Step1에서 Airflow 설치에 관해서 실습하였다. 이번에는 DAG를 생성해서 데이터를 수집해 Parquet 형태로 저장하는 Flow를 실습해보려고 한다. Step1을 통해 이미 Airflow가 Docker위에 띄워진 상태여야 한다.
0. DAG란?
Airflow에서는 파이프라인을 정의하기 위해서 DAG를 사용한다. DAG란 Directred Acyclic Graph의 약자로 방향성 있는 비순환 그래프라고 불린다. 정의는 이렇게 되고, 쉽게 말하면 Airflow에서 각각의 행위를 노드로, 그 방향을 엣지로 정의한 파이프 라인이라고 보면 된다.
각각의 Task를 이용해 Workflow를 만들 수 있는데 예를 들어, ETL 파이프라인을 구축한다고 한다면 각각의 Task Extract, Transform, Load 일 것이고 이를 노드로 표현하며, 그 과정을 엣지로 나타내면 아래와 같은 DAG를 만들 수 있다.

이런 식으로 각각의 Task들이 정해진 방향으로 실행되는 그 Flow가 DAG로 구현된 것이라고 생각하면 될 것 같다. 이것은 파이썬 코드로 실행된다. 즉 각각의 Task의 코드가 실행되는 그 Flow가 있고 그것이 Orchestration 되는 주체가 DAG인 것 같다.
- 뭔가 SOAR랑 비슷한 느낌이 들었다. 기존에 SOAR가 하는 역할이 Orchestration이 대부분인데 MLOps로 전환하게 되면 SOAR가 하던 부분까지 모두 대체가 가능할 것 같은 느낌이다.
1. 실습 Flow
이번 실습은 Airflow예제에서 자주 사용되는 weatherdata를 사용하려고 한다. 대부분 Study할때 보니 이 데이터를 시초로 사용하더라... 나도 사용해봤다.
weatherdata에서 서울의 날씨 데이터를 가져와 그 결과를 parquet형태로 저장한다.
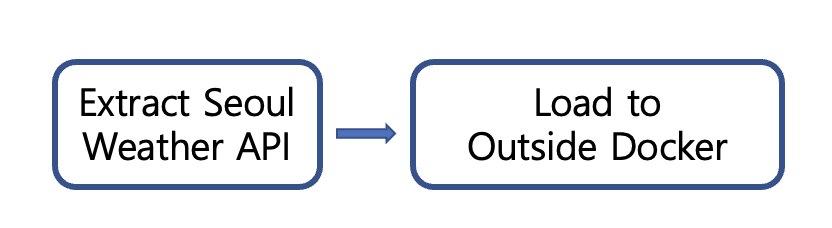
Airflow는 도커에서 실행되지만, 데이터 저장은 도커가 아닌 로컬 호스트 자체에 하기로 했다. 도커 내부에 저장하게 되면 도커가 날라갈 경우 데이터 가용성 보장이 안된다는 전제로 외부에 저장하는 컨셉이다.
현재 실습에서는 외부 로컬에 저장했으나, 실 사용시에는 S3에 주로 저장하는 것 같다.
1) https://openweathermap.org/ 사이트 가입
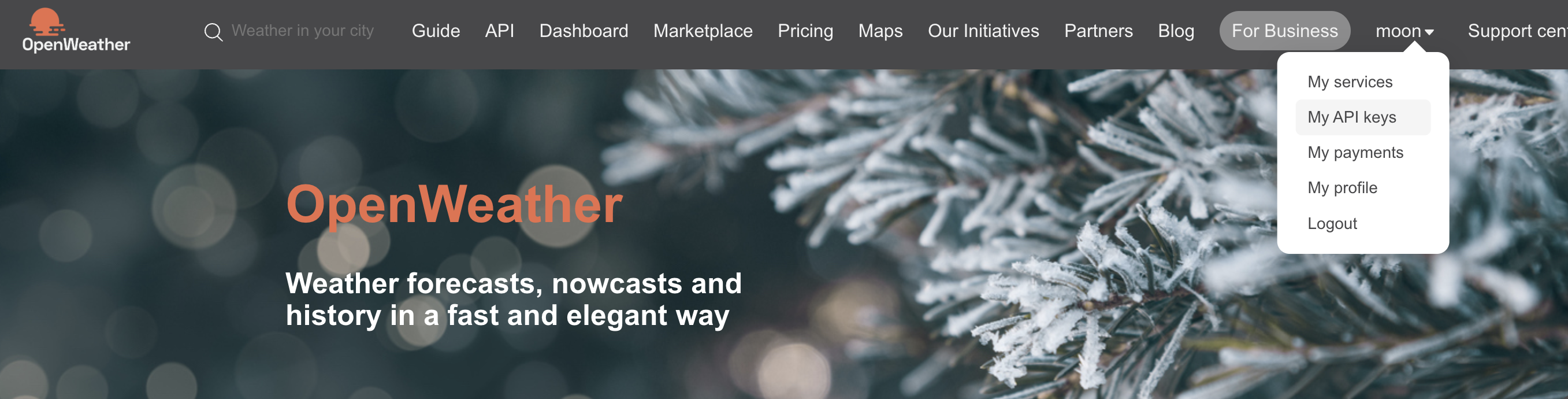
사이트 가입 후, 내 프로필을 눌러보면 My API Keys가 있다. 여기서 보이는 key 값을 복사해 저장해둔다.
2. DAG 코드 작성
1) 2가지의 process로 코드 작성
코드를 작성해준다. Chat GPT 님께서 짜주셨다. weather에서 데이터 가져와서 parquet로 저장하는 DAG코드를 짜달라고 요청드리면 친절히 짜주셨다.
각각의 항목에 대한 설명은 너무 길기 때문에 다음 포스팅으로 작성하겠다.
cd ~/airflow/dags
vi weathermap.pyimport os # 경로 확인 및 디렉터리 생성에 필요
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
import requests
import pyarrow as pa
import pyarrow.parquet as pq
import pandas as pd
# OpenWeatherMap API 설정
API_KEY = "" # 본인의 API 키 입력
CITY = "Seoul" # 원하는 도시 이름
BASE_URL = "http://api.openweathermap.org/data/2.5/weather"
# Parquet 파일 저장 경로(도커 내의 경로를 입력해야함)
OUTPUT_DIR ="/opt/airflow/data/weather/"
# 스키마 정의 (기본 스키마)
schema = pa.schema([
('city', pa.string()),
('temperature', pa.float32()),
('humidity', pa.int32()),
('weather', pa.string()),
('timestamp', pa.string()) # ISO 형식의 timestamp (문자열)
])
def fetch_weather_data():
"""OpenWeatherMap API에서 날씨 정보를 가져옵니다."""
params = {"q": CITY, "appid": API_KEY, "units": "metric"}
response = requests.get(BASE_URL, params=params)
response.raise_for_status() # HTTP 오류 발생 시 예외
data = response.json()
weather_data = {
"city": data["name"],
"temperature": data["main"]["temp"],
"humidity": data["main"]["humidity"],
"weather": data["weather"][0]["description"],
"timestamp": datetime.utcnow().isoformat(), # ISO 형식으로 날짜 변환
}
return weather_data
def save_to_parquet(ti):
"""XCom에서 데이터를 가져와 Parquet 파일로 저장합니다."""
weather_data = ti.xcom_pull(task_ids="fetch_weather_data_task")
if not weather_data:
raise ValueError("No weather data found in XCom.")
# 파일 저장 디렉터리 확인 및 생성
if not os.path.exists(OUTPUT_DIR):
os.makedirs(OUTPUT_DIR) # 디렉터리 생성
# 고유한 파일 이름 생성 (현재 시간 기반)
timestamp = datetime.utcnow().strftime('%Y%m%d%H%M%S')
output_file = os.path.join(OUTPUT_DIR, f"weather_data_{timestamp}.parquet")
# Parquet 저장을 위한 데이터 구조 변환
new_table = pa.Table.from_pandas(
pd.DataFrame([weather_data]),
schema=schema # 명시적으로 스키마 지정
)
# Parquet 파일에 새 데이터를 저장 (기존 파일 덮어쓰기 안 함)
pq.write_table(new_table, output_file)
# DAG 기본 설정
default_args = {
"owner": "airflow",
"depends_on_past": False,
"email_on_failure": False,
"email_on_retry": False,
"retries": 1,
"retry_delay": timedelta(minutes=5),
}
with DAG(
"weather_data_to_parquet",
default_args=default_args,
description="Fetch weather data from OpenWeatherMap and save to Parquet",
schedule_interval=timedelta(hours=1), # 1시간마다 실행
start_date=datetime(2023, 12, 1),
catchup=False,
) as dag:
fetch_weather_data_task = PythonOperator( ## 첫 번째 프로세스
task_id="fetch_weather_data_task",
python_callable=fetch_weather_data,
)
save_to_parquet_task = PythonOperator( ## 두 번째 프로세스
task_id="save_to_parquet_task",
python_callable=save_to_parquet,
)
fetch_weather_data_task >> save_to_parquet_task이후에는 :wq!를 이용해 저장해준다.
여기서 주의할 점은 데이터가 저장되는 장소는 도커 내의 경로를 입력해줘야 한다는 것 이다. 따라서 도커 내의 경로를 확인하기 위해 아래의 커맨드를 실행해서 확인한다.
- 현재 실행중인 이미지 확인
docker ps
- airflow-webserver_1 이미지로 진입
docker exec -it CONTAINER ID /bin/sh
## 로컬 환경의 /bin/sh 쉘을 이용해 CONTAINER ID에 해당되는 이미지에 진입하겠다 라는 의미이다.
이렇게 하면 아래와 같이 airflow내부의 터미널로 진입했다.

pwd, ls를 입력해서 주 경로가 /opt/airflow임을 확인해주고, 데이터를 저장하기 위해 data 폴더를 생성해준 후 나갔다.
mkdir data
exit이후에는 파이썬 코드에 /opt/airflow/data 하위 경로를 적어줬다.
2) Docker 를 로컬 저장소로 Mount 시키기
도커가 날라갔을 경우를 가정해, 로컬 저장소에도 남아있을 수 있도록 로컬 저장소에 마운트 시켜준다.
cd ~/airflow
vi docker-compose.yaml
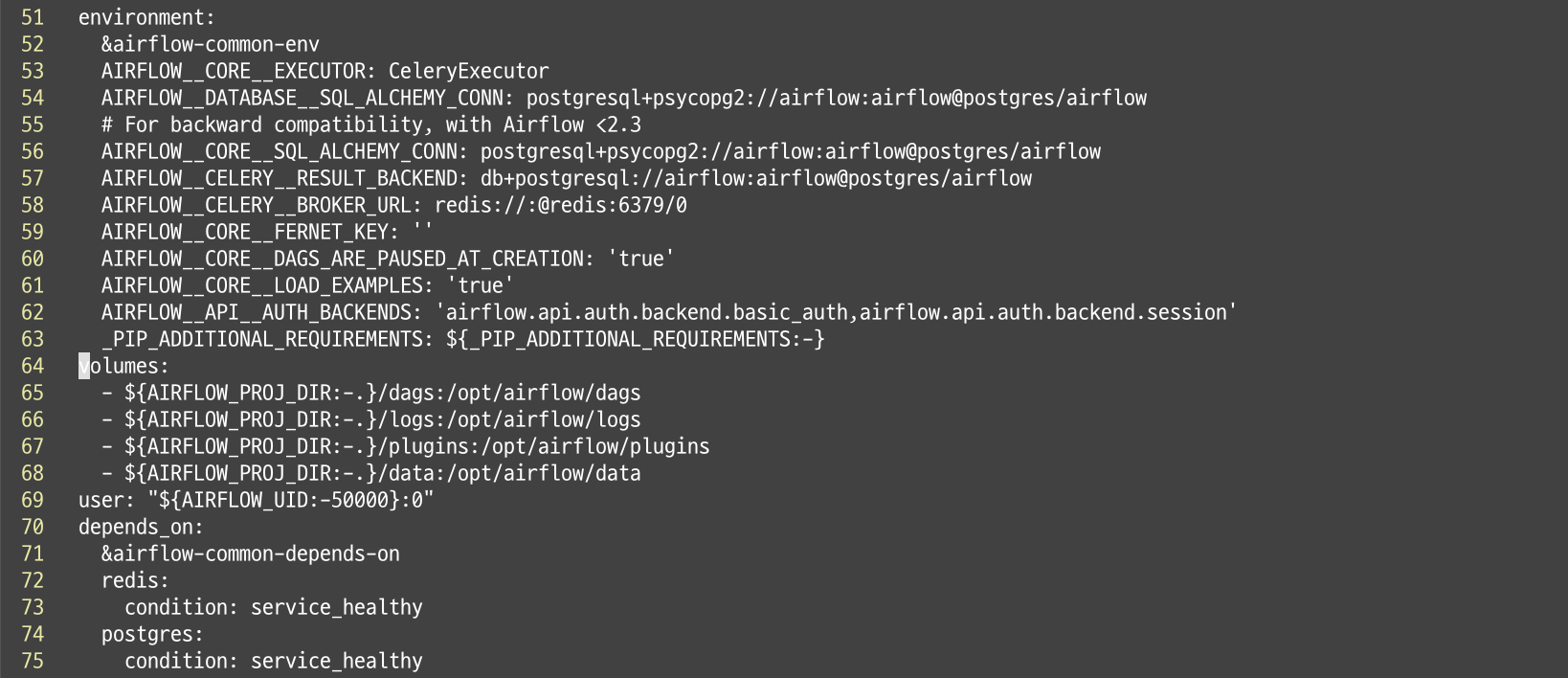
/volvi로 도커 설정 파일을 open한 후 vol 키워드를 검색한다. n 을 누르면서 아래로 내려가다 보면 아래와 같은 내용이 보인다.
environment:
&airflow-common-env
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
# For backward compatibility, with Airflow <2.3
AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__BROKER_URL: redis://:@redis:6379/0
AIRFLOW__CORE__FERNET_KEY: ''
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: 'true'
AIRFLOW__CORE__LOAD_EXAMPLES: 'true'
AIRFLOW__API__AUTH_BACKENDS: 'airflow.api.auth.backend.basic_auth,airflow.api.auth.backend.session'
_PIP_ADDITIONAL_REQUIREMENTS: ${_PIP_ADDITIONAL_REQUIREMENTS:-}
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/dags:/opt/airflow/dags
- ${AIRFLOW_PROJ_DIR:-.}/logs:/opt/airflow/logs
- ${AIRFLOW_PROJ_DIR:-.}/plugins:/opt/airflow/pluginsvolumes: 키워드 아래의 목록에 추가해주면 되는데, 위의 옵션에 대해 간략한 설명을 하자면 아래와 같다.
${AIRFLOW_PROJ_DIR:-.}/dags:/opt/airflow/dags
- ({AIRFLOW_PROJ_DIR:-.}는 환경 변수 AIRFLOW_PROJ_DIR을 사용하며, 설정되지 않았을 경우 현재 디렉토리(.)를 기본값으로 사용합니다.
이 디렉토리에는 Airflow DAG 파일이 저장됩니다.- (/opt/airflow/dags): Docker 컨테이너 내부에서 dags 디렉토리가 위치하는 경로입니다. Airflow가 이 디렉토리를 검색하여 DAG 파일을 로드합니다.
쉽게 해석하면 도커에 올려진 airflow의 내부 경로 /opt/airflow/dags는 현재 로컬 디렉토리(.)와 연결되어있다는 의미이다. 현재 디렉토리는 ~/airflow/로 설정되어있다.
위의 옵션 바로 아래에 아래의 내용을 입력해준다.
${AIRFLOW_PROJ_DIR:-.}/data:/opt/airflow/data 설명을 하자면 현재 로컬 환경의 ~/airflow/data 경로를 docker내의 /opt/airflow/data와 연결시켜 준다는 의미이다.
3. Airflow Scheduler 실행
airflow scheduler
스케줄러를 실행 후 localhost:8080 으로 접속하여 추가된 weather_data_to_parquet를 활성화 시켜준다.
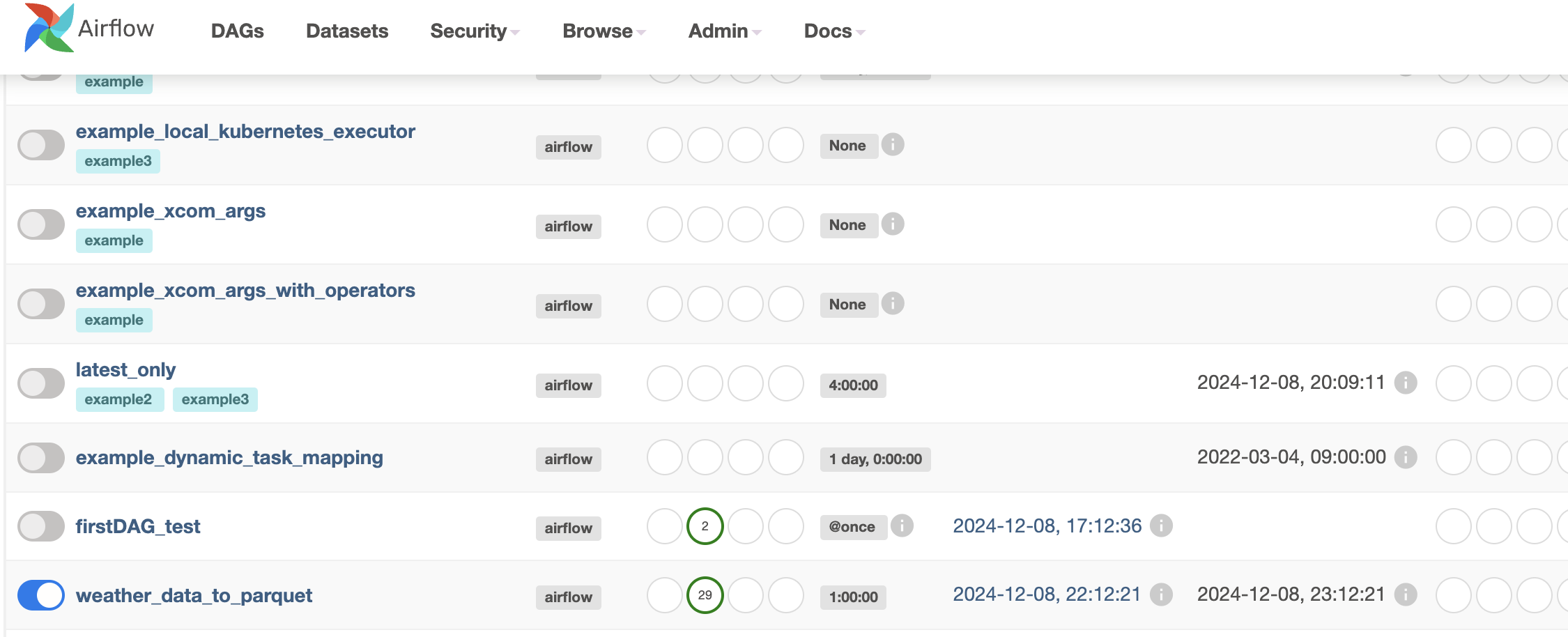
이후 제목을 클릭해 진입해보면
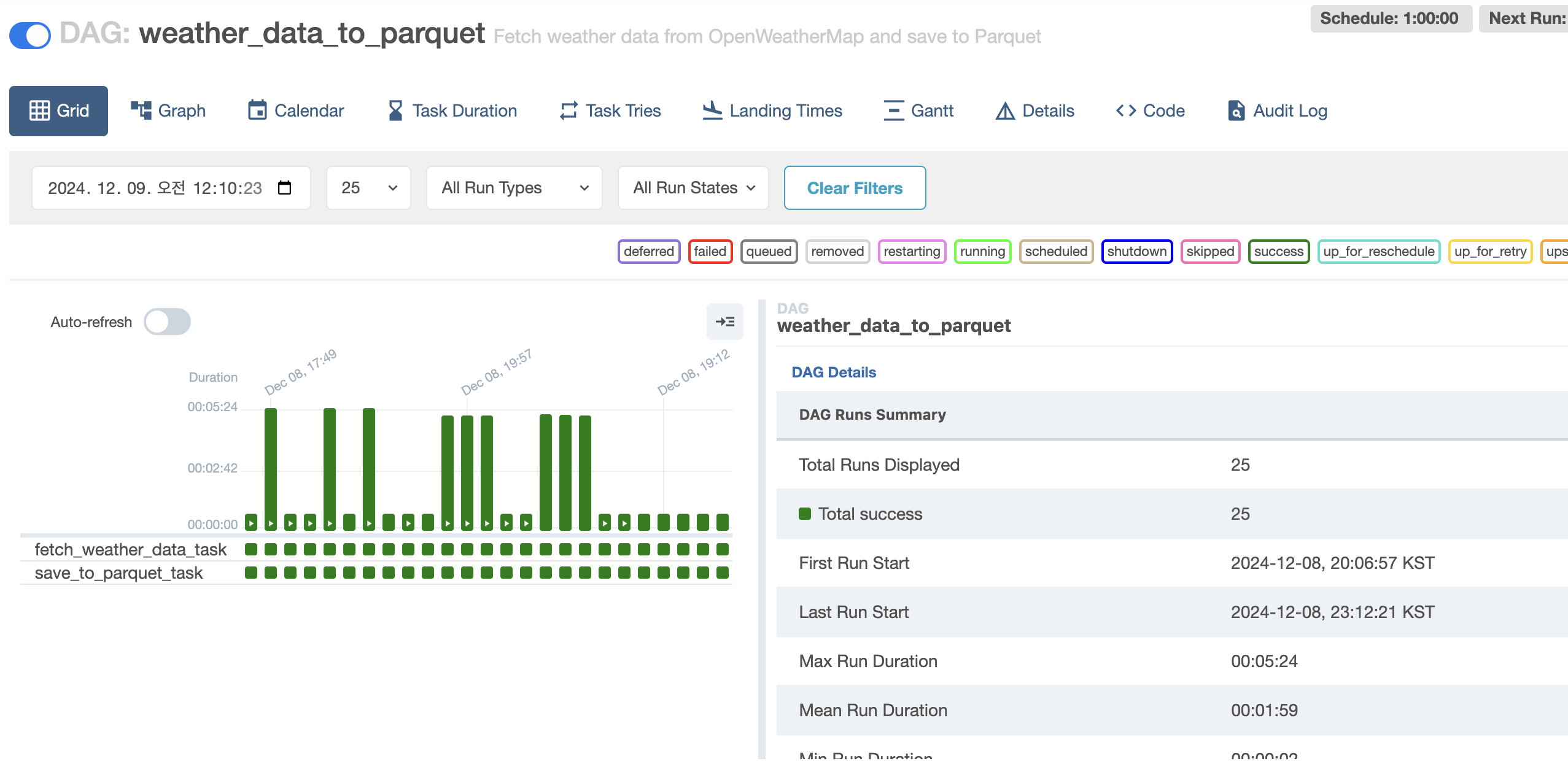
아래와 같이 모두 초록색이 뜨고있으면 성공하고 있는 것 이다.
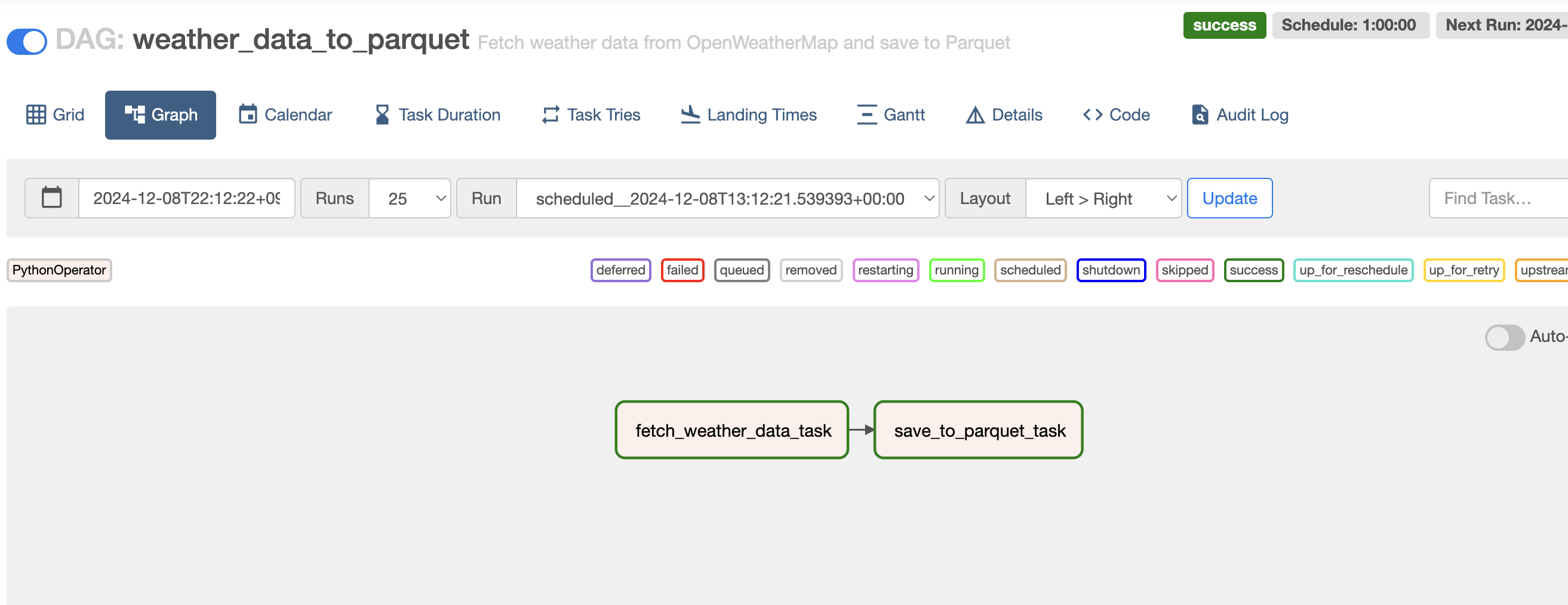
그래프를 확인해 보면 Operater로 정의한 파이썬 실행 flow가 그래프 형태로 시각화 되어 보이고 있다.
끝이다.
다음에는 이를 Splunk와 연결해서 Task 실행, 간단한 모델 배포해보기 등을 해봐야겠다. .. 아 추가로 DAG에 관한 설명도 할 예정이다..
