Chainpoll: A high efficacy method for LLM hallucination detection (논문 링크, 블로그 링크)
배경지식
- Hallucination (환각)
- 언어 모델이 부정확하거나 그럴듯한 거짓말을 하는 현상
- 과거 ChatGPT에게 "세종대왕이 맥북을 던진 사건"을 물어봤을 때 이에 대해 실제 있었던 일처럼 답변한 게 대표적인 환각 케이스
- Open-domain hallucination
- 실제 사실에 대해 거짓말을 하는 경우 (e.g. 태양이 지구 주위를 돈다)
- Closed-domain hallucination
- 특정 참조자료의 문맥으로부터 거리가 먼 응답을 하는 경우 (e.g. 제공된 문서에 없는 내용을 답변)
문제점
- 환각은 LLM에게 빈번히 등장하는 고질적인 문제
- 하지만 환각 감지 능력을 평가하는 데이터셋들은 대개 최신 LLM에게는 너무 쉽거나, 현실적이지 않음
해결책
RedHall
- 환각 감지를 평가하기 위한 벤치마크 데이터셋
- 최신 LLM에게도 어렵거나 (challenging), 실제 사례에 연관성이 높은 (realistic) 다양한 태스크의 (task diversity) 데이터셋 4개 선정
RedHall Closed
- closed-domain hallucination 감지 능력 평가
- 생성된 응답과 프롬프트에 제공된 참조 텍스트 사이의 불일치성 탐지
- 검색 내용을 포함한 COVID-QA
- COVID-19에 관련된 질의응답 쌍
- Retrieval Augmented Generation에 특화
- DROP
- 오픈북 QA 데이터셋
- 문단 내에 언급된 여러 개의 사실들에 대해 추론을 요구
RedHall Open
- Open Assistant prompts
- ChatGPT 스타일의 언어모델을 학습하기 위해 사용하는 대화 트리 데이터셋
- 대화 트리의 첫 번째 프롬프트만 사용
- 다양한 태스크를 포함하며 현실적이고, 최신 LLM에게도 어려움
- ChatGPT 스타일의 언어모델을 학습하기 위해 사용하는 대화 트리 데이터셋
- TriviaQA
- 원래는 독해 능력을 평가하는 데이터셋이었으나, 참조 문서 없이 질문만 사용하여 LLM에게 사실적 지식을 물어보는 용도로 자주 사용됨
ChainPoll
- Chain
- Chain-of-thought 프롬프팅
- 언어 모델에게 정답을 말하기 전 단계별 추론을 강제하는 방법
- Poll
- 동일 프롬프트에 대해 LLM을 여러 번 호출해 응답을 모음 (응답의 평균을 사용)
- 자기일관성(self-consistency)을 담보하기 위한 방법
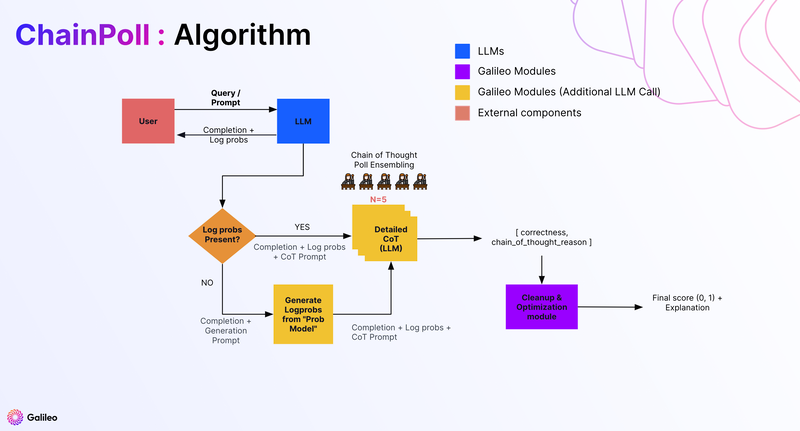
- ChainPoll 수행 순서
- gpt-3.5-turbo에게 모델의 응답에 환각이 포함되었는지에 대해 프롬프팅
- yes, no의 binary로 응답하게 함 (여러 개의 스코어보다 좋은 점수)
- 심혈을 기울여 프롬프트를 고안했다고 함 (detaild CoT)
- 위의 단계를 여러 번 반복 (일반적으로 5번)
- yes 응답 수 / 전체 응답 수 계산 (0-1 사이의 점수로 평균냄)
- gpt-3.5-turbo에게 모델의 응답에 환각이 포함되었는지에 대해 프롬프팅
- ChainPoll 종류
- ChainPoll-Correctness: open-domain 환각
- ChainPoll-Adherence: closed-domain 환각
평가
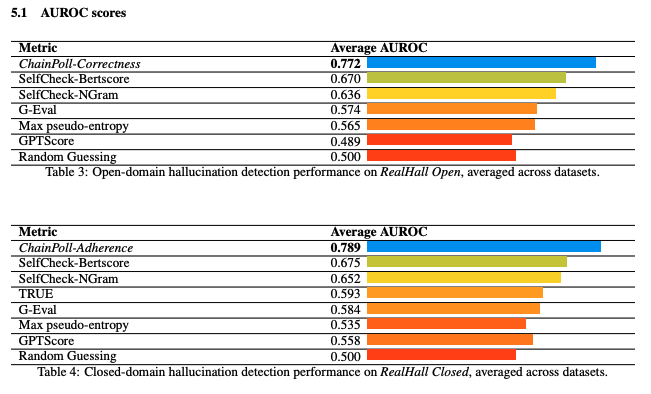
- 베이스라인
- 자세한 CoT를 제외한 ChainPoll
- G-Eval-3.5
- LLM으로 하여금 1-5점으로 응답을 평가하도록 함 (가이드라인 제공)
- 아웃풋 토큰의 확률을 사용해 가중평균을 하거나, 확률을 얻을 수 없다면 LLM에서 20번 샘플링
- GPTScore
- SelfCheckGPT
- 동일한 프롬프트를 사용하여 LLM으로 하여금 여러 개의 응답을 생성하도록 함 (20+개)
- 응답들 사이의 자기일관성 (self-consistency) 확인해 환각여부 평가
- BERTScore를 활용해 응답들 사이의 유사성 평가하거나 (SelfCheck-BERTScore)
- 단순한 unigram LM 활용해 응답들 사이의 유사성을 평가하는 등 (SelfCheck-NGram)
- 응답 유사성 평가에 다양한 방식 사용
- 문장 기반 평가
- TRUE (closed-domain)
- 11개의 closed-domain 데이터셋을 활용해 벤치마크 생성
- NLI로 파인튜닝한 T5-XXL 모델의 확률을 활용
- pseudo-entropy
- 단순한 확률 기반 베이스라인
- 평가지표
- AUROC
한계
- BLEU, ROUGE, METEOR 등 정답(ground-truth)을 필요로 하는 지표와는 성능을 비교하지 않음
- 이는 실제 운영에서는 정답이 없는 경우가 많으며, 빠른 실험을 위함이라고 밝힘
- 하지만 모델의 응답과 정답 사이의 평가와 hallucination 여부 평가는 모델 응답의 품질을 다루는 전혀 다른 영역임
- Galileo가 평가지표로 확보하고 있는 Ground Truth Adherence가 모델의 응답과 정답을 비교함에 있어서 얼마나 효과적인 지표일지 의문이 듦

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab