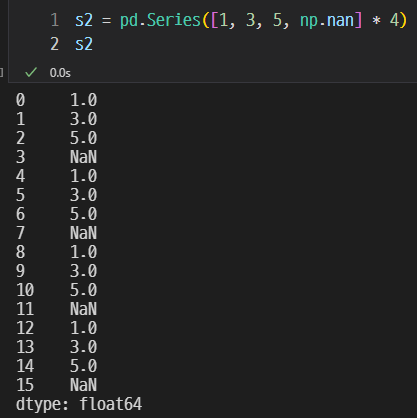
1, 3, 5, NaN이 4번 반복된다.
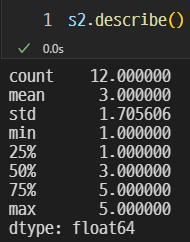
describe()을 사용해보자.
1, 3, 5, Nan, 1, 3, ... 5, NaN 의 값을 분석한 것이다.
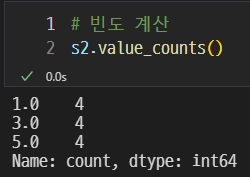
value_counts()이다.
각각 값의 갯수를 나타낼 수 있다.
dropna = False(결측치)
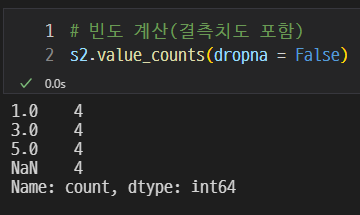
dropna = False를 이용하여 결측치도 포함하여 계산할 수 있다.
비율
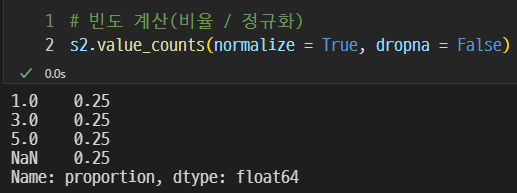
모든 값의 비율을 계산할 수 있다.
구간
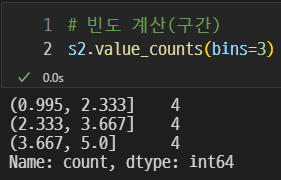
구간을 나누어 그에 포함된 값의 갯수를 계산할 수 있다.
결측치 확인
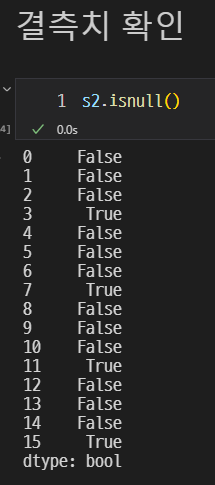
isnull()을 이용하여 True, False로 나타낼 수 있지만, 값이 많아지면 정확하지 않다.
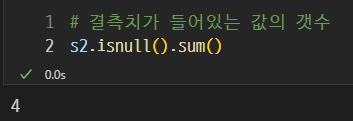
.isnull().sum()을 이용하여 결측치의 갯수를 알 수 있다.
결측치를 없애는 방법
- 결측치 삭제 - 통계치 전부 변경
- 결측치 채움 - 0으로 대체(평균값, 표준편차 수치가 많이 변경될 가능성이 큼), 평균값으로 대체
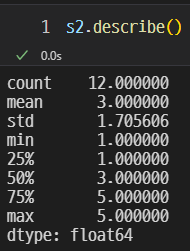
s2로 해보자
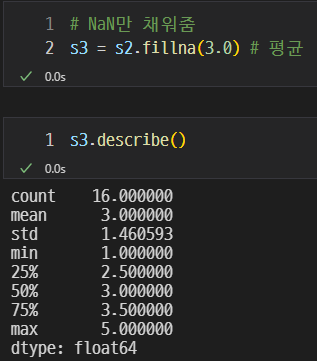
s2의 결측치를 평균값인 3으로 채워넣었다.
count, std, 25%, 75%의 값이 변경된 것을 확인할 수 있다.
데이터 대치 map
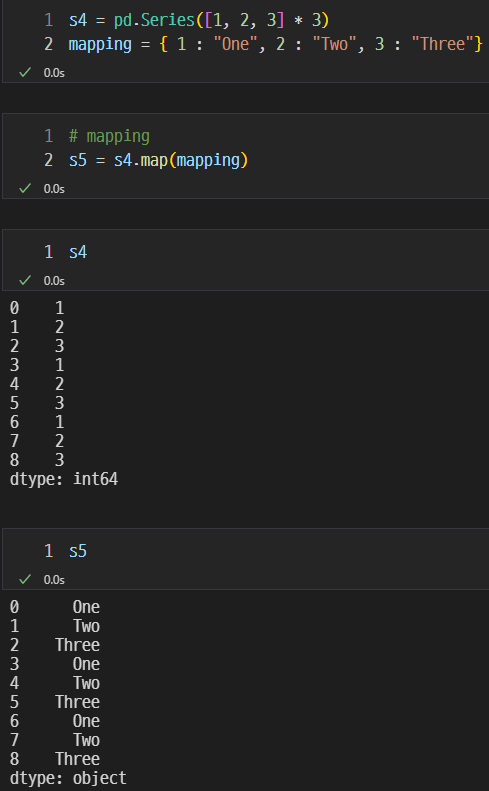
map을 이용하여 데이터의 값인 1, 2, 3을 각각 One, Two, Three로 대치할 수 있다.
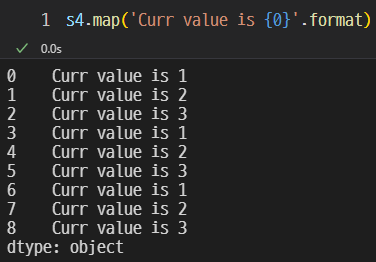
모든 값에 동일한 글자를 추가할 수 있다.
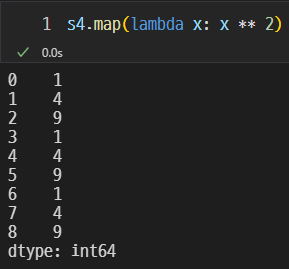
lambda x : X ** 2를 이용하여 값의 제곱을 구할 수 있다.
Series 부분출력
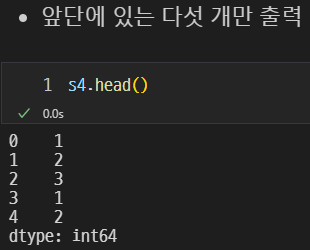
앞단에 있는 다섯 개만 출력할 수 있다.
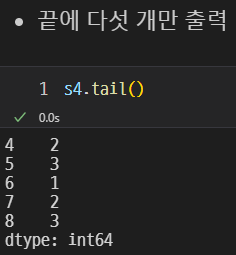
반대로 끝에서 다섯 개만 출력할 수도 있다.
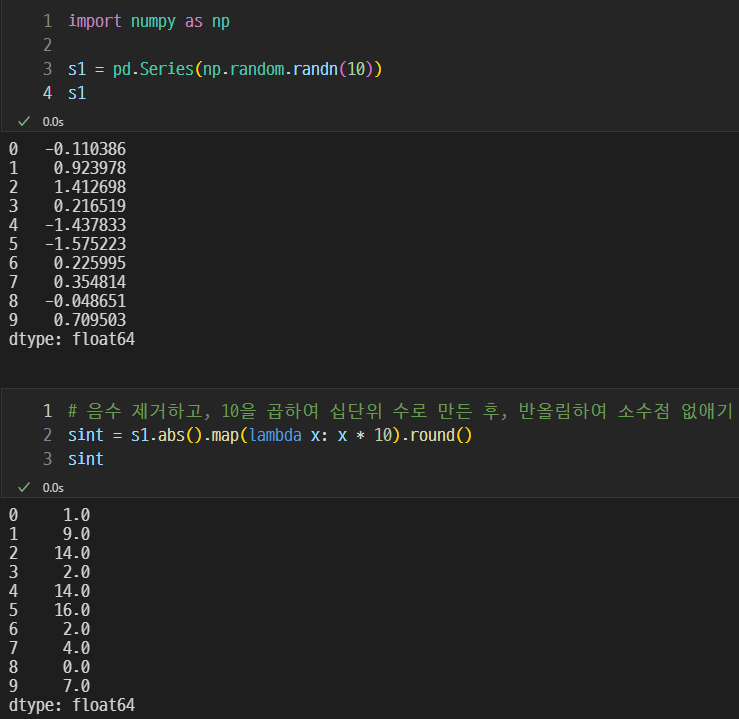
이렇게 원하는 대로 응용이 가능하다.
py31_pandas_dataframe.ipynb
기초

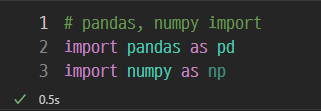
pandas, numpy를 import한 후
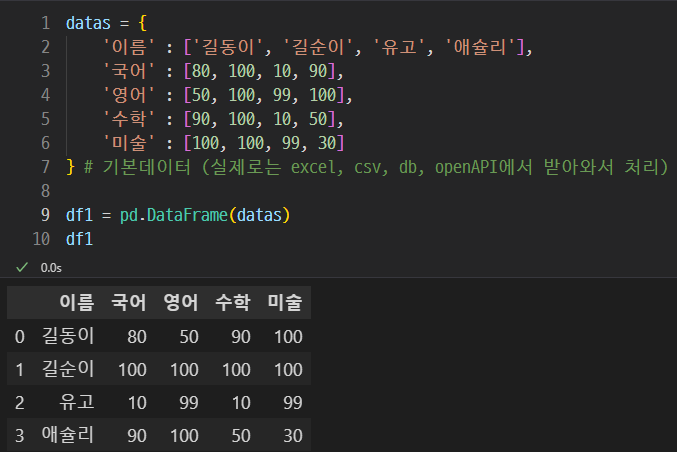
이렇게 데이터프레임을 생성할 수 있다.
특정 컬럼 사용
이 데이터를 토대로
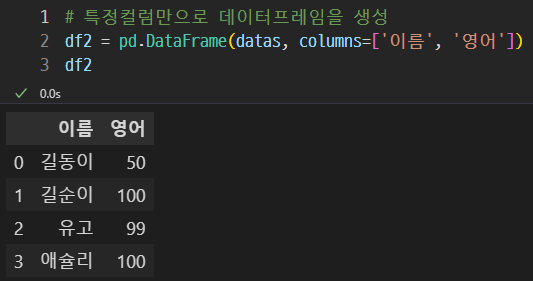
이름과 영어 항목만 불러올 수 있다.
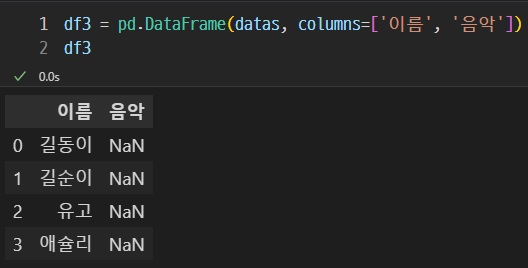
없는 컬럼을 입력하면 NaN이 출력된다.
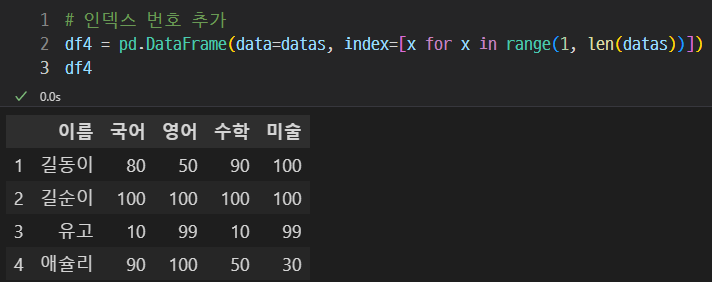
이렇게 추가할 수 있다.
데이터프레임 내의 데이터조회
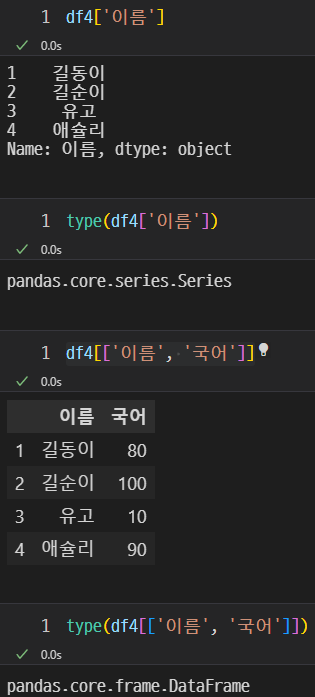
이렇게 원하는 항목의 데이터를 조회할 수 있고 type 명령어로 type을 알 수 있다.
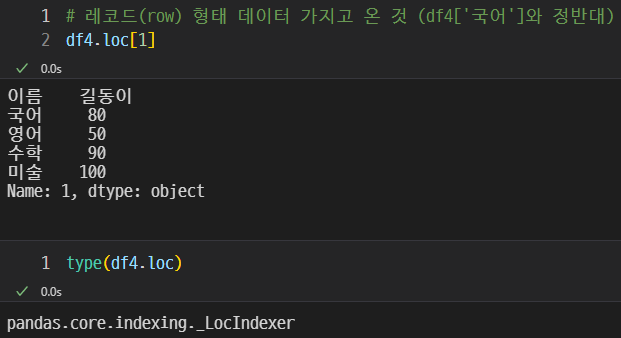
loc를 사용하여 가로로 series를 조회할 수 있다.
또한 type 명령어로 type을 알 수 있다.
다중 인덱스
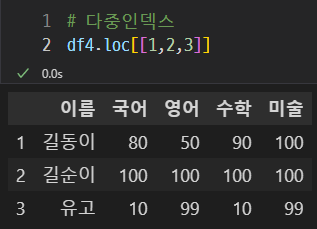
이런 식으로 한 번에 여러개의 인덱스를 조회할 수 있다.
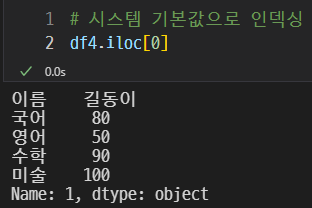
기본값으로 인덱싱해보자.
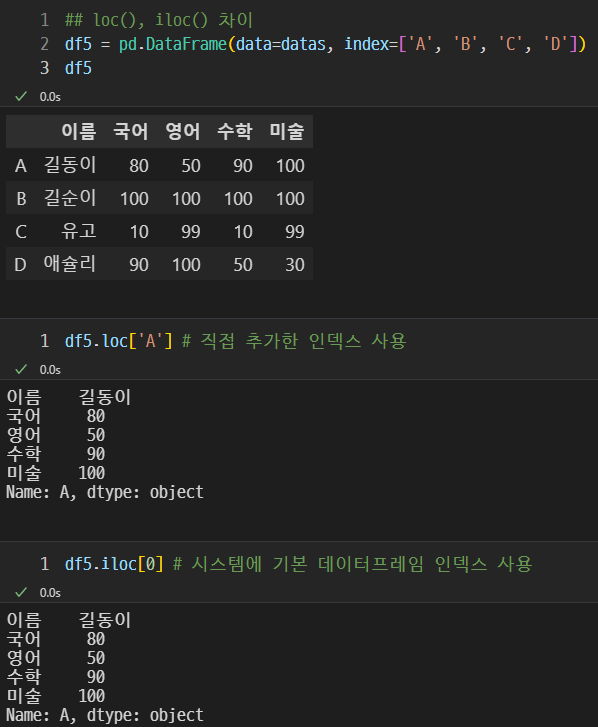
편한 것으로 사용하면 된다.
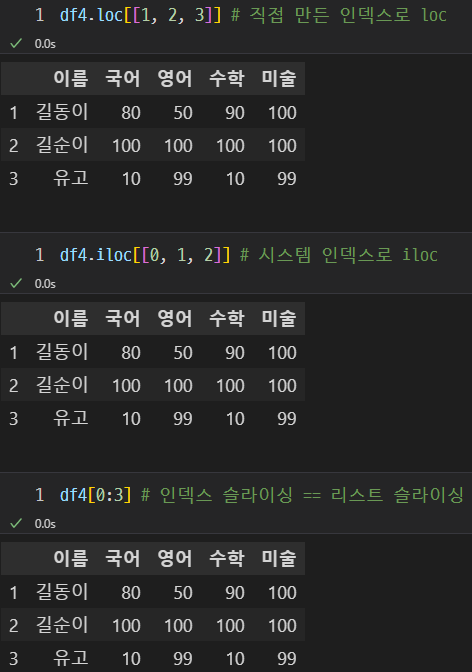
위 사진방법 또한 같은 의미이다. 편한 것으로 적절하게 사용하자.
특정 데이터 상세 조회
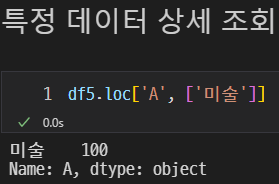
이렇게 특정 데이터를 상세히 조회할 수 있다.
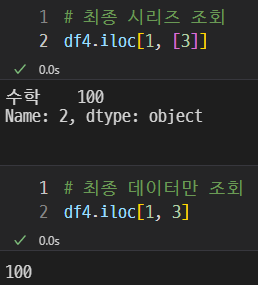
추가로 시리즈를 조회할 수도, 최종 데이터만 조회할 수도 있다.
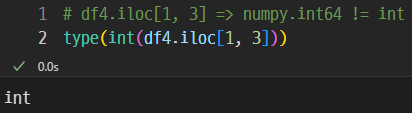
numpy.int64는 int와 다르다.
조건식 조회
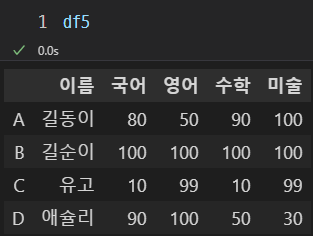
df5에서 조건을 넣어 조회해보자.
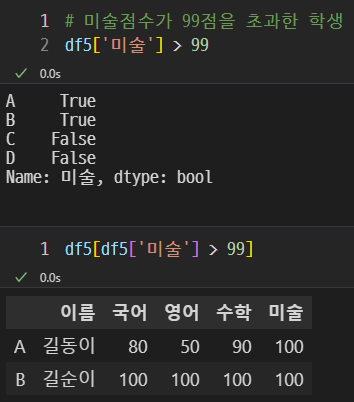
위 사진처럼 다른 방식으로 조회할 수 있다.
