NLP theory
1.NLP 개요

NLU와 NLG로 나뉜다.NLU(Natural language understanding): 언어에서 의도한 바를 이해하는 것NLG(Natural language generation): machine이 nl을 어떻게 생성할지 가르치는 영역.Major conference:
2.Bag-of-Words
Bag-of-Words 딥러닝 이전에 단어를 숫자로 나타내는 기법. Bag-of-Words Representation 1. Constructing the vocabulary conatining unique words. 여러 문장에 걸쳐 중복되게 사용된 단어라도 Voc
3.Word Embedding

문장의 단어들을 벡터 공간 상의 점으로 표현하기 위해, 단어들을 벡터로 변환하는 방법.Word Embedding 자체가 딥러닝, 머신러닝 기술이다. 학습 데이터, 사전에 정의한 벡터 공간의 차원 수를 통해 핛브을 진행한다. 학습이 완료되면 학습 데이터, 즉 특정 단어에
4.NLP 전처리
ref: https://bkshin.tistory.com/entry/NLP-3-%EB%B6%88%EC%9A%A9%EC%96%B4Stop-word-%EC%A0%9C%EA%B1%B0분석에 큰 의미가 없는 단어들. a, an, the와 같은 관사나 I, my 같은
5.RNNs
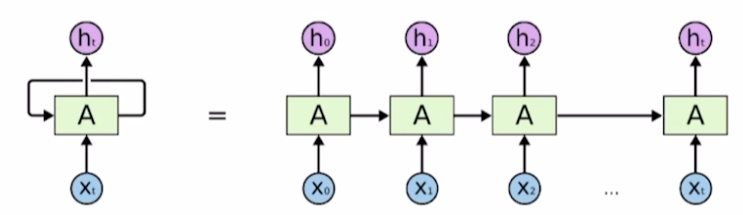
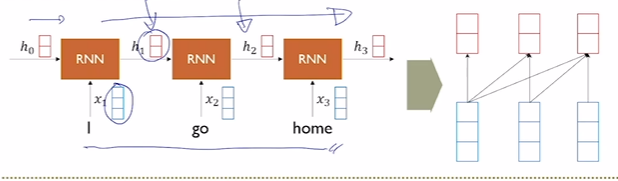
sequence data가 입출력으로 주어진 상태에서 t에서의 입력 $xt$와 이전 hidden state인 $h{t-1}$을 입력으로 받고 $h_t$를 출력하는 네트워크.중요한 것은 매 time stamp마다 새로운 model이 등장하는 것이 아니라, 하나의 para
6.LSTM, GRU
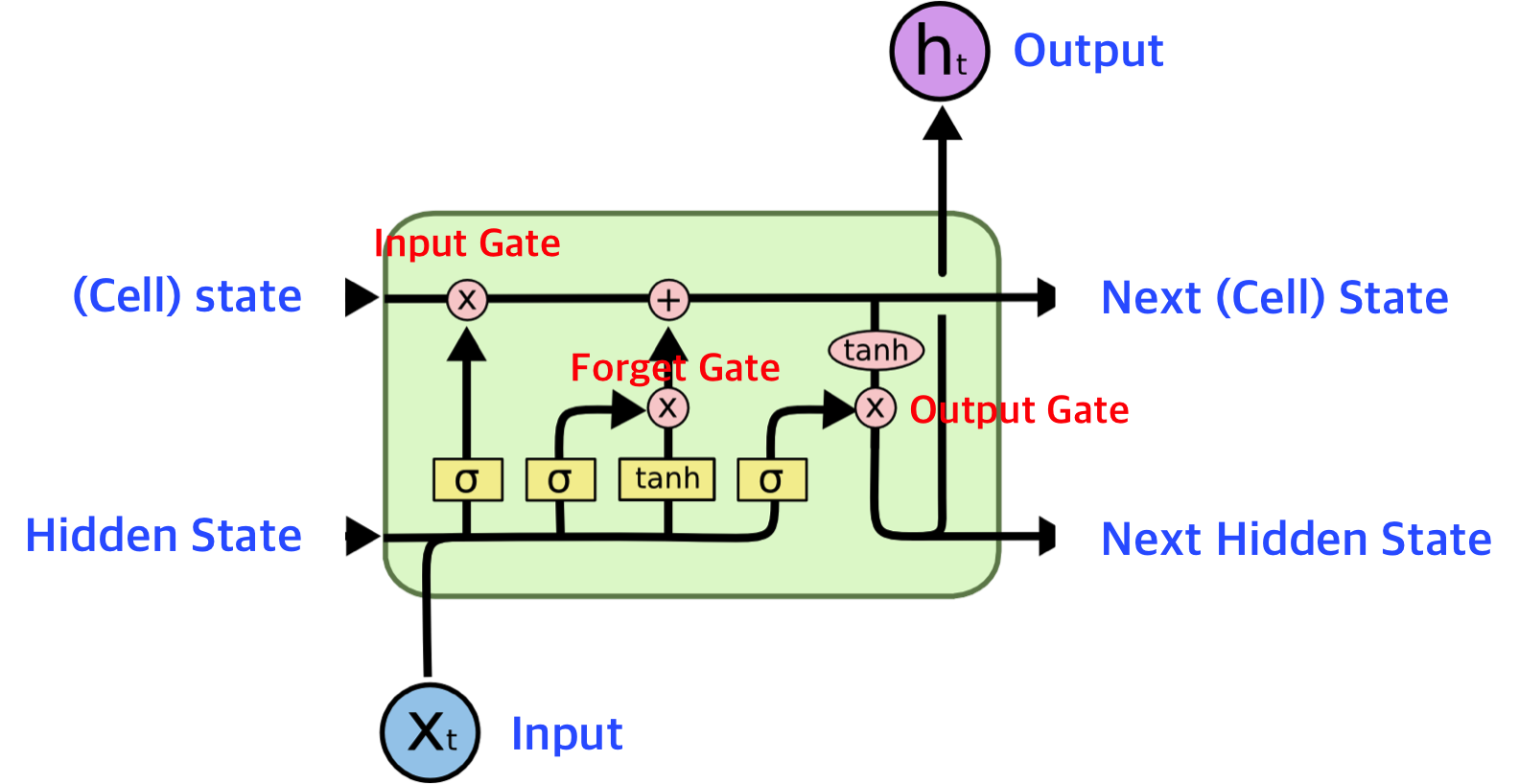
Long short-term memory.RNN이 가진 Long term dependency를 해결한 모델. 먼 time step의 정보를 잘 전달하기 위해 만들어졌다. hidden state를 마치 단기 기억 소자처럼 보고, 단기 기억 소자가 보다 긴 시간 동안 생존
7.Attention
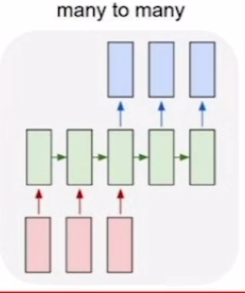
Seq2Seq는 RNN의 구조 중 many to many에 해당한다. 즉, 입출력 모두 sequenece인 word 단위의 문장.위 그림은 Dialog system(e.g., chat bot)이다. 입력 문장을 받아들이는 부분이 encoder, 출력 문장을 생성하는 부
8.Beam search
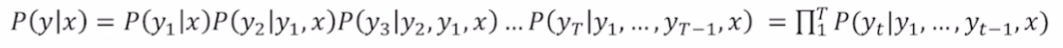
이전 포스팅의 attention이나 LSTM들은 특정 step에서 다음 단어를 예측할 때, 가장 확률이 높은 하나의 단어를 선택한다. 이러한 방법을 greedy decoding이라고 한다.전체적인 맥락에서 예측하는 것이 아니라 근시안적으로 가장 좋은 방법을 택하기 때문
9.BLEU
일반적인 precision이나 recall을 계산하면 Seq2Seq에서는 모든 지표가 0에 가까울 것이다. 왜냐하면 step별로 비교하면 대부분 일치하지 않을 확률이 매우 높기 때문이다. 즉, 아래처럼 굉장히 유사한 문장의 지표가 0에 가깝게 나올 수도 있다.그래서 이
10.Transformer 도입
'Attention is all you need'(2017) 논문 이전의 attention은 LSTM, GRU에 add-on처럼 쓰일 뿐이었다. 해당 논문에서는 기존의 RNN 모델을 완전히 탈피하고 attention을 사용한 새로운 Seq2Seq 모델을 제시했다.
11.Transformer
Multi-Head Attention(MHA) 기본 구조는 이전 포스팅에서 다룬 transformer와 동일하게 Q, K, V를 입력으로 받고 Scaled-Dot Product Attention을 수행해서 Encoding vector를 얻는다. 다른 점은 trans
12.Self-supervised Pre-training models
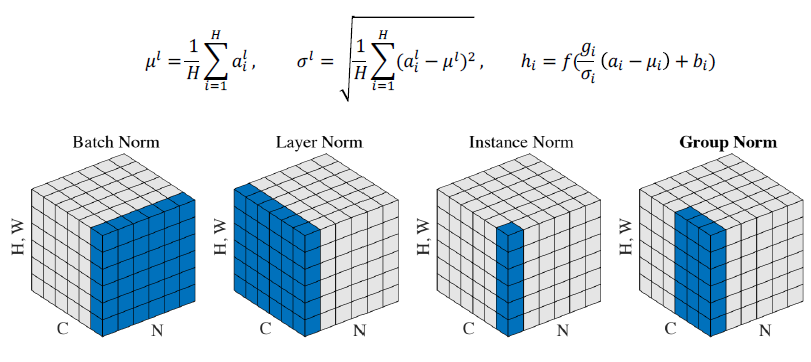
transformer, self-attention은 기계번역 외의 분야에서도 쓰이고 있다!transformer 논문에서 제시된 것처럼 6개의 transformer를 쌓지 않고 12개, 24개 혹은 그 이상으로 쌓는 것만으로도 성능 향상이 있는 것이 실험적으로 밝혀졌다.
13.Advanced Self-supervised Pre-training model

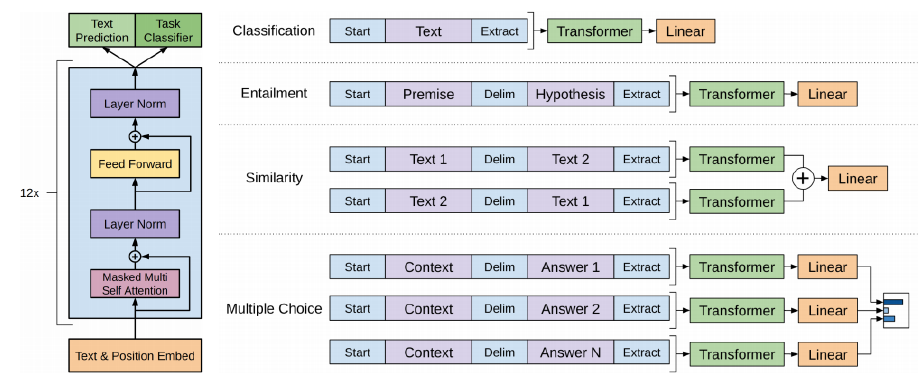
GPT-1과 기본적인 구조는 같다. Transformer layer를 보다 더 많이 쌓았다.다음 단어를 예측하는 task로 학습을 진행.더 많은 학습 데이터 사용보다 양질의 데이터 사용zero-shot setting으로 다뤄질 수 있는 잠재적인 능력을 보여줬다ref:
14.Recent trends of NLP

BERT, GPT와 같은 self-supervised learning의 가장 큰 수혜자라고 할 수 있는 영역이다. Question과 context가 주어진다.context는 문맥이라고 이해하면 되는데 사용되는 분야마다 의미가 조금씩 달라진다고 한다. Multiple-c
15.NLP 헷갈렸던 점들
nlp 모델의 출력에 대해 argmax를 쓰지 않는 이유는 자명하다. 왜냐하면 argmax는 classification과 같이 모델의 출력이 하나의 답을 얻도록 유도하기 때문이다. 가령, 입력 $X_n$에 대한 모델의 출력에 softmax를 거친 결과물이 0.2, 0.
16.GPT 언어 모델
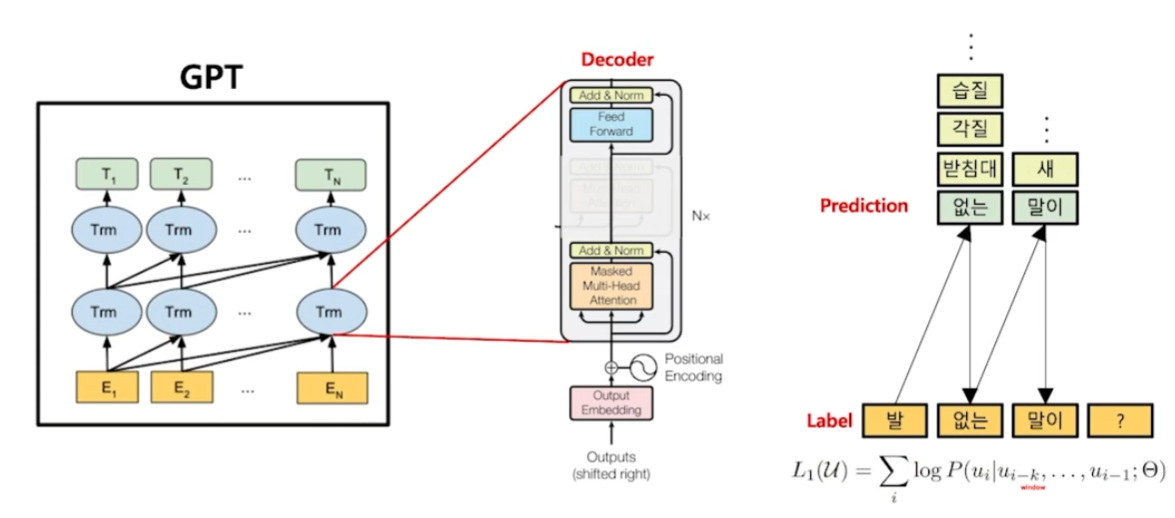
BERT: embedding 모델Transformer encoder 사용GPT: 생성 모델Transformer decoder 사용일반적으로 배웠던 Language model의 언어 생성 과정과 동일하다. 순차적으로 다음에 올 가장 적절한 단어들을 확률적으로 예측한다.G
17.최신 모델
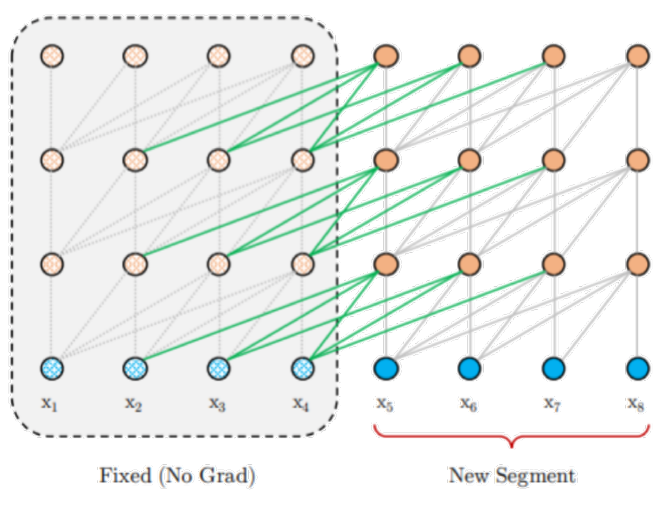
기존의 모델들의 문제점BERT MASK 토큰을 독립적으로 예측하기 때문에 Token 사이의 관계 학습이 불가능Embedding length의 한계로 Segment간 관계 학습 불가능GPT단일 방향성으로만 학습이러한 한계를 극복하고자 XLNet이 등장한다.512 toke