Attention을 소개하는 하는 논문입니다. 해당 논문에서는 annotation이라는 표현을 사용하지만 추후 attention으로 불리며 transformer 구조의 뼈대로 활용됩니다.
[Abstract]
Neural machine translation은 번역의 성능을 높이는 single neural network를 구성하는 것을 목적으로 합니다. 최근에 일반적으로 사용되는 구조는 encoder-decoder 구조로 source setence를 고정된 길이의 vector로 encode한 후 decoder를 통해서 해당 vector를 번역 결과로 만들어냅니다. 해당 논문에서는 고정된 길이의 vector를 사용하는 것이 기본적인 encoder-decoder 구조의 번역 성능의 bottleneck으로 의심하였으며 model이 자동으로 source sentence에서 target word를 예측할 때 가장 관련이 있는 부분을 자동으로 찾을 수 있도록 하였습니다.
1. Introduction
Neural machine translation은 sentence를 읽은 후 정확한 번역 결과를 만들어내는 single, large neural network를 학습하는 것을 목적으로 합니다.
최근 제안된 대부분의 neural machine translation model은 encoder-decoder 계열입니다. Encoder neural network는 source sentece를 고정된 길이의 vector로 encode합니다. Decoder는 encoder에서 encoded된 vector에서 번역 결과를 만들어냅니다. Encoder-decoder system은 source sentence가 주어졌을 때 제대로 된 번역 결과가 나올 수 있는 확률을 최대화 하는 방향으로 학습됩니다.
Encoder-decoder가 가질 수 있는 문제점은 neural network가 source sentence가 가지고 있는 필수 정보들을 고정된 길이의 vector 안에 압축해서 넣어야 한다는 것입니다. 이는 neural network가 긴 길이의 sentence는 잘 다루지 못하도록 할 수 있어며 과거 연구에서 실제로 encoder-decoder는 input sentece의 길이가 길어질수록 성능이 떨어지는 것을 보였습니다.
이러한 문제를 다루기 위해 해당 논문에서는 align and translate를 동시에 학습할 수 있는 encoder-decoder model의 확장된 model을 제안합니다. 해당 논문에서 소개하는 model은 번역을 수행할 때 source sentence에서 가장 관련있는 정보를 포함하고 있는 부분의 위치를 찾습니다. 해당 논문의 model은 source sentence의 관련있는 부분인 context vector와 이전에 만들어진 target word들을 기반으로 target word를 예측합니다.
기존의 encoder-decoder model과 해당 논문에서 소개하는 model의 가장 구분되는 특징은 input sentence를 고정된 길이의 vector로 encode할 필요가 없다는 것입니다. 대신, input sentence를 vector의 sequence로 encode하고 translation 수행 중에 이 vector sequence 중 일부를 선택하여 사용합니다. 이를 통해 neural translation model이 source sentence의 모든 정보를 압축할 필요가 없어지게 됩니다. 그 결과 해당 논문에서는 소개하는 model을 통해 길이가 긴 sentence를 잘 다룰 수 있다는 것을 보여줍니다.
해당 논문에서 제안하는 model은 source sentence와 target sentence 사이의 언어적으로 관련이 있는 alignment를 찾습니다.
2. Background: Neural Machine Translation
Translation은 source sentence x가 주어졌을 때 y의 조건부 확률을 최대화(argmax_y p(y|x))하는 target sentence y를 찾는 것으로 생각할 수 있습니다. Neural machine translation에서는 parallel training corpus를 활용하여 sentence pair의 조건부 확률을 최대화할 수 있도록 model의 parameter를 조정합니다. Translation model을 통해 학습된 조건부 분포가 학습이 된다면 source sentence가 주어지면 해당 sentence의 translation은 조건부 확률의 최대값을 갖는 것으로 선택됩니다.
최근 neural machine translation은 2개의 구성요소로 이루어져있습니다. 하나는 source sentence x를 encode하는 것과 다른 하나는 target sentence y를 decode하는 것입니다. 예를 들어 2개의 RNN은 고정되지 않은 길이의 source sentence를 고정된 길이의 vector로 encode하고 이 vector를 다시 고정되지 않은 길이의 target sentence로 decode 해줍니다.
예를 들어, phrase table에서 phrase pair의 score나 candidate translation의 re-rank를 위해 neural component를 추가하였을 때 기존보다 좋은 결과를 얻을 수 있었습니다.
2.1 RNN Encoder-Decoder
RNN Encoder-Decoder를 활용하여 해당 논문에서는 aling과 translation을 동시에 학습할 수 있는 새로운 구조를 소개합니다.
Encoder-Decoder에서 encoder는 input sentence (x = (x_1 ~ x_T))를 읽어 고정된 길이의 vector c를 만듭니다.

Decoder는 context vector c와 이미 기존에 예측된 단어들인 (y1 ~ y(t'-1))이 주어졌을 때 다음 단어인 y_t'를 예측하기 위해 학습됩니다.

3. Learning to Align and Translation
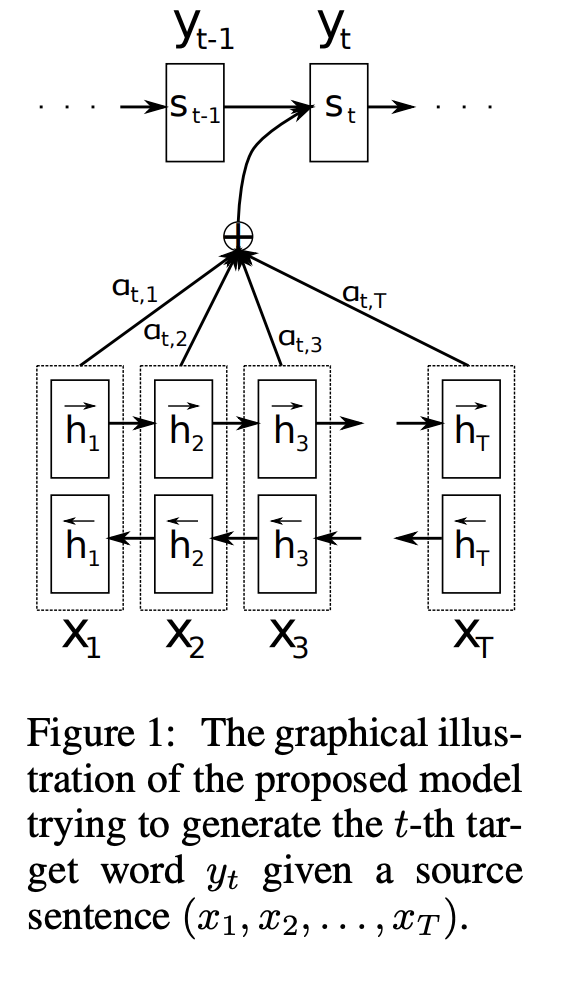
해당 논문에서는 neural machine translation을 위한 새로운 구조를 소개합니다. 이 구조는 encoder로 bidirectional RNN을 encoder와 decoder로 사용하고 decoder는 translation을 decoding하는 중에 source sentence를 searching합니다.
3.1 Decoder: General Description
새로운 model 구조에서 아래 식과 같이 새로운 조건부 확률을 정의합니다.
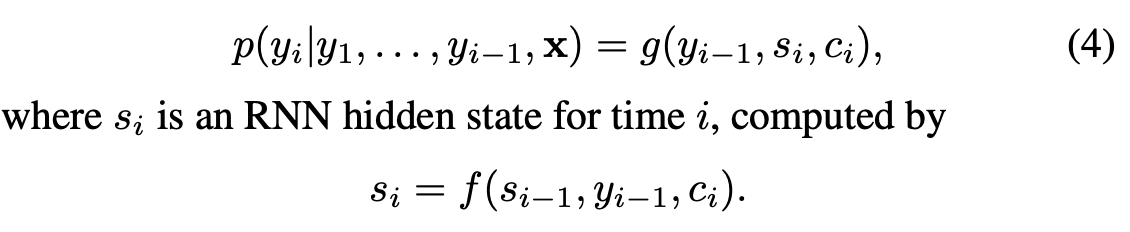
기존의 encoder-decoder와는 달리 여기서는 조건부 확률이 target word yi마다 서로 다른 context vector c_i를 활용합니다.
Context vector c_i는 encoder가 input sentence를 mapping한 (h_1 ~ h(T_x))라는 annotation(attention) sequence로부터 얻어집니다. 각 annotation h_i는 input sentence의 i번째 단어 주변의 부분을 focus하여 전체 input sequence의 정보를 포함하고 있습니다.
Context vector c_i는 아래와 같이 annotaion h_i들의 가중합을 통해 계산됩니다.

해당 논문에서는 alignment model a를 feedforward neural network를 활용하였습니다. 기존 translation machine translation과 달리 alignment는 latent variable로 간주되지 않습니다. 대신 alignment model은 soft alignment를 통해 직접적으로 계산하며 cost function의 gradient는 역전파를 통해 얻을 수 있습니다. 이 gradient는 전체 translation model뿐만 아니라 alignment model까지 학습할 떄 사용할 수 있습니다.
모든 annotaion의 가중합을 expected annotation을 계산하는 과정으로 생각할 수 있습니다. Alpha_ij를 source word x_j와 align되어 있고 source word x_j에서 translation되는 target word y_i의 확률이라고 합시다. 그러면 i번째 context vector c_i는 확률 alpha_ij의 모든 annotation에서 얻을 수 있는 expected annotation으로 생각할 수 있습니다.

3.2 Encoder: Bidirectional RNN for Annotating Sequences
해당 논문에서는 각 단어의 annotation이 이전 단어 뿐만 아니라 후에 나오는 단어들 역시 가능할 수 있도록 하였습니다. 그러기 위하여 해당 논문에서는 BiRNN(bidirectional RNN)을 활용하였습니다.
BiRNN은 forward RNN과 backward RNN으로 이루어져있습니다. Forward RNN은 input sentence를 순서대로 읽으며 forward hidden state를 만듭니다. Backward RNN은 input sentence를 역순으로 읽으며 backward hidden state를 만듭니다.
해당 논문에서는 각 단어 x_j의 annotation을 forward hidden state와 backward hidden state를 concat 하여 얻습니다. 이를 통해 annotation h_j는 앞에 등장하는 단어와 뒤에 등장하는 단어의 모든 것들을 요약하여 담고 있습니다. RNN이 최근 input의 정보를 더 잘 갖고 있기 때문에 annotation h_j는 x_j단어 주변을 더욱 focus하고 있습니다.
4. Experiment Settings
4.1 Dataset
4.2 Models
- RNN Encoder-Decoder(RNNencdec) : 기존
- RNNsearch : 해당 논문에서 제안
- 30, 50 : 문장이 지닌 최대 단어 수
- Minibatch SGD + Adadelta
- Beam search







5. Results
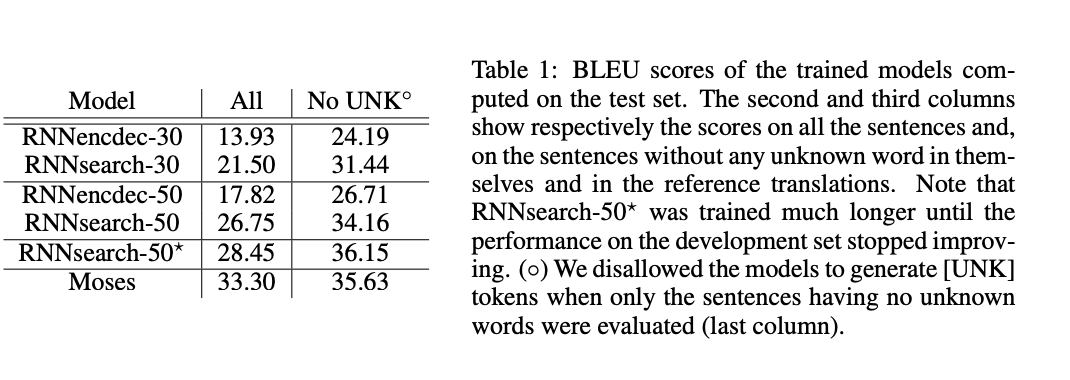
5.1 Quantitative Results
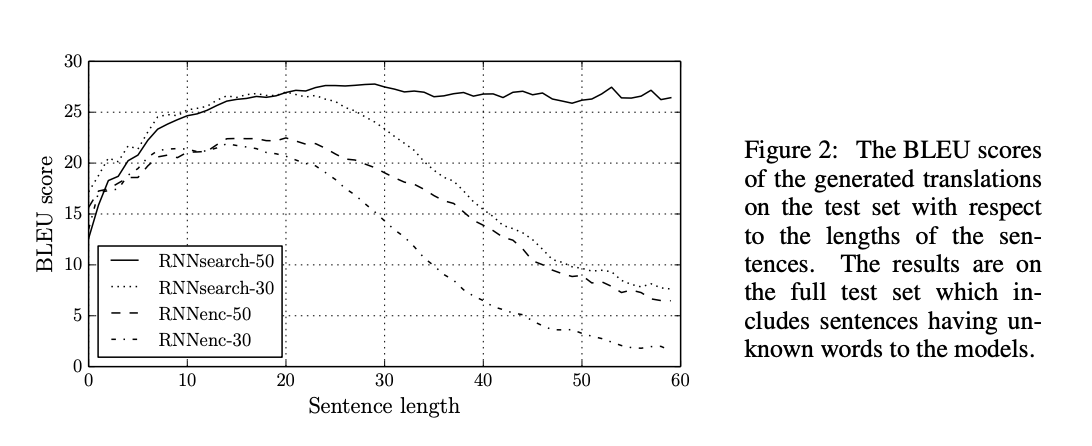
5.2 Qualitative Analysis
5.2.1 Alignment
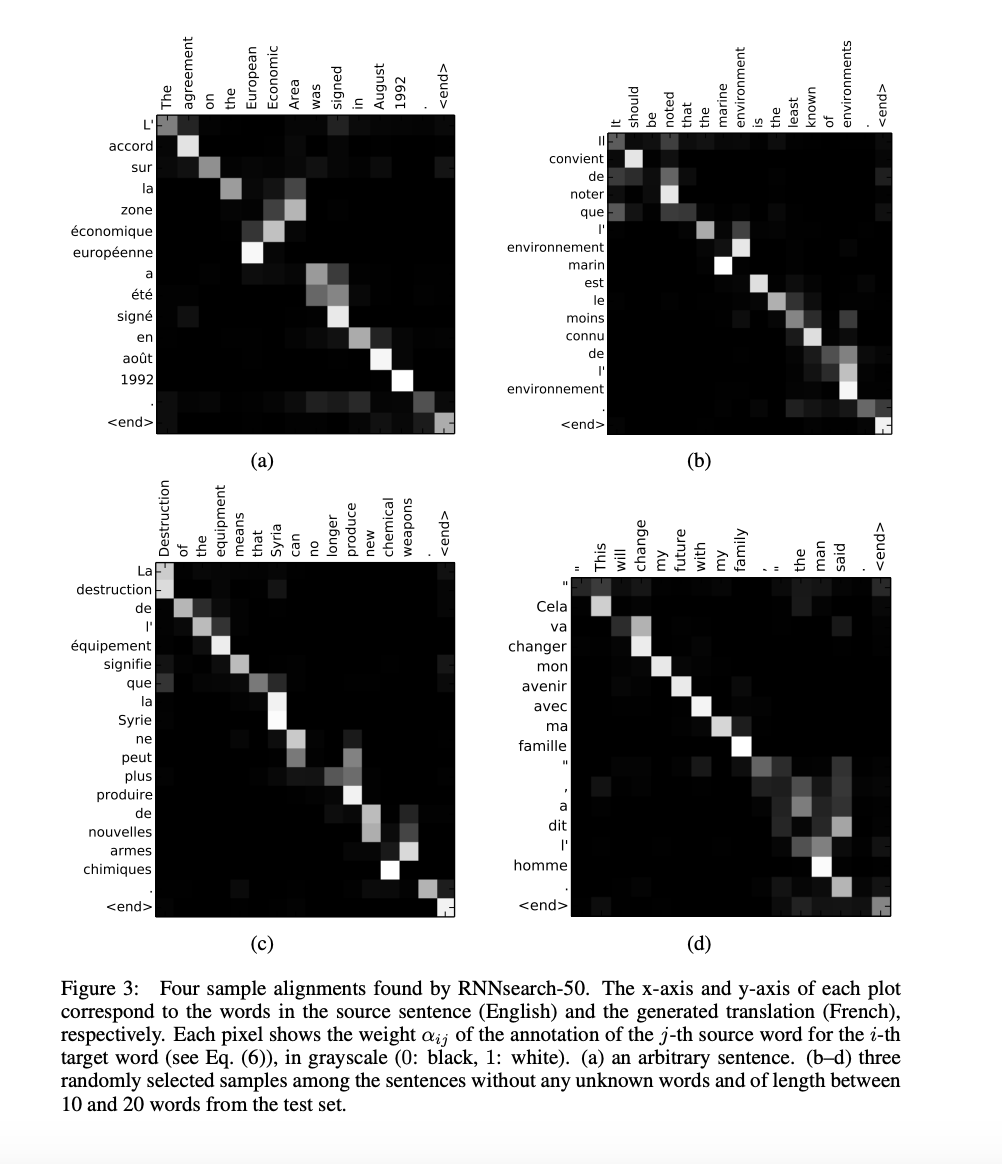
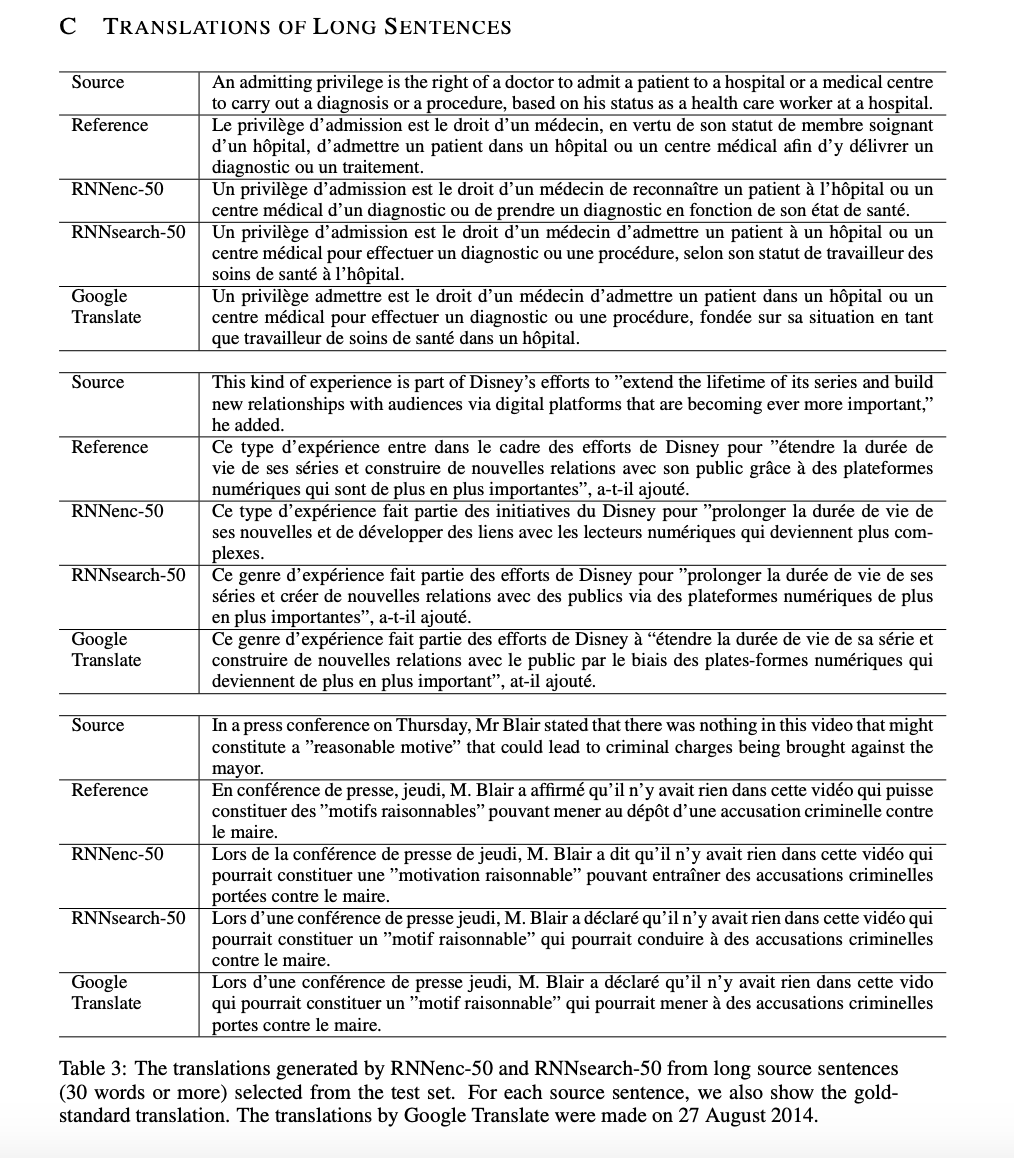
5.2.2 Long Sentences
해당 논문에서 제안한 model인 RNNsearch는 기존 model인 RNNencdec보다 긴 문장에 대해 translation 성능이 좋았습니다. 이는 RNNsearch는 긴 문장을 고정된 길이의 vector로 encode할 필요가 없기 때문일 수 있습니다.
6. Related Work
6.1 Learning to Align
6.2 Neural Network for Machine Translation
7. Conclusion
해당 논문에서는 긴 문장을 translation할 때 고정된 길이의 vector로 변환하는 것이 성능 저하에 큰 영향을 미친다고 의심하였습니다.
이를 해결하기 위하여 기본적인 encoder-decoder를 확장하여 input word를 search할 수 있도록 하였으며 encoder를 통해 annotation을 계산하고 target word를 만들어냈습니다. 이를 통하여 model은 더 이상 source sentence를 고정된 길이의 vector로 변환할 필요가 없어졌으며 다음 target word를 만들어낼 때 관련있는 정보에 focus를 할 수 있게되었습니다.
