GPT-2
GPT-1과 기본적인 구조는 같다.
- Transformer layer를 보다 더 많이 쌓았다.
- 다음 단어를 예측하는 task로 학습을 진행.
- 더 많은 학습 데이터 사용
- 보다 양질의 데이터 사용
- zero-shot setting으로 다뤄질 수 있는 잠재적인 능력을 보여줬다
ref: zero shot learning
한 번도 보지 못한 데이터를 분류 가능하도록 학습하는 것.

GPT-2의 기본적인 task는 위와 같이 지문이 주어지면 순차적으로 다음에 올 단어들을 에측하는 language model이다. 소설과도 같은 지문이 주어졌을 때, 실제 사람이 쓸 법한 공상적인 이야기를 이어서 썻다.
decaNLP, motivation of GPT-2
기존의 nlp task는 task별로 다른 모델 구조와 해결 방법을 고안해야했다. 가령, 문장의 긍/부정을 판단하기 위해서는 CLS token을 output layer에 통과시킨 후 이를 binary classification에서 사용한다. 혹은 QnA를 진행하기 위해서 QnA만을 위한 모델 구조를 별도로 고안해야 했다.
GPT-2로부터 3~4년 전의 decaNLP에서는 모든 NLP task를 질의응답으로 통합해서 구성할 수 있다는 것이 요지다. 즉, 모든 task를 자연어 생성 task로 간주하는 것이다.
e.g., 문장의 긍/부정 판단 task를 다음과 같이 구성한다.
1. 임의의 문장을 입력 후
2. 'What do you think about this document in terms of positive or negative?'라는 질문을 추가로 입력
3. 모델이 1번 문장에 대한 긍/부정 판단을 기대한다.
2번의 질의 문장은 자유롭게 바꿀 수 있다. 'Do you think wheter this sentence is postivie or negative?'처럼 말이다.
문단의 요약을 원한다면 'What is the summarization of the above paragraph?'를 1번 문장 다음에 추가하면 된다.
Dataset of GPT-2
양질의 글으 얻기 위해 아래의 웹 사이트들을 dataset으로 사용했다고 한다.
- Reddit
- 3개 이상의 karam(up-vote)를 받은 discussion이 외부 링크를 포함하고 있다면, 해당 링크의 document가 양질의 데이터를 포함하고 있다고 가정
- 이러한 방식으로 Reddit의 데이터와 Reddit에서 참조하는 외부 링크들의 document를 dataset으로 활용
- 45M links 수집
- 8M removed Wikipedia documents
- Dragnet(경찰 시리즈물인 것 같다)
- newspaper
Preprocess
- BPE(Byte pair encoding)
- Minimal fragementation of words across multiple vocab tokens
Modification of models
- Layer normalization
- sub-block 단위로 수행하거나 기존의 normalization 위치를 변경
- Initialization of weight in residual Layer
- Residual Layer의 index가 커질수록 weight 초기화 값을 에 반비례하게 만들었다.
- Output에 가까워질수록 Layer의 선형변환의 출력들이 0에 가까워지도록 하기 위함이다.
- 뒤쪽 layer의 역할을 줄여주는 것이 목적.
- 멘토님 답변: 모델의 뒤로 갈수록 high dimentional한 특징을 학습하는데, 이러한 feature에 영향을 덜 받기 위해서?
Question Answering
CoAQ(Conversationi question answering dataset)을 사용.
- 해당 데이터셋을 전혀 사용하지 않은채로 테스트할 경우
- F1 score = 55%
- Fine tuned 후
- F1 score = 89%
Summarization

이 부분은 교수님의 설명이 부족한 것 같아 좀 더 찾아봐야 될 것 같다. 모든 학습 데이터에 대해서 TL;DR; token이 존재할리가 없는데..
GPT-2의 학습 데이터에는 TL;DR; token의 등장 이후에 한 줄 요약을 하는 데이터가 많다. 따라서 zero-shot learning처럼 별도의 fine tuning 없이 원하는 지문의 끝에 Tl;DR; token을 붙이는 것만으로도 summarization task를 수행할 수 있다고 한다.
Translation
Summarization의 TL;DR; token처럼, 번역하고자 하는 문장의 뒤에 'in French'와 같은 문구를 추가하면 translation task를 수행한다.
GPT-3
GPT-2보다 굉장히 많은 parameters, transformer layer, batch size로 학습해보니 GPT-2보다 좋은 모델이 나왔다고 한다.
Few-shot learning
GPT-2에서는 zero-shot, few-shot learning에 대한 가능성을 보여줬다면 GPT-3는 이에 대한 매우 좋은 성능을 보여줬다.

모델을 전혀 변경하지 않고 아래의 inference task를 수행했다.
- Zero-shot: GPT-3는 번역 데이터를 학습하지 않았지만, 별도의 fine tuning을 전혀 하지 않고도 translation이 가능했다.
- One-shot: 학습 데이터에 대한 예시를 한 쌍만 보여준다.
- Few-shot: 학습 데이터에 대한 예시를 여러 쌍을 보여준다.
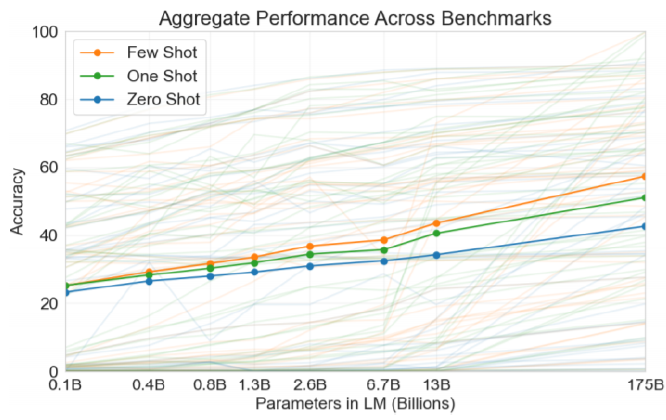
모델의 크기(parameter의 개수)를 늘릴수록 zero-shot, one-shot, few-shot에 대한 성능은 계속 증가한다. 모델이 클수록 모델의 동적인 학습 능력이 올라갔음을 알 수 있다.
ALBERT
A Lite BERT.
BERT, GPT와 같은 거대 모델을 self-supervised learning으로 학습하기 위해서는 많은 메모리, parameters, batch size가 필요하다. 하지만 이러한 자원은 한정적이다. 이를 경량화하면서 오히려 BERT보다 더 좋은 성능을 가진 모델이 ALBERT다.
- Obstacles
- Memory Limitation
- Training speed
- Solutions
- Factoried Embedding Parameterization
- Cross-layer Parameter Sharing
- (For performance) Senetence Order Prediction
Factorized Embedding Parameterization
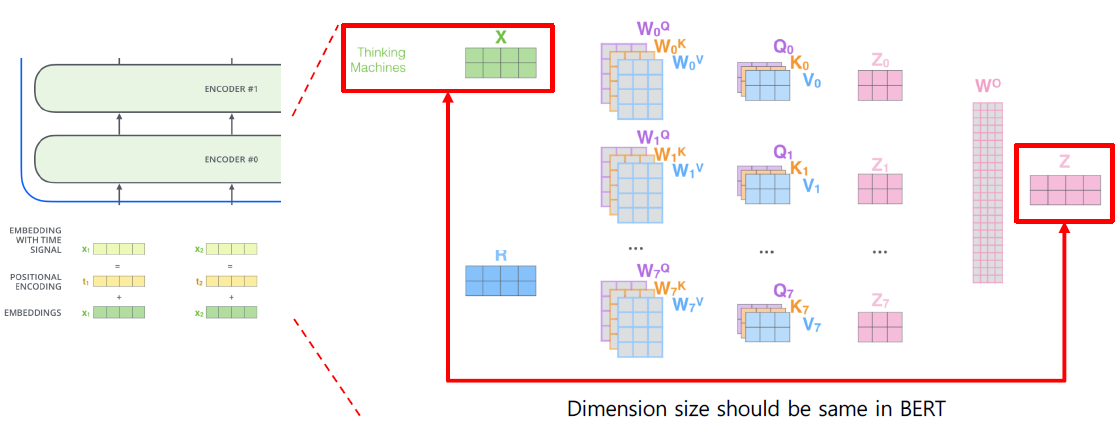
- 기존 transformer: transformer 내의 residual block 때문에 Embedding의 차원과 출력 차원이 동일해야하기 때문에, 모든 Layer의 입출력 차원들은 같다.
- ALBERT: Layer별 출력 차원들을 축소시키자.
Motivation
- Embedding layer: 문맥을 전혀 고려하지 않고 Word만이 가진 정보를 상수로써 표현하는 vector
- hidden state vector: 문맥이 고려된 semantic한 정보들을 포함하고 있는 vector
Embedding layer는 hidden state vector에 비해 담고 있는 정보가 적다. 따라서 Embedding layer를 쪼개서 보다 작은 차원으로 표현해보자.
Implementation
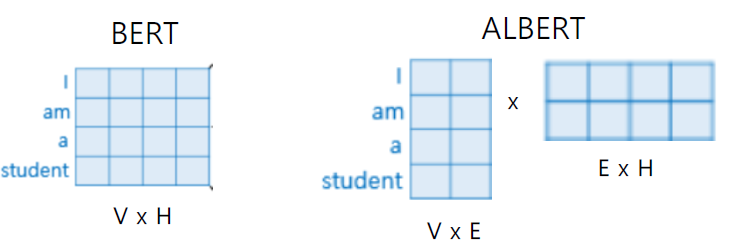
본래 4차원으로 word들이 Embedding 된다고하자. 그러면 위 도식과 같이 Word embedding layer 또한 4차원이다. 이러한 Embedding layer를 2차원으로 줄이여서 모델에 입력하고자 한다.
위 도식에서 V x E에 해당하는 layer를 transformer의 입력으로 준다면 transformer의 paramters 수는 이전보다 줄어들 것이다.
residual 연산을 위해서는 입력 차원과 동일해야하는데, transformer는 2차원을 출력할 것이다. 따라서 residual 이전에 위 도식의 E x H와 같이 본래 차원으로 되돌려주는 layer를 추가한다. 결과적으로 transformer의 parameter는 줄고 출력은 입력과 동일해진다. 이러한 방식을 Low rank matrix factorization이라고 한다.
Factorized Embedding Parameterization은 기존의 Word Embedding 결과를 그대로 사용하는 것에 근사하는 결과를 보여주는 것으로 알려져 있다.
Cross-layer Parameter Sharing
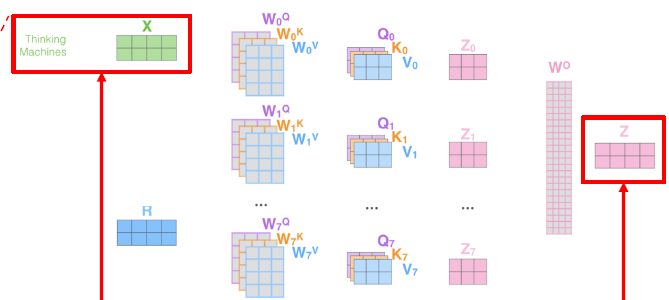
transformer에서 학습이 진행되는 parameters는 self-attention layer별로 가지고 있는 와 concatenate된 matrix의 차원을 줄여주는 이다. transformer를 쌓을수록 parameter의 수가 늘어나는데, ALBERT에서는 이 parameter들을 self-attetion들이 공유하도록 해봤다.
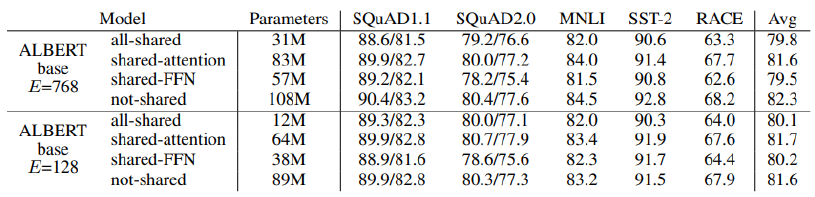
- Shared-FFN: Only sharing feed-forward network parmeters
- Shared-Attnetion: Only sharing attention parameters
- All-shared: Both of them
All-shared를 해도 not-shared에 비해서 성능이 나쁘지 않다.
Sentence Order Prediction
BERT는 두 가지 형태로 학습이 진행된다.
- Maksed language modeling: k%를 mask token으로 치환 후 학습
- Next sentence prediction: 두 문장을 sep token으로 concat후 학습
BERT의 next sentence prediction 실효성이 없다는 연구결과들이 나았다. next sentence prediction을 학습 과정에서 제외하고 masked language modeling만을 수행해도 모델의 성능이 좋기 때문이다.
왜냐하면 next sentence prediction에서 negative samples를 판단하는 것은 유사한 단어가 나타나는지 파악만 해도 가능하기 때문이다.
e.g., 사회면의 기사와 스포츠면의 기사는 내용과 사용되는 단어들이 매우 상이하기에 두 분야에서 sampling한 단어들은 next sentence가 아님을 쉽게 예측 가능하다.
next sentence 관계에 있는 문장들은 동일하거나 유사한 단어들이 자주 등장할 것이다. next sentence 판별이 또한 예측이 매우 쉬워진다.
고차원적인 판단이 아니라 단어의 출현을 기반으로 next sentence prediction을 수행하기 때문에, 이렇게 학습된 모델은 얻게 next sentence prediction으로부터 얻은 정보가 많지 않을 것이다
ALBERT는 next sentence prediction을 변형해서 sentence order prediction으로 학습을 진행했다.
이 방법론은 올바른 순서의 두 문장을 concat해서 모델에 입력하면 올바른 순서라고 인지해야 한다. 반대로 올바르지 않은 순서의 두 문장(Negative smaples)을 concat해서 모델에 입력하면 올바르지 않은 순서라고 인지해야 한다.
overlapped 되는 단어들이 거의 없도록 두 문장을 뽑기 위해서 동일 문서에서 sampling을 한다. 단어의 출현을 기반으로 학습하지 않고 문맥을 고려하여 Sentence order prediction을 학습하도록 하기 위함이다.

NSP(Next sentence prediction)과 SOP(Sentence order prediction)의 결과를 나타낸 표이다. NSP는 성능 향상이 미미하고 오히려 떨어지는 case도 있다. SOP는 큰 성능 향상을 이뤘다.
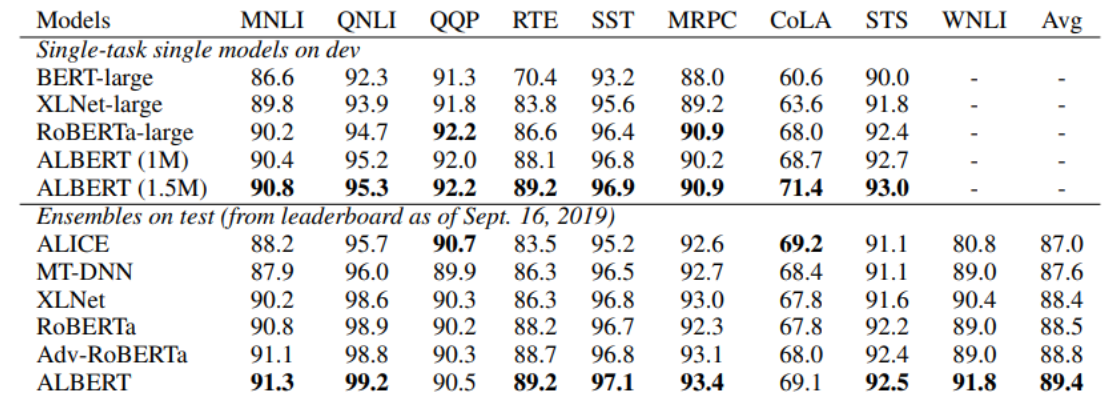
NLP task를 평가하기 위한 데이터셋인 GLUE에서도 ALBERT가 기존 모델들보다 더 좋은 성능을 보여주는 것을 알 수 있다.
ELECTRA
Efficiently Learning an Encoder that Classifies Token Replacements Accurately. ICLR 2020에서 구글 리서치 팀이 발표한 논문이다.
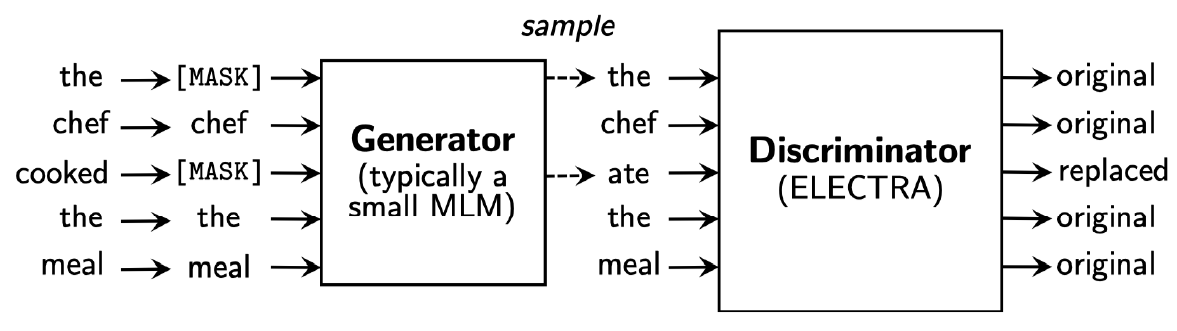
두 모델은 Adversarial(적대적) learning 형태로 학습이 진행된다.
관련 링크: Adversarial learning, Adversarial learning 긴 설명
- Generator: Maksed language model
- BERT와 같은 원리로 동작
- Maksed 문장을 복원
- Discriminator: mask token에 위치한 단어가 원본 단어인지, replaced된 단어인지 추론.
- Transformer 기반으로 Binary classification 진행.
- GAN(Generative adversarial network)에서 착안했다.
- 학습 데이터의 Ground truth와 Discriminator의 결과를 비교하면서 학습한다.
Pre-trained model로는 Generator가 아니라 Discriminator를 사용한다.
Performance
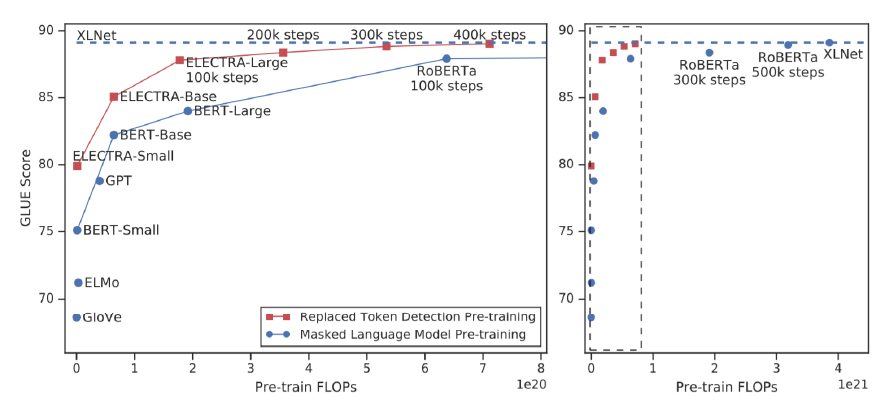
동일 연산량에서 기존 모델에 비해 더 높은 GLUE score를 기록했다. ALBERT와 함께 많은 downstream task에서 활용되고 있다.
Light-weight models
BERT, GPT, ELECTRA들은 self-attention block을 매우 많이 쌓아서 성능 향상을 이뤘기 때문에 parameters가 매우 많다. 이러한 parameters를 줄여서 모델의 크기와 학습 속도를 줄이는 경량화 모델이 연구되고 있다.
클라우드, 고성능컴퓨팅 자원이 아닌 모바일 기기에서 빠르고 저전력을 소모해서 모델을 돌리기 위해 사용된다.
DistillBERT
HuggingFace가 NeuralPS(뉴립스) 2019에서 발표한 논문.
teacher, student model로 구성된다.
- teacher: 기존의 거대한 구조를 유지하면서 feature들 학습하고 student model을 학습 시킨다.
- student: teacher보다 layer, parameters가 적음에도 teacher의 feature를 모사하려고 노력하는 모델.
동작 원리
Teacher: BERT의 Seq2Seq와 동일하다.
1. 'I go home'을 입력으로 했을 때, Seq2Seq의 teacher는 'I'에 대해서 'go'를 예측하고자 한다.
2. 'I'에 대한 입력에 대해서 vocabulary size만큼의 vector 생성되고 여기에 softmax를 취한다.
3. 2번의 결과에 대해서 확률값이 가장 큰 값은 'go'에 해당하는 index일 것이다.
Studnet: Teacher의 출력인 target distribution을 ground truth로 하여 학습한다. 단순히 Teacher의 출력을 모사하도록 한다.
TinyBERT
Teacher, student로 이루어지는 구조는 DistillBERT와 동일하다. TinyBERT는 teacher의 출력 distribution만을 모사하는 것이 아니라, 중간 생성물인 query, key, value, hidden state들까지도 모사하도록 한다.
Teacher에 비해서 student는 경량화모델이기 때문에 layer의 dimension들이 teacher에 비해 작다. 모사할 때 이것이 문제가 되는데, teacher의 dimension을 축소시키는 fully connected layer를 추가해서 해결했다고 한다.
Fusing Knowledge Graph into Language model
BERT는 문맥을 파악하거나 단어들간의 유사도를 구하는 task에서는 뛰어났지만 주어진 데이터셋 외의 정보들에 대해서 효과적으로 처리하지 못하기도 한다.
e.g., 땅을 파는 행위에 대한 데이터로 '땅을 팠다.'라는 문장만이 존재하는 데이터셋을 가정하자.
Question Answering task에서 이 문장에 대해서 '어떤 도구를 사용했는가?'를 묻는다면 기존의 모델은 답하기 어려울 수 있다. 정보가 없기 때문이다.
사람의 경우 '상식'이라는 외부 정보를 활용해 다양한 상황에 대한 사용 도구를 추론하고 답할 수 있을 것이다.
이와 같이 외부 정보를 모델에서 활용하고자 하는 분야다.
Knowledge graph: 정보들을 쳬게화해서 정리한 것
대표적인 모델
- ERNIE
- Information fusion layer takes the concatenation of the token embedding and
entity embedding
- Information fusion layer takes the concatenation of the token embedding and
- KagNET
- For each pair of question and answer candidate, it retrieves a sub-graph from
an external knowledge graph to capture relevant knowledge
- For each pair of question and answer candidate, it retrieves a sub-graph from
