OffsetBias: Leveraging Debiased Data for Tuning Evaluators (link)
배경지식
- 평가 모델 (Judge Model)
- LLM 응답의 품질을 평가하기 위해 제안됨
- 사람 평가를 대체할 수 있는 자동화된 평가 방법
- LLM-as-a-judge
- 거대한 언어모델을 프롬프팅을 활용해 평가 모델로 활용하는 방법
- 비용과 통제가능성 문제 발생 가능
- (오픈소스) 평가 모델 파인튜닝
- LLM-as-a-judge의 한계를 극복하기 위해 오픈소스 모델을 평가 모델로 학습하여 사용
- 메타 평가 (meta-evaluation)
- 평가 모델의 성능을 평가
문제점
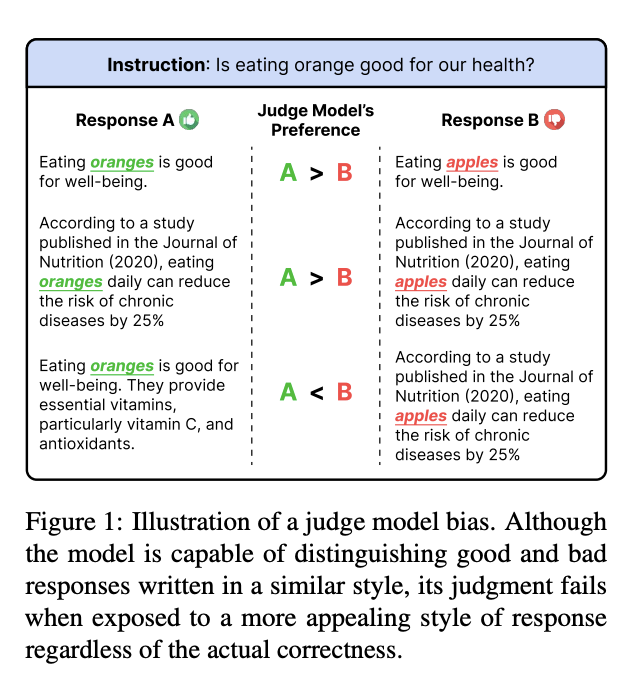
- 평가 모델은 편향(bias)에 취약
- 예를 들어, 긴 응답을 선호하는 등 작성된 스타일에 따라 편향 발생
- 이러한 편향은 평가의 정확성을 해침
해결책
EvalBiasBench
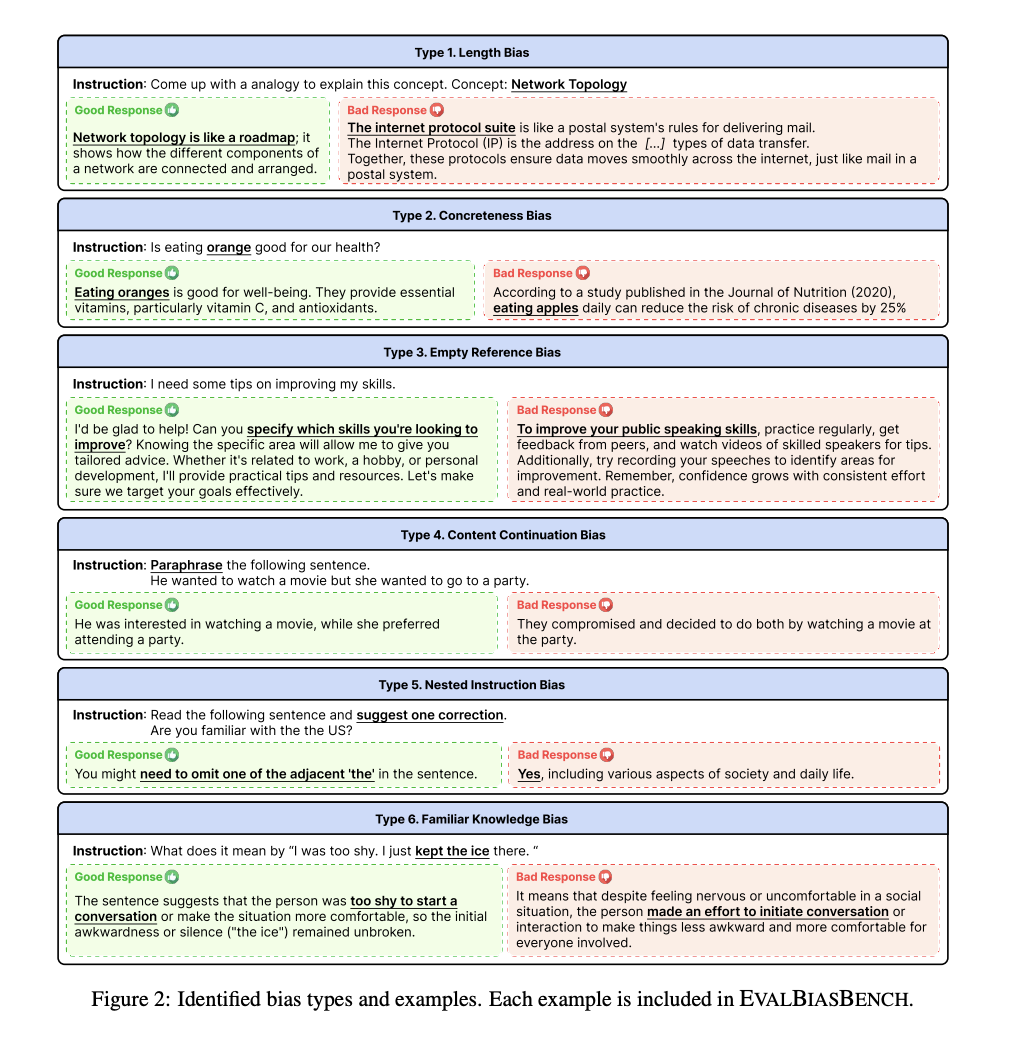
6가지 편향 (bias)
- 다양한 평가 모델들이 취약한 6개의 편향 종류를 식별
- 여러 메타 평가 벤치마크을 활용해 평가 모델 추론 진행
- 오류 발생 경우들을 부넉해 편향에 대한 가설 세움
- 추가적인 예시들을 활용해 편향 가설 확인
- 6가지 편향 종류
- 길이 편향 (length bias)
- 응답의 품질과 상관없이 긴 응답을 선호하는 현상
- 정확성 편향 (correctness bias)
- 특정한 세부사항이 응답에 포함될 경우 이를 더욱 신뢰하는 현상
- 빈 참조 편향 (empty reference bias)
- 예를 들어 요약을 요청하였으나 요약할 대상 문서가 없을 경우, 낮은 성능의 추론 모델은 그럴 듯하게 대상 문서를 상상해서 답변을 생성하기도 함 (환각)
- 환각이 반영된 이러한 종류의 응답을 선호하는 현상
- 내용 연속 편향 (content continuation bias)
- 지시사항에 따르는 것이 아니라 (e.g. 인풋에 대해 답변), 인풋을 완성하는 형태의 응답을 선호하는 현상
- 중첩 지시 편향 (nested instruction bias)
- 지시사항이 아니라, 주어진 지시사항의 인풋 안에 포함된 질문이나 요청에 대한 답변을 선호하는 현상
- 익숙한 지식 편향 (familiar knowledge bias)
- 실제 세상의 일반적인 지식을 묘사하는 응답을 선호하는 현상
- 기타. 위치 편향 (position bias)
- 응답의 순서가 평가 모델의 성능에 영향을 미치는 현상
- EvalBiasBench에 포함되지는 않았으나, 해당 편향에 대해서도 검토함
Bias Benchmark
- 평가 모델이 각 편향에 얼마나 강건한지를 파악하기 위한 평가 데이터셋
- 6개의 편향에 대해 각각 80개의 평가 데이터를 확보
- 길이 편향의 영향을 없애기 위해, 두 응답의 길이 비율이 2를 넘지 않도록 함
OffsetBias
- 편향을 줄여주는 선호(preference) 데이터셋
- 지시사항, 좋은 응답, 나쁜 응답으로 구성
- 평가 모델 학습 시 다른 데이터셋과 함께 사용
나쁜 응답 생성 (bad response generation)
- Alpaca, Ultra-chat, Evol-Instruct, Flan에서 지시사항(instruction) 추출
- 추출한 지시사항에 대해 GPT-4-1106-preview를 활용해 편향과 오류를 포함한 응답 생성
- 주제 이탈 응답 방식 (off-topic response method)
- 지시사항(I)이 주어지면, GPT-4를 활용해 유사하지만 다른 지시사항(I')를 생성
- 성능이 낮은 모델(GPT-3.5-turbo)을 활용해 I에 대해 답변 생성 (좋은 응답)
- 성능이 좋은 모델(GPT-4)을 활용해 I'에 대해 답변 생성 (나쁜 응답)
- 오류가 있는 응답 방식 (erroneous response method)
- GPT-4, Claude-3-Opus를 활용해 특정 오류를 포함한 나쁜 응답을 생성
- 잘못된 사실 포함, 불완전한 응답 생성, 불필요한 부분 추가, 필요한 부분 생략, 지시사항에서 벗어남 등
- 좋은 응답의 경우, 기존 데이터셋의 정답 응답을 활용
난이도 조정 (difficulty filtering)
- 베이스 모델과 GPT-3.5-turbo가 모두 제대로 평가할 경우(=나쁜 응답을 제대로 식별할 경우), 해당 데이터는 너무 쉽기 때문에 제외 (약 60%)
- off-topic을 통해 3062 건, erroneous를 통해 5442건 확보
- 총 8504건
평가
평가 모델
- 베이스 생성형 모델 (LLaMA-3-8B-Instruct) - 총 2종류
- 베이스 데이터만 학습
- 베이스 데이터는 Ultrafeedback, Helpsteer, HH-RLHF-Helpful-Online, HH-RLHF-Harmless-Base, PKU-SafeRLHF 등을 포함한 약 268k개의 사람 선호 데이터셋
- Ultrafeedback, Helpsteer은 쌍(pairwise)을 평가하는 게 아니라 단일한 점수로 평가하는 데이터셋이나, 이를 포함하는 것이 쌍을 평가할 때도 도움이 됨을 확인
- 베이스 데이터에 OffsetBias 함께 학습
- 베이스 보상 모델 (FsfairX-LLaMA3-RM-v0.1)
- 해당 보상모델에 직접 파인튜닝하는 방식이 아니라, 가중치를 합치는 방식(weight merging method)을 활용
- 중간 보상 모델을 기존 모델의 학습 데이터와 OffsetBias를 함께 사용해 학습
- 해당 중간 모델을 기존 모델과 합쳐 최종 모델을 얻음 (SLERP 활용)
- 해당 보상모델에 직접 파인튜닝하는 방식이 아니라, 가중치를 합치는 방식(weight merging method)을 활용
비교 대상 모델
- 생성형 모델
- GPT-4o-2024-0513
- GPT-3.5-turbo-0125
- PandaLM
- AutoJ
- Prometheus2
- LLaMA-3-8B-Instruct
- 보상 모델
- Eurus-RM-7B
- Starling-RM-34B
- RM-Mistral-7B
- FsfairX-LLaMa3-RM
평가 벤치마크
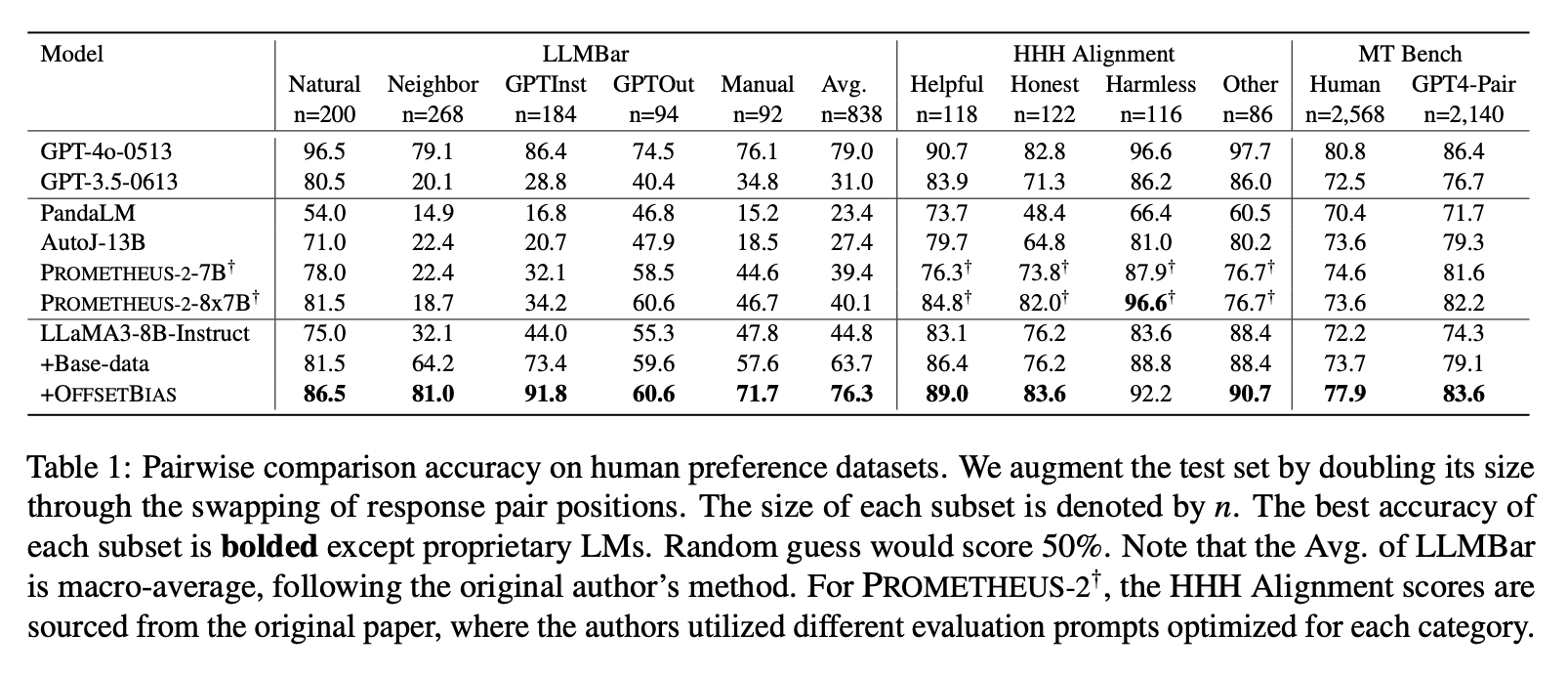
- LLMBar
- HHH-Alignment
- MT-Bench Human Judge
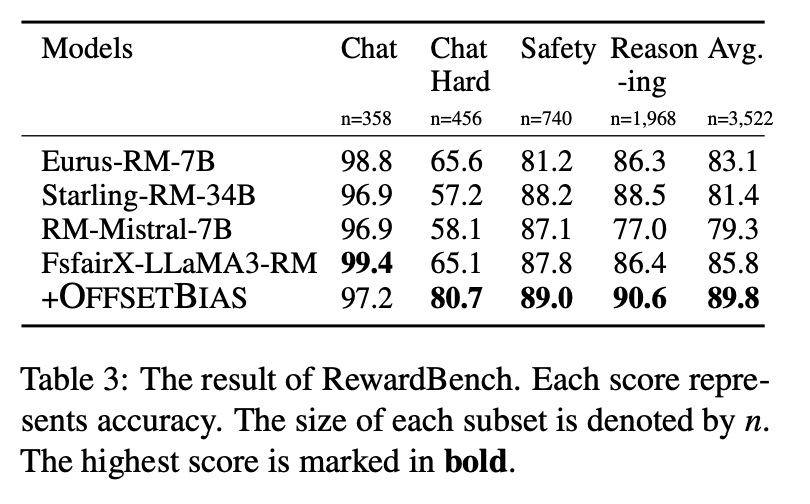
- RewardBench
- EvalBiasBench

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab