YOLO v2 모델 개요 + VGG , NIN , GAP
YOLO v1 모델
- YOLOv1 모델은 GoogLeNet을 기반 커스텀 모델
- YOLOv1 모델은 VGG16보다 빠르지만 성능이 좋지 않음
v2 → VGG 모델을 튜닝해서 사용했습니다. VGG모델은 그 당시 최고의 모델 중 하나로써 지금까지 사용이 많이 되고 있으며 많은 모델의 기반이 됩니다.
VGG의 컨셉은 ‘깊게 가보자’입니다.
당시 많은 연구자들이 했던 연구들 중에 뭐가 있었냐면 깊을수록 성능이 좋다는 인식이 있었습니다.
일반적으로 모델이 깊어지면 속도는 느려지지만, 성능은 좋아진다는 일반적인 견해때문에 일단 깊게 가보는 것입니다.
VGG 연구자들이 아래의 실험 테이블을 만들어서 모델을 연구했는데 , 성능이 개선되었음을 확인할 수 있습니다.
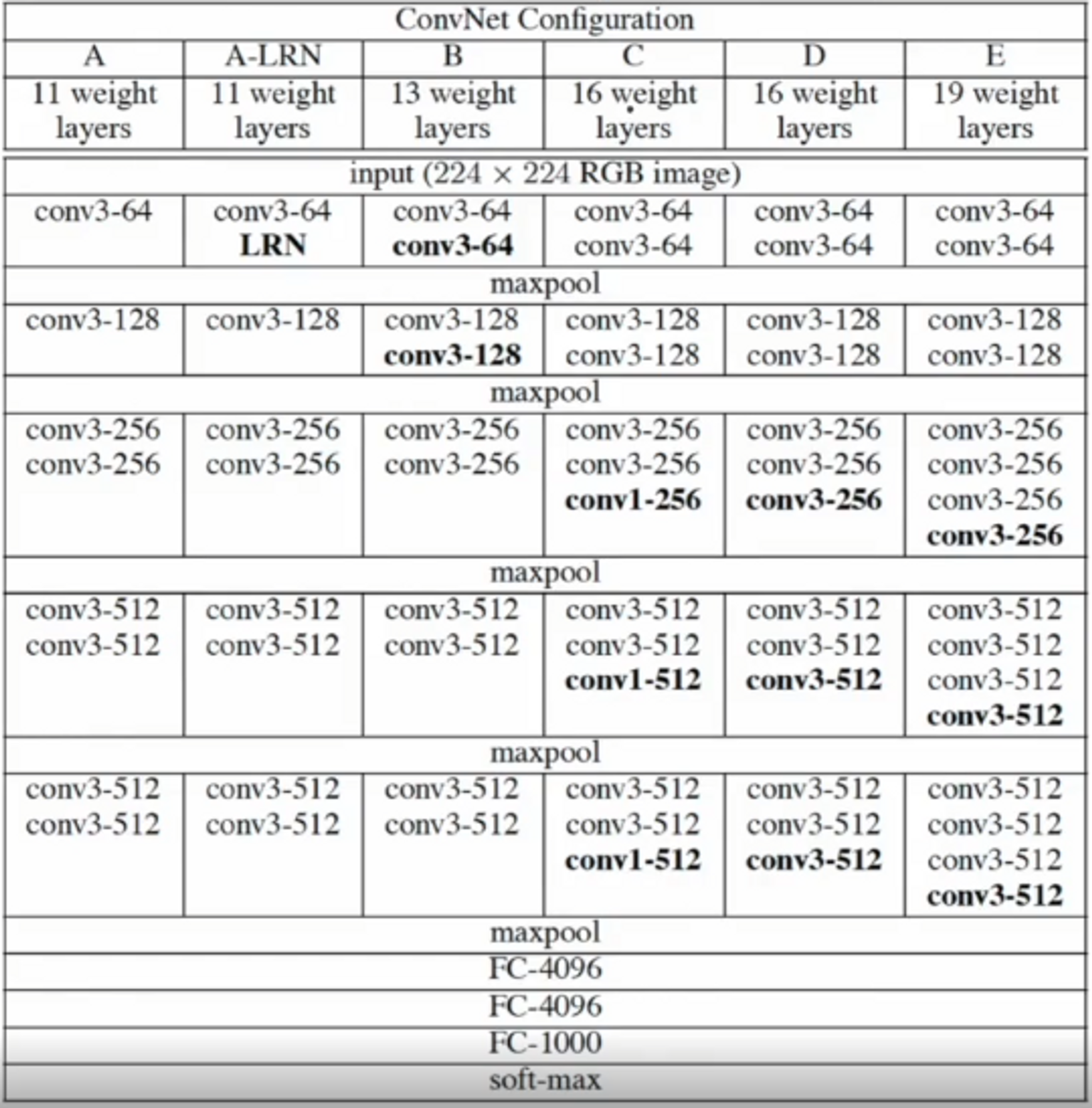
그래서 VGG를 기반으로 한 모델을 만들건데, 작은 테크닉을 적용합니다.
VGG는 conv을 그냥 사용합니다. convolutional operator의 연산은 어떻게 진행되죠?
3x3 filter가 있다고 했을 때, 이미지의 국소적인 부분을 filter로 봤었죠.
Convolutional 연산은 linear convolution으로 이루어져 있었습니다.
그 다음 feature map의 첫번째 연산은 이미지의 각 픽셀이 갖는 값과 filter의 값으로 linear combination을 통해 계산했습니다. 각 위치에 해당하는 값끼리 곱한 뒤에 더해서 계산했죠?
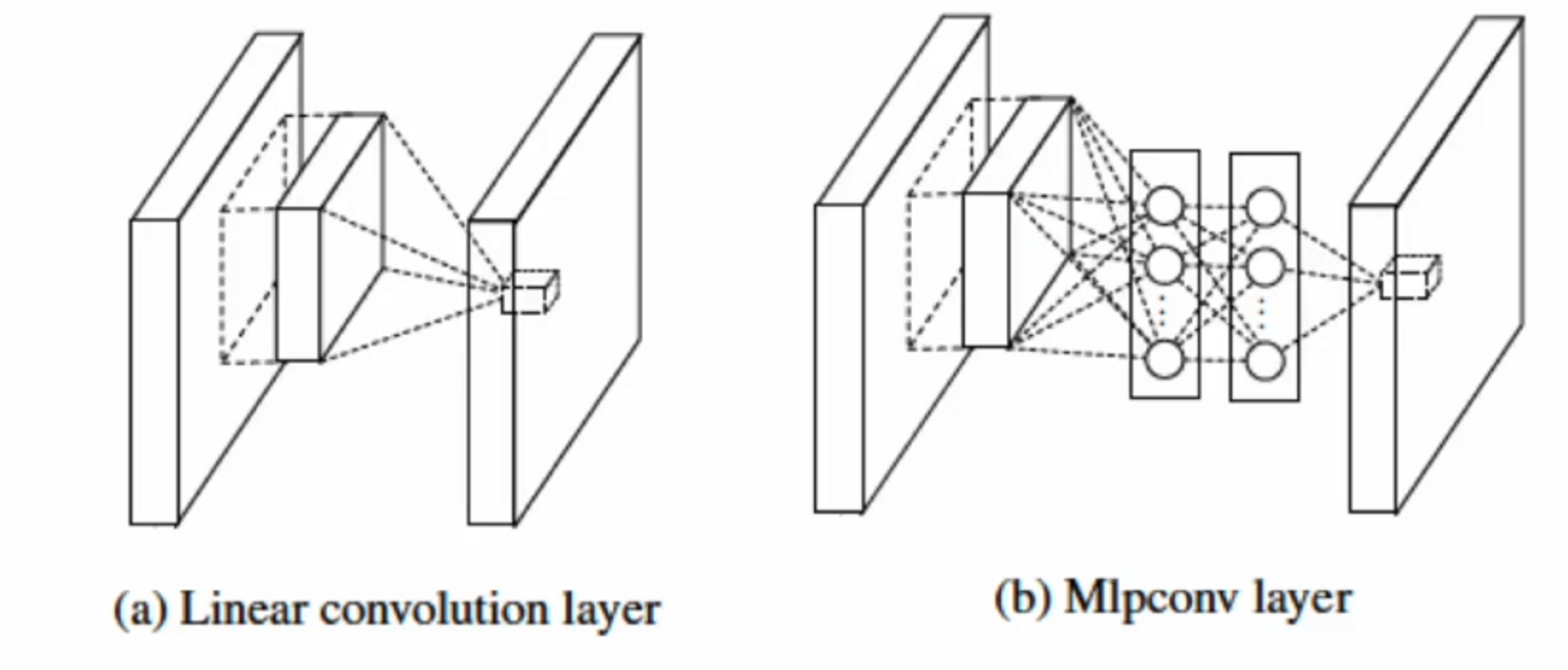
여기서는 조금 더 성능을 높이기 위해서 Convolution 네트워크 안에 Network in Network 기술을 사용한 것입니다. 말 그대로 네트워크 안에 네트워크를 한 번 더 넣는건데요, Convolution 연산 후에 일차결합을 하지 않고 중간에 MLP 연산을 넣는거예요.
YOLOv2
VGG와 유사하게 3x3 필터를 사용
Max Pooling 후 채널을 2배씩 늘림
Batch Normalization 사용
FC 삭제 - Global average pooling으로 대체
NIN 적용
YOLO v2 모델구조 - Passthrough layer , Polynomial lr decay
Darknet19
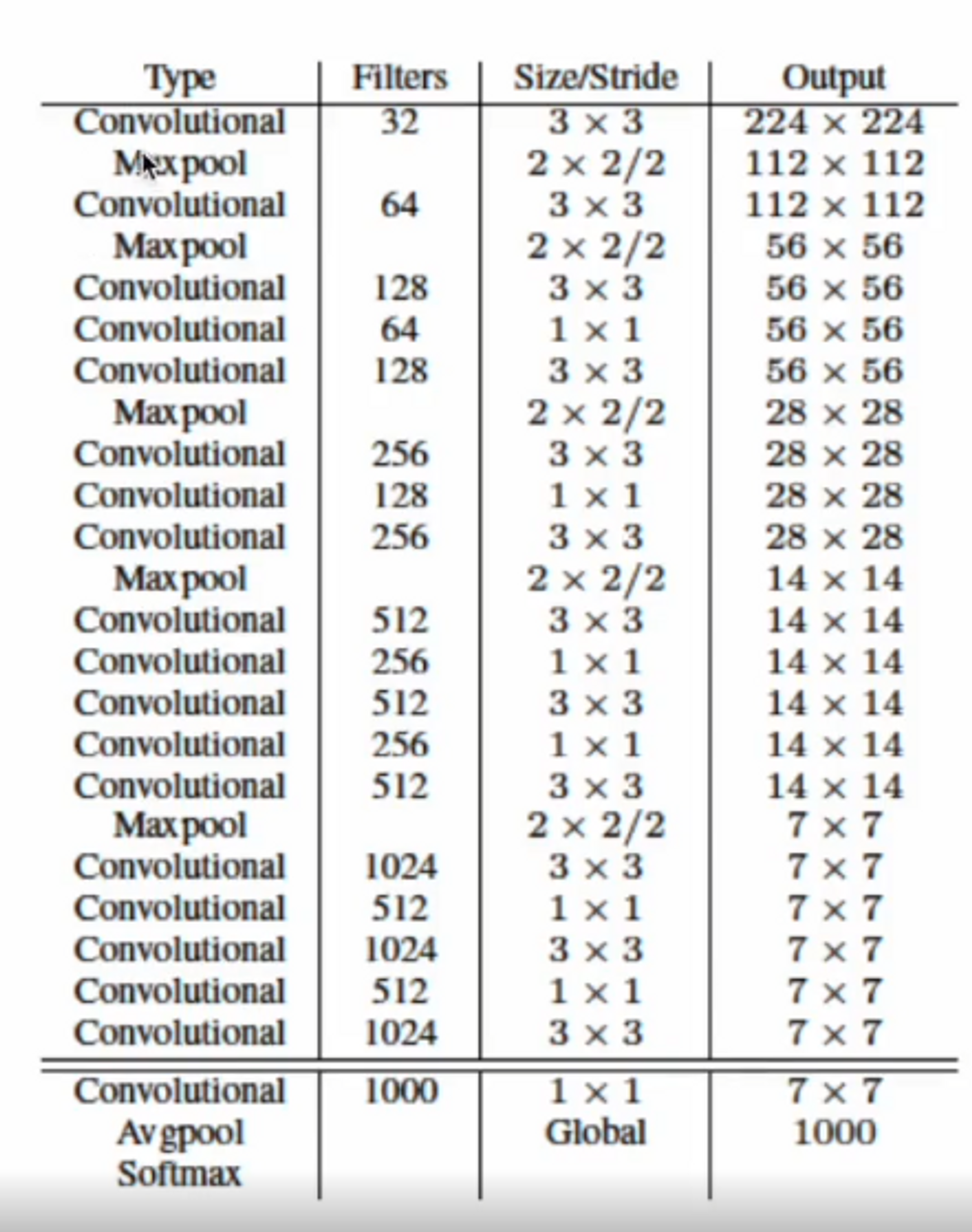
yolo v2 모델은 VGG를 기반으로 했기 때문에, deep하게 형성되어 있고, 블록들이 유사하게 구성되어 있습니다 ( Convoutional ).
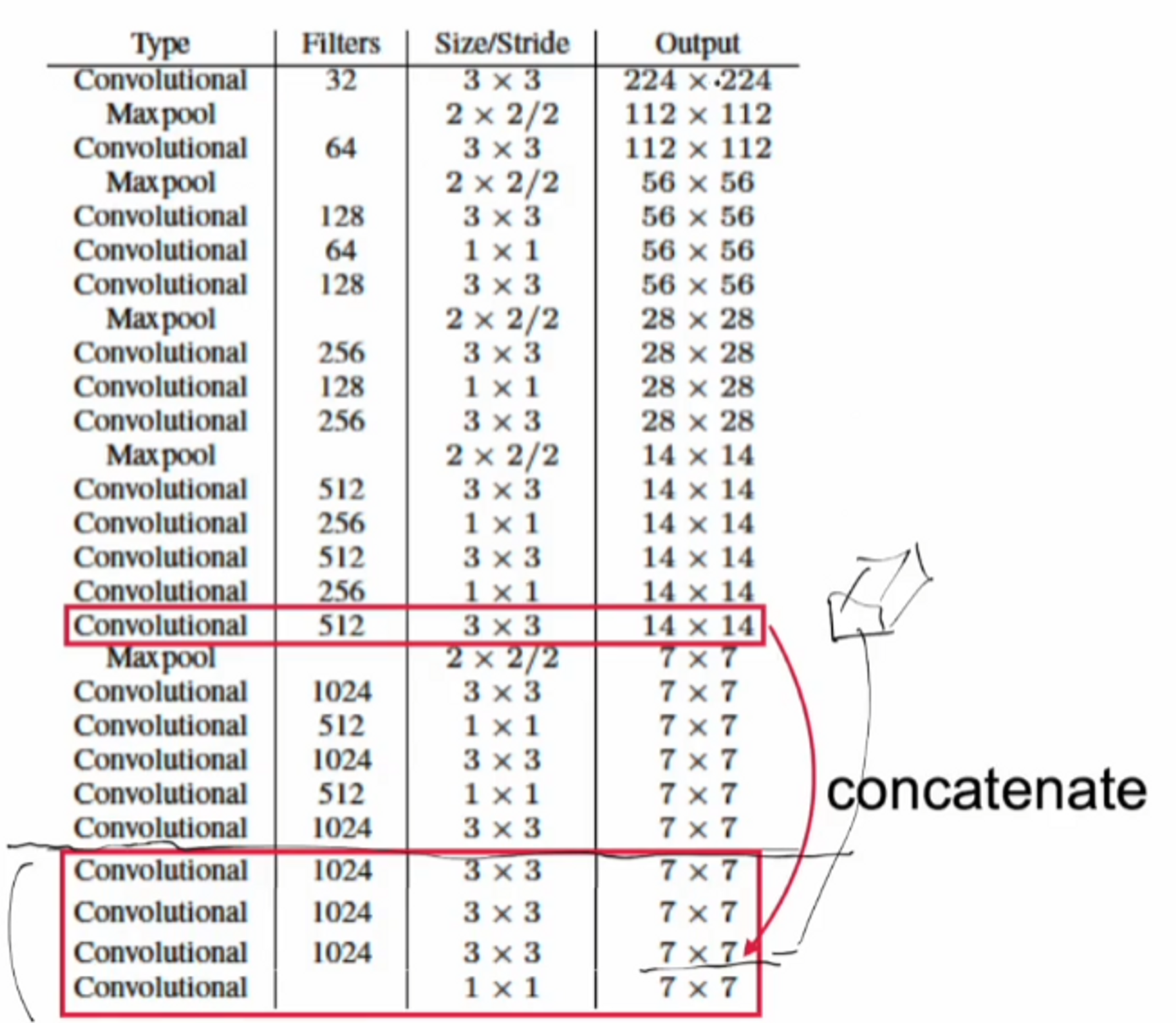
VGG기반인 NIN(Network in Network) 기술이 적용된 네트워크를 Darknet19이라고 부르기로 했습니다. Conv layer가 19개 maxpooling이 5개 입니다. 그래서 Darknet’19’라는 이름으로 불리게 되었습니다.
3x3 , 1x1 을 섞어서 쓰는 저런 조합은 메모리를 효율적으로 사용하는 방법입니다. 아주 많이 쓰는 구조 중 하나이죠. 그리고 채널 수를 마음대로 바꿀 수 있는 것이 장점입니다.
512에서 256으로 바꿨다가 다시 512로 바꿔주네요. 이미지 사이즈는 유지한채 연산량을 한 번 더 늘려서 계산할 수 있는데, 효율적인 연산을 위해서 채널 수도 조정할 수 있습니다.
초반에는 ImageNet으로 훈련을 하기 때문에 Conv 연산의 filter가 1000개로 세팅이 되어있는 것을 보실 수 있습니다. 채널 수가 마지막의 크기이기 때문에 7 x 7 x 1000 를 GAP(Global Average Pooling)을 시행하면 1000 x 1 짜리 벡터가 하나 나오는거죠.
모델 학습
- 사전 학습
- 1000개 클래스를 가진 224x224 ImageNet 데이터 이용 ( 160 epochs )
- Darknet19 사용 ( GAP을 사용했기 때문에 입력 이미지 사이즈에 대해서 영향이 없음 → 이미지를 한 번 더 키울 수 있음. )
- 448x448 ImageNet 이미지로 추가 학습 ( + 10 epochs )
- Polynomial learning rate decay 4승 사용 ( yolov1에서는 multi step scheduler 사용 )
- momentum optimizer 사용
- Data Augmentation 적용 : 랜덤 크롭, 컬러 변환 등
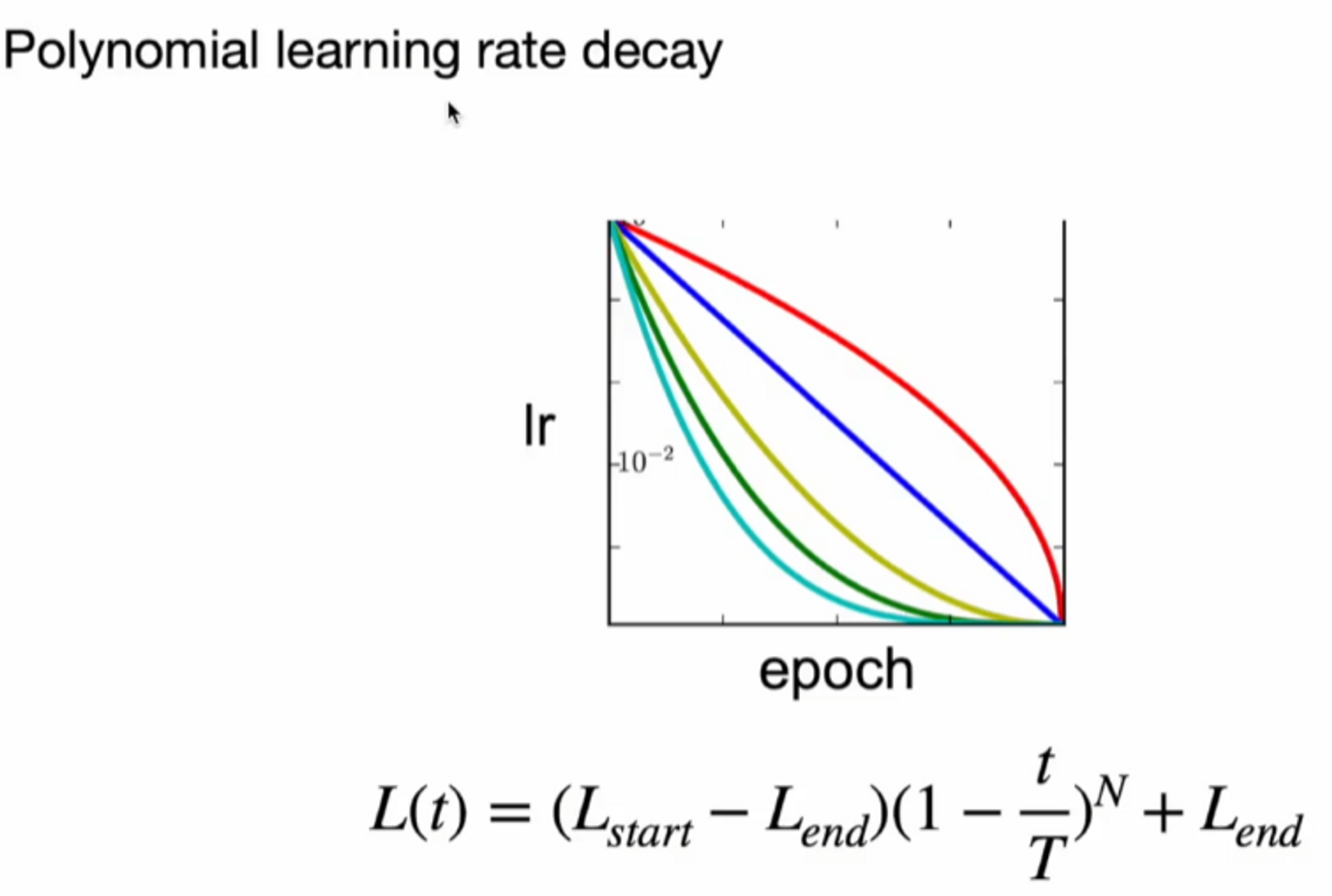
Polynomial learning rate decay는 논문에서 레퍼런스를 찾을 수 없습니다.
찾아본 내용을 바탕으로 적어보겠습니다.
일반적으로 learning rate ( as lr ) 은 epoch이 커지면 작게 설정하게 되어있습니다.
polynomial 함수를 하나 그려서 아래의 그래프 처럼 lr을 줄여가면서 학습을 진행하겠다는 것이죠.
그래서 몇 승을 쓰느냐에 따라서 저렇게 색깔별로 다양한 그래프가 나올 수 있습니다.
각 epoch마다 진행되기 때문에 아래의 식에서 ‘t / T’ = epoch에 대한 정보가 들어있습니다.
→ 스케줄링 기법 중 하나
Main 모델 학습
- 추가 학습 ( Fine - Tuning for detection )
- 탐지를 위해 모델 후반부 수정 ImageNet 데이터로 학습을 했을 때는 클래스가 1000개이기 때문에 average pooling을 하기 위해 1000개의 채널을 마지막에 만들었어야 했는데, 이 부분을 바꿔줍니다. conv 4개를 더 붙여서 수정을 진행합니다. 여전히 fc는 사용하지 않습니다.
- passthrough layer 사용 모델이 이미지를 받고 layer들을 거치는데 ( conv1 , conv2 ,,, ) 중간에 있는 Feature map을 가지고 와서 뒷 부분에 있는 feature map과 concatenate
- 탐지를 위해 모델 후반부 수정 ImageNet 데이터로 학습을 했을 때는 클래스가 1000개이기 때문에 average pooling을 하기 위해 1000개의 채널을 마지막에 만들었어야 했는데, 이 부분을 바꿔줍니다. conv 4개를 더 붙여서 수정을 진행합니다. 여전히 fc는 사용하지 않습니다.
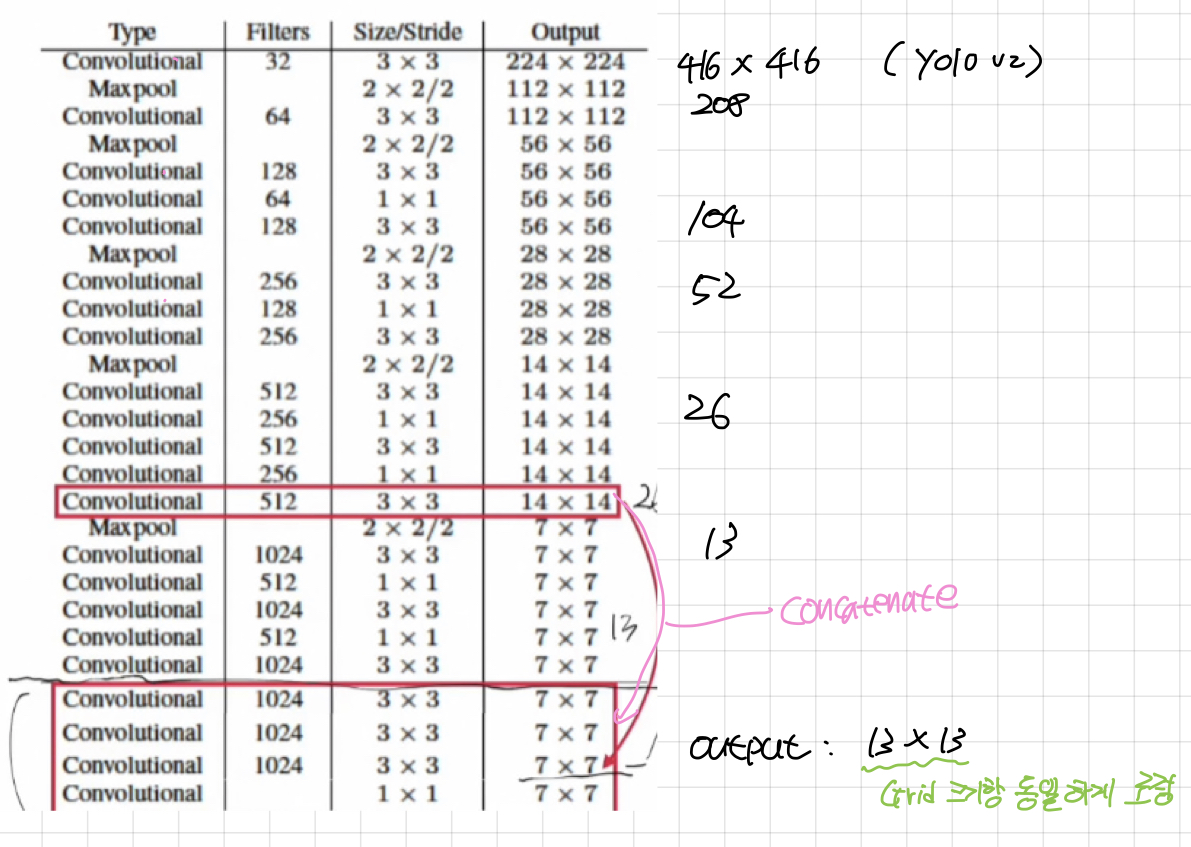
- 416x416 데이터 사용 ( Multi scale training : 320, 253, .. ., 608 ) 학습 시에 Multi scale training을 사용했습니다. 매 10회 배치마다 랜덤으로 사이즈를 변경해서 모델에게 주입을 시킵니다. ( 320부터 608까지 자유롭게 랜덤으로 바꿔가며 학습 )
- momentum optimizer 사용
- Data Augmentation 적용 : 랜덤 크롭, 컬러 변환 등
- 다양한 기술 적용 → NIN , passthrough layer , Batch Norm
passthrough Layer
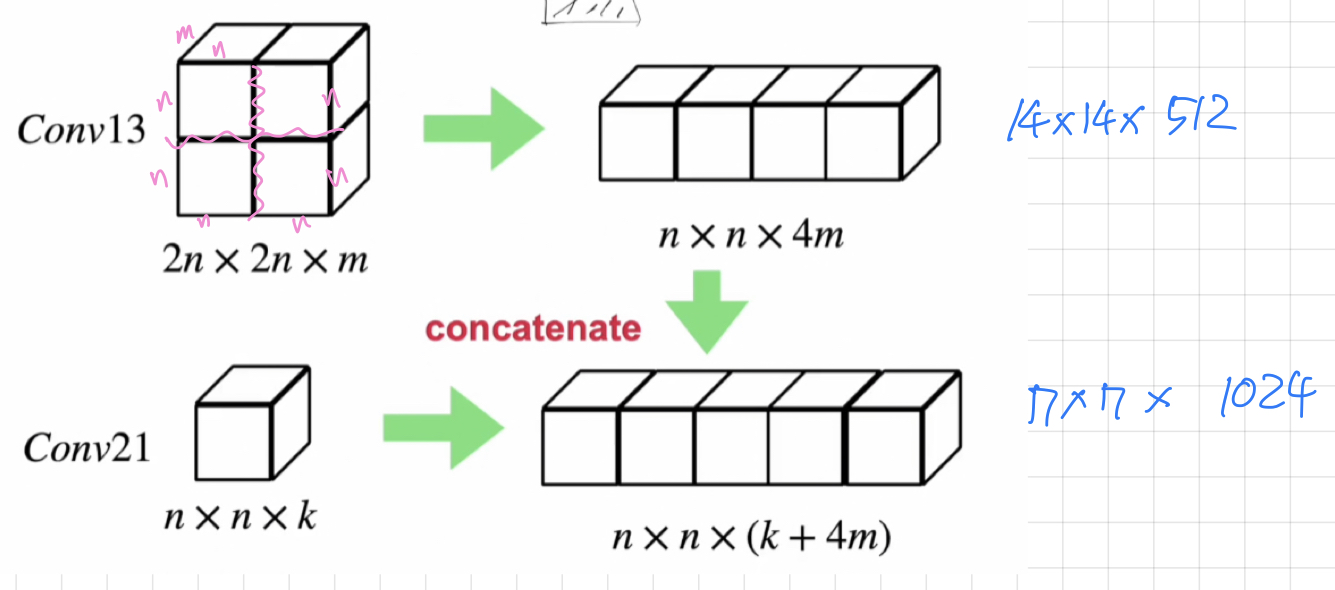
앞서 봤듯이 , low level에서 만든 feature map과 high level에서 만든 feature map의 사이즈가 다르잖아요 ? 그래서 그 사이즈를 보면
마지막 전 단계의 feature map의 사이즈는 n x n x k 입니다. 그리고 우리가 가지고 온 feature map의 사이즈가 2n x 2n x m 사이즈입니다.
이 둘을 붙여야하는데 사이즈가 다르기 때문에
conv13을 4등분을 해줍니다. 각각 4등분에 대한 크기는 n x n x m 입니다.
4등분한 요소들을 일렬로 붙이면 크기는 n x n x 4m이 되죠 ?
그러면 우리가 붙여야 하는 feature map의 사이즈 ( n x n x k )와 동일한 사이즈를 얻을 수 있습니다.
이제 이걸 뒤에 붙이면 됩니다. 그래서 마지막 conv layer에 들어갈 input 값이 n x n x ( k + 4m )이 되는 것입니다.
Activation maximization ( 논문과 무관하지만 관련 내용 )
CNN은 일반적으로 low level ( 앞 부분의 layer ) 에서는 작은 패턴이나 색상이나 질감이 잘 포착된다고 하구요, high level에서는 객체의 형상을 본다고 합니다. 큰 이미지 shape을 본다는 것이죠.
아래의 그림은 activation maximization 기술을 사용해서 만든 그림인데, 이게 뭐냐면
각 layer의 filter가 최대 활성화가 되기 위한 이미지는 어떤 이미지를 필요로 할지에 대해 생각해 봤을 때, pre-trained 된 모델의 filter를 고정한 채 이미지를 최적화하여 이 filter가 가장 활성화 되는 이미지를 찾는 기술이에요.
만약에 이게 이해가 잘 안간다면, low level 딴에서는 color, 자동 개체, texture 이 정도를 본다! 는 정도만 알고 있으면 되고 high level에서는 object shape을 본다! 라는 것 정도 알고 계시면 좋을 것 같습니다.
아래의 그림을 보면 conv이 깊어질수록 작은 형상들이 나오기 시작합니다.
color나 texture에서 점점 눈, 코와 같은 구체적인 object shape이 뚜렷해지네요 !
passthrough layer를 사용할 경우 high level에서 low level을 사용할 수 있다는 장점이 있습니다.
이런 background가 있다는 것만 알고 계시면 될 것 같습니다 :)

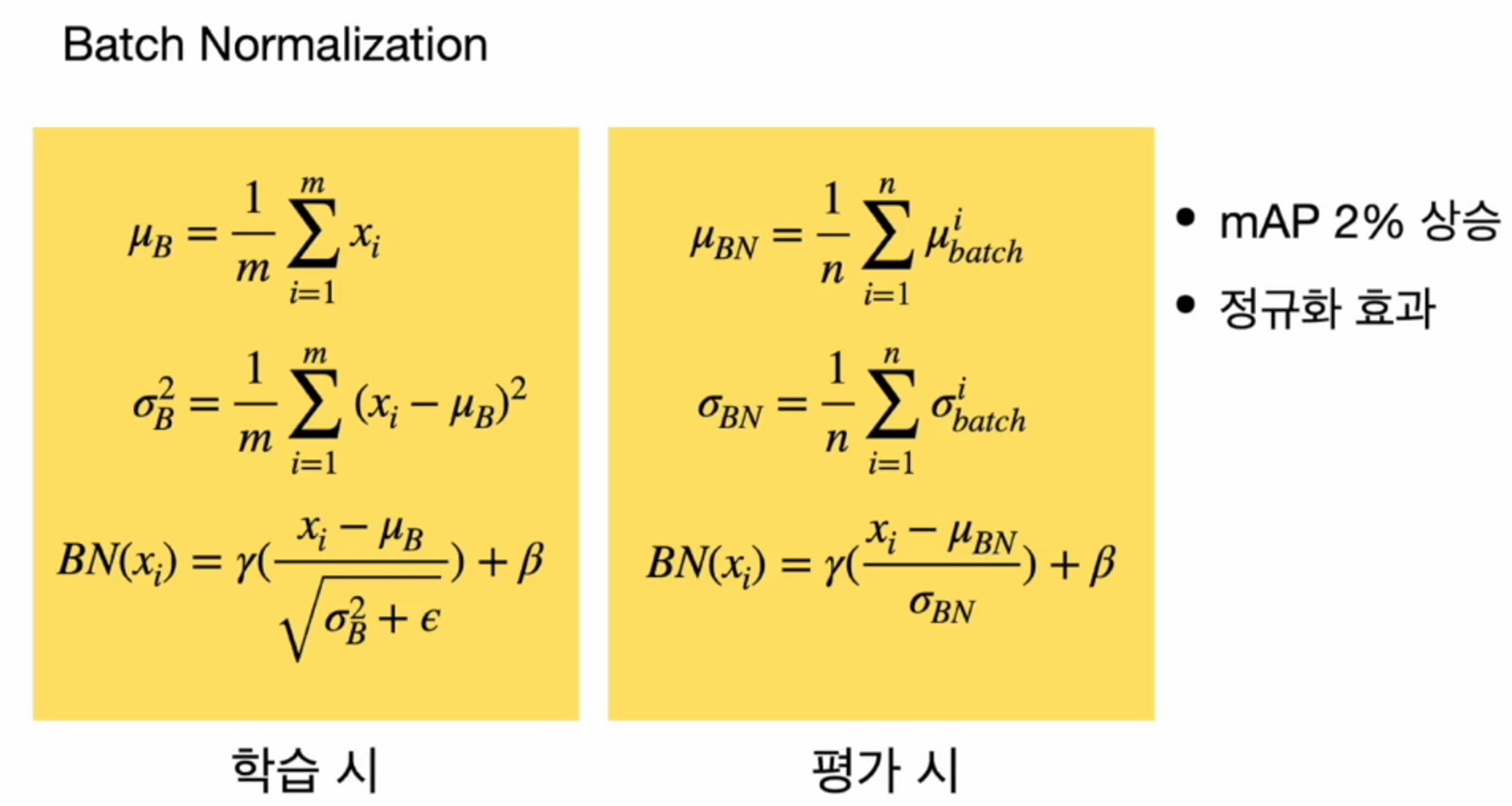
Batch Normalization
Batch Normalization ( 배치 정규화 )는 수렴 속도를 빠르게 하고 정규화 효과가 있는 것으로 알려져있죠. 일반적으로 conv 뒤에 사용하고 Feature map의 결과를 정규화해서 항상 동일 분포위에 있도록 하는 방법입니다. 각각의 Batch에서 들어오는 평균과 분산을 구하구요 그 평균과 분산을 바탕으로 정규화를 진행합니다.
분산이 너무 작은 경우에 분모가 0이 되는 것을 방지하고자 입실론(작은 값)을 더해줬고, 정규화를 스케일링 ( 감마를 곱해주고, 베타를 더함 ) 해줬습니다. 여기서 감마랑 베타도 학습이 가능한 파라미터입니다. 따라서 Batch Norm도 학습이 되는 것이죠.
평가를 할 때는 학습 시에 학습을 했던 각 batch마다의 평균을 이용해서 평균을 정의했고
마찬가지로 표준편차도 batch마다 계산되었던 표준편차를 이용해서 평균으로 표준편차를 정의했습니다.
그래서 그 둘을 바탕으로 Batch Norm을 적용을 시켰네요.
High Resolution Classifier
- 448x448 ImageNet 이미지로 추가 학습 ( ~ 10 epoch )
- mAP 4% 상승
Multi-Scale Training
- 매 배치 10회마다 이미지 사이즈를 변경하며 학습
- 320x320 ~ 608x608 ( 32배수 ) 크기 사용
- mAP 대폭 상승
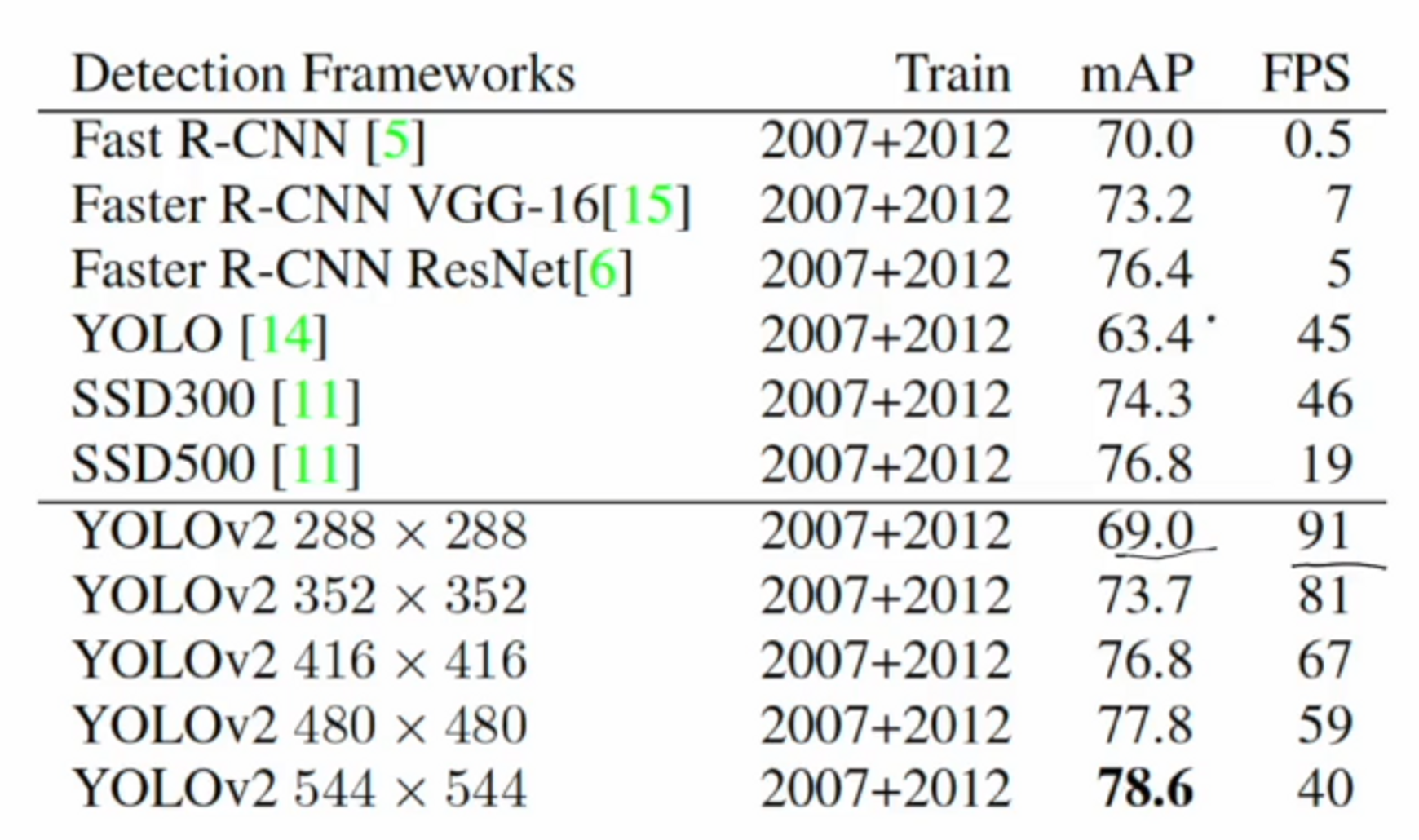
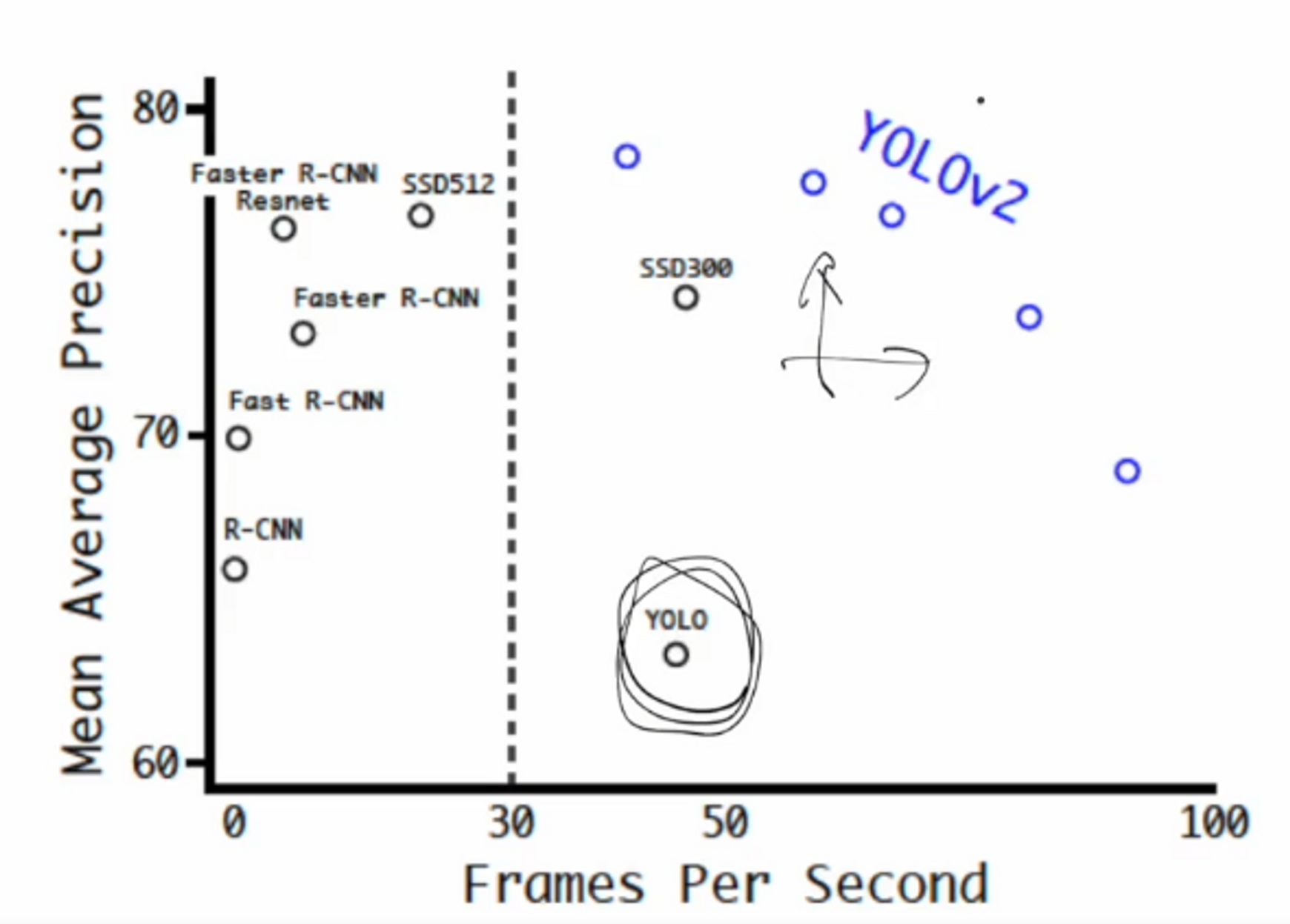
결과를 확인해보면 2-stage 모델인 Faster R-CNN 모델보다는 mAP가 낮지만
YOLO v1 보다는 mAP와 FPS 모두 월등히 높은 것을 확인할 수 있습니다.
입력 이미지 사이즈를 높였더니 2-stage 모델보다 성능이 높아졌네요.
버전2에서 성능이 상당히 높게 개선되었다는 것을 볼 수 있겠네요.
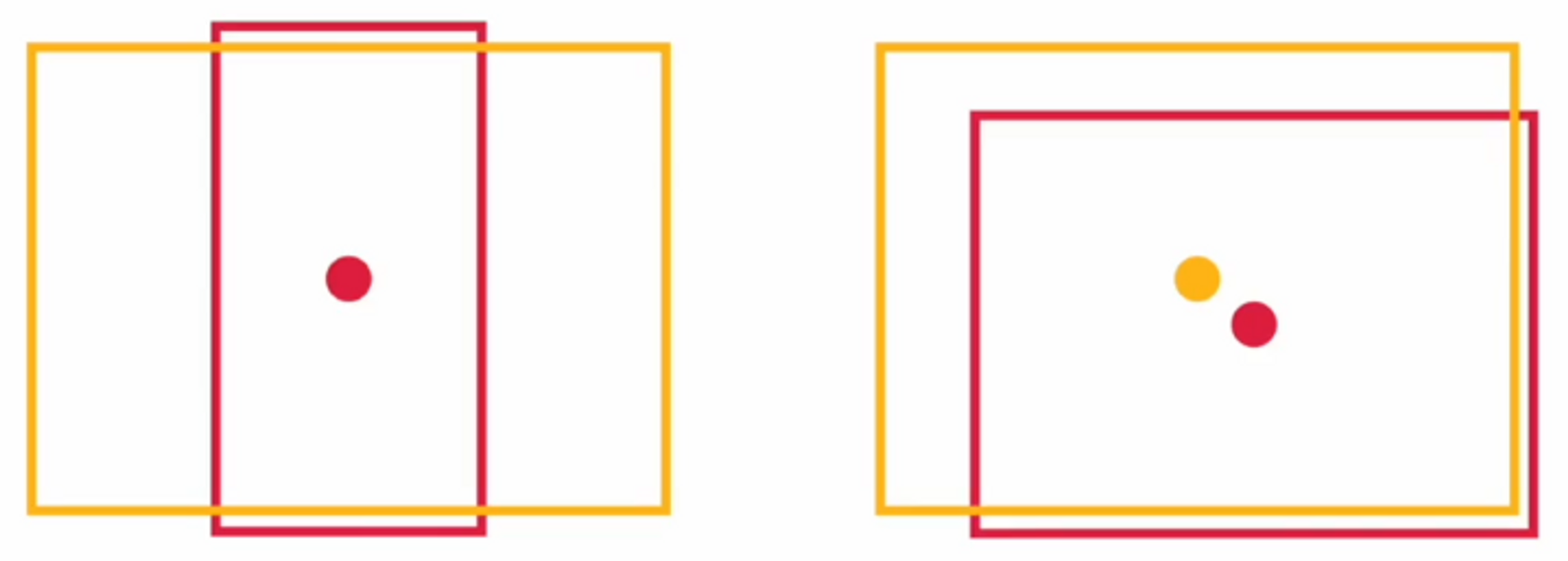
Anchor Box
- 448x448 에서 416x416 이미지를 사용하여 산출 피쳐맵의 크기가 홀수가 되도록 함 ( 13x13 ) 즉, grid cell 개수도 홀수로 설정
- 큰 객체인 경우 이미지 중앙에 오는 경우가 많아서 객체 중심이 cell안에 있도록 할 수 있음
- mAP 0.3% 하락
- recall 7% 향상
Anchor Boxes - Dimension Clusters
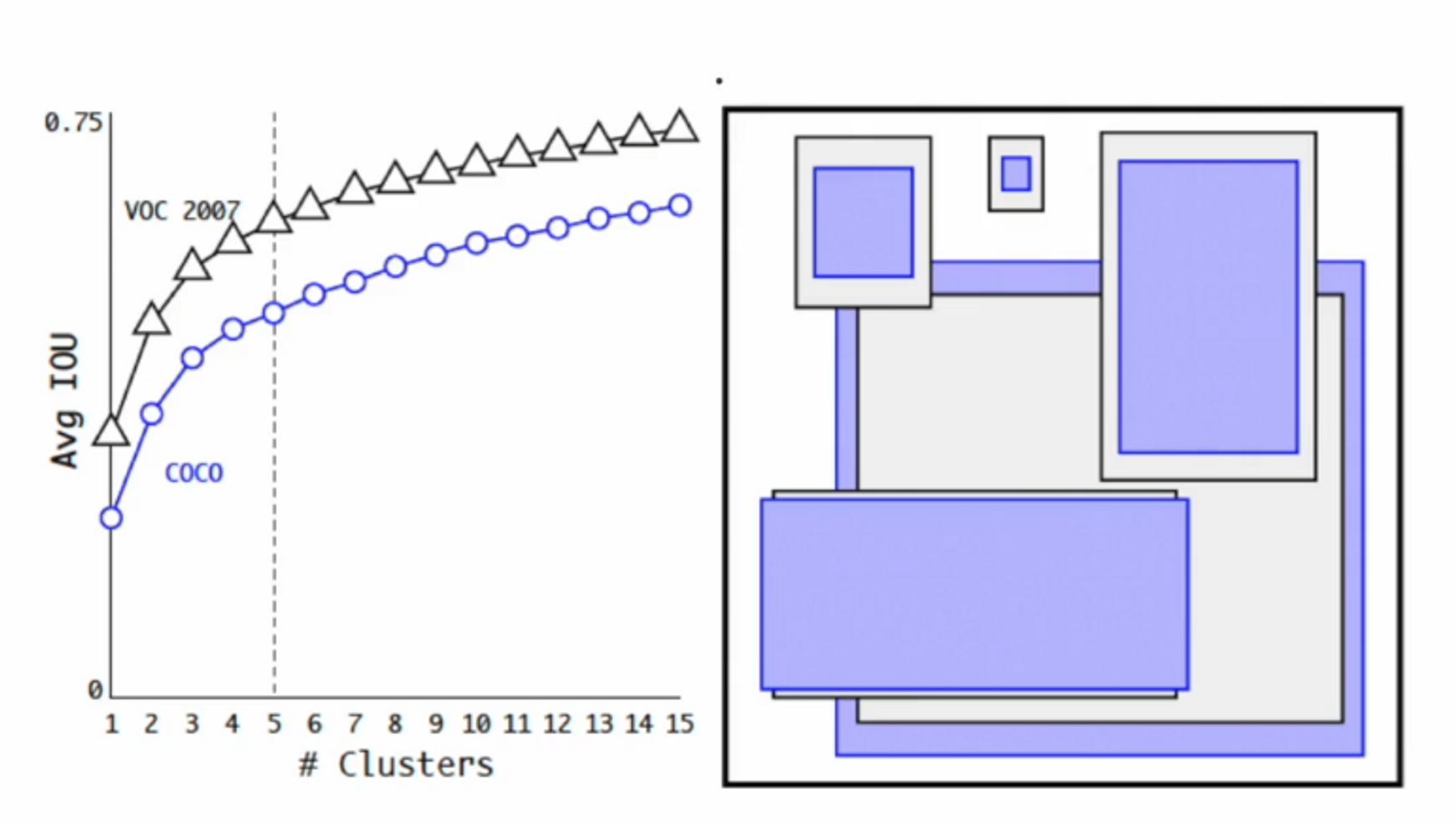
- 학습 데이터셋에 있는 bbox의 정보를 이용하여 k-means clustering 시행
- 거리함수 d(box, centroids) = 1 - IoU(box, centroids)
coco데이터와 VOC 데이터에 대한 결과입니다.
클러스터링의 개수가 많을수록 ( bbox의 개수가 많을수록 ) IoU가 올라가는 모습을 볼 수 있습니다.

시그모이드를 사용하여 예측 !

Fine-Grained Features
- passthrough layer를 이용해 다양한 feature map을 결과에 고려
- 26x26x512와 13x13x2028을 합침
- mAP 1% 향상
결과
YOLOv2 의 모델은 mAP와 FPS 모두 크게 향상 !!
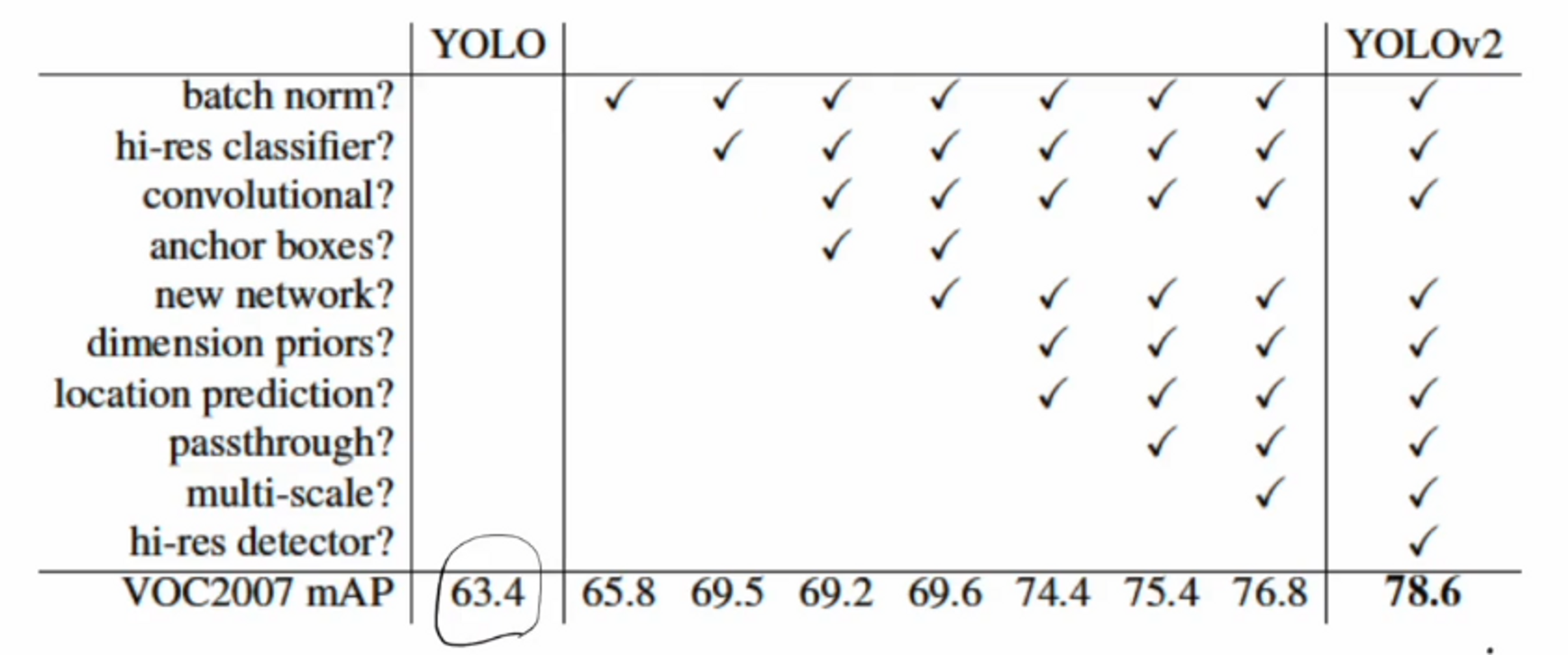
이 부분은 기존에 사용하지 않았던 다양한 기술들을 yolo v2에서 사용했음을 보여주네요.
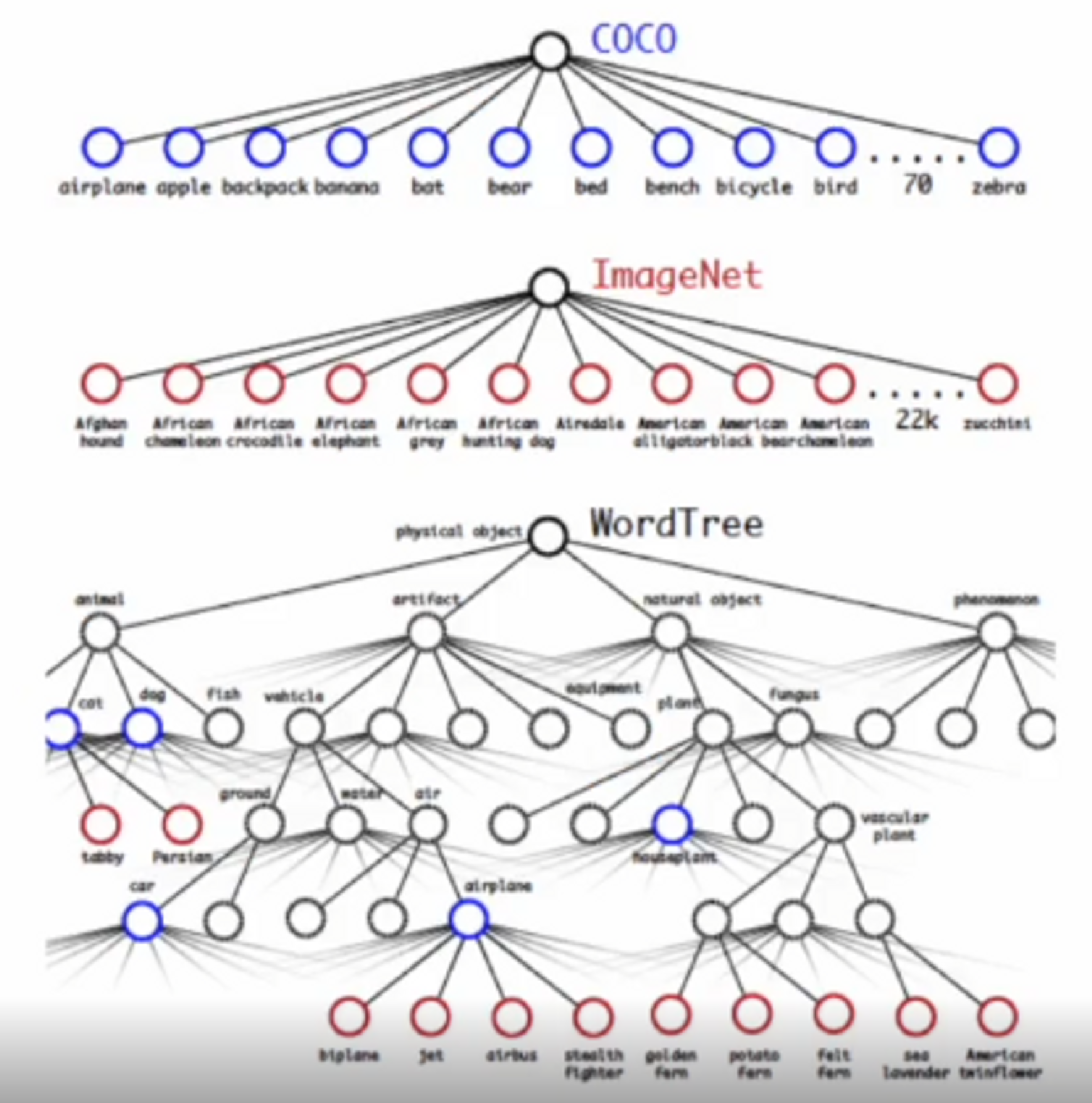
- 계층적 분류 : COCO와 ImageNet 데이터를 합쳐 WordTree 생성
- 이미지의 label 관련!
여기서 yolov2 논문 리뷰를 마치도록 하겠습니다 ! :)
yolov2는 따로 scratch에서 구현해보지 않을 계획이며 v3나 v5에서 따로 구현하는 연습을 할까합니다. 그래도 yolov2는 v1과 굉장히 많은 차이가 있는 모델이므로 꼭 공부해보시면 좋겠네요 !
