AI model as Researching
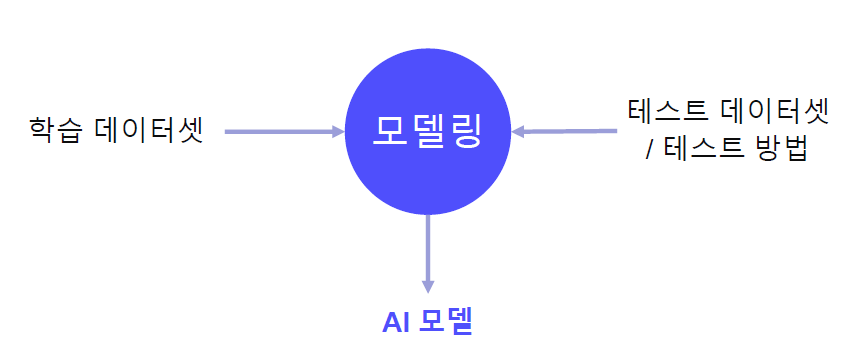
Imagenet처럼 데이터셋이 명확하고, 이를 해결하기 위한 모델링에 집중한다.
AI model as Servicing
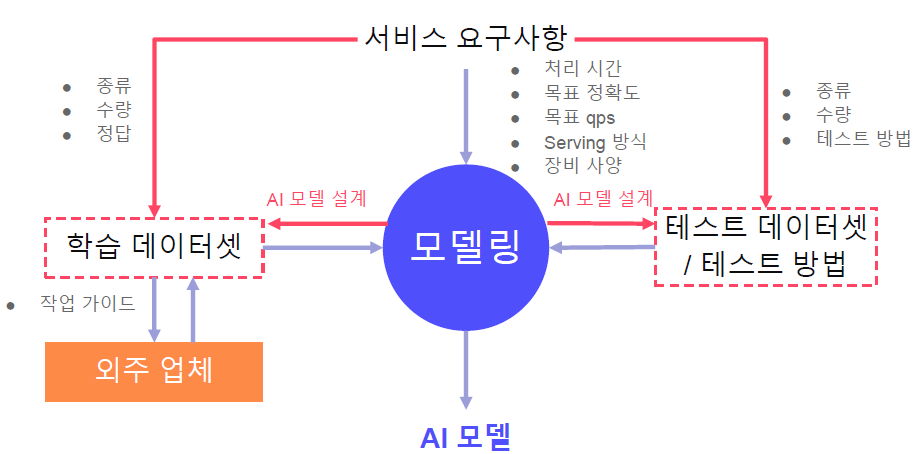
보통의 산업환경에서는 데이터셋 자체가 존재하지 않는 경우가 대부분이다. Software Requirements들만 존재하고 이를 해결하기 위한 도구로써 AI를 요구하는 경우가 대부분이다.
따라서 데이터셋을 직접 만들어야하는 경우가 대부분이다!
Requirements
학교에서 배웠던 Software engineering을 떠올리면 된다. Functional, non-Functional requirements들을 뽑아내기 위해 수단과 방법을 가리지 말자.
Dataset
- 종류, 수량, 정답 관련 requirements들을 명확히하자
- 각각의 requirements들을 반드시 명확하게 정의
- 종류: Requirements에 크게 의존하나 유연하게 하자
- e.g., OCR에서 수식의 이미지를 어떠한 종류로 나눌 것인가? 초등, 중등, 손글씨, 인쇄글씨 등의 카테고리들을 고려할 수 있다.
- 데이터셋을 처리하기 위한 모듈 정의
- e.g., 여러 수식이 적힌 이미지에서 개별적인 수식을 추출하는 AI 모듈 정의.
- 정답 정의
- e.g., 수식관련 OCR이라면 LaTex string
- 수량 정의
- 예산과 모델의 성능을 고려하여 적절하게 설정
Modeling
- 처리 시간
- 실제 서비스에서 입력이 처리되어 출력이 나올 때까지의 시간
- 목표 정확도
- 정량적으로 정해진다
- 목표 QPS(Query per Second)
- 초당 처리 가능 쿼리를 결정
- 장비, 처리 시간, 모델의 크기에 영향을 받는다
- 모델의 크기는 threshold에서만 QPS에 영향을 미친다
- GPU MEM이 10GB일 때, 모델의 크기가 5GB보다 크다면 모델의 크기를 아무리 줄여도 하나의 모델밖에 탑재되지 않는다. 즉, QPS 관점에서는 5기가 이상의 모델은 QPS에 영향을 주지 않는다.
- Serving 방식
- Local, Cloud, Mobile 등...
- 장비 사양
모델 분할
데이터셋에 크게 의존되어서 설계된다. 필요하다면 검증된 여러 모델을 결합하여 하나의 모델을 생성하는 것이 좋다. 데이터셋 또한 여러 모델에 맞게 따로 준비해야 된다.
손글씨 수식을 인식하는 OCR을 예를 들어보자.
AI Model
- input: 수식 이미지
- output: LaTex string
해당 task만을 위한 모델이 따로 존재하지 않고 OCR을 위한 모델링을 하기에는 Task가 고차원적이다. 따라서 다음과 같이 AI model을 분리할 수 있다.
AI model
- 검출기: LaTex symbol 검출
- 인식기: LaTex symbol 분류
- 정렬기: LaTex symbol들을 한 줄에 정렬
- 변환기: LaTex string 생성
4개의 모델로 분리했기 때문에, 4개의 모델에 맞는 입출력을 제공하는 데이터셋이 필요하다.
모델 후보군
하나의 AI model만을 통해 서비스를 출시하는 것은 위험할 수 있다. 여러 후보 AI model을 생성하고 정량, 정성 평가 후 서비스 출시 버전을 선택하자.
Test
테스트를 위한 데이터셋을 따로 구축하기도하고, 학습 데이터에서 테스트 데이터셋을 일부 사용하기도 한다. 이 또한 Requirements를 통해 도출하자.
- Offline test: 실 서비스 적용 전의 개발환경에서 이루어지는 정량 평가
- AI model 후보군을 선택하기위해 사용
- e.g., model의 accuracy가 99%
- Online test: 실 서비스 적용 시의 정량 평가
- VOC(Voice of Customer)을 통해 개선 포인트 파악
e.g., 1 vs 1 Ai Game player
- input dataset: 프레임당 캡쳐 이미지, 프로게이머의 로그
- output dataset: 사용할 스킬 set(no action도 포함)
해당 task를 Classification task로 분류할 수 있다고 가정하고 이에 대한 99% accuracy(Offline test)의 model을 개발했다고 하자. 하지만 실제 유저와 겨뤄본다면(Online test) 해당 model은 가만히 있을 가능성이 매우 다분하다!
왜냐하면 단순한 classification을 가정하고 개발됐기 때문이다. 대부분 멈춰 있고 가끔씩 스킬을 사용하는 프로게이머의 로그에서 멈춰 있는 행동 외에는 전부 노이즈 취급할 확률이 매우 높기 때문이다.
Team
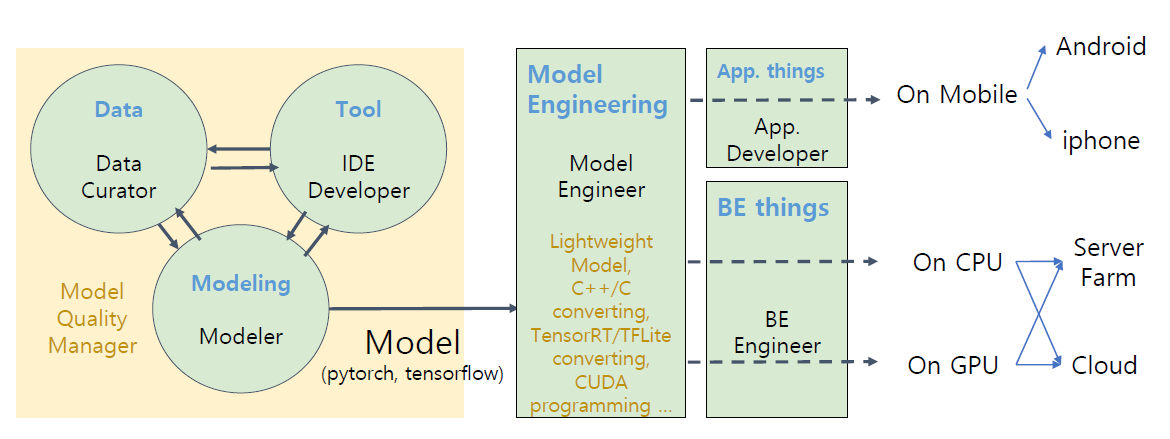
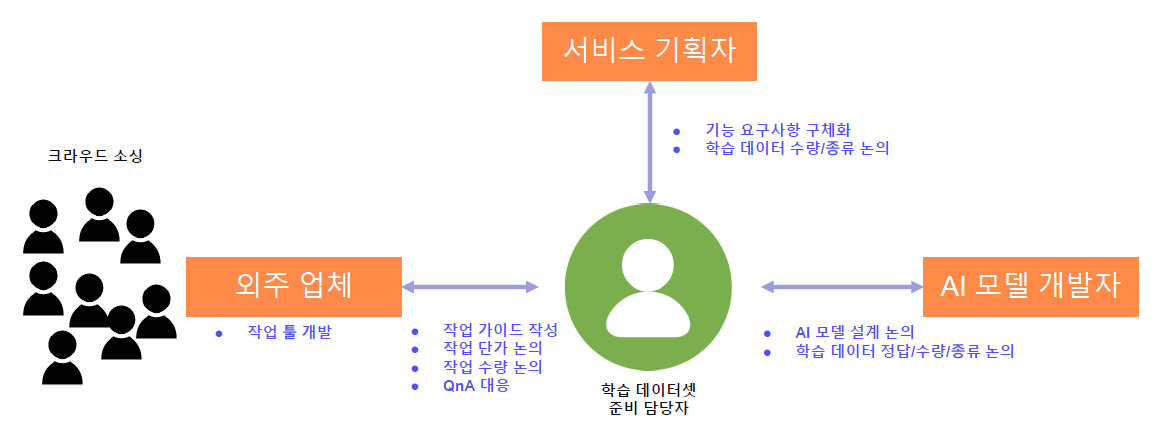
Requirments를 분석하고 개발하기 위한 팀을 구상해본 도식도이다.
- Model engineer
- 보통의 모델들은 pytorch로 개발되는데 service에 적합하게 tensorflow로 변환
- tensorflow 모델을 모바일에 적합하게 TFLite로 변환
- GPU Server에서 serving하기 위해 모델을 TensorRT로 변환
- framework 변환 시 존재하지 않는 operation 개발
- CUDA Programming
- Lightweight(경량화) task
- 빠른 연산을 위해 연산을 C++/C로 변환
- Modeler
- Model을 개발하는 인력
- Model을 잘 만드는 역량은 여전히 매우 유효한 능력이지만 자동화가 빠르게 일어나는 분야다(e.g., AutoML)
- 다른 분야를 조금씩 공부해보자.
- FE: annotation tool, debugging tool
- BE: api serving, massive gpu training
- Model: engineering
- Model management
- 전체적인 Model의 품질을 관리
