PROMETHEUS 2: An Open Source Language Model Specialized in Evaluating Other Language Models (EMNLP 2024, link)
배경지식
언어모델 종류
- Proprietary LM
- GPT-4와 같이 학습 데이터셋, 모델의 파라미터를 포함한 모델 정보가 공개되지 않은 상업적 언어모델
- Open LM
- Open-weight LM이라고도 불리며, 모델의 파라미터 정보가 공개된 언어모델
- 예전엔 Open-source LM이라고도 칭했으나, 실제로 모델을 학습할 때 사용한 코드나 데이터셋 정보를 공개하지 않는다는 점에서 Open-weight LM이 더욱 정확한 용어
언어모델 응답 평가방식
- 전통적으로 언어모델의 응답을 Rouge, BLEU, BERTScore와 같은 지표로 평가하였음
- 최근에는 언어모델을 평가자로 활용해 다른 언어모델의 응답을 평가 (LM as a judge)
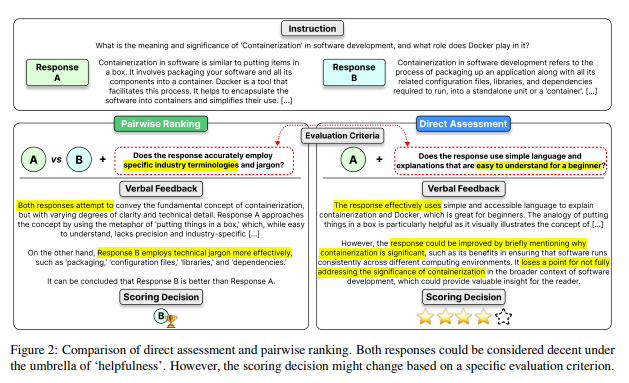
- 직접 평가 (direct assessment)
- 생성한 모델 응답의 품질을 숫자 지표로 평가
- 평가 모델로 하여금 숫자로 응답을 평가하도록 프롬프팅
- 두 개 순위 매기기 (pairwise ranking)
- 두 개의 모델 응답 중 어떤 응답이 더욱 선호되는지 평가
- 직접 평가 (direct assessment)
문제점
- Proprietary LM을 활용한 평가의 경우, 통제 가능성, 투명성, 경제성(affordability) 측면에서 한계가 존재함
- Open LM을 활용한 평가의 경우, 아래와 같은 문제점 존재
- 사람이 내린 평가와 모델이 내린 평가가 크게 다른 경우 존재
- direct assessment와 pairwise ranking를 동시에 수행할 수 없음
해결책
Prometheus 2
- GPT-4, 사람의 평가와 유사한 강력한 평가 모델
- Mistral-7B, Mixtral-8x7B 기반으로 학습
- direct assessment와 pairwise ranking 동시 수행 가능
가중치 머징 (wieght merging) - 개별 태스크 학습
-
태스크 1. direct assessment

- 사람의 평가와 언어모델의 평가 사이의 상관성을 높이려면 아래와 같은 사항들이 중요함
- 평가 언어모델에 인풋으로 정답(reference)이 제공되어야 함
- 숫자 점수를 내기 전 피드백(verbal feedback)을 생성하도록 하는 것이 좋음
- 평가 범주를 포함하면 특별한 요구사항도 유연하게 평가할 수 있음 (특히, 범주에 대한 설명과 각 점수에 대한 설명 포함)
- 평가모델 학습 시 인풋으로는 지시사항, 모델 응답, 정답, 평가 범주를 사용
- 이에 대해 피드백과 점수(숫자)를 출력하도록 학습
- 사람의 평가와 언어모델의 평가 사이의 상관성을 높이려면 아래와 같은 사항들이 중요함
-
태스크 2. pairwise ranking
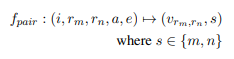
- 마찬가지로 정답, 피드백, 평가 범주를 학습 과정에 포함
- 단, 평가 범주의 경우 범주에 대한 설명만을 포함 (점수에 대한 설명 X)
- 피드백의 경우 두 응답 사이의 공통점과 차이점을 비교하도록 함
- 평가모델 학습 시 인풋으로 지시사항, 모델 응답 (2개), 정답, 평가 범주를 사용
- 이에 대해 피드백과 점수(둘 중 무엇을 선호하는지)를 출력하도록 학습
- 마찬가지로 정답, 피드백, 평가 범주를 학습 과정에 포함
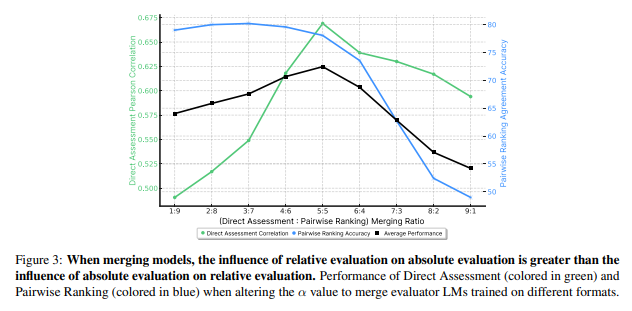
가중치 머징 (weight merging) - 학습 가중치 합침
- Linear, Task Arithmetic, Slerp, TIES, DARE 등 여러 방법론 실험
- DARE-linear merging이 가장 좋은 성능, 이를 활용
- DARE-linear merging이란 반복되는 가중치를 제거하기 위해 random drop과 re-scale을 적용한 가중치 합산 방식
- 두 개의 데이터셋을 하나의 모델로 학습하는 joint training의 경우, negative task transfer가 발생하나 weight merging 시 positive task transfer 발생
- 단순히 여러 개의 모델을 앙상블해서 나타나는 현상이 아닌, 다른 평가 포맷을 합침으로써 발생하는 긍정적 시너지 효과 발생
- pairwise ranking 학습이 direct assessment 성능 향상에 큰 영향을 미침 (direct assessment가 pairwise에 미치는 영향보다)
Preference Collection 데이터셋
- Feedback Collection을 기반으로 새롭게 만든 pairwise ranking 피드백 데이터 (huggingface link)
- Feedback Collection에서는 하나의 instruction에 대해 1-5점에 대응하는 다섯 개의 응답이 존재
- 하나의 instruction에 대해 5개의 응답을 두 개씩 쌍을 지어 총 10개의 응답쌍 조합을 생성, 기존의 점수를 바탕으로 어느 응답이 더 좋은지 (점수) 결정
- GPT-4-1106을 프롬프팅하여 두 응답의 공통점과 차이점을 식별, 이를 피드백(verbal feedback)으로 활용
평가
데이터셋
- direct assessment 벤치마크
- Vicuna Bench
- MT Bench
- FLASK
- Feedback Bench
- pairwise ranking 벤치마크
- HHH Alignment
- MT Bench Human Judgment
- Auto-J Eval
- Preference Bench
평가지표
- direct assessment
- 정답 기반 평가 (reference-based)
- 정답 평가자와의 상관성을 pearson, spearman, kendall-tau로 측정
- pairwise ranking
- 정답 없이 평가 (reference-free)
- 사람과 평가모델 사이의 일치도 측정 (accuracy)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab