Input 문서만으로 document embedding을 활용하여 informativeness와 diversity 특성을 지닌 keyphrase를 unsupuervised하게 뽑아주는 EmbedRank, EmbedRank++를 소개하는 논문입니다.
[Abstract]
Keyphrase extraction은 주어진 문서를 가장 잘 표현할 수 있는 phrase를 자동으로 선택해주는 task입니다. Supervised keyphrase extraction은 labeling이 된 매우 큰 학습 data가 필요하고, 학습 data domain 밖의 영역으로는 일반화가 잘 되지 않습니다. Unsupervised keyphrase은 정확도는 좋지않고 input으로 매우 큰 말뭉치가 필요하기 때문에 때때로 일반화가 잘 되지 않을 수도 있습니다. 이러한 단점을 해결하기 위해 해당 논문에서는 sentence embedding을 활용하는 unsupervised 방식은 EmbedRank를 단일 문서에 적용하여 keyphrase extraction을 수행하고자 했습니다. EmbedRank와 함께 해당 논문에서는 선택되는 keyphrase의 범위와 다양성을 늘리기 위하여 embedding-based maximal marginal relevance(MMR)을 소개합니다.
1. Introduction
문서의 keyword와 keyphrase는 큰 text collection에서 빠르고 정확한 검색을 가능하게 해주고 문서 요약에서 중요한 역할을 합니다. 다양한 분야에서 활용되고 실시간 서비스에서 자주 사용되기 때문에 extraction은 빠르게 가능해야 하며 keyphrase는 disjoint해야 합니다.
Supervised keyphrase extraction은 학습을 위해 문서와 선택된 keyword 사이에 라벨링이 되어 있는 매우 큰 dataset을 필요합니다. Supervised 방식은 또한 학습 data 이외의 domain에 대해서는 좋지 못한 성능을 보입니다. 이는 새로운 문서의 domain을 알 수 없기 때문에 심각한 문제가 될 수 있습니다. Unsupervised keyphrase extraction에서는 이러한 정보가 제한적인 상황을 2가지 방식으로 해결합니다. 첫째, 말뭉치와 현재 문서의 통계 정보를 활용합니다. 둘째 현재 문서에서 뽑은 정보들만 사용합니다.
해당 논문에서는 문서에서 keyphrase를 뽑아주는 unsupervised 방식인 EmbedRank를 소개합니다. 해당 방식은 단순하며 전체 말뭉치가 아닌 현재 문서만을 필요로 합니다. 해당 방식은 임의의 길이 문서나 word sequence가 동일한 contiunuous vector space에 embedding될 수 있다는 text representation learning에 의존하고 있습니다.
Semantic text representation을 통해 informativeness와 diversity 2가지 keyphrase의 특성을 보장할 수 있습니다.
다른 연구에서는 사용자들이 다양한 keyphrase를 선호한다는 것을 보였습니다.
2. Related Work
2.1 Unsupervised Keyphrase Extraction
Unsupervised keyphrase extraction은 corpus-dependent, corpus-independent 2가지 방식이 있습니다.
Coupus-independent 방식은 해당 논문에서 제안하는 방식을 포함하며 keyphrase를 뽑을 문서를 제외하고는 어떠한 input도 필요로 하지 않습니다. 현재 존재하는 대부분의 방식은 graph-based이며 KeyCluster, TopinRank 등이 있습니다. Graph-based keyphrase extraction에서 가장 먼저 소개할 TextRank는 target document는 graph가 되고 word는 node가 되며 edge는 주어진 window 내에서 주어진 node들의 co-occurrence를 나타냅니다. SingleRank처럼 edge는 co-occurrence를 가중치로 사용하여 가중될 수 있습니다. 단어는 node ranking metric을 활용하여 점수가 매겨지게됩니다. 개별 단어들의 score는 multi-word phrase score로 합쳐지게 됩니다. 최종적으로 특정 tag를 나타내는 sequences of consecutive word는 phrase의 후보가 되고 그들의 score에 따라서 순위가 매겨집니다.
2.1.1 Diversifying results
Information retrieval에서 사용자들에게 다양성을 보장해주는 것은 매우 중요합니다. 해당 논문에서는 MMR을 사용하였는데 사용과 해석 측면에서 단순하기 때문입니다.
소개할 방법들은 keyphrase를 뽑을 때 diversity factor를 통합한 것들입니다. KeyCluster는 clustering-based 접근법을 소개하였습니다. TopicRank는 graph와 clustering-based 접근법을 혼합하였습니다.
대조적으로 EmbedRank는 문서와 phrase 후보를 모두 semantic document embedding 방법을 통해 high-dimensional space에 표현하였습니다.
2.2 Word and Sentence Embeddings
Word2Vec은 단어를 continuous vector space에서 vector로 표현하여 놀라운 발전을 보였습니다. 단어를 moderate dimenstion으로 표현하여 기존의 단어의 의미적 관계를 잘 표현하지 못하며 높은 차원을 활용해야만 한다는 bag-of-word의 단점을 해결하였습니다. Skip-Thought는 근접한 문장을 예측하는 것을 학습하여 sentence embedding을 제공하였습니다. Paragraph Vector는 paragraph의 순서없는 list를 사용하여 paragraph embedding을 얻었습니다.
Sent2Vec은 sentence embedding을 만들기 위해 word n-gram feature를 활용하였습니다. 해당 방식은 word와 n-gram vector를 만들어 sentence vector로 합쳐질 수 있도록 학습되었습니다. Sent2Vec은 Paragraph Vector나 Skip-Thought보다 속도가 빨랐습니다. Sent2Vec은 phrase간의 의미적 관계를 반영할 수도 있습니다.
3. EmbedRank: From Embedding to Keyphrases
해당 논문에서는 EmbedRank를 활용합니다. EmbedRank는 3개의 Step으로 이루어져 있습니다.
(1) text에서 part-of-speech를 바탕으로 phrase 후보를 뽑습니다. 좀 더 자세히는 1개 이상의 명사 앞에 존재하는 형용사가 존재할 수 있는 phrase를 놔둡니다.
(2) Sentence embedding을 활용하여 후보 phrase와 문서 자체를 동일한 고차원의 vector space에 표현합니다.(embed)
(3) 그 후 후보 phrase에서 keyphrase를 뽑아내기위해 rank를 매깁니다.(rank) 이 뿐만아니라 ranking step을 발전시키기 위해 추출된 keyphrase에 다양성을 표현할 수 있는 요소를 추가하기도 합니다.
3.1 Embedding the Phrases and the Document
SOTA text embedding은 vector들간의 거리를 통하여 의미적 연관도를 잡아냅니다.
문서와 후보 phrase들 사이의 의미적 연관도는 phrase가 가지고 있는 informativeness의 대안으로 사용할 수 있습니다.
Keyphrase extraction은 2가지 step을 따릅니다.
(1) Document embedding을 계산합니다. 이 때 오직 형용사와 명사만 남겨둠으로서 noise reduction 절차를 포함합니다.
(2) 각 phrase 후보들의 embedding을 계산합니다.
Doc2Vec과 Sent2Vec 2가지 방법은 정해지지 않은 길이의 word sequence를 embedding할 수 있습니다.
Sent2Vec은 pre-trained model에서 text 요소들의 미리 계산된 representation을 평균하여 document embedding을 얻기 때문에EmbedRank s2v은 매우 빠릅니다. EmbedRank d2v은 Doc2Vec이 전체 문서 vector를 계산하기 때문에 속도가 느립니다.
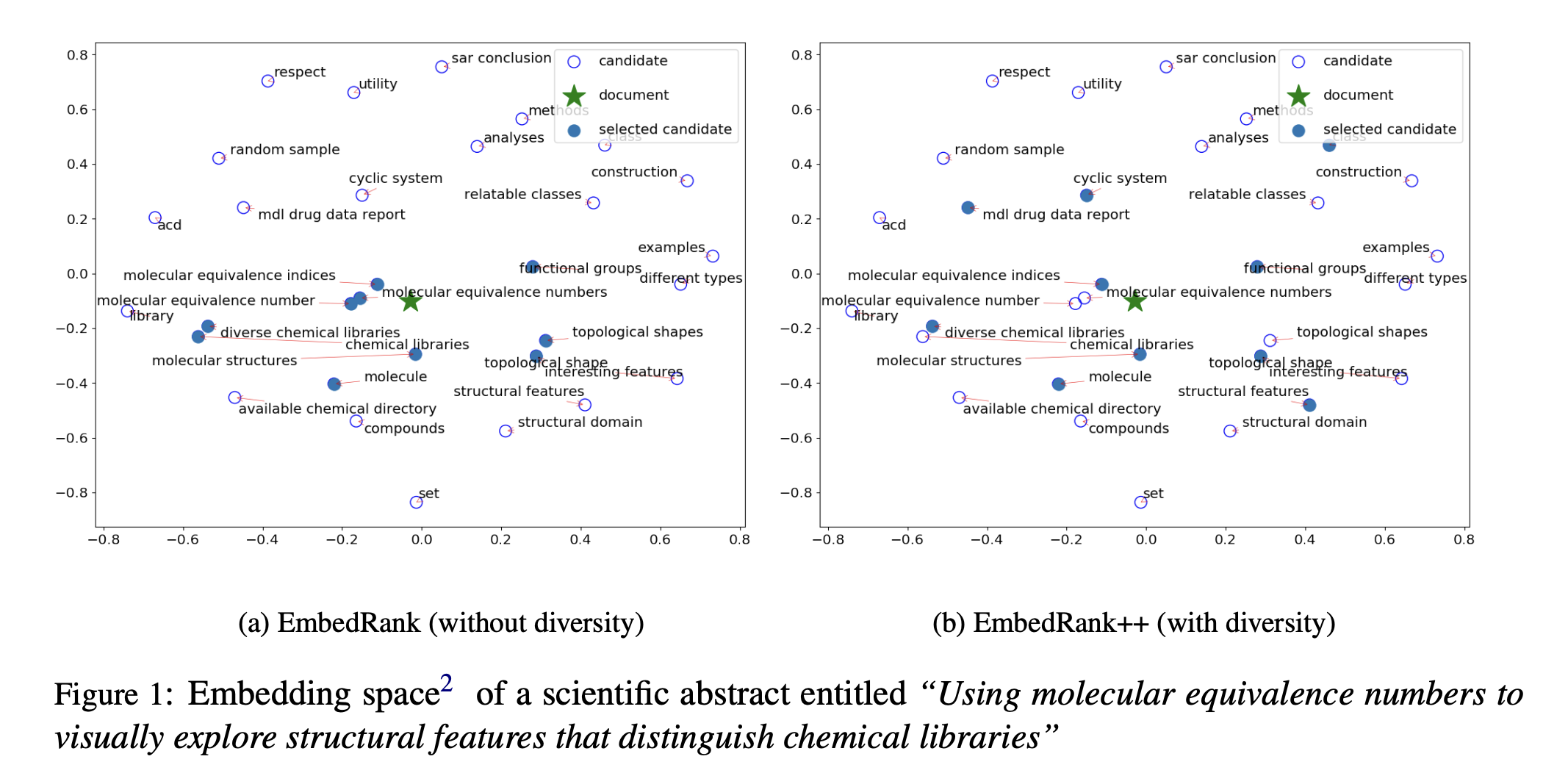
Phrase가 document vector와 가까워질 수록 phrase가 document의 더 많은 informative가 있다고 볼 수 있습니다.
3.2 Selecting the Top Candidates
위 결과를 바탕으로 document embedding과 candidate phrase의 cosine distance를 계산하여 순위를 매긴 후 initial set의 top keyphrase를 선택합니다.
그럼에도 불구하고 top keyphrase간의 중복된 정보가 존재한다는 것을 볼 수 있습니다. 이러한 문제는 phrase embedding을 활용하여 의미적 유사도를 cosine similarity로 활용하여 해결할 수 있습니다.
해당 section에서는 informative keyphrase를 unsupervised step-by-step 방법을 통해 얻는 것을 소개하였습니다.
4. EmbedRank++: Increasing Keyphrase Diversity with MMR
Document embedding과 가장 가까운 N개의 candidate phrase를 뽑아냄으로써 EmbedRank는 단순히 phrase informativeness 특성만을 반영하기 때문에 keyphrase간의 중복이 존재할 수 있습니다. 사용자의 입장에서 keyphrase가 중복이 될 때 사용자 경험에 부정적인 영향을 받을 수 있습니다.
고정된 개수의 keyphrase를 뽑게된다면 중복되는 내용은 뽑힌 keyphrase들의 다양성을 낮추게 됩니다.
검색 엔진에서는 queyr-document relevance와 문서의 다양성의 균형을 맞추는 것을 중요시합니다. 이를 위한 효과적인 방법 중 하나가 MMR(Maximal Marginal Relevance)입니다. MMR은 relevance와 diversity를 조절하여 혼합할 수 있습니다. 해당 논문에서는 MMR이 keyphrase 추출에 어떻게 적용하여 keyphrase와 informativeness와 뽑힌 keyphrase 간의 독립성을 보장할 수 있는지 보여줍니다.
Origianl MMR은 최초로 뽑힌 문서 R과 input query Q, Q에 대한 좋은 결과로 뽑힌 문서들을 표현하는 집합 S를 사용합니다. S는 MMR을 계산하면서 반복적으로 추가됩니다.


5. Experiments and results
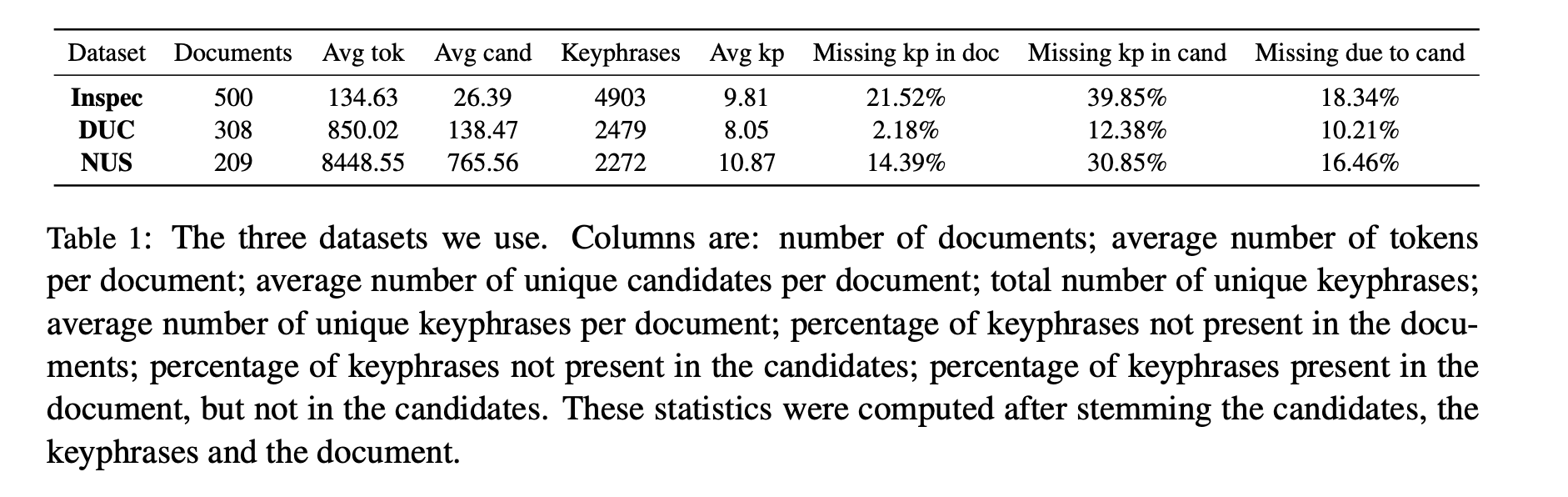
5.1 Datasets
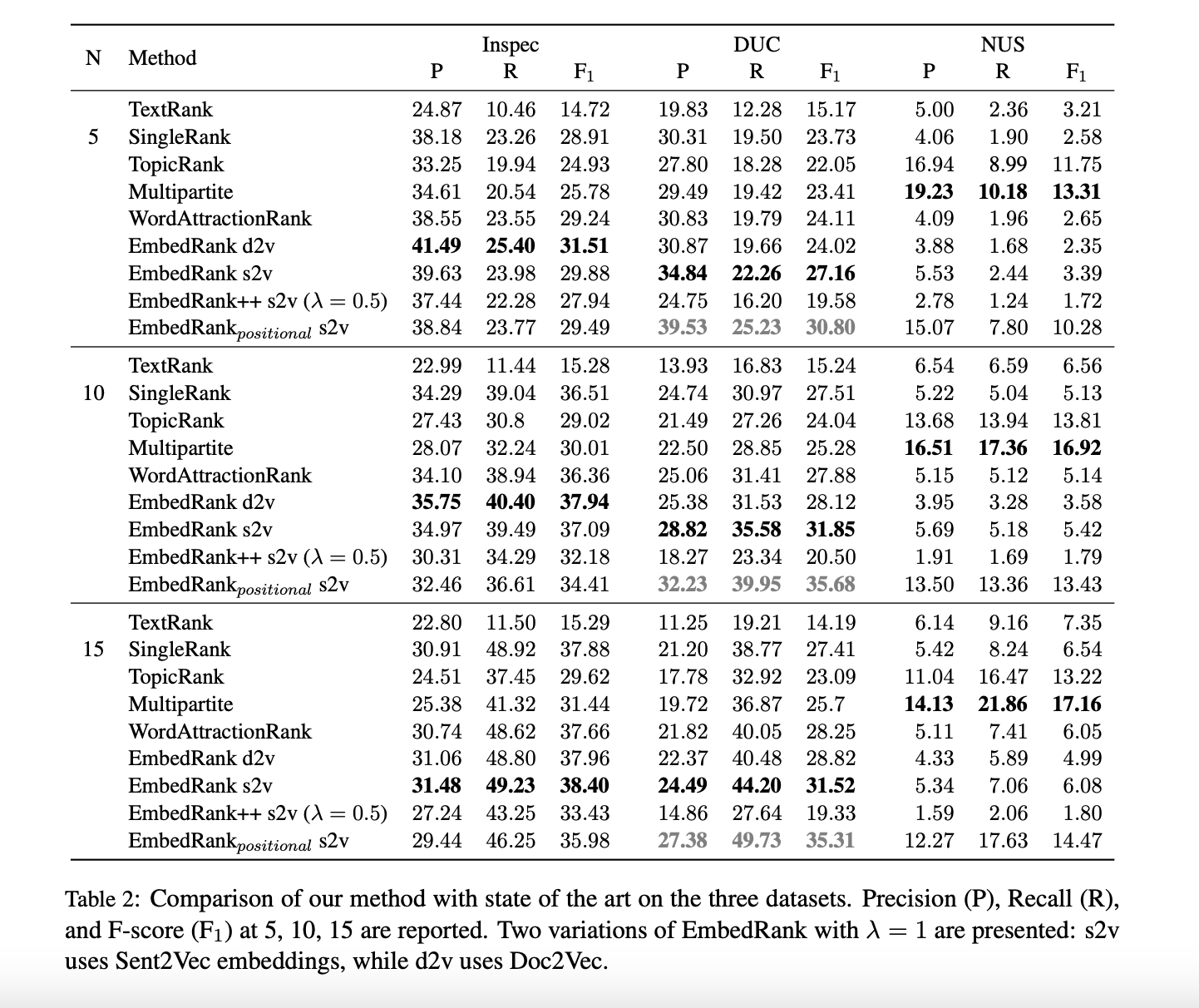
5.2 Performance Comparison
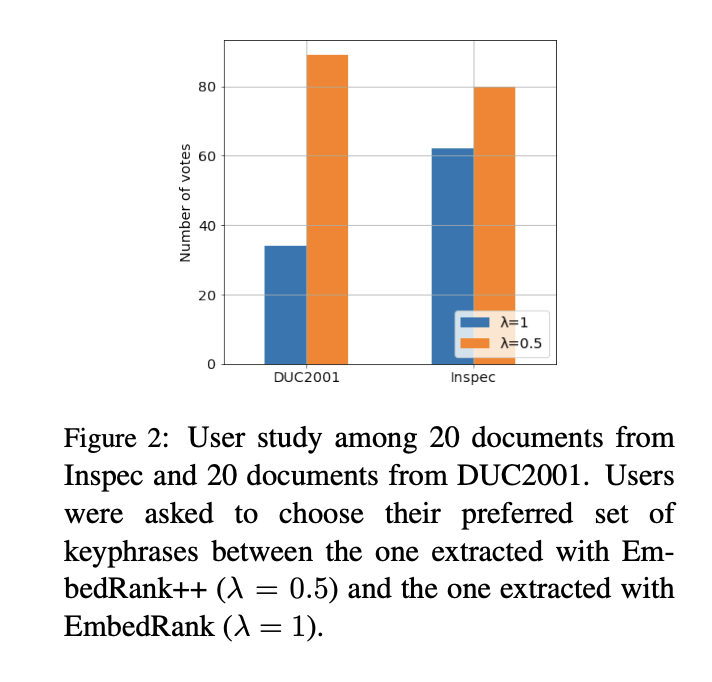
5.3 Keyphrase Diversity and Human Preference
6. Discussion

EmbedRank keyphrase extraction은 빠르고 실시간 계산과 시각화가 가능합니다.
7. Conclusion
해당 논문에서는 하나의 문서에서 sentence embedding을 활용하여 keyphrase를 뽑아내는 2개의 단순하면서도 확장가능한 방식은 EmbedRank, EmbedRank++를 고새합니다. 2개의 방법 모두 unsupervised, corpus-independent하고 current document만을 input으로 활용합니다. 두 방법 모두 input text의 graph representation을 기반으로하는 전통적인 keyphrase extracion과는 다르며 informativeness와 diversity를 반영할 수 있습니다.
EmbedRank는 모든 길이의 문서를 embedding할 수 있다면 어떠한 document embedding을 활용하여 적용할 수 있습니다.
