py25_list_adv.py
3의 배수
# 리스트 고급 사용
# 1~1000까지 사이에서 3의 배수값 리스트
list_3rd = []
for n in range(1, 1000+1) : # 1부터 1000까지
if n % 3 == 0 : # 3의 배수이면
list_3rd.append(n)
print (list_3rd)입력값

3부터 999까지 정상적으로 출력된다.
# 다른 방법
list_3rd_2 = [n for n in range(3, 1000+1, 3)] # 3부터 1000까지 3씩 올라감
print(list_3rd_2)위처럼 입력하면

역시 동일하게 같은 값이 나온다.
이 방법이 훨씬 간단하다.
list_3rd.clear() # list_3rd 값 초기화
for n in range(3, 1000+1, 3) :
list_3rd.append(n)
print (list_3rd) 이런 방법도 있다. 출력값도 역시 동일하다.
print([2 * x for x in range(1, 10+1)]) # 1부터 10까지의 값의 2배수
print([3 * x for x in range(1, 333+1)]) # 1부터 333까지의 값의 3배수
print([x for x in range(1,101) if x % 3 == 0]) # for문 if문 전부 처리
방법은 다양하므로 편한 것을 사용하자.
2중 for문
# 2중 for문
# zip하고 유사
print([(x, y) for x in ['광어', '고등어', '참치'] for y in['한돈', '한우', '한계']])
l1=[]
for x in ['광어', '고등어', '참치'] :
for y in ['한돈', '한우', '한계'] :
l1.append((x,y))
print(l1)
이렇게 2중 for문을 사용할 수 있다.
2중 if문
# 2중 if문
print([x for x in range(10+1) if x < 5 if x % 2 == 0]) # 10까지의 숫자 중에서 5보다 작은 짝수 (0포함)
for x in range(10+1):
if x < 5:
if x % 2 == 0:
l1.append(x)
print(l1)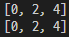
위와 같이 2중 if문도 사용할 수 있다.
print(tuple([x * 2 for x in range(1, 5+1)]))
이런 방법도 있다.
py26_std_lib.py
표준 라이브러리
date, datetime
# 표준 라이브러리
# import datetime as dt
from datetime import date, datetime
first_date = date(2022, 12, 25)
print(first_date)
cur_date = date.today()
print(cur_date)
print(cur_date - first_date)
cur_dt = datetime.now() # 많이 사용
print(cur_dt)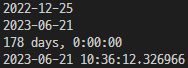
date는 날짜만, datetime은 시간도 포함된다.
time.sleep
# time.sleep
import time
for x in range(10):
print(x)
time.sleep(1.0) # second C3, java, C++ time.sleep(ms)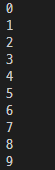
1초마다 1, 2, 3 ... 9까지 하나씩 출력된다.
math
# math
import math
print(math.pi)
파이값이 출력된다.
os
# os
import os
print(os.environ)
시스템속성 - 고급 - 환경변수의 정보라고 한다.
print(os.environ['PATH'])
환경변수값의 경로를 알 수 있다.
print(os.getcwd())
print(os.system('dir'))
print(os.system('git --version')) # 콘솔 명령어 실행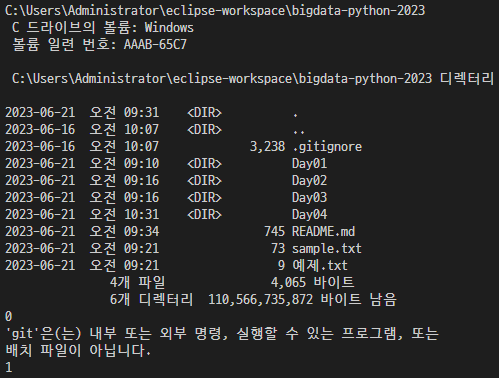
이건 뭐지
아무튼 이런 기능이 있다~
json
{
"이름" : "주세환",
"생일" : "0827",
"나이" : 25,
"man" : true
}같은 폴더에 data.json을 생성한다.
# json
import json
data = ''
with open('./Day04/data.json', mode='r', encoding='utf-8') as f:
data = json.load(f) # load -> str / loads -> byteArray
print(data)위 코드를 입력하면

data.json에 입력한 값이 출력된다.
urllib
# urllib
from urllib.request import urlopen
res = urlopen('https://www.naver.com')
print(res.status) # 200 : OK
print(res.read().decode('utf-8')) #index.html 가져옴 -> 웹 크롤링 기초urllib이다.
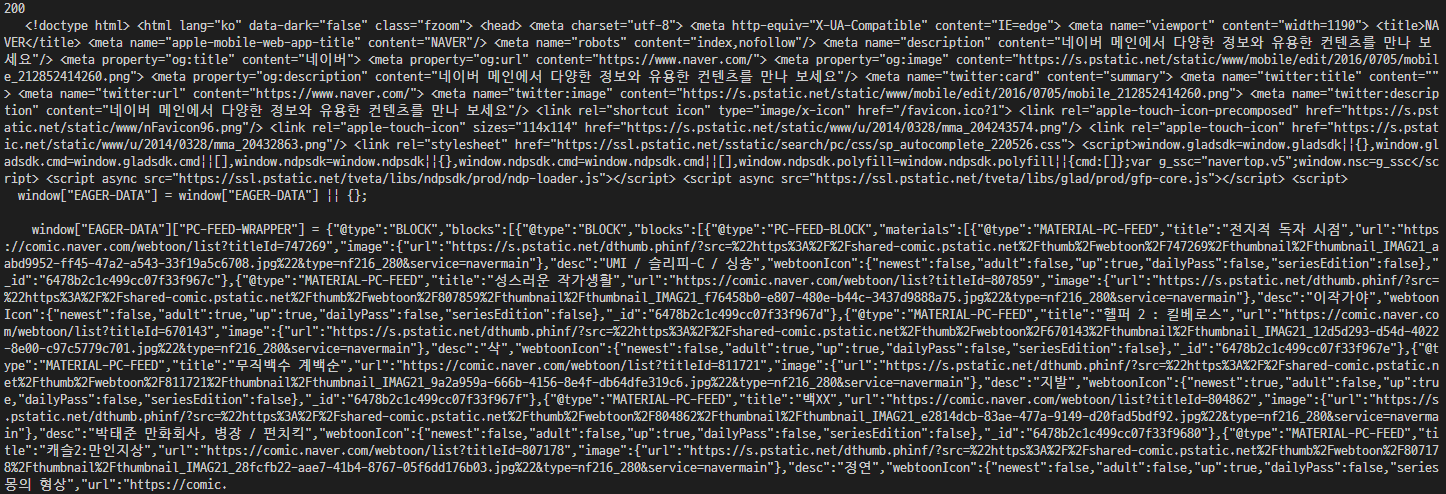
200이 출력되었다는 건 연결이 정상적으로 되었다는 뜻이다.
그 아래 출력값은 네이버에서 index.html을 가져온 것이다. 웹 크롤링이라고 한다.
py27_webbrowser.py
내부 라이브러리
크롬 열기
# webbrowser
# 크롬 브라우저로 네이버 띄우기
import webbrowser
print(webbrowser.get())
url = 'http://www.naver.com'
chrome_path = 'C:/Program Files/Google/Chrome/Application/chrome.exe %s'
webbrowser.get(chrome_path).open(url)위 코드를 입력하고 실행하면 크롬창이 실행되고 네이버로 이동한다.
- 프로그램을 종료하면 웹브라우저도 같이 종료된다.
외부 라이브러리
pip

명령 프롬프트에서 pip를 설치할 수 있다. 버전을 지정하지 않으면 최신버전을 설치하고 지정하면 지정한 버전을 설치할 수 있다. 사진처럼 1.0.4버전은 존재하지 않아서 다운이 불가능하다.

Faker도 설치하자.
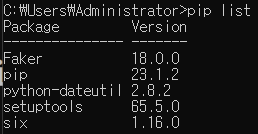
pip list를 입력하여 설치된 pip를 확인할 수 있다.

pip의 상위버전이 존재하다면
pip install --upgrade pip명 을 입력하면 최신버전으로 업데이트된다.
py28_faker_test.py
# faker 사용법
from faker import Faker
dummy = Faker('ko-KR')
print(dummy.name())
print(dummy.address())
print(dummy.company())이렇게 작성한다.

임의의 이름, 주소, 회사를 생성한다.
# 여러개의 데이터 생성
dummy_data = [(dummy.name(), dummy.postcode(), dummy.address(),
dummy.phone_number(), dummy.email()) for i in range(10)]
print(dummy_data)위처럼 작성하면

작성한 항목인 이름, 우편번호, 주소, 전화번호, 이메일을 각각 10개씩 생성한다.
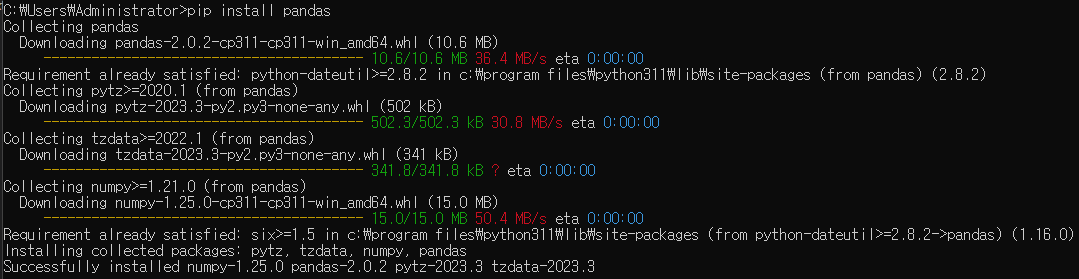
pandas를 설치한다.
# faker 사용법
from faker import Faker
import pandas as pd
dummy = Faker('ko-KR')
# 여러개의 데이터 생성
dummy_data = [(dummy.name(), dummy.postcode(), dummy.address(),
dummy.phone_number(), dummy.email()) for i in range(10)]
df = pd.DataFrame(data = dummy_data, columns=['이름', '우편번호', '주소', '전화번호', '이메일'])
df.to_csv('./Day04/dummy_members.csv', index = False, encoding='utf-8')
print('CSV 생성완료!')위처럼 수정한 후에 실행한다.

생성완료라는 출력과 함께
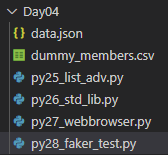
dummy_members.csv파일이 생성되었다.

우클릭 후 Open Preview를 누르면
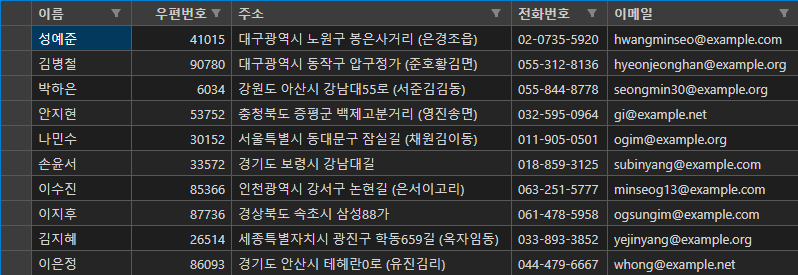
이렇게 표시된다.
df.to_csv('./Day04/dummy_members.csv', index = True, encoding='utf-8')index = True로 수정하면

앞에 번호가 추가된다.
range 값을 변경하여 데이터 갯수를 수정할 수 있다.
py29_jupyter_start.ipynb
Jupyter Notebook
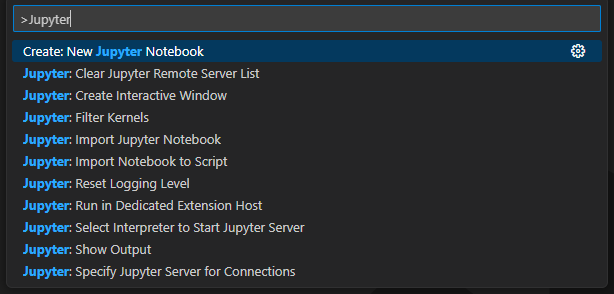
Ctrl + Shift + P 를 눌러 해당 창을 띄운 후 Create: New Jupyter Notebook을 선택
또는
.ipynb로 파일을 생성한다.

여태 쓰던 다른 파일의 인터페이스와 전혀 다르다.

Markdown을 클릭하여 Markdown에서 작성

Ctrl + Enter를 누르면 사진처럼 생성된다.
Shift + Enter 를 누르면 생성한 후에 새로운 셀이 추가된다.
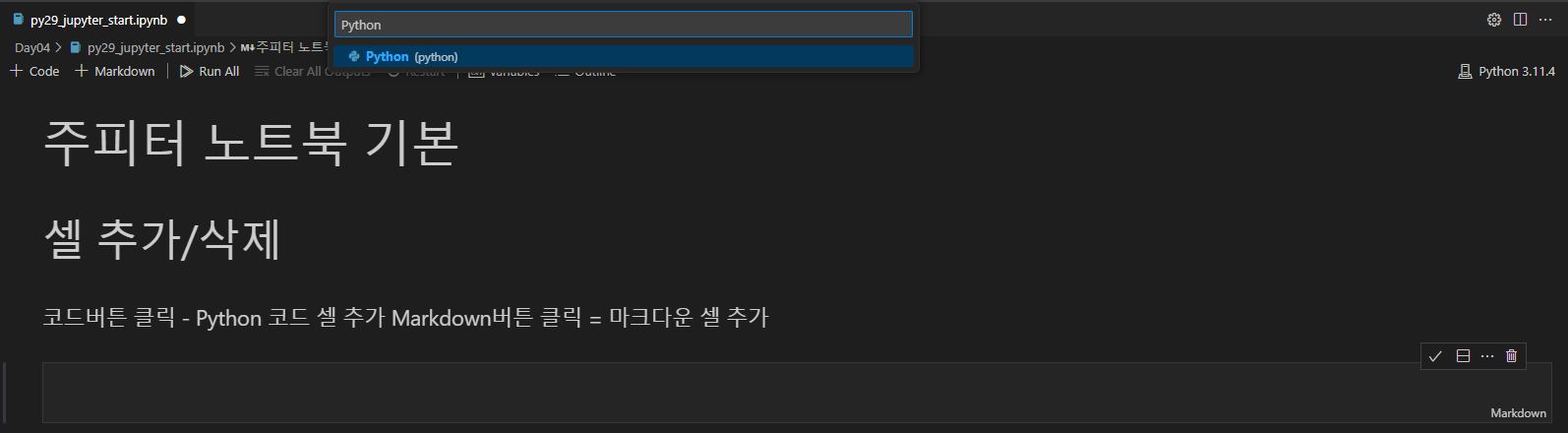
셀을 추가한 후에 오른쪽 아래 Markdown을 눌러 Python으로 변경하자.

변경하지 않으면 실행되지 않는다.

Jupyter Notebook을 처음 사용할 때 위 창이 뜬다. Install을 눌러 설치하자.
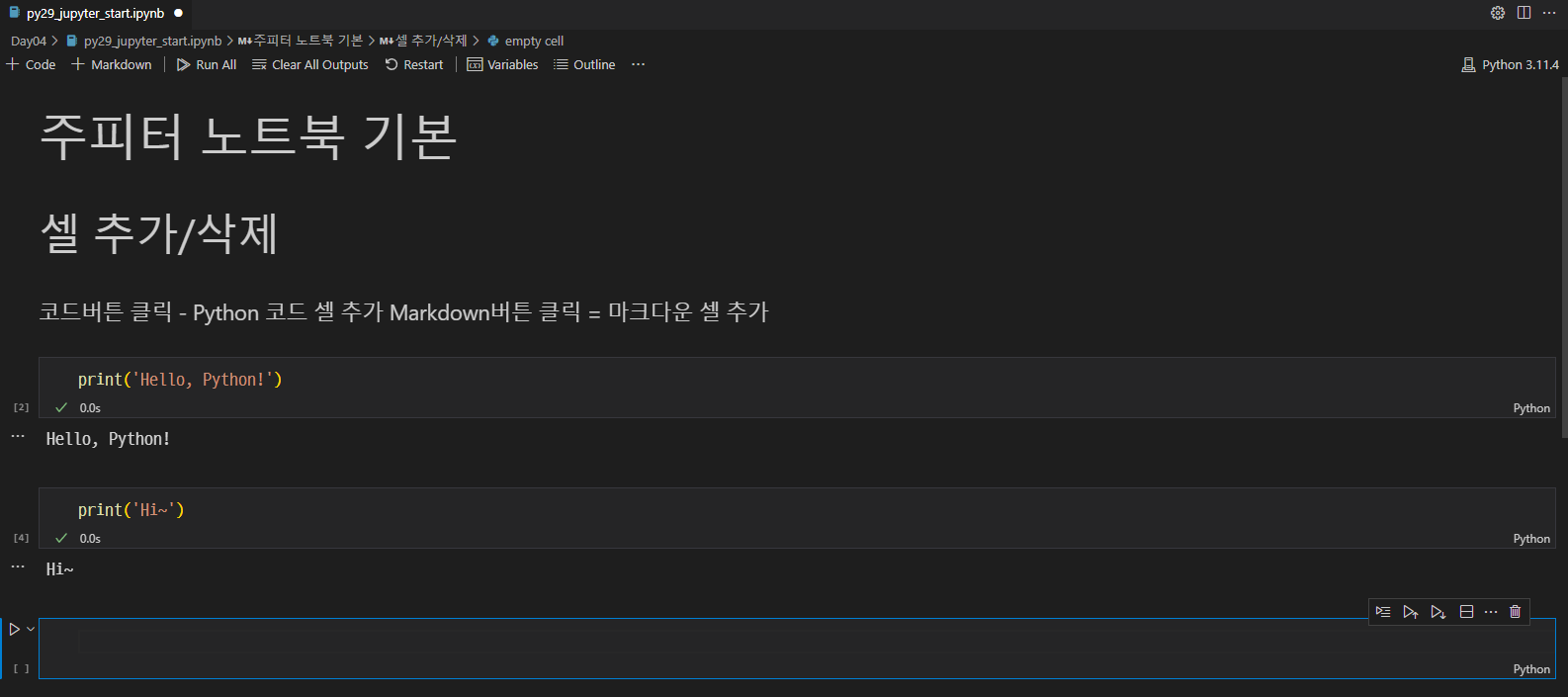
Python으로 변경하면 사진처럼 정상적으로 실행된다.
단축키 :
Ctrl + Enter : 셀 실행
Shift + Enter : 실행 후 새로운 셀 추가
Enter : 현재 셀 진입
ESC : 현재 셀 빠져나가기
B : 현재 셀 아래 새 셀 추가
A : 현재 셀 위 새 셀 추가
M : 현재 셀 (Python) -> Markdown 셀 변경
Y : 현재 셀 (Markdown) -> Python 셀 변경Shift + L : 셀 라인번호 표시 On/Off
### 이미지 추가
### 이미지 추가
<img src="http://m.seyaseya.kr/web/product/medium/201703/366_shop1_685009.jpg" width="400">
<img src="https://media.tenor.com/gcJ_J1YsR54AAAAd/parrot-cat.gif" width="400">
---
|제목|내용|비고|
|:-----|----------:|:----:|
|제목1|내용1|비고1|
|제목2|내용2|비고2|
|제목3|내용3|비고3|
|제목4|내용입니다.|비고4|
|제목입니다.|내용4|비고입니다|Markdown에 위 코드를 추가하여 셀을 실행해보자.

이렇게 실행된다.
:-- 은 왼쪽 정렬, --: 은 오른족 정렬, :--: 은 중앙정렬이다.
디버깅
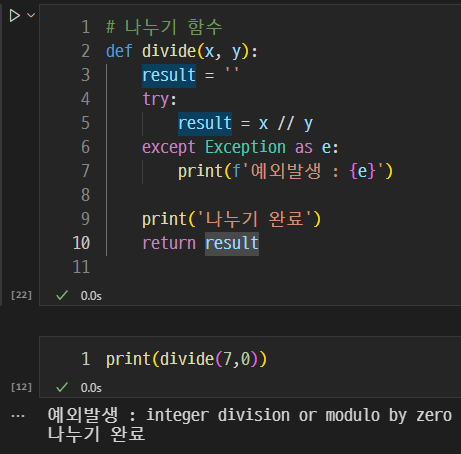
Python과 동일하게 try, except를 이용
출력 python과 차이점
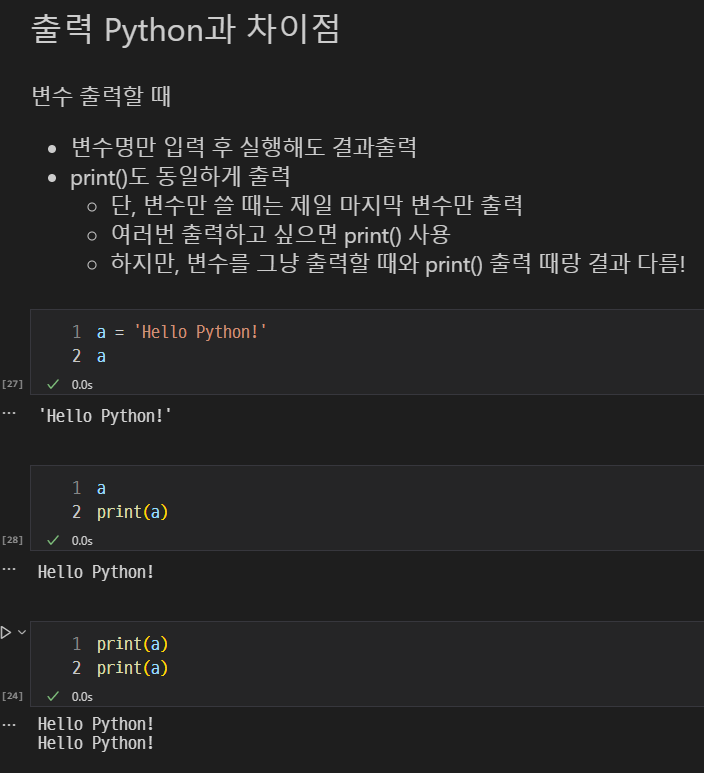
a : ''도 같이 출력
print() : ''사이에 있는 값만 출력
경로 문제
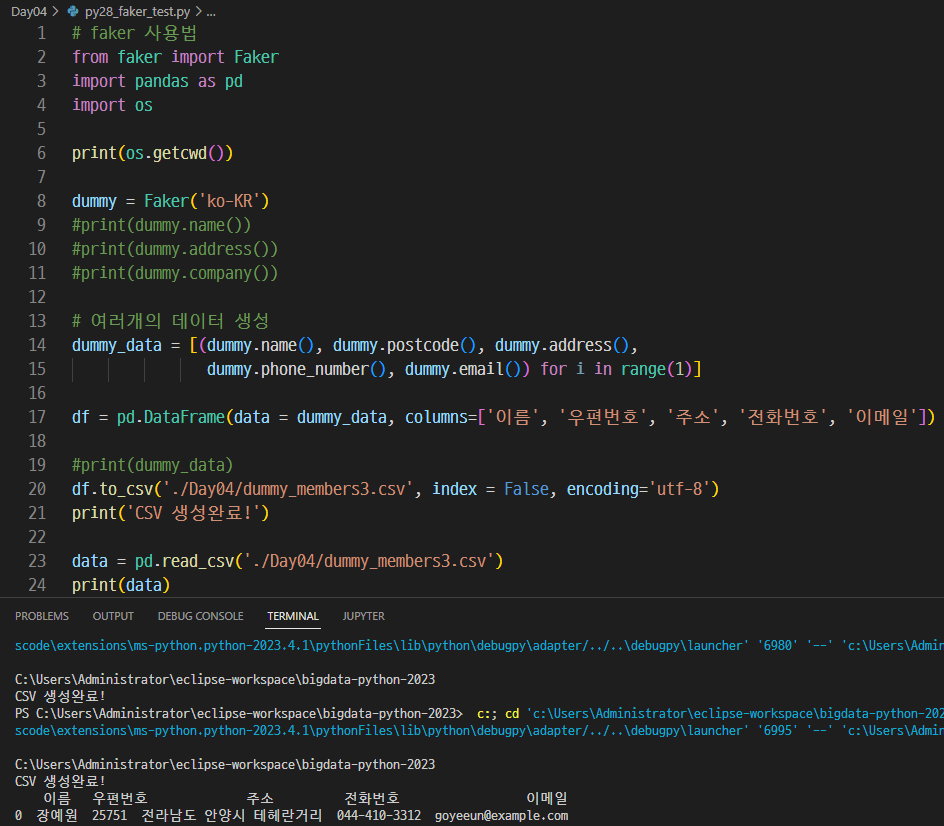
Python
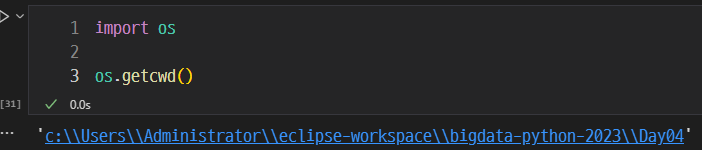
Jupyter Notebook
출력초과 문제
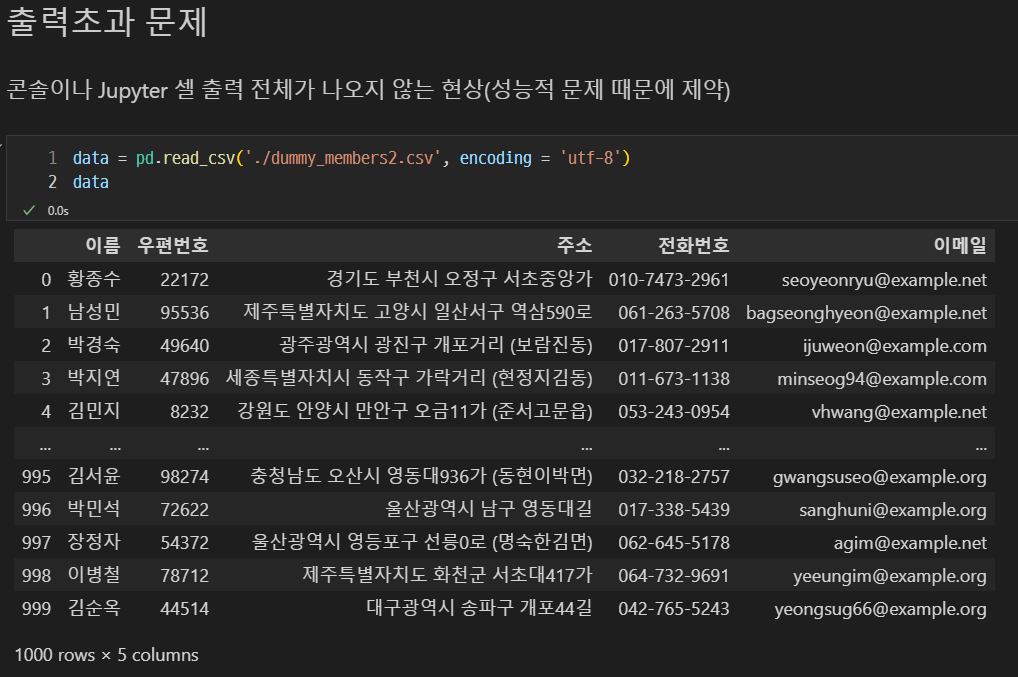
dummy_members2.csv의 데이터 수를 1000개로 수정하고 출력하였다.
값이 너무 많아 중간에 생략되었다.
pd.options.display.max_columns = None
pd.options.display.max_rows = None
data = pd.read_csv('./dummy_members2.csv', encoding = 'utf-8')
data이렇게 수정해보자.

...
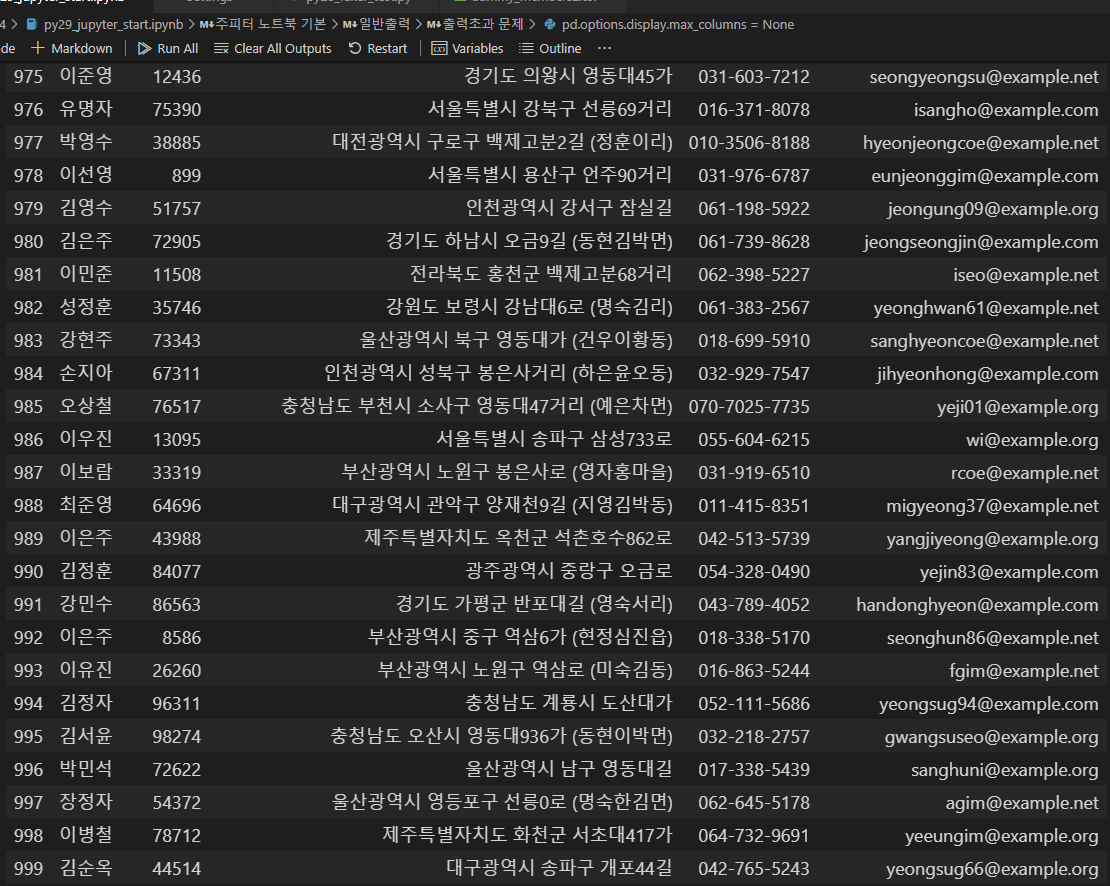
다 출력되었다.
출력할 값이 많을 때 사용해보자.
