https://velog.io/@minyoungxi/YOLO-v1-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
yolov1 리뷰 링크입니당 ㅎㅎ
앵커 박스 ( Anchor Box )
YOLO v1이 가진 Bounding Box의 한계
- 각 cell 당 하나의 클래스만 가질 수 있고 학습 시 하나의 bbox만 사용
→ recall 성능 저하 ( 실제 True 중 예측을 True로 한 비율 )
→ bbox 형상에 제약이 없음
- 해결책
→ 각 bbox마다 클래스 예측 ( 각 cell 당 클래스를 예측하는 것이 아닌, bbox마다 클래스 예측 )
→ 정해진 bbox의 크기의 비율을 조정
앵커는 닻이라는 의미입니다.
닻처럼 고정된 비율을 사용하겠다는 의미입니다.
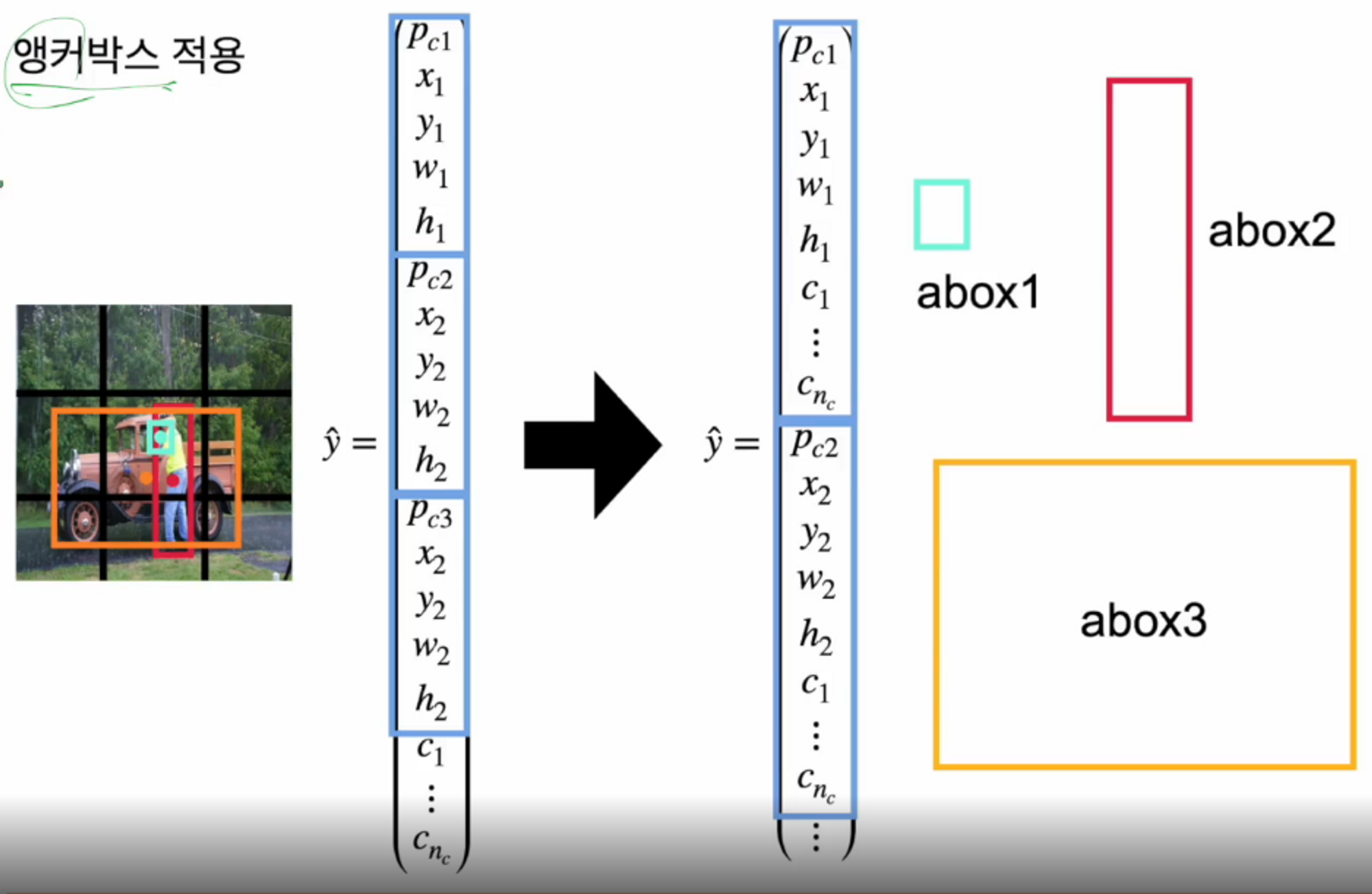
기존의 y 예측값은 confidence score와 각 box의 정보만 들어있고 하나의 클래스가 있었죠?
개선된 bbox는 confidence score와 bbox의 정보, 그리고 클래스 정보까지 담고있습니다.
그래서 각 box마다 클래스의 정보를 갖도록 바뀐거죠.
그러면 그림처럼 벡터의 길이는 늘어나겠죠 ?
그러면 이 앵커박스는 어떻게 적용이 될까요?
- 각 cell의 중심을 기준으로 정해진 미리 정해 둔 box를 배치
- yolo v1에서는 각 cell 당 box를 2개씩 생성했습니다. 여기서는 3개씩 생성합니다.
- 아래 그림은 임의로 박스를 그린 것입니다.
- bbox가 cell을 넘어가도 상관없습니다. 여기서 각 cell마다 bbox를 최적화합니다.

노란색 box는 target 이구요 하얀색 box는 prediction 인데, 노란색 box랑 하얀색 box는 비율이 유사한걸 확인할 수 있습니다.
그래서 하얀색 bbox ( prediction )의 비율을 최적화 과정을 통해 늘려갑니다.
동시에 하얀색 bbox의 중심은 노란색 bbox의 중심으로 이동을 하게 되는거죠.
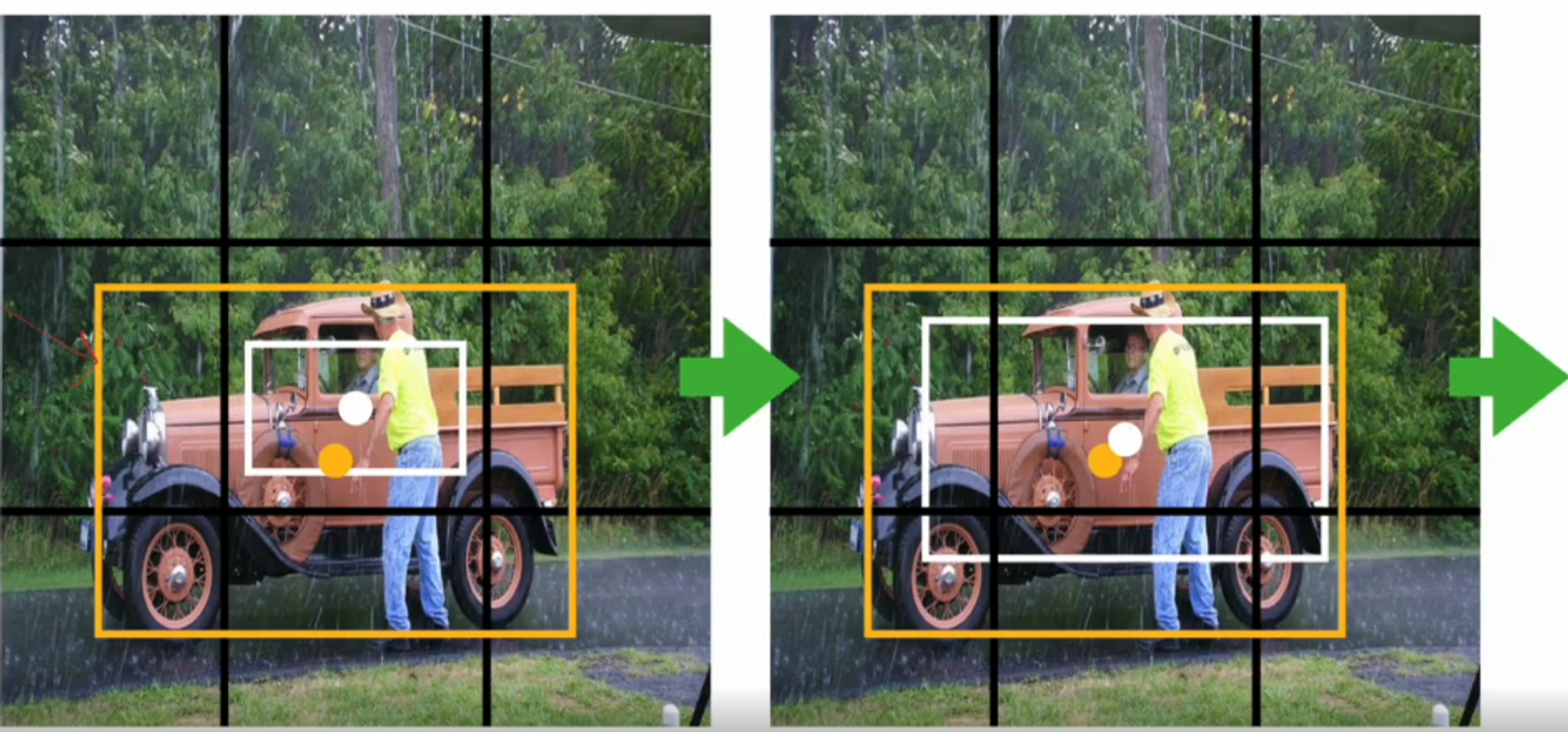
학습을 통해서 abox를 이동, 확대, 축소합니다.
이러한 과정을 통해 prediction box를 target 값에 가깝게 만들 수 있습니다.

YOLO에서 제안한 앵커박스의 크기 설정 방법
앵커 박스를 사용한다는 의미는 초기에 앵커 박스를 어떤 것을 사용할지 생각해야 한다는 것입니다.
흔히 사용할 수 있는 방법은 임의로 설정하는 것입니다.
Anchor Box 개념 자체는 본 논문에서 처음 나온 것은 아니고 원래 있던 개념입니다.
Faster Rcnn에서 이미 사용한 방법인데, YOLO v2에서 그 아이디어를 가져온 것이죠.
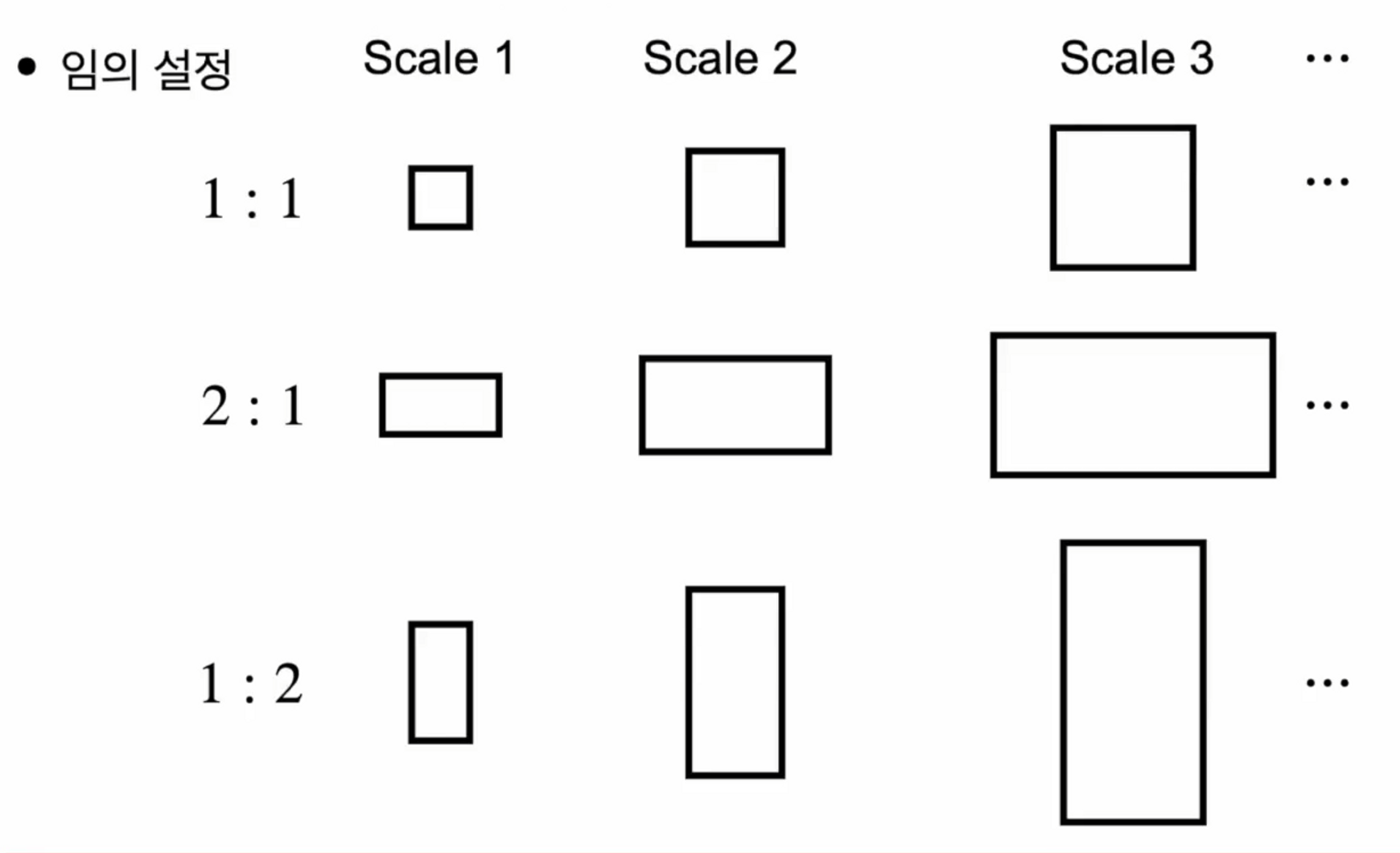
기존에 설정했던 방법은 ‘임의 설정’입니다.
각 cell당 bbox를 9개씩 치는 방법이었어요. ( B = 9 )
정사각형 1개, 옆으로 긴 직사각형 1개, 위아래로 긴 직사각형 1개를 만든 후에
그 사각형들을 좀 더 키우고 더 키우고를 해줘서 작은 물체에서 큰 물체까지 잡을 수 있도록 만들어주는 bbox 9개를 만들어서 사용했습니다.
YOLO에서는 임의로 정하지 않고
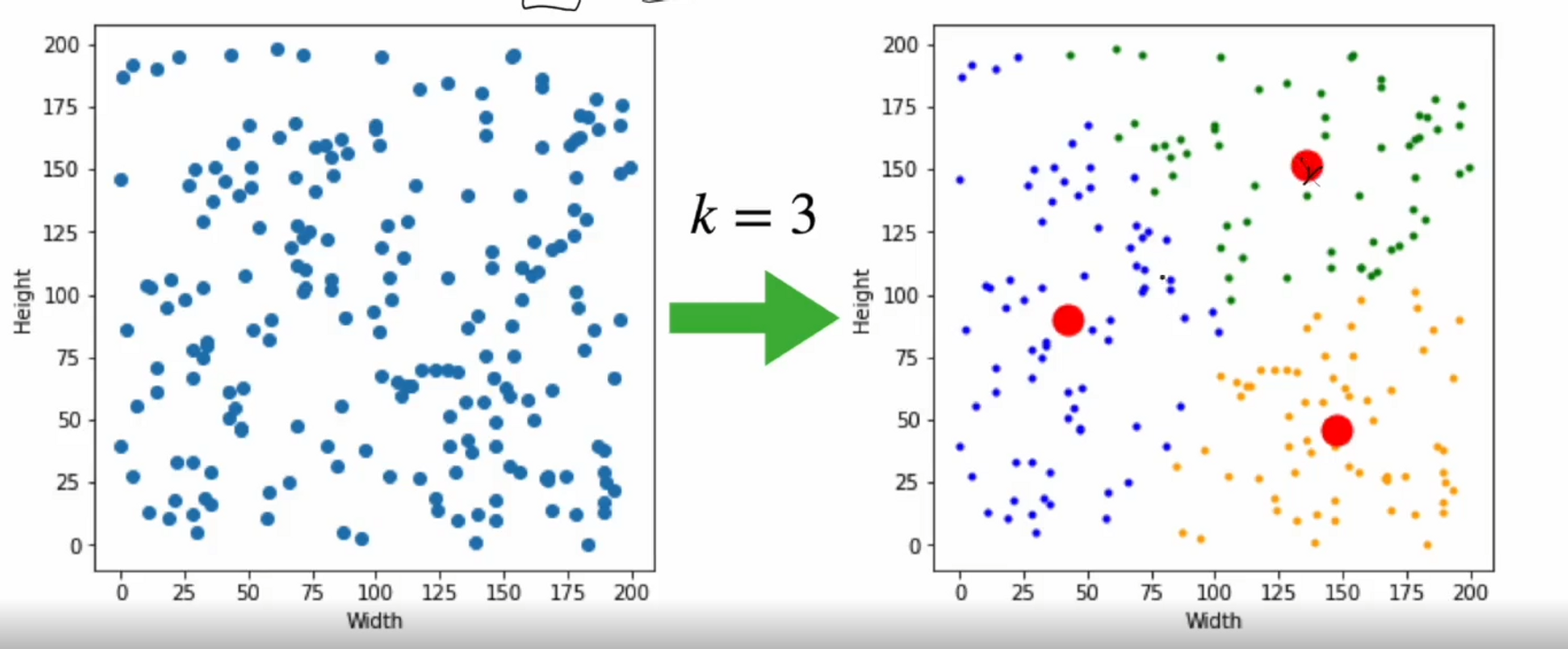
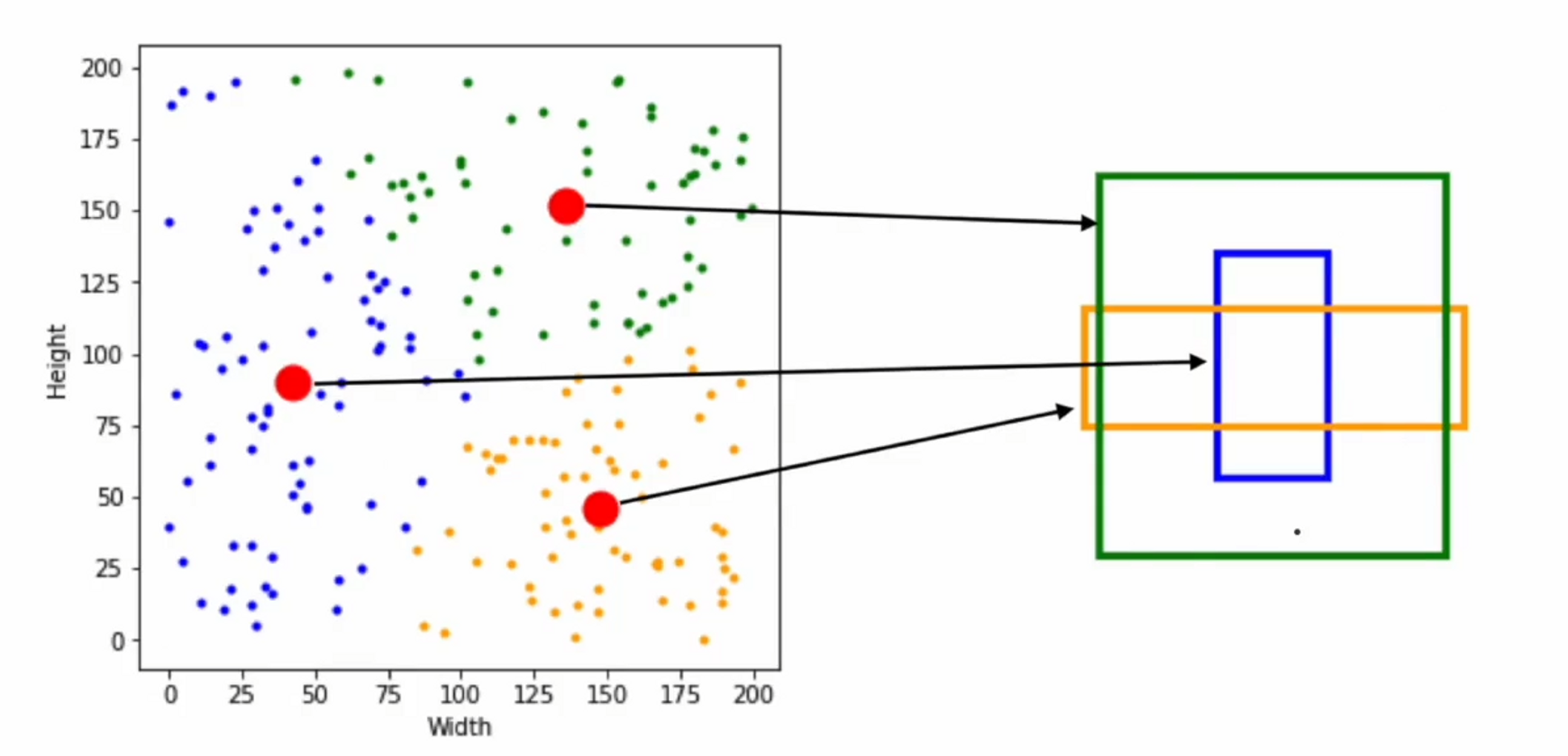
학습 데이터셋에 있는 bbox의 정보를 이용하여 k-means clustering을 시행합니다.
모든 bbox는 좌표 값과 높이 너비 값을 가지고 있는데, 얘네들을 조사해보자는 것이죠.
k-means clustering을 통해서 각 그룹의 평균값을 구합니다.
( x, y, w, h)는 4차원의 값이므로 이해를 돕기위해 h,w 값으로 클러스터링한 결과입니다.
결과를 보면 우리가 생각할 수 있는 대표 Anchor Box는 빨간 점 3개로 결정합니다.
학습 데이터셋에 이미 나와있는 정보를 통해서 Anchor Box를 세팅해보자는 좋은 아이디어입니다.
따라서 다음과 같은 anchor box를 구성할 수 있습니다.
Anchor Box를 5개로 구성하고 싶다면, k값을 5로 설정하여 클러스터링 하여 구할 수 있습니다.
YOLO v2에서 위의 방법을 활용했더니 mAP가 소폭 하락(0.3%)했다고 합니다.
아무래도 형태가 정해져있으니 mAP가 조금 떨어졌는데, recall 성능이 대폭 향상(8%)되었습니다.
YOLO v2 모델의 주요 특징
YOLO v2 논문의 부제는 ‘더 좋고 더 빠르고 더 강하고’입니다.
본 논문은 YOLO v1과 Faster-RCNN 보다 빠르고 정확하다는 것을 보여줬고 , 성능 향상을 위해 다양한 기술 ( 최신 기술 )을 적용했습니다.
또한 논문의 마지막에서 9000개 이상의 객체 카테고리를 인식한다는 것을 보여줍니다.
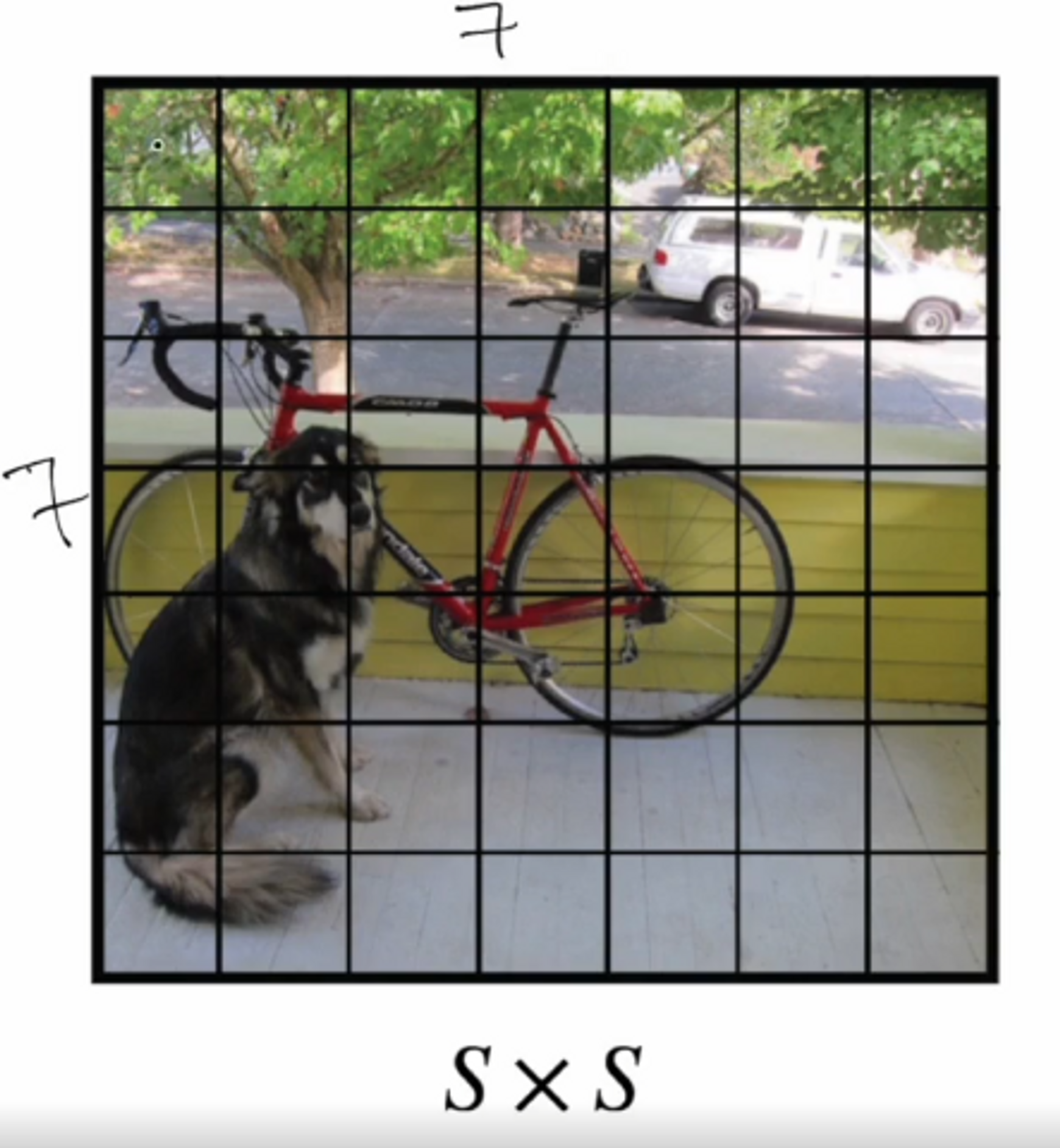
YOLO v1을 살짝 복습해보면
이미지가 들어오면 (448,448)로 resize가 되고, 이 이미지를 각 grid cell로 나눈다고 했죠?
v1에서는 7 x 7 을 사용했습니다. 그리고 각 cell당 bbox를 2개씩 그렸습니다.
따라서 총 98개의 bbox를 만들었습니다.
그런데 v1의 한계가 뭐였죠? 각 cell 당 class를 하나씩 갖는다는 것입니다.
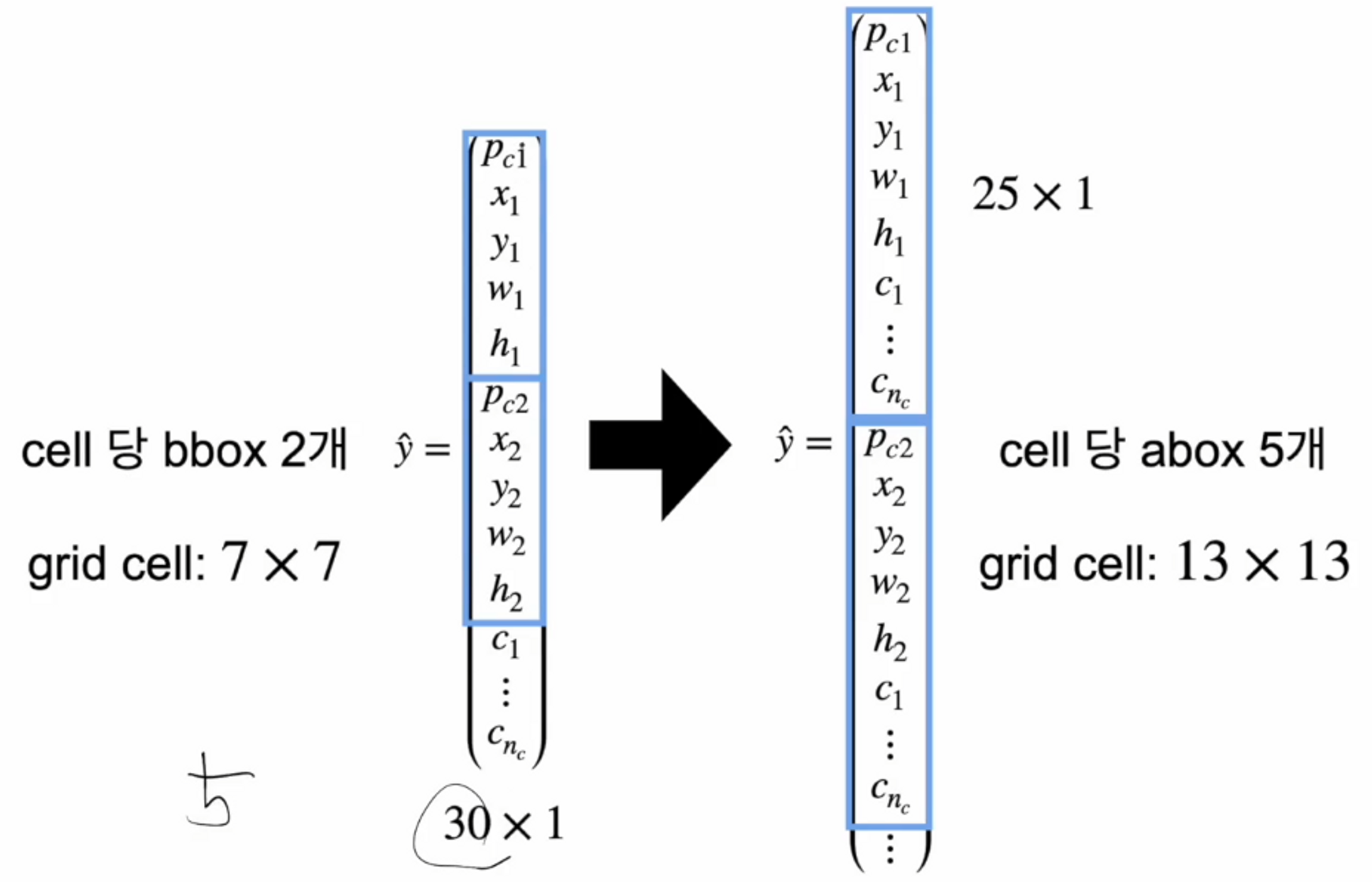
기존의 v1에 대해서 아래의 그림에서 각 cell은 첫 번째 벡터처럼 나와있었고
pascal 데이터를 사용했으니 클래스는 30개이므로 30 x 1 크기를 갖습니다.
박스당 정보는 5개 ( confidence score, x, y , w, h )에 박스는 2개씩 있고, 클래스는 20개이므로
( 5 x 2 + 20 ) = 30 입니다. 그리고 grid cell 은 7 x 7
따라서 7 x 7 x 30 의 tensor를 모델에서 출력하는 것이었죠.
이를 v2에서는 abox를 이용해 계산을 할 것입니다.
abox는 각 box마다 클래스를 가지고 있죠.
25 x 1 이 어떻게 나오는지 알아볼게요.
confidence score : 1
x ,y , w, h : 4
class : 20
⇒ 25 이므로 각 abox 마다 25개의 성분들이 있네요.
만약에 각 cell당 abox를 5개씩 사용한다면, 25 x 5 개가 있는 것이겠죠?
그리고 v2에서는 grid cell을 더 잘게 쪼개서 13x13 을 사용했습니다.
그렇다면 총 출력의 개수는 → 13 x 13 x ( 25 x 5 ) 라는 결과가 나오겠네요.
이를 일반화 한다면 S x S x (( 5 + C ) B)가 되네요 !
다음 포스팅은 yolov2의 모델 개요와 VGG 및 yolov2에서 사용한 구조를 살펴보겠습니다 :)
감사합니당 :)
