ML Engineer
ML/DL을 이해, 연구하고 Product을 만드는 Engineer.
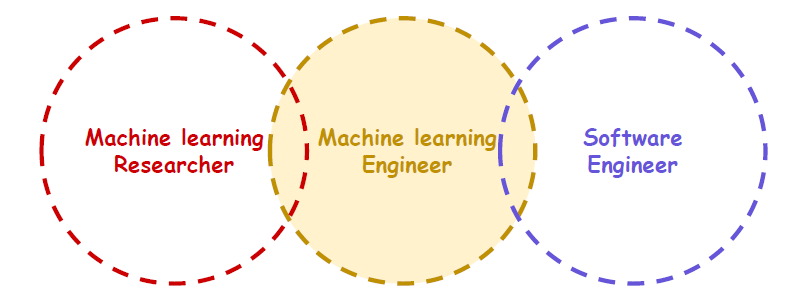
Researcher와 Engineer의 사이에서 모호한 위치에 있다. 발전속도가 워낙 빨라서 연구와 동시에 Product에 적용할 사례가 많기 때문이다.
Full stack Engineer
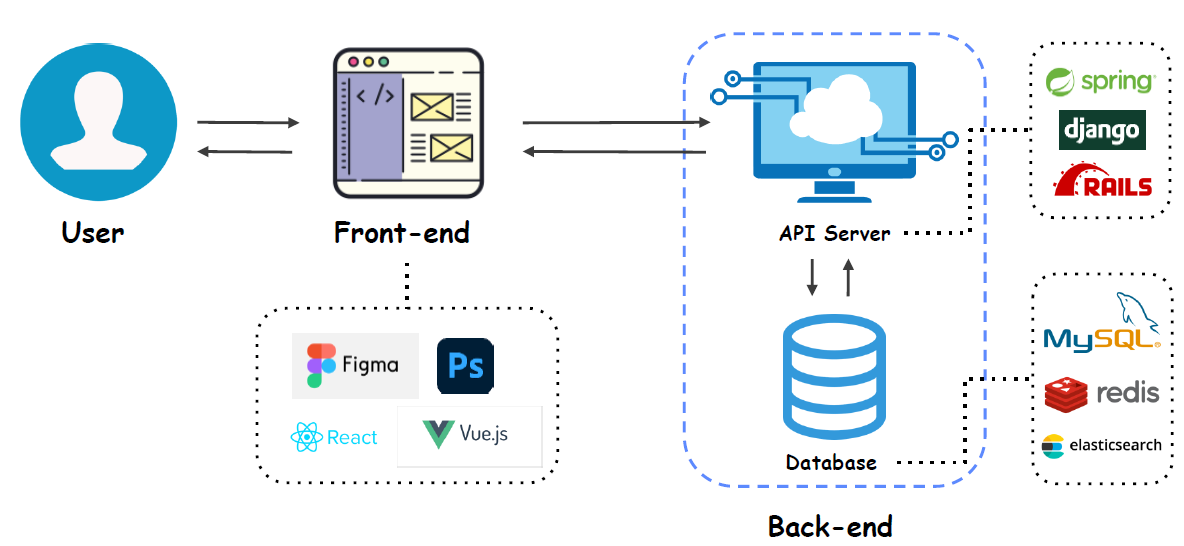
Front-end, Back-end를 모두 개발 가능한 Engineer. Product을 만들 시간만 있다면 모두 혼자 개발 가능한 개발자.
Full stack ML Engineer
DL Research를 이해하고 ML Product를 만들 수 있는 Engineer.
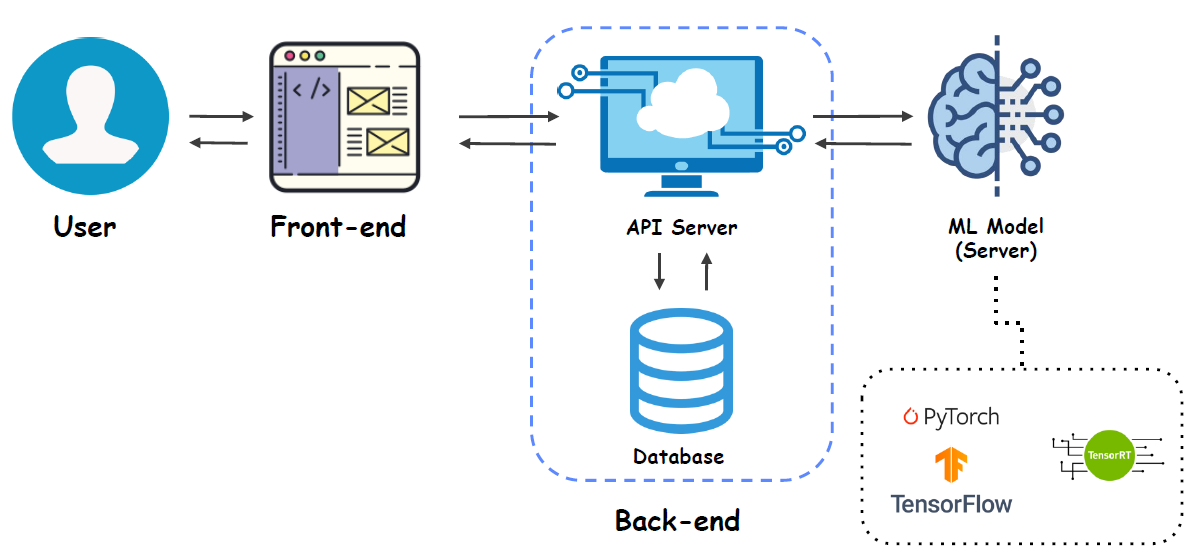
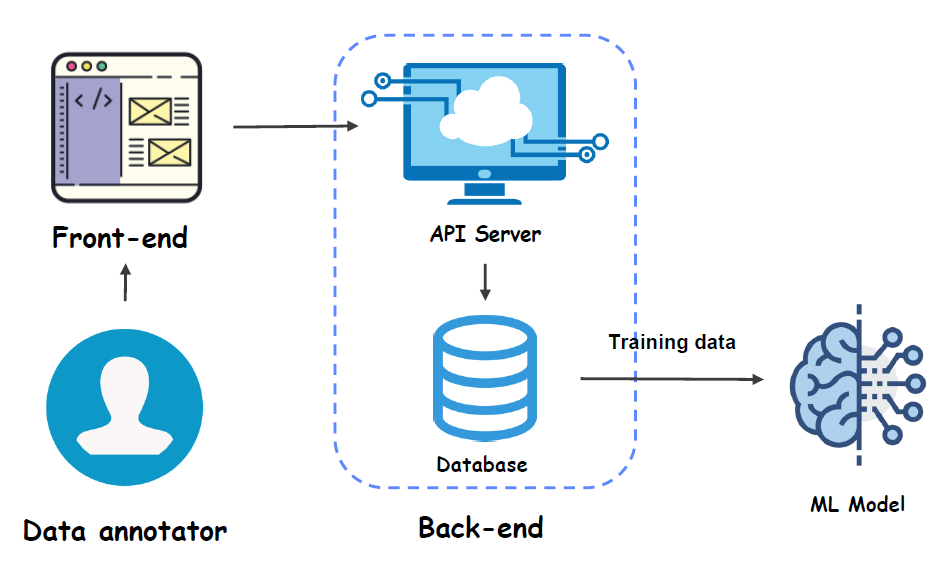
Back-end에서의 ML
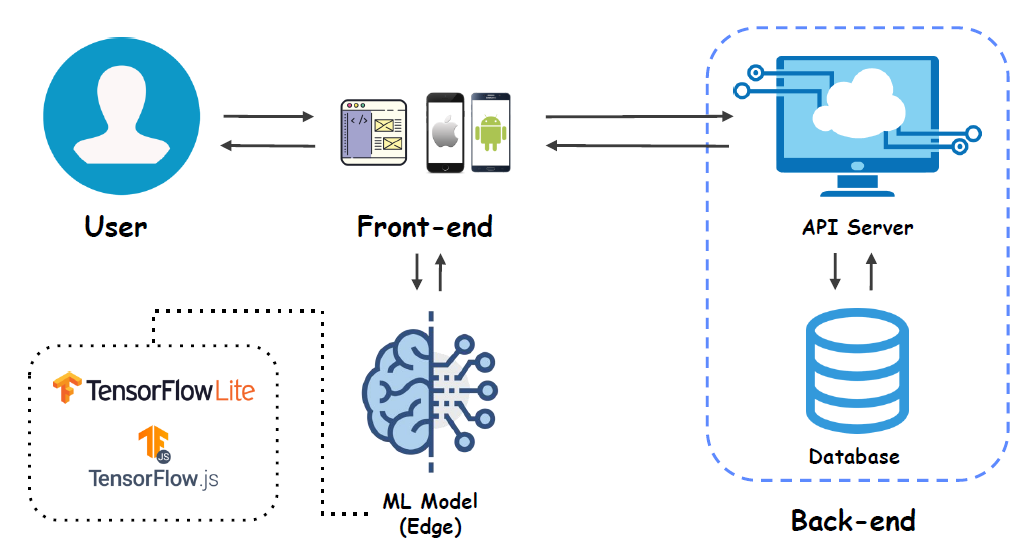
Front-end에서의 ML
ML model 개발을 위한 pipeline
Pros(장점)
- 프로토타이핑에 용이
- 프로토타이핑은 협업에 곤란한 경우가 많아서 직접 해결하는게 좋은 경우가 많다.
- Stack간 시너지
- stack에 대한 이해가 각 stack에 대한 효율적인 개발에 용이한 경우가 있다.
- 협업
- 갈등이 생길만한 포인트에서 협업 포인트 찾을 수 있다.
- 잠재적 위험을 예측할 수 있다.
- 성장의 다각화
- 성장의 밑거름이 된다.
- 매너리즘을 떨쳐내기 위한 트리거가 되기도 한다.
Conf(단점)
- 하나의 stack에 대한 깊이가 없어질 수도 있다.
- 모든 stack들의 발전 속도가 매우 빨라서 학습 자체가 너무 어렵다.
- 절대적 시간의 부족
- 공부할 분야는 많은데 주어진 시간은 모두 동일하다.
ML Product
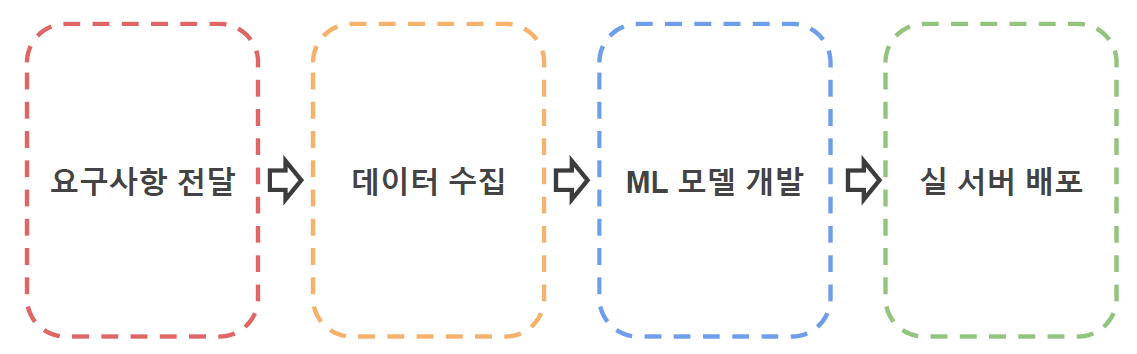
- 요구사항 전달
- 고객사 미팅(B2B), 서비스 기획(B2C)
- 요구사항, 제약사항 정리
- ML Probelm으로 회귀
- 데이터 수집
- Raw 데이터 수집
- Annotation tool 기획 / 개발
- Annotation guide 작성 / 운용
- ML 모델 개발
- 기존 연구 조사 및 내재화
- 실 데이터 적용 실험, 평가 / 피드백
- 모델 차원 경량화
- 실 서버 배포
- 엔지니어링 경량화 작업
- 연구용 코드 수정 작업
- 모델 버전 관리 / 배포 자동화
ML Team
이상적인 업무 분할이 일어난 ML Team 구성의 예시
- 프로젝트 매니저 1명
- 개발자 2명
- 연구자 2명
- 기획자 1명
- 데이터 관리자 1명
업무가 혼용된, 적은 인원의 ML Team
- 프로젝트 매니저, 기획자, 연구자 1명
- 개발자, 연구자, 데이터 관리자 1명
- 개발자, 데이터 관리자 1명
Full stack ML Engineer in ML Team
한 명이 개발자, 기획자, 데이터 버전 관리자 등의 역할을 겸하는 것이다.
1. 실 생활 문제를 ML 문제로 Formulation
고객/서비스의 요구사항을 구체화 하는 작업이다. 기존 ML 연구에 대한 폭넓은 지식과 최신 연구 수준을 파악하고 있어야 문제의 해결방안과 수행 가능 정도를 판단할 수 있다.
2. Raw Data 수집
Web cralwer(scraper)를 직접 구현.
3. Annotation tool 개발
수집/제공 받은 데이터와 데이터의 정답을 입력하는 작업을 수행하는 Application 개발.
- 작업 속도와 정확성을 고려한 UI 디자인 필요
- Annotation tool 개발을 위해서 ML model 자체에 대한 이해가 필요한 경우도 많다.

4. Data version 관리, Data loader 개발
데이터의 Version을 관리해야 한다. 대부분의 경우 데이터에 직접 접근하지 않고 DB를 통해 접근하기 때문에 관련 Loader package를 개발해야 한다. 멘토님은 Amazon S3와 python을 통해 구현하셨다고 한다.

5. Model 개발, 논문 작성
- 기존 연구 조사, 재현
- 재현 성능은 public benchmark 데이터로 검증
- 수집된 서비스 데이터 적용
- 모델 개선 및 아이디어 적용
- 필요하다면 논문 작성
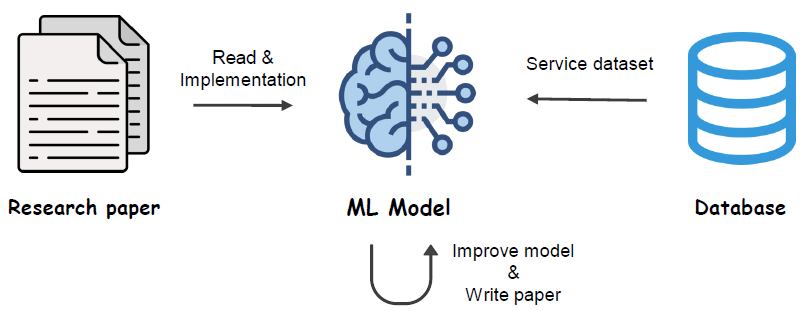
- 필요하다면 논문 작성
6. Evaluation tool, Demo 개발
- Model prediction 결과를 채점하는 application 개발
- Evaluation tool을 통해 모델의 발전 포인트를 잡을 수 있다.
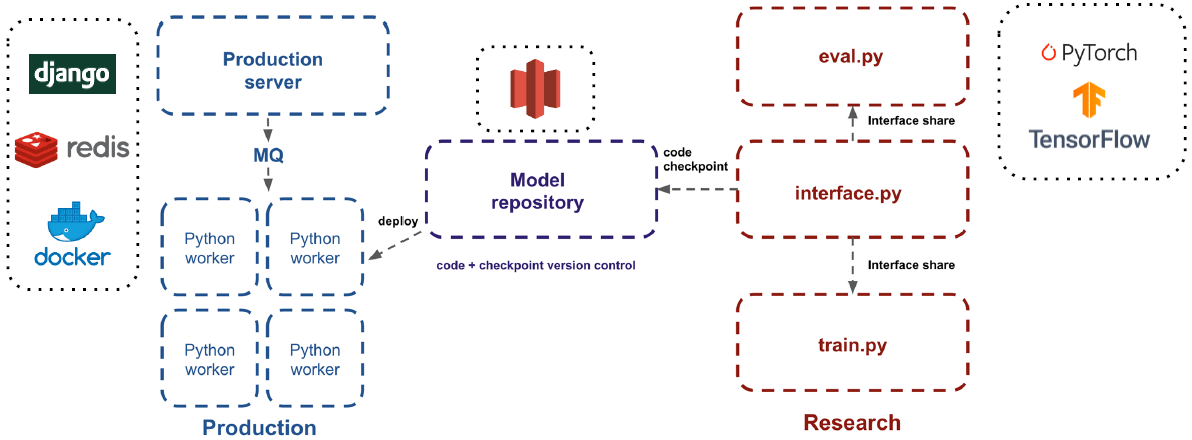
7. 모델 실 서버 배포
- 6번까지의 연구용 코드를 Production server에서 사용 가능하도록 정리해주느 작업
- File server에 code, parameters weight를 저장해 version 관리
- Production server는 python worker에 MQ를 통해 job 전달
Stack
조언
멘토님 조언을 정리하면 아래와 같다.
- 빨리 만들려고 해봐라
- 모든 stack에 대한 체계적인 architecture를 고려하면 개발 기간이 너무 길어진다. 처음부터 끝까지 최대한 빠르게 일단 완성해보고 기능을 더해보자.
- 전문 분야를 정해라
- 모든 stack을 초~중급으로 유지하는 것은 별로다. 전문 분야는 중급 수준 이상으로 실력을 갖춰라.
- 각 분야의 engineer라면 코드의 high level implementation을 보고 내부 작동과정을 알 수 있어야 한다.
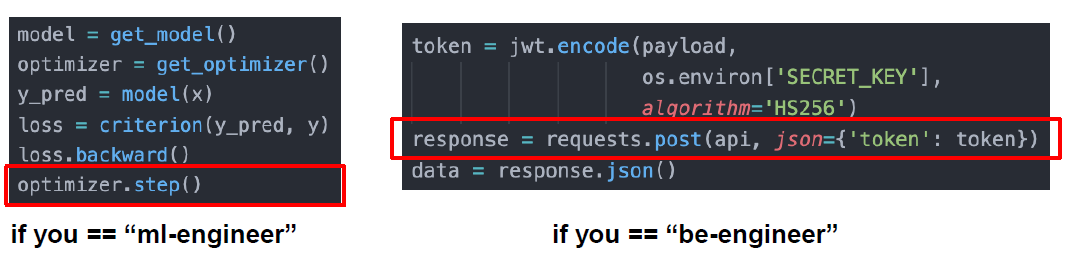
- 두려움을 없애기 위해 반복해라
ML Engineer를 위한 추천
- ML 논문을 읽고 구현/재현
- Web에서 implementation 구동
- DB를 활용해 2번 implementation 발전

https://github.com/naem1023