Numpy
- 일반 list에 비해 빠르고, 메모리 효율적
- 반복문 없이 데이터 베열에 대한 처리를 지원함
- 선형 대수와 관련된 다양한 기능을 제공
import numpy as npArray.dtype # Array 전체의 데이터 Type을 반환함
Array.shape # Array의 Shape을 반환함Shape
Vector
Array = np.array([1, 2, 3, 4], float)Matrix
matrix = [[1, 2, 5, 8], [1, 2, 5, 8], [1, 2, 5, 8]]
np.array(matrix, int).shape # (3, 4)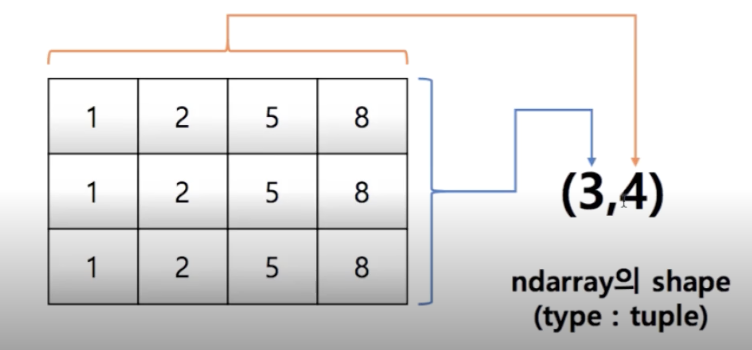
3rd Order Tensor
tensor = [[[1, 2, 5, 8], [1, 2, 5, 8], [1, 2, 5, 8]],
[[1, 2, 5, 8], [1, 2, 5, 8], [1, 2, 5, 8]],
[[1, 2, 5, 8], [1, 2, 5, 8], [1, 2, 5, 8]],
[[1, 2, 5, 8], [1, 2, 5, 8], [1, 2, 5, 8]]]
np.array(tensor, int).shape # (4, 3, 4)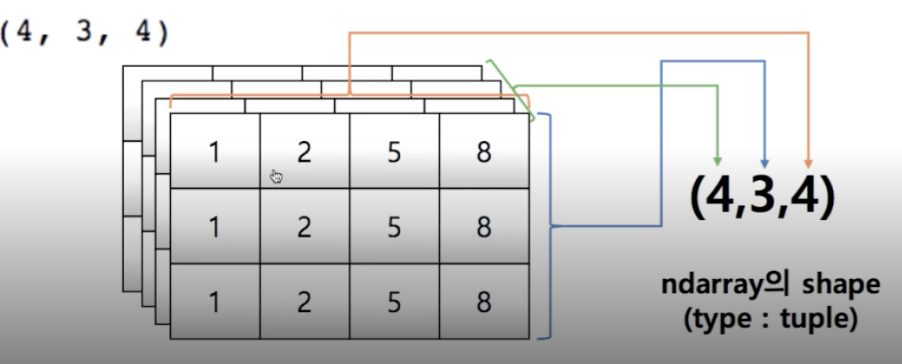
Ndim & Size
- ndim : number of dimension
- size : data의 개수
tensor = [[[1, 2, 5, 8], [1, 2, 5, 8], [1, 2, 5, 8]],
[[1, 2, 5, 8], [1, 2, 5, 8], [1, 2, 5, 8]],
[[1, 2, 5, 8], [1, 2, 5, 8], [1, 2, 5, 8]],
[[1, 2, 5, 8], [1, 2, 5, 8], [1, 2, 5, 8]]]
np.array(tensor, int).ndim # 3
np.array(tensor, int).size # 48reshape
- Array의 shape의 크기를 변경함
- Array의 size만 같다면 다차원으로 자유롭게 변경함
- -1 : size를 기반으로 row 개수 선정
matrix = [[1, 2, 3, 4], [1, 2, 3, 4]]
np.array(matrix, int).shape # (2, 4)np.array(matrix, int).reshape(2, 2, 2)
# [[[1, 2],
[3, 4]],
[[1, 2],
[3, 4]]]flatten
- 다차원 Array를 1차원 Array로 변환
tensor = [[[1, 2, 5, 8], [1, 2, 5, 8], [1, 2, 5, 8]],
[[1, 2, 5, 8], [1, 2, 5, 8], [1, 2, 5, 8]],
[[1, 2, 5, 8], [1, 2, 5, 8], [1, 2, 5, 8]],
[[1, 2, 5, 8], [1, 2, 5, 8], [1, 2, 5, 8]]]
np.array(tensor, int).shape # (4, 3, 4)
np.array(tensor, int).flatten().shape # (48,)indexing
a = np.array([[1, 2, 3], [4, 5, 6]], int)
print(a[0, 0]) # 1
print(a[0][0]) # 1slicing
b = np.array([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]], int)
print(b[:, 2:]) # 전체 row 2열 이상 [[ 3 4 5], [ 8 9 10]]
print(b[1, 1:3]) # 1 row의 1열 ~ 2열 [7 8]
print(b[1:3]) # 1 row ~ 2row 전체 [[ 6 7 8 9 10]]Creation Function
arange
- Array의 범위를 지정하여, 값의 list를 생성
np.arange(5) # array([0, 1, 2, 3, 4])zeros, ones, empty
np.zeros(shape=(5, ), dtype=np.int8) # array([0, 0, 0, 0, 0], dtype=int8)
np.ones(shape=(5, ), dtype=np.int8) # array([1, 1, 1, 1, 1], dtype=int8)
np.empty(shape=(5, ), dtype=np.int8) # array([0, 0, 0, 0, 0], dtype=int8)something_like
- 기존 ndarray의 shape 크기 만큼 1, 0 또는 empty array를 반환
matrix = np.arange(10).reshape(2, 5)
np.ones_like(matrix)
# array([[1, 1, 1, 1, 1],
# [1, 1, 1, 1, 1]])identity
- 단위 행렬을 생성
np.identity(n=3, dtype=np.int8)eye
- 대각선인 1인 행렬, k 값의 시작 index의 변경이 가능
np.eye(N=3, M=5, k=2)
# array([[0., 0., 1., 0., 0.],
# [0., 0., 0., 1., 0.],
# [0., 0., 0., 0., 1.],
# [0., 0., 0., 0., 0.]])diag
- 대각 행렬의 값을 추출함
matrix = np.arange(9).reshape(3, 3)
np.diag(matrix) # array([0, 4, 8])random sampling
np.random.uniform(0, 1, 10).reshape(2, 5) # 균등 분포
np.random.normal(0, 1, 10).reshape(2, 5) # 정규 분포Operation Functions
sum
- ndarray의 element들 간의 합을 구함
Array = np.arange(1, 11)
Array.sum(dtype=np.float) # 55.0axis
- 모든 Operation Functions을 실행할 때, 기준이 되는 dimension 축
Array = np.arange(1, 13).reshape(3, 4)
Array.sum(axis=0) # array([15, 18, 21, 24])
Array.sum(axis=1) # array([10, 26, 42])
mean & std
- ndarray의 element들 간의 평균 또는 표준 편차를 구함
Array = np.arange(1, 13).reshape(3, 4)
Array.mean(axis=0) # array([5., 6., 7., 8.])
Array.std(axis=0) # array([3.26598632, 3.26598632, 3.26598632, 3.26598632])concatenate
- Numpy array를 합치는 함수
a = np.array([1, 2, 3])
b = np.array([2, 3, 4])
np.vstack((a, b))
# array([[1, 2, 3],
# [2, 3, 4]])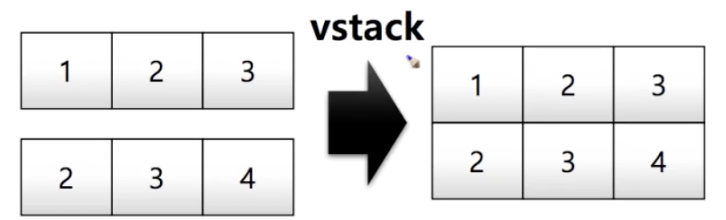
a = np.array([1, 2, 3])
b = np.array([2, 3, 4])
np.concatenate((a,b), axis=0)
# array([[1, 2, 3],
# [2, 3, 4]])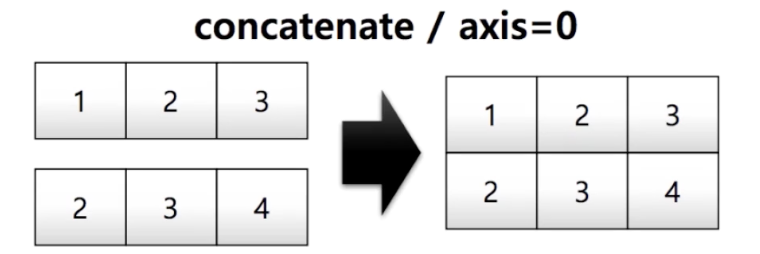
a = np.array([[1], [2], [3]])
b = np.array([[2], [3], [4]])
np.hstack((a, b))
# array([[1, 2],
# [2, 3],
# [3, 4]])
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]])
np.concatenate((a,b.T), axis=1)
# array([[1, 2, 5],
# [3, 4, 6]])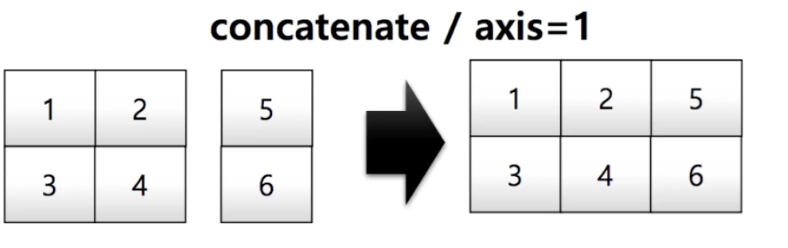
Array Operations
사칙 연산
a = np.array([[1, 2, 3], [4, 5, 6]])
a + a # array([[ 2, 4, 6], [ 8, 10, 12]])
a - a # array([[0, 0, 0], [0, 0, 0]])
a * a # array([[ 1, 4, 9], [16, 25, 36]])Element wise operations
- Array간 shape이 같을 때 일어나는 연산
matrix = np.arange(1, 13).reshape(3, 4)
matrix * matrix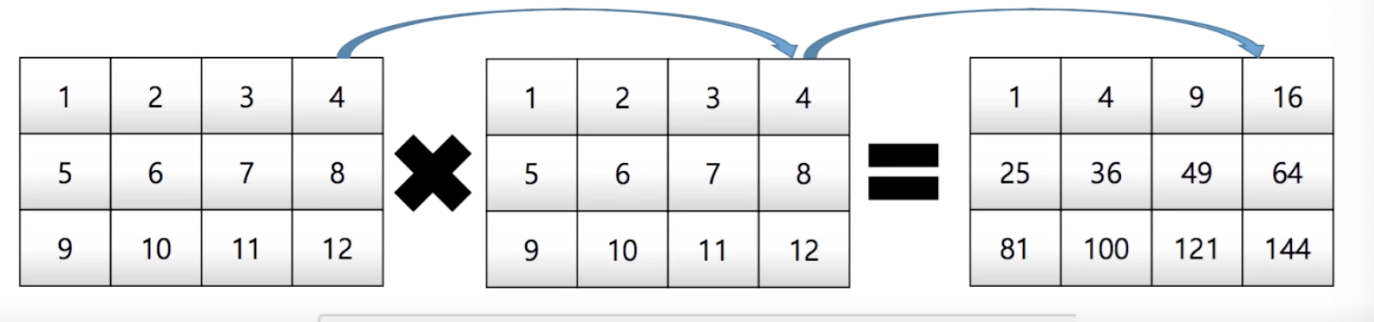
Dot Product
a = np.arange(1, 7).reshape(2, 3)
b = np.arange(1, 7).reshape(3, 2)
a.dot(b)
# array([[22, 28],
# [49, 64]])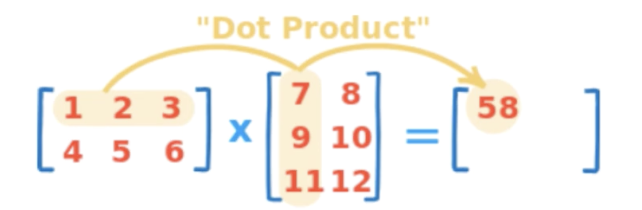
transpose
a = np.arange(1, 7).reshape(2, 3)
a.T
a.transpose()broadcasting
matrix = np.array([[1, 2, 3], [4, 5, 6]], float)
scalar = 3
matrix + scalar
Comparisons
All & Any
- any : 하나라도 조건에 만족한다면 True
- all : 모두가 조건에 만족한다면 True
a = np.arange(10)
np.any(a > 5), np.any(a < 0) # (True, False)
np.all(a > 5), np.all(a < 10) # (False, True)np.where
np.where(a > 0, 3, 2)
# array([[3, 3, 3],
# [3, 3, 3]])argmax & argmin
- Array 내 최대값 또는 최소값의 index를 반환함
a = np.array([1, 2, 4, 5, 8, 78, 23, 3])
np.argmax(a), np,argmin(a) # (5, 0)a = np.array([[1, 2, 4, 7], [9, 88, 6, 45], [9, 76, 3, 4]])
np.argmax(a, axis=1), np.argmin(a, axis=0) # (array([3, 1, 1]), array([0, 0, 2, 2]))boolean index
Array = np.array([1, 4, 0, 2, 3, 8, 9, 7])
Array > 3 # array([False, True, False, False, False, True, True, True])
Array[Array > 3] # array([4, 8, 9, 7])fancy index
a = np.array([2, 4, 6, 8], float)
b = np.array([0, 0, 1, 3, 2, 1], int)
a[b] # array([2., 2., 4., 8., 6., 4.])
a.take(b) # array([2., 2., 4., 8., 6., 4.])
🌳가 되기 위해 🌱부터 시작