py31_pandas_dataframe
조건식
and 조건식
df5[(df5['국어'] >= 80) & (df5['수학'] > 80)]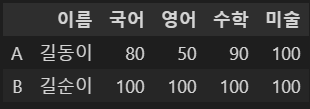
or 조건식
df5[(df5['영어'] <= 50) | (df5['국어'] <= 10)]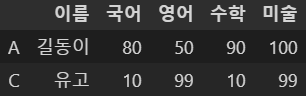
isin
df5[df5['영어'].isin([50, 99])]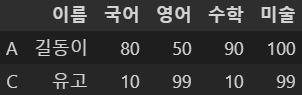
영어점수가 50점, 99점인 값만 출력
df5[(df5['영어'].isin([50, 99])) & (df5['수학'] == 10)]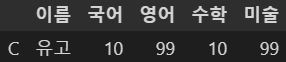
조건을 여러개 넣을 수도 있음
데이터프레임 데이터 추가
df5['음악'] = [0, 100, 30, 10]
df5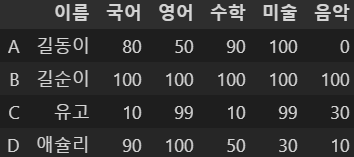
음악이 추가되었다.
데이터 수정
df5['음악 + 10'] = df5['음악'] + 10
df5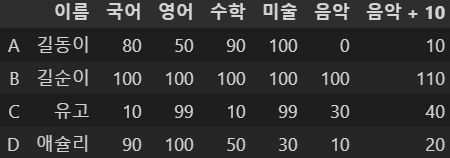
이렇게 점수에도 숫자를 더할 수 있다.
df5['음악'] = df5['음악'] + 10
df5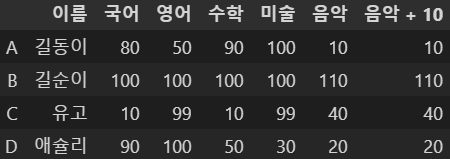
이렇게 음악 점수를 10씩 올리고
# 값 변경
df5.loc[df5['음악'] > 100, ['음악']] = 100
df5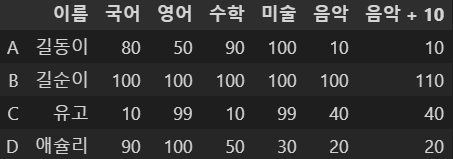
100이 넘는 항목은 100으로 변경하였다.
# 특정위치 값만 변경
df5.at['A', '음악'] = 20
df5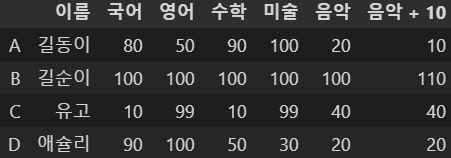
이렇게 원하는 항목만 값을 변경할 수 있다.
데이터 삭제
drop
# 삭제 - 음악 + 10
del df5['음악 + 10']
df5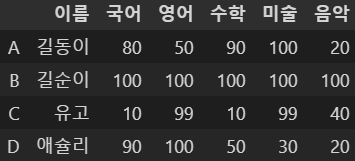
이렇게 지정한 값을 삭제할 수 있다.
# drop, axis=0(values), axis=1(column)
df5.drop(['미술'], axis=1)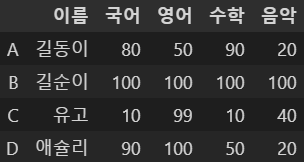
미술 컬럼 삭제
# 1row(values) 드랍
df5.drop('A', axis=0)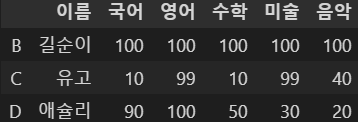
A 항목 삭제
inplace=True
# 실제로 지움 == del
df5.drop('C', axis=0, inplace=True)
df5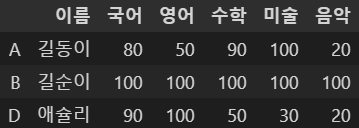
일시적으로 사라지는 drop과 달리 완전히 사라지는 del과 동일한 명령어다.
나머지 속성값
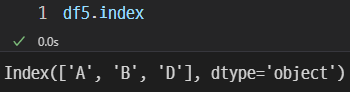
index
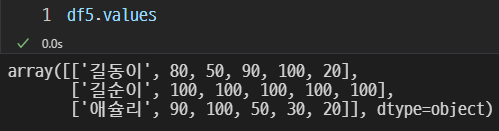
value
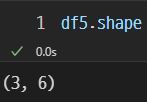
가로 세로 갯수

총 갯수
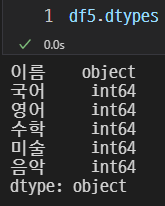
컬럼 타입
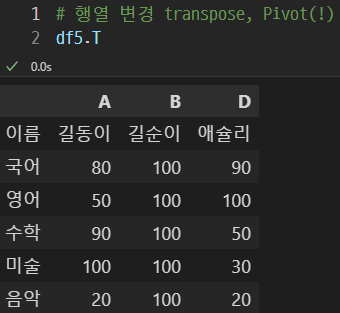
행열 변경
py32_pandas_io
판다스 파일 읽기

pandas와 numpy를 import하고 시작
csv 파일을 두개 받음
로컬 파일 읽기
df1 = pd.read_csv('./충청북도_푸드뱅크현황.csv', encoding='utf-8', header=0)
df1이렇게 입력하면
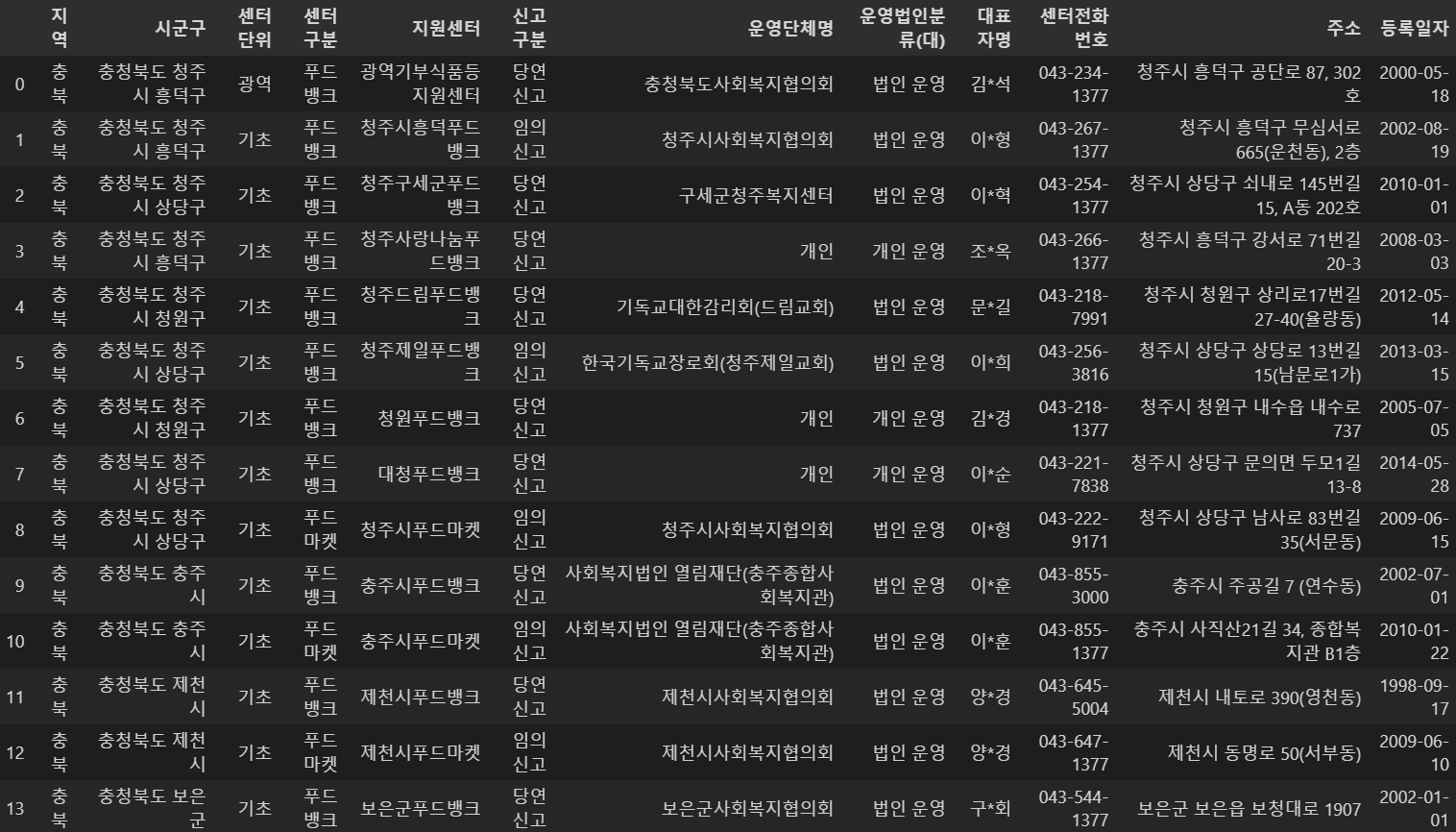
사진은 13번까지만 업로드하였지만 28개의 항목이 있다.
df2 = pd.read_csv('./부산광역시_시내버스_이용건수.csv')
df2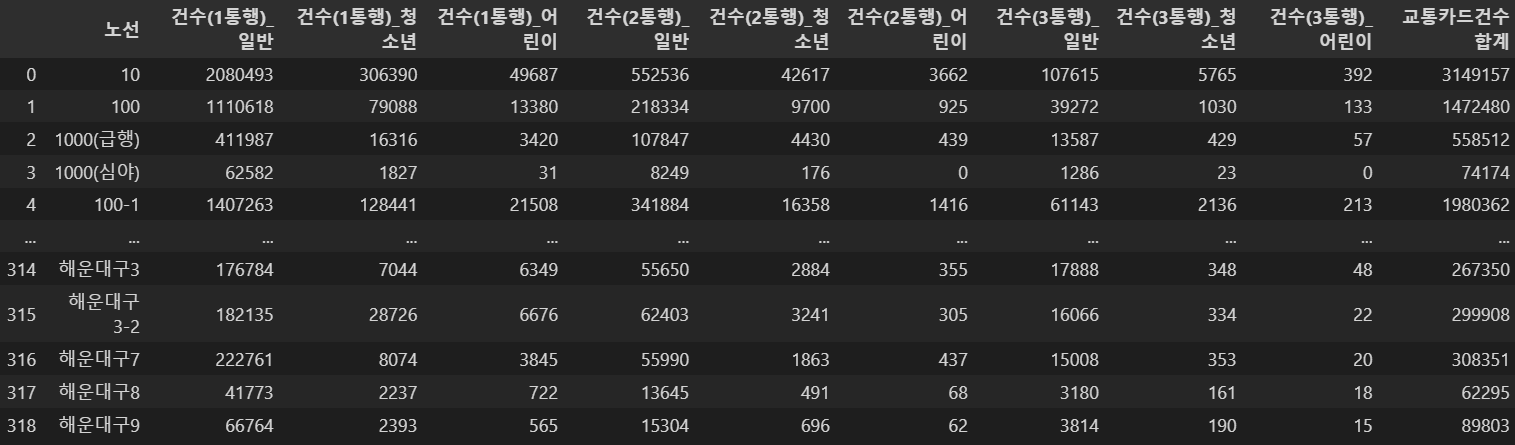
항목이 많으므로 중략되었다.
웹사이트 상에 있는 csv 읽기
df3 = pd.read_csv('https://raw.githubusercontent.com/hugoMGSung/bigdata-python-2023/main/Day03/%EC%B6%A9%EC%B2%AD%EB%B6%81%EB%8F%84_%ED%91%B8%EB%93%9C%EB%B1%85%ED%81%AC%ED%98%84%ED%99%A9.csv')
df3강사님 깃허브에 있는 충청북도_푸드뱅크현황.csv이다.
df4 = pd.read_csv('https://raw.githubusercontent.com/bourbonkk/StatisticDataAnalysis/main/rawdata/totally_raw_data.csv')
df4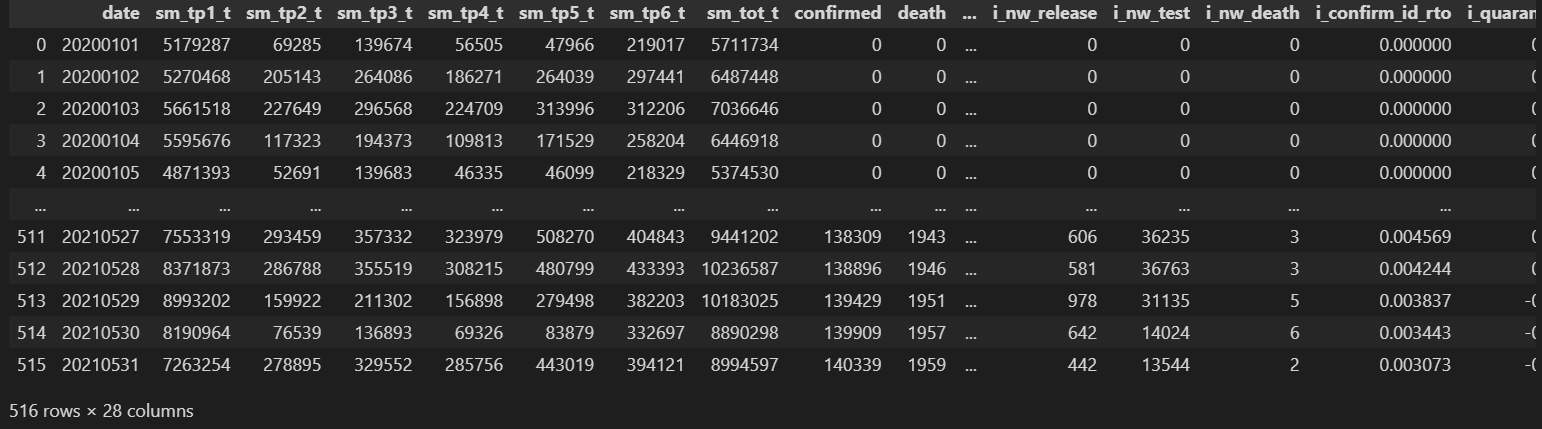
다른 csv 파일이다.
df4.to_csv('./totally_raw_data.csv', encoding='utf-8')위 코드를 실행시키면
totally_raw_data.csv
파일이 추가된다.
excel xls / xlsx
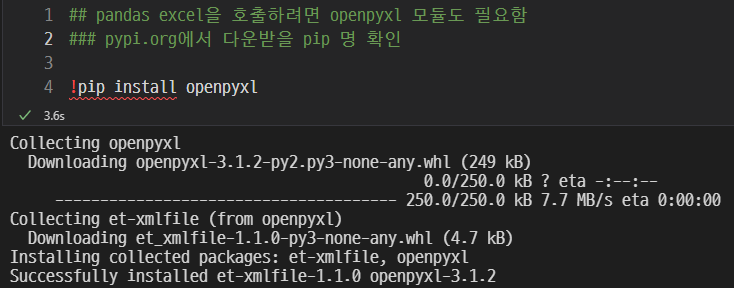
pip install openpyxl을 입력하여 openpyxl을 설치.
# excel xls(2진 binary) / xlsx (xml textfile)
df_xls = pd.read_excel('./totally_raw_data.xlsx', sheet_name='totally_raw_data')
df_xls위 코드를 실행하면
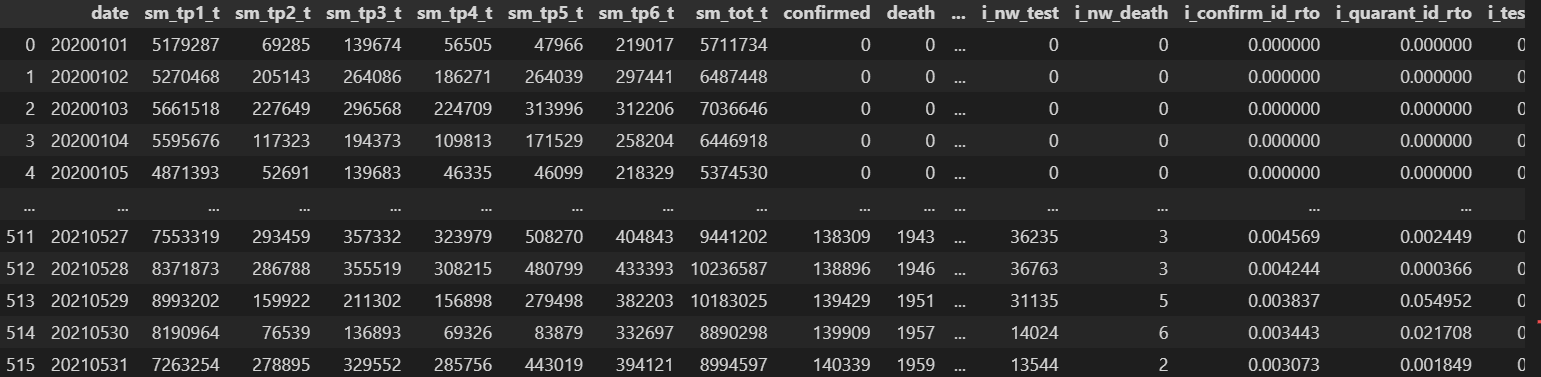
sheet name이 'totally_raw_data'인 시트가 출력된다.
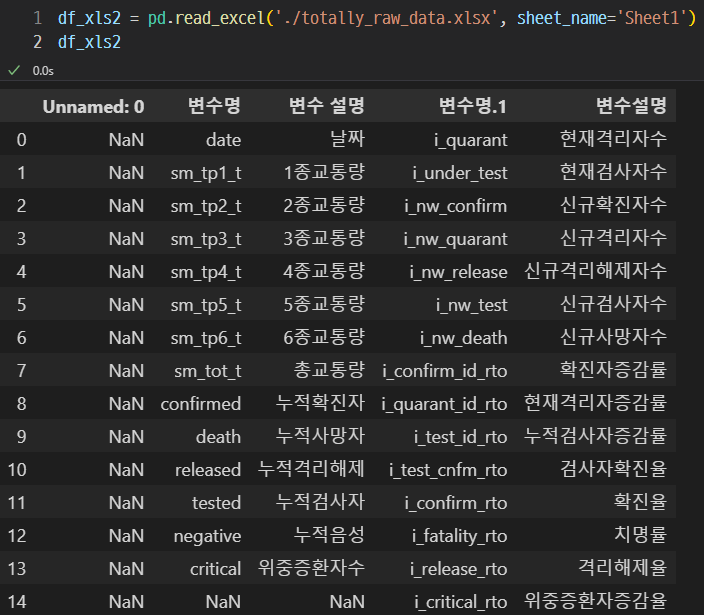
이렇게 Sheet1이 출력된다.
json
ora3.vuerd.json을 추가하고
# json 읽고 쓰기
df_json1 = pd.read_json('./ora3.vuerd.json', encoding='utf-8')
df_json1위 코드를 실행하면

이렇게 json을 읽을 수 있다.
df_json1.to_csv('./ora3_vuerd.csv', encoding='utf-8')위 코드를 실행하면

csv 파일로 저장된다.
df_json1.to_json('./ora3_vuerd2.json')
json파일 또한 저장할 수 있다.
