CBOW의 아이디어를 활용하여 bidirectional LSTM을 통해 context를 embedding하는 context2vec을 소개하는 논문입니다.
[Abstract]
Context representation은 다양한 NLP task들에서 중요한 역할을 합니다. 해당 논문에서는 bidirectional NLP를 활용하여 큰 말뭉치에서 일반적인 context embedding을 학습하는 model을 소개합니다. 해당 논문에서 소개하는 context representation을 활용하여 기존의 SOTA 성능과 유사하거나 그 이상의 성능을 보일 수 있습니다.
1. Introduction
Generic word embedding은 단어를 저차원의 representation으로 표현하여 의미적, 문법적 정보를 잡아냅니다. 해당 분야의 주된 발전은 큰 말뭉치에서 generic word embedding을 학습할 수 있는 word2vec, glove와 같은 효율적인 model들이 등장하여 크게 발전하였습니다. 말뭉치에서 정보를 잡아내는 것은 unsupervised, semi-supervised NLP task 모두에서 word embedding의 중요성을 높였습니다.
Target word와 주어진 주변의 context 모두를 잘 표현하는 것은 큰 도움이 됩니다.
Target word와 마찬가지로 context 역시 word embedding을 활용하여 표현됩니다. 다양한 task에서 활용되는 context representation은 target word 주변 이웃단어들의 개별 embedding의 집합이거나 (때때로 가중치를 사용하기도 하며) 해당 embedding들의 평균을 활용합니다. 해당 논문에서는 이러한 접근방식은 문맥의 전체적인 의미를 제대로 표현할 수 없다고 생각하였습니다.
최근, bidirectional recurrent neural network 그 중 bidirectional LSTM이 context의 representation을 학습하기 위해 활용되고 있습니다.
Supervised data는 주로 사이즈에 제약이 있기 때문에 이러한 system을 학습할 때 큰 말뭉치에서 미리 학습된 word embedding을 활용하는 것이 성능을 증가시킨다고 밝혀져있습니다. 하지만 pre-trained word embedding은 taget word와 문맥 전체의 관계 정보를 표현하는 데는 한계가 있습니다.
해당 논문에서는 context2vec이라고 불리는 bidirectional LSTM을 활용하여 효율적으로 generic context embedding을 학습하는 모델을 소개합니다. 해당 논문에서는 특히 neural model을 학습하기 위하여 large plain text corpora를 활용하였으며 context와 target word를 동일한 low-dimensional space에 embed 시켰습니다. 이를 통해 target word와 context 사이의 관계를 반영하는 데 최적화할 수 있었습니다.
2. Context2vec's Neural Model
2.1 Model Overview
Context2vec의 주요 목적은 target word 주변의 고정되지 않은 길이의 context를 task-independent embedding 시키는 것입니다. 이런 목적을 수행하기 위하여 해당 논문에서는 word2vec의 CBOW 구조를 바탕으로 하지만 고정된 값의 window에서 word embedding의 단순평균을 통하여 간단한 context를 modeling하는 것이 아닌 bidirectional LSTM을 통하여 좀 더 powerful한 neural model을 사용하였습니다.
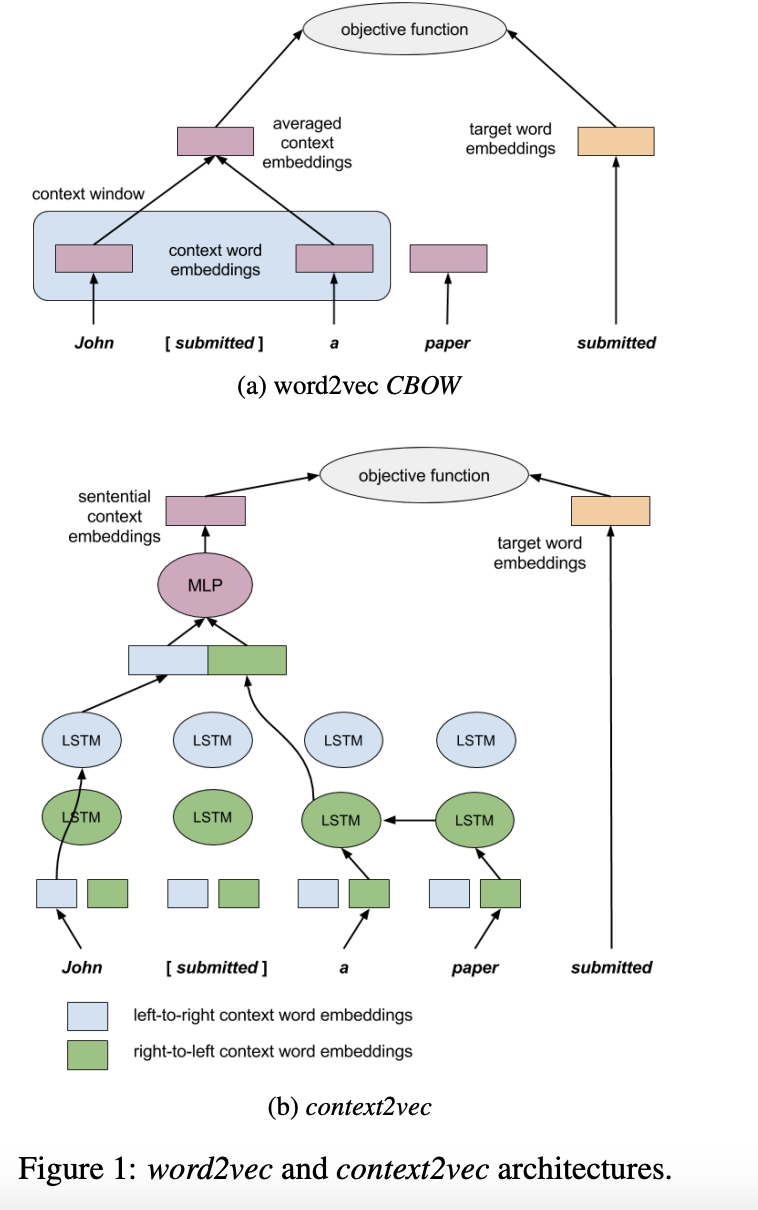
해당 논문에서는 bidirectional LSTM recurrent neural network를 사용하여 하나의 LSTM은 왼쪽에서 오른쪽으로 단어를 입력받고, 나머지 하나는 오른쪽에서 왼쪽으로 단어를 입력받습니다. 2개의 LSTM은 서로 독립적인 parameter를 갖고 있으며 left-to-right, right-to-left 각각 서로 다른 2개의 word embedding 집합을 얻게됩니다. Target word의 context를 표현하기 위하여 해당 논문에서는 LSTM의 left-to-right 결과와 right-to-left 결과를 concat 합니다. 이를 통하여 target word에서 멀리 떨어져 있더라고 context에서 관련있는 정보를 잡아낼 수 있습니다. 그 다음 concat된 vector를 multi-layer perceptron을 활용하여 양 방향의 context 사이의 non-trivial dependency를 잡아내도록 합니다. 이렇게 나온 output을 target word 주변의 context embedding으로 화룡합니다. Word2Vec의 CBOW와의 유일하면서도 가장 중요한 차이는 CBOW는 target word 주변의 고정된 window size의 context를 context 단어들의 단순 평균을 통하여 표현하는 반면 context2vec은 context의 모든 문장을 활용한다는 것입니다.
마지막으로 context2vec의 parameter를 학습하기 위하여 word2vec의 negative sampling objective function을 활용합니다. 이를 통하여 ccontext embedding과 word embedding 모두를 학습할 수 있습니다.
해당 논문의 주된 목표는 context representation 입니다. 해당 논문에서 소개하는 모델은 이러한 목적을 context와 target word에 유사한 embedding을 할당하는 목적을 통해 달성합니다.
2.2 Formal Specification and Analysis
해당 논문에서는 sentece-level context representation을 얻기위하여 bidirectional LSTM recurrent neural network를 활용하였습니다. lLS를 문장의 왼쪽에서 오른쪽으로 읽는 LSTM이라 하고, rLS를 문장의 오른쪽에서 왼쪽으로 읽는 LSTM이라고 합시다.
문장 w_1:n이 주어졌을 때 shallow bidirectional LSTM context representation은 target word w_i에 대해서 아래와 같이 표현할 수 있습니다.
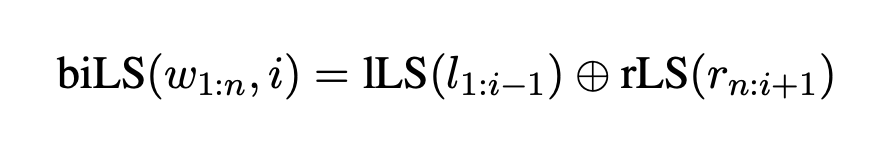
이러한 정의는 standard bidirecional LSTM과는 약간 다르며 이는 해당 논문에서는 target word 자체를 LSTM에서 사용하지 않기 때문입니다. 그 다음 left and right context를 concate한 결과를 non-linear function을 적용하며 아래와 같이 표현할 수 있습니다.

Target word와 context representation의 차원을 동일한 값을 활용합니다. Target word와 context representation을 학습하기 위하여 해당 논문에서는 word2vec의 negative sampling objective function을 활용합니다.

해당 논문에서는 target context embedding을 모든 가능한 target work와 모든 가능한 서로 다른 context 사이의 PMI matrix를 factorizaion했다고 생각할 수 있습니다. 하나의 단어 context 경우와는 달리 가능한 context의 수가 지수적으로 커치지 대문에 PMI matrix를 계산하는 것은 불가능합니다. 하지만 해당 논문에서 최적화한 objective function을 통해서는 이를 근사할 수 있습니다. 해당 논문에서는 target과 context embedding을 내적을 PMI_alpha(c,t)로 근사할 수 있다고 기대합니다. Alpha의 값이 커질수록 rare word에 더 큰 bias를 두어 context와 가까워질 수 있게합니다.
2.3 Model Illustration
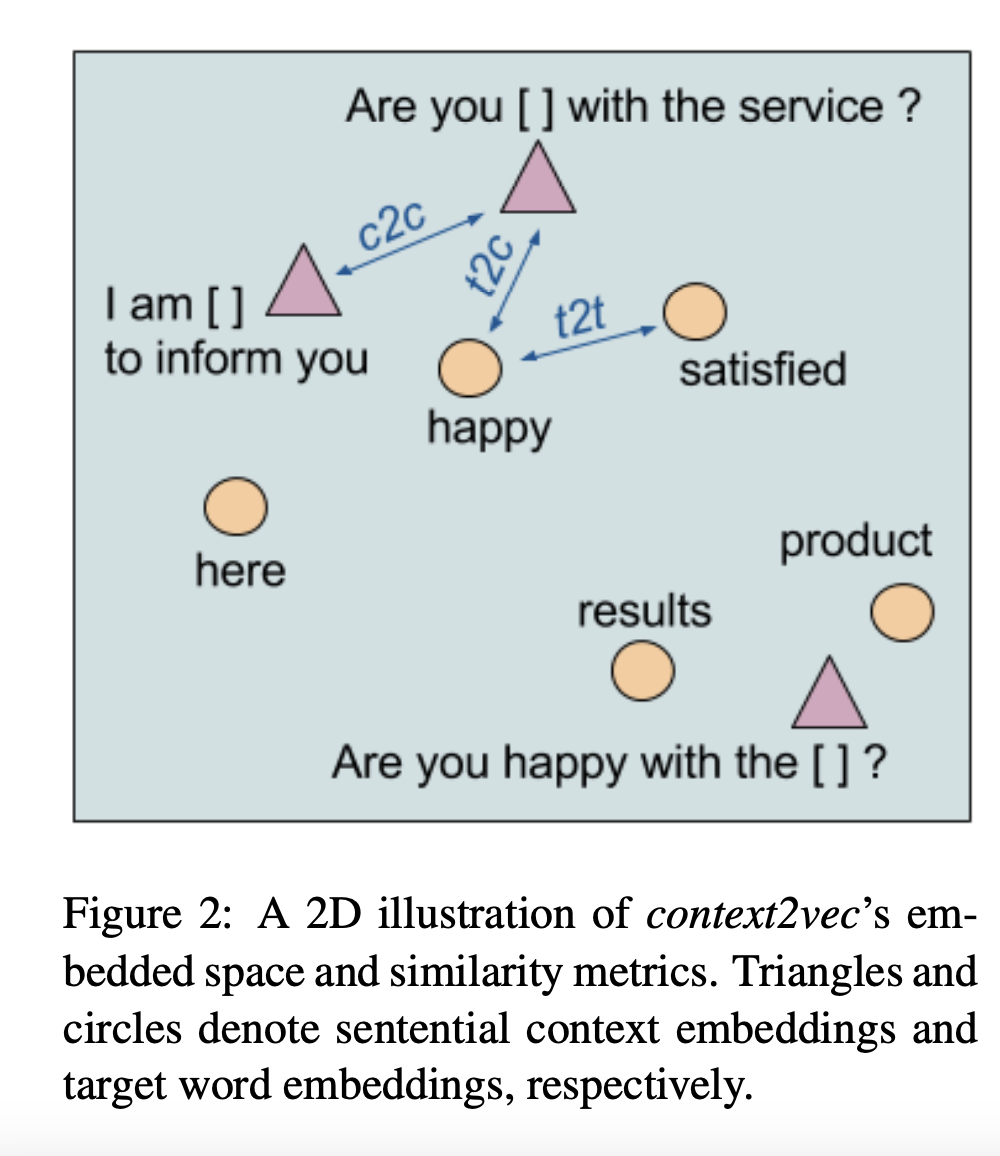
Context2vec의 embedding space의 성능을 비교하기 위하여 3가지 유사 지표를 활용합니다. Target-to-context (t2c) / context-to-context(c2c) / target-to-target(t2t)
위 3가지 모두 각 embedding 결과들의 cosine 값을 활용하여 계산됩니다.
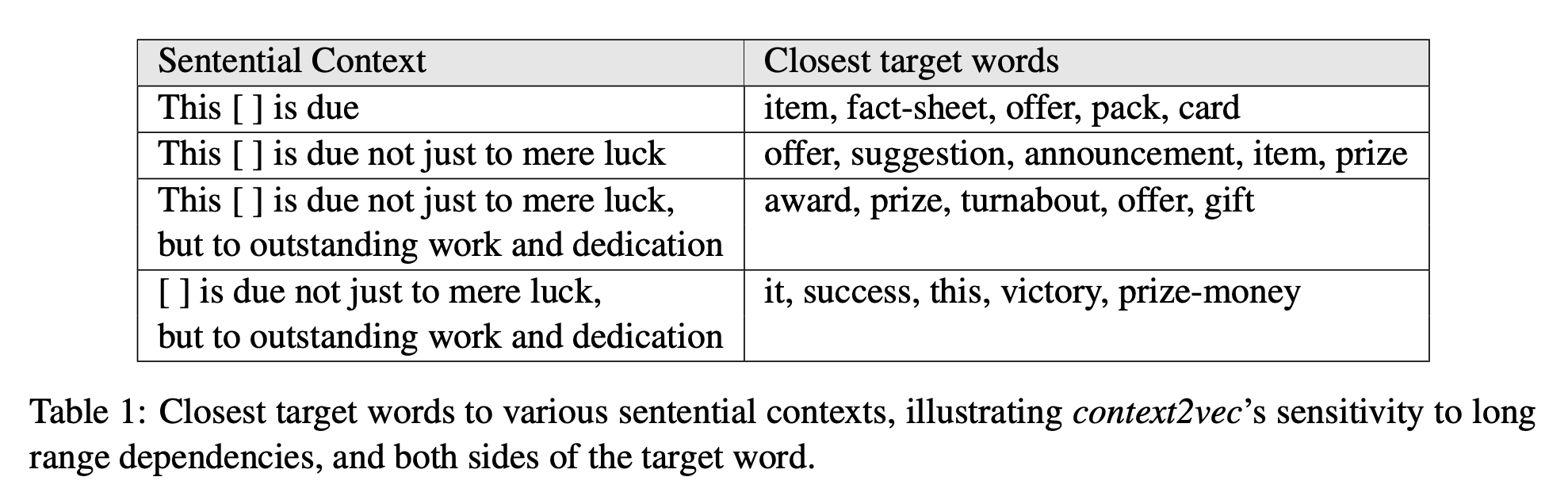
위 table1 에서는 context와 target word가 얼마아 유사한 지 context2vec embedding을 활용하여 target-to-context 유사 지표를 활용한 결과를 보여줍니다. Context2vec의 bidirectional LSTM이 실제로 long range dependency를 잘 잡아낸다는 것을 알 수 있습니다.

위 table2 에서는 서로 다른 negative sampling smoothing parameter alpha를 활용한 각각의 context2vec model에서 context가 주어졌을 때 가까운 target word를 구한 결과입니다. Alpha 값이 커질 수록 rare word가 뽑히는 것을 확인할 수 있습니다.

위 table3 에서는 context2vec과 AWE를 기반으로 하나의 query context가 주어졌을 때 2개의 유사한 문장을 뽑은 결과입니다. Context는 target word의 의미를 도출하기 때문에 좋은 context 유사도는 동일한 target word에 대해서 유사한 의미를 만들어 낼 수 있는 context를 뽑아낼 수 있습니다.
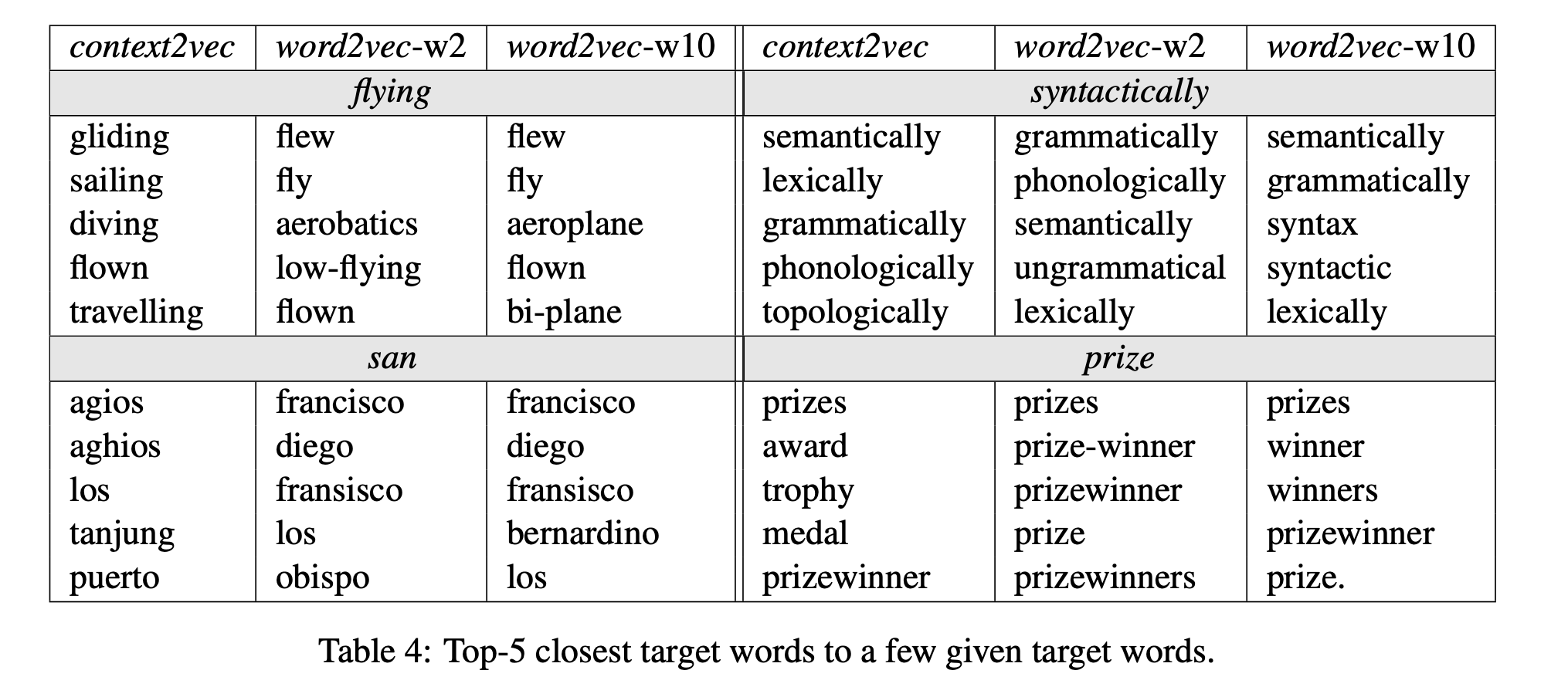
마지막으로 table4 에서는 몇몇의 target word에 대해서 target-to-target 유사도 지표를 통해서 얻은 유사한 단어 결과입니다.
해당 논문의 model은 context word의 순서와 위치를 통하여 전체적인 context를 고려합니다.
2.4 Relation to Language Models
해당 논문의 모델은 language model과 유사성이 있습니다. 특히 모두 context를 기반으로하여 target word를 예측한다는 objective로 LSTM neural network를 학습하고 negative sampling 기법을 사용하여 large vocabulary 계산 복잡도를 다루기 때문에 LSTM 기반의 language model과 유사성이 있습니다. LSTM langugae model과의 주된 차이점은 LSTM langugae model은 이전 단어들이 주어졌을 때 target word의 조건부 확률을 예측하는 것을 최적화하는 데 주된 관심을 두고 있는 반면 해당 논문의 모델은 앞 선 단어와 뒤 단어 모두를 활용하여 일반적인 representation을 얻는 것을 목적으로 합니다.
3. Evaluation Settings
Context2vec의 context embedding runction을 다양한 task-specific system에 활용하였습니다.
3.1 Learning corpus
- 2B word ukWac
- 64 단어 이상의 문장 제외
- lower-cased all text
- 100번 이하 등장한 단어는 unknown word
- 최종적으로 180K word
3.2 Compared Methods
Context2vec
AWE
(1) Ignoring stopword
(2) TF-IDF 가중치를 활용하여 context 단어들을 weighted average
(3) Target word를 중심으로 5-word window 활용
3.3 Sentence Completion Challenge
3.4 Lexical Substitution Task
3.5 Supervised WSD
4. Results
4.1 Development Experiments
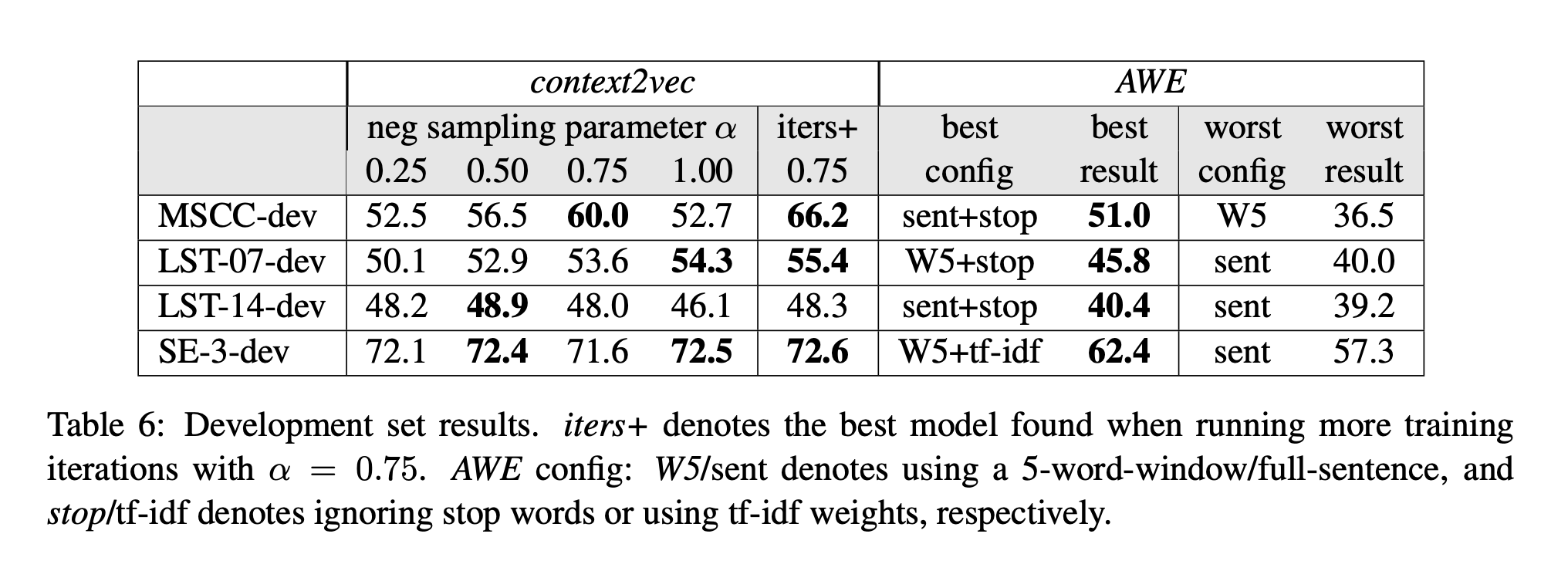
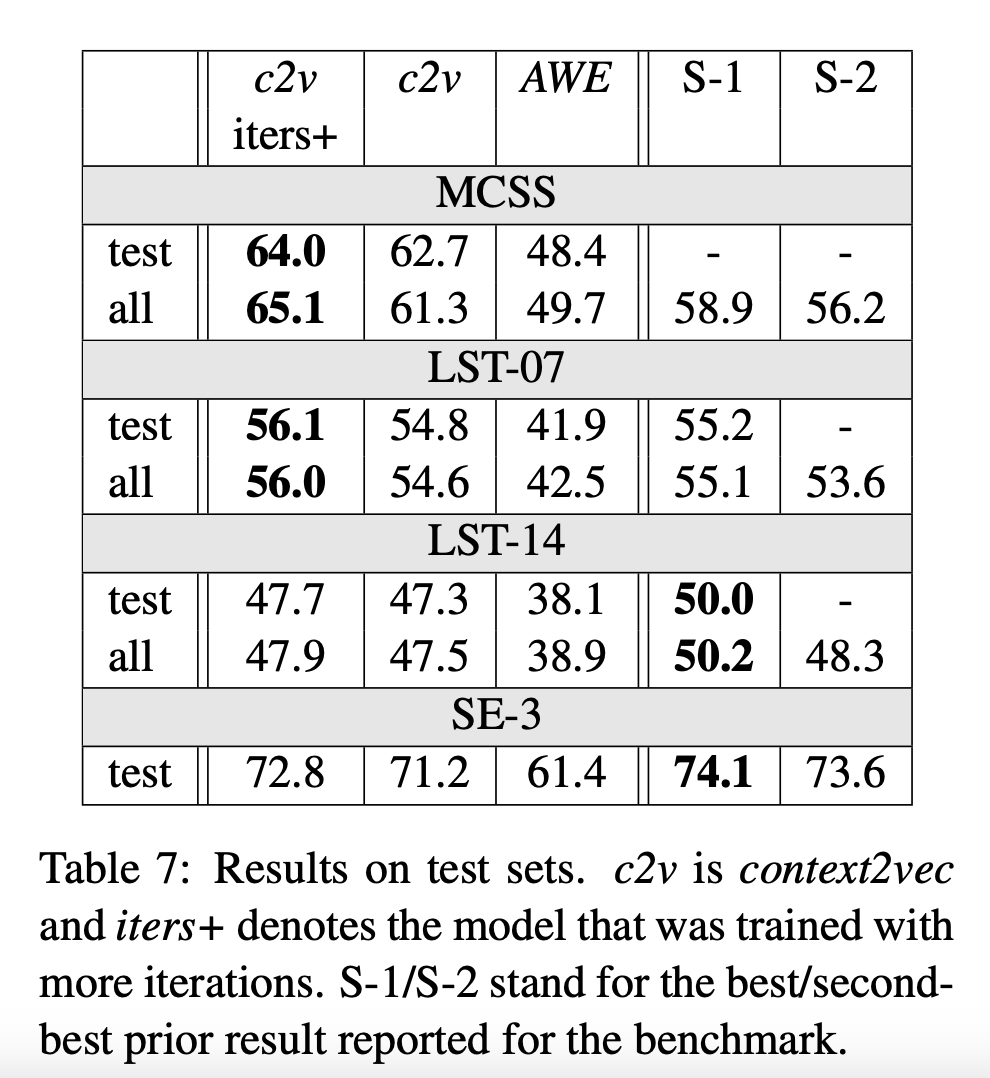
4.2 Test Sets Results
5. Related Work
6. Conclusions and Future Potential
해당 논문에서는 고정되지 않은 길이의 context의 generic embedding을 학습하는 neural model인 context2vec을 소개하였습니다.
Context2vec은 다양한 NLP systemp에 사용할 수 있습니다. 특히 semi-supervised model은 context2vec을 활용하면 개별 pre-trained word embedding보다 large corpora에서 유용한 정보를 활용할 수 있기 때문에 많은 이점을 얻을 수 있습니다.
