Prometheus: Inducing Fine-Grained Evaluation Capability in Language Models (link)
배경지식
- 최근 언어모델의 성능을 평가할 때 이전의 통계적 평가방식(e.g. BLEU, ROUGE)을 넘어 LLM을 활용하는 추세
- LLM을 사용한 평가(LLM as a judge)는 사람 평가와 상관성이 높음
- 커스터마이즈된 점수 기준을 활용할 수 있음
- 기존의 오픈소스 모델은 일반적인 평가는 가능하나, 특정 도메인/태스크를 평가하거나 세세한 내용을 평가하기는 어려움
문제점
- GPT-4와 같이 API를 사용해 호출하는 LLM(proprietary)을 사용한 평가는 아래와 같은 한계를 가짐
- 모델에 대한 정보가 공개되어 있지 않음 (closed-source)
- 버전 업데이트로 인해 이전의 평가 결과가 재현되지 않을 수 있음
- 상당한 API 호출 비용 발생 가능
해결책
Prometheus
적절한 정답(reference answer), 점수 기준(score rubric)이 주어졌을 때 GPT-4와 유사한 성능을 보이는 평가모델 (오픈소스)
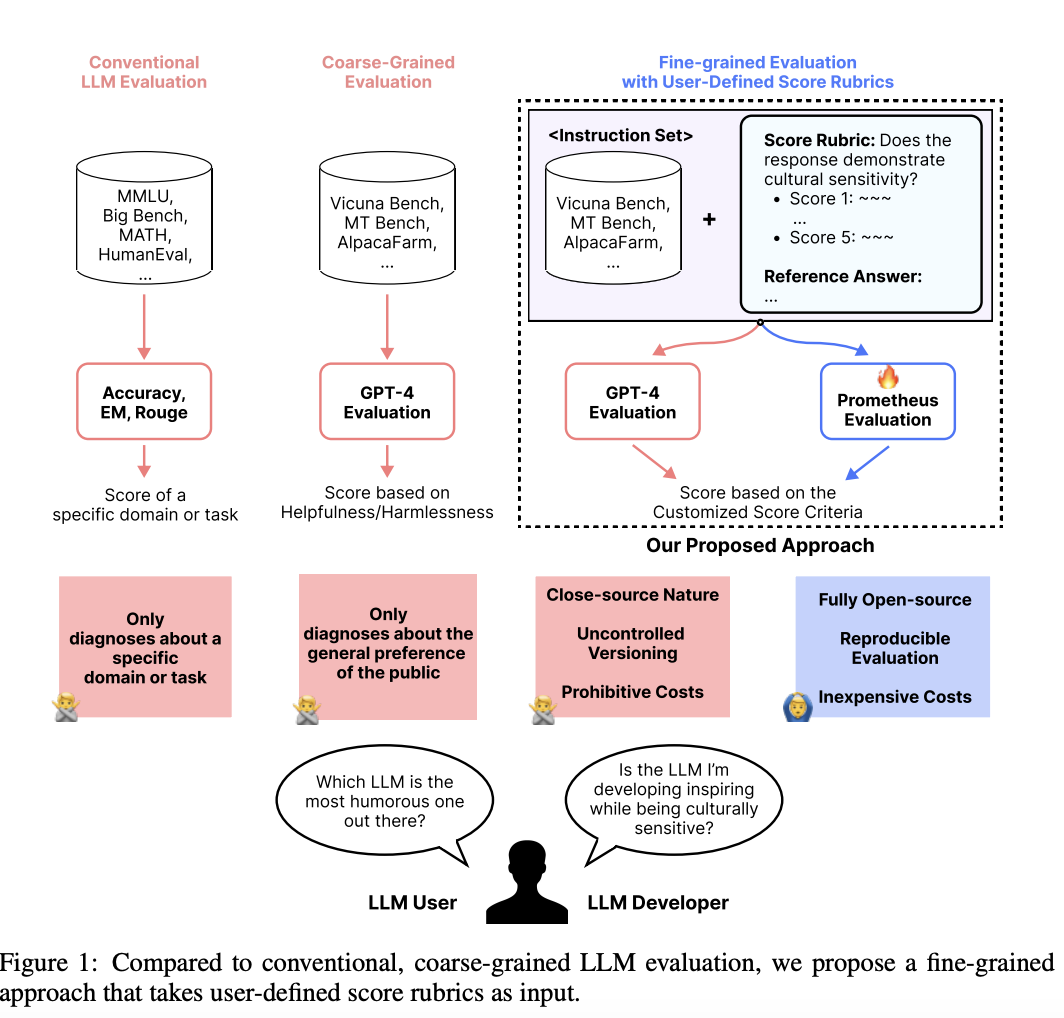
- GPT-4처럼 다양하고 상세한 평가가 가능하도록 학습된 13B 오픈소스 언어모델 (fine-grained)
- 직접 구축한 Feedback Collection 데이터셋을 활용하여 Llama-2-Chat-13B 파인튜닝
- 학습 시 피드백과 점수 사이에 [RESULT]와 같은 구문을 넣는 것이 중요
- 학습 시 정답과 점수 기준을 포함하는 것이 중요
Feedback Collection
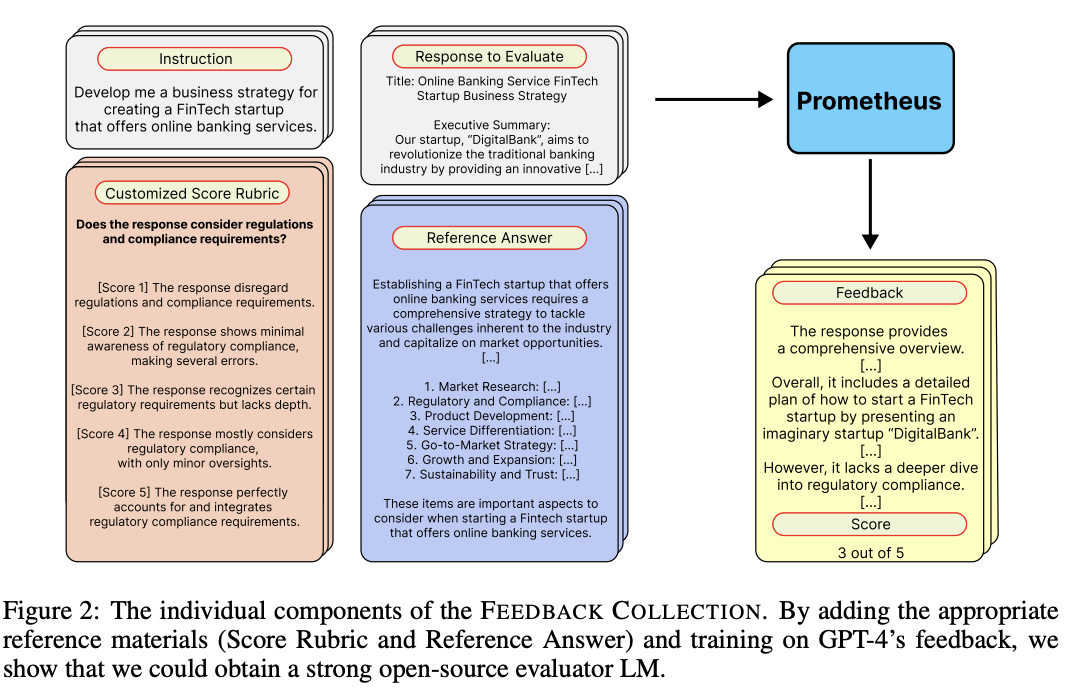
- 평가 언어모델을 학습하기 위해 고안된 데이터셋
- 커스터마이즈된 점수 기준과 정답을 포함
- 길이 편향을 예방하기 위해 각 점수(1-5)의 정답(reference answer)의 길이를 동일하게 유지
- 결정 편향을 예방하기 위해 점수의 균등 분포 유지
- 지시사항(instruction)과 응답의 범위를 현실적인 상황으로 한정
- 인풋으로 지시사항, 평가할 응답, 커스터마이즈된 점수 기준 (범주에 대한 설명과 점수 포함), 정답을 사용
- 아웃풋으로는 Chain-of-Thoughts와 유사한 피드백, 1-5 사이의 점수 사용

- 데이터셋 구축 과정
- 상세한 점수 기준 생성 (50개의 시드)
- GPT-4로 점수 기준 시드 증강
- 50개의 시드에서 4개씩 샘플링해 인컨텍스트 러닝의 예시로 활용, GPT-4에게 이를 기준으로 새로운 점수 기준을 생성하도록 프롬프팅 (brainstorm)
- GPT-4에게 새로 생성된 점수 기준을 다른 말로 바꾸도록 (paraphrase) 프롬프팅
- brainstorm -> paraphrse 과정을 10번 반복
- GPT-4로 지시사항 생성
- 주어진 점수 기준과 관련성이 높은 지시사항을 생성하도록 GPT-4 프롬프팅
- GPT-4로 학습 데이터 생성
- GPT-4를 활용해 1-5점으로 평가할 응답, 피드백을 생성
평가
절대 평가 (Absolute grading)
- 평가 언어모델이 지시사항, 평가할 응답, 정답, 점수 기준이 주어졌을 때 피드백과 점수를 생성
- 점수의 경우 사람 평가, GPT-4 평가와의 상관성 분석
- Pearson, Kendall-Tau, Spearman 활용
- 피드백의 경우 GPT-3.5-Turbo, GPT-4, Prometheus가 생성한 피드백의 품질을 사람이 비교 (pairwise comparison)
- 점수의 경우 사람 평가, GPT-4 평가와의 상관성 분석
- 평가 벤치마크
- Feedback Bench (Feedback Collection과 동일하게 생성)
- Vicuna Bench
- MT Bench
- FLASK Eval
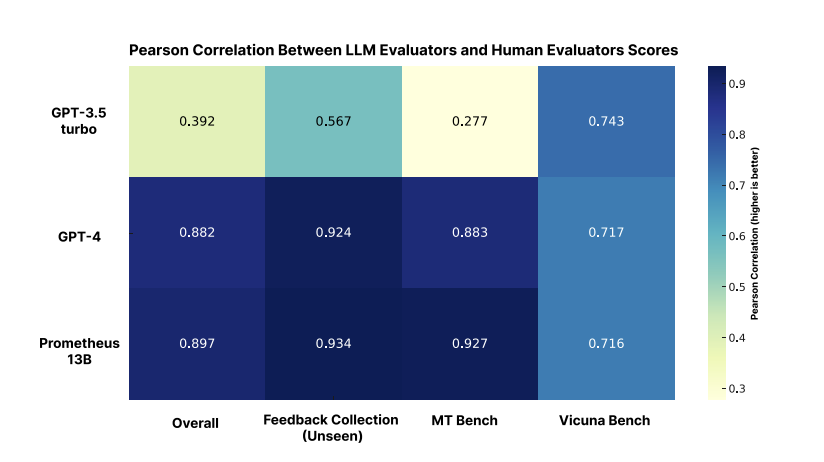
- 점수의 경우 사람의 평가와 높은 상관성을 보임
- 사람 평가의 경우 코딩, 수학 관련 질문들은 제외됨
- 피드백의 경우 GPT-4보다는 58.62%, GPT-3.5-Turbo 보다는 79.57% 더 선호됨
- GPT-4의 경우 피드백이 너무 일반적이고 추상적이라는 평가 존재
- Prometheus의 경우 피드백이 너무 비판적이라는 평가 존재
- 이렇듯 상관성이 높은 이유는 학습 데이터셋이 평가 데이터셋과 유사한 분포를 가지기 때문인 것으로 추정
순위 평가 (Ranking grading)
- 사람의 선호 벤치마크를 활용해 정확성을 평가
- 만약 동점이 나온다면, 하나의 모델이 승리할 때까지 평가 반복 (temperature=1.0)
- 평가 벤치마크
- MT Bench Human Judgement
- HHH Alignment
- 절대 평가에 대한 학습이 순위 평가의 성능 개선에 긍정적 영향을 줌
Baselines (비교 모델)
- Llama2-Chat-7,13,70B
- Llama2-Chat-13B + 다른 논문에서 제시된 12개의 점수 기준으로 학습
- 약간의 점수 향상이 있었으나 크지 않았음
- 이에 대해 다양한 점수 기준을 학습하는 것이 중요하다고 판단
- Flask Eval을 학습하여 Flask Eval에서는 Prometheus 능가
- 태스크 특화 평가모델을 위해서는 평가 데이터셋으로 직접 학습하는 것이 유용
- 약간의 점수 향상이 있었으나 크지 않았음
- GPT-3.5-Turbo-0613
- GPT-4-0314,0613,최신
- StanfordNLP Reward Model
- ALMOST Reward Model

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab