Luna: An Evaluation Foundation Model to Catch Language Model
Hallucinations with High Accuracy and Low Cost (paper link, blog link)
배경지식
- Hallucination (환각)
- 언어모델이 그럴 듯한 거짓말을 하는 현상
- RAG를 통해 context를 제공해주며 완화되었으나, 여전히 발생
- NLI (Natural Language Inference) 태스크
- 전제(premise)와 가설(hypothesis) 사이의 관계 파악하는 태스크
- 수반(entailment), 모순(contradiction), 중립(neutral) 중 하나로 분류
- NLI 모델은 closed-domain 생성 태스크에서 사실적 일관성을 평가하는 데에 사용됨
- 많은 환각 감지 연구에서 NLI를 활용
- 전제(premise)와 가설(hypothesis) 사이의 관계 파악하는 태스크
문제점
- RAG 평가 프레임워크
- 자동화된 환각 감지 평가를 가능하게 함
- 고정된 프롬프트를 활용 (RAGAS, Trulens)
- 도메인 데이터로 파인튜닝 (ARES)
- 다양한 산업군에 일반적으로 적용되기 어려움
- 자동화된 환각 감지 평가를 가능하게 함
- 환각 감지 및 대체 기술 (detect-and-replace)
- LLM 평가는 latency 존재
- 실제 시스템에서 실시간으로 환각을 예방할 수 없음
- API를 활용한 LLM judge 활용
- 비용, 보안, 프라이버시 문제 존재
해결책
Luna
개요
- DeBERTA-large (440M) 파인튜닝 모델
- NLI 태스크를 학습한 사전학습 모델의 가중치를 초기값으로 활용
- RAG에서 hallucination을 감지
- LLM judge와 대등한 성능
- 다양한 도메인에 일반화 가능
- 더 낮은 latency
- 실시간 배포에 유리
- 모델을 직접 띄워 실행 가능 (local execution)
- 보안 및 프라이버시 문제 해결
- LLM judge와 대등한 성능
환각 확률 구하는 방법
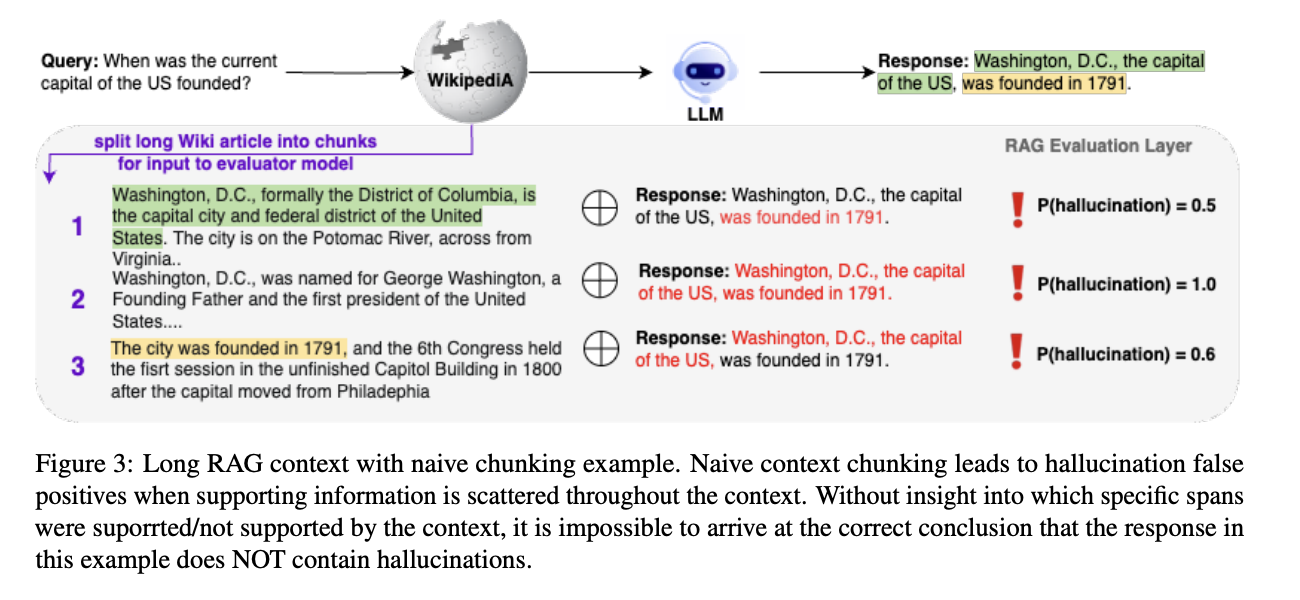
- 쿼리와 검색된 문서(context)가 주어졌을 때, 응답에서 지원되는(supported) 토큰을 식별
- 응답에서 환각이 존재하는 영역(span)을 찾아내고자 함
- 긴 문서에서도 잘 작동하기 위해서, span-level 예측을 활용
- 위의 그림 예시처럼, 긴 문서를 단순한 청킹 방식으로 쪼갤 경우 정보가 흩어져있을 때 이를 환각으로 오인할 수 있음 (위의 그림 예시는 Luna가 선택한 방법이 X)

- 응답과 문서를 비교해, 토큰 단위로 지원되는지(supported) 여부를 식별
- 응답의 특정 길이(window)에 위치하는 토큰들에 대해서, 모든 문서에 걸쳐 최댓값을 취함
- 위의 그림에서 window는 각각 초록색, 노란색 영역
- 토큰의 최댓값을 취한다는 건 1P, 2P, 3P에 대해 세로로 확인하며 최대 확률을 선택함을 의미
- 환각 확률 = 1 - (지원되는 토큰의 확률 중 가장 작은 값)
학습
- NLI 분류 헤드의 가중치로 환각 예측 헤드의 가중치 초기화
- 학습 시 환각 토큰의 확률에 대해 1. 모순 확률을 높게 2. 수반 확률은 낮게 학습
- 추론 시 각 토큰의 수반 확률을 출력
- 데이터 변형 기술 활용
- 문서 일부를 삭제하거나 삽입
- 질문과 응답을 섞음
데이터셋
- RAG QA 데이터셋을 만들기 위해 open-book QA 데이터셋을 재활용
- 5개의 산업군 데이터셋 카테고리 활용
- 고객 지원 (DelucionQA, EManual, TechQA)
- 금융 및 수치 추론 (FinQA, TAT-QA)
- 바이오의료 연구 (PubmedQA, CovidQA)
- 법률 (Cuad)
- 일반 지식 (HotpotQA, MS Marco, HAGRID, ExpertQA)
- GPT-3.5와 Claude-3-Haiku를 활용해 새로운 응답 두 개 생성
- RAG QA 데이터셋의 모델 응답 후보로 활용 (response)
- 다양성과 환각 가능성을 부여하기 위해 temperature=1로 세팅
- GPT-4-turbo를 활용해 RAG QA 데이터셋 정답 생성
- nltk를 활용해 문서(context)와 답변(response)를 문장으로 쪼갬
- 문장 수준으로 환각 여부 레이블링 진행 (supported, not supported)
- GPT-4-turbo를 활용해 정답(annotation, ground truth) 생성
- chain-of-thought 활용
- 응답 수준(response-level), 문장 수준(sentence-level) annotation을 비교해 모순이 없는지 확인
- 최대 3번까지 re-annotation을 해 모순되는 데이터가 2% 미만이 되도록 수정
- 예외적인 케이스이나 "지원된다(generally supported)"고 레이블링한 케이스들
- 문장과 문장을 이어주는 접속문 (transition sentence)
- 일반적인 문장
- 문장 내 토큰들이 부분적으로만 지원하는 경우에도, 응답 수준 - 문장 수준과 모순이 있는 경우 "지원되지 않는다(not supported)"라고 레이블링
- nltk를 활용해 문서(context)와 답변(response)를 문장으로 쪼갬
평가
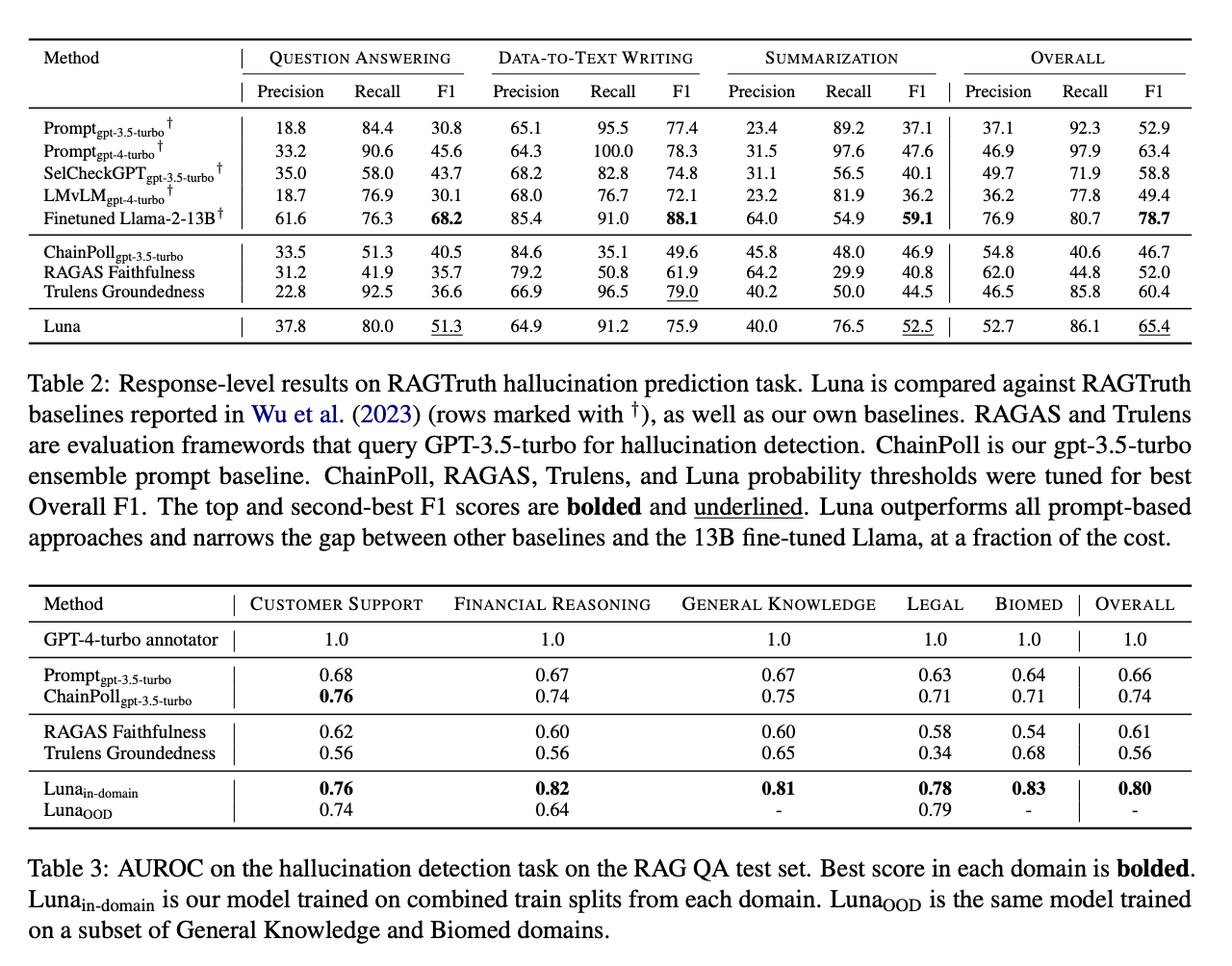
- 데이터셋
- RAGTruth
- RAG QA Test Set
- 베이스라인
- zero-shot 프롬프팅
- ensemble 프롬프팅
- RAG 평가 프레임워크 (RAGAS, Trulens)
- 평가지표
- Precision, Recall, F1 (RAGTruth)
- F1 기준 최고 성능을 내는 threshold를 설정해, 모델의 출력 확률을 이진화
- AUROC (RAG QA Test Set)
- Precision, Recall, F1 (RAGTruth)
한계
- closed domain 환각만 탐지 가능
- 다시 말해, 문맥이 있는 경우에만 환각 탐지 가능
- 일반적인 사실과 위배되는지 여부(open domain 환각)을 판단하기에는 Luna가 너무 작은 모델임
- 파라미터에 저장된 지식이 한정적
- LLM(GPT-4-turbo)을 활용한 annotation
- 환각 여부에 대한 레이블링 품질 개선 여지 존재
- 토큰 단위 예측을 수행하는 모델이나, 학습한 데이터셋은 문장 단위로 레이블링됨
- 문장 단위 예측으로 학습한 모델이 토큰 단위 예측도 효과적으로 하리라는 보장이 없음

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab