
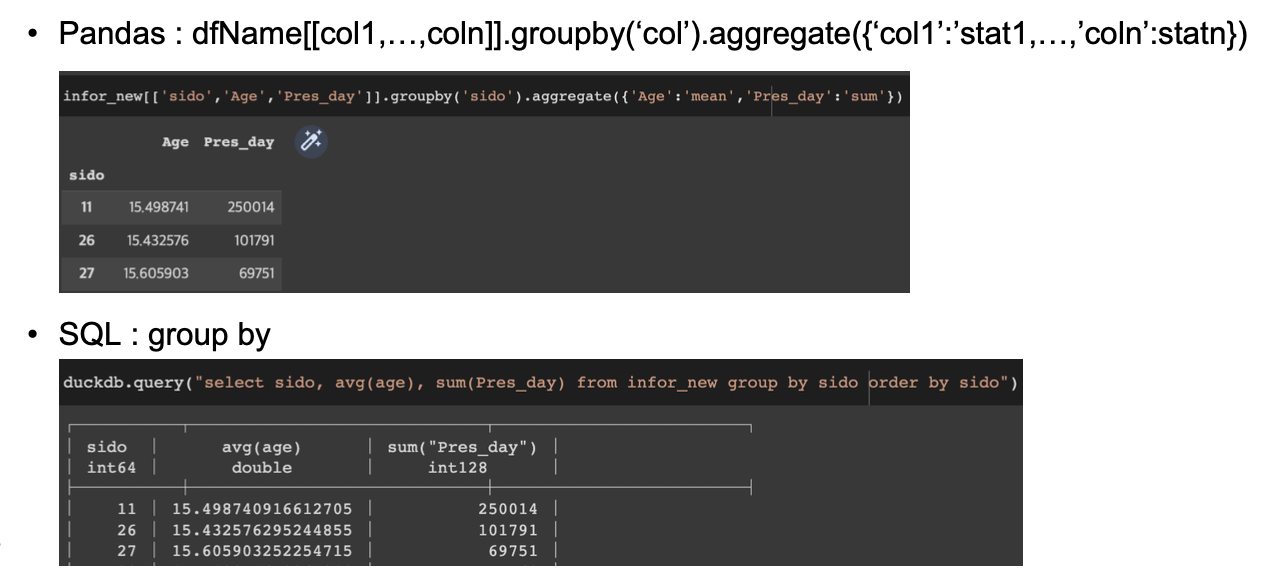
1. 데이터 전처리: SQL & Pandas
1) SQL 문법을 읽고 실행할 수 있는 라이브러리 설치
Pip install duckdb2) duckdb 라이브러리 호출
Import duckdb3) SQL 쿼리문으로 데이터 프레임 생성
infor2020 = duckdb.query(‘select * from DF_name where 조건‘).df()pd.DataFrame & duckdb.query
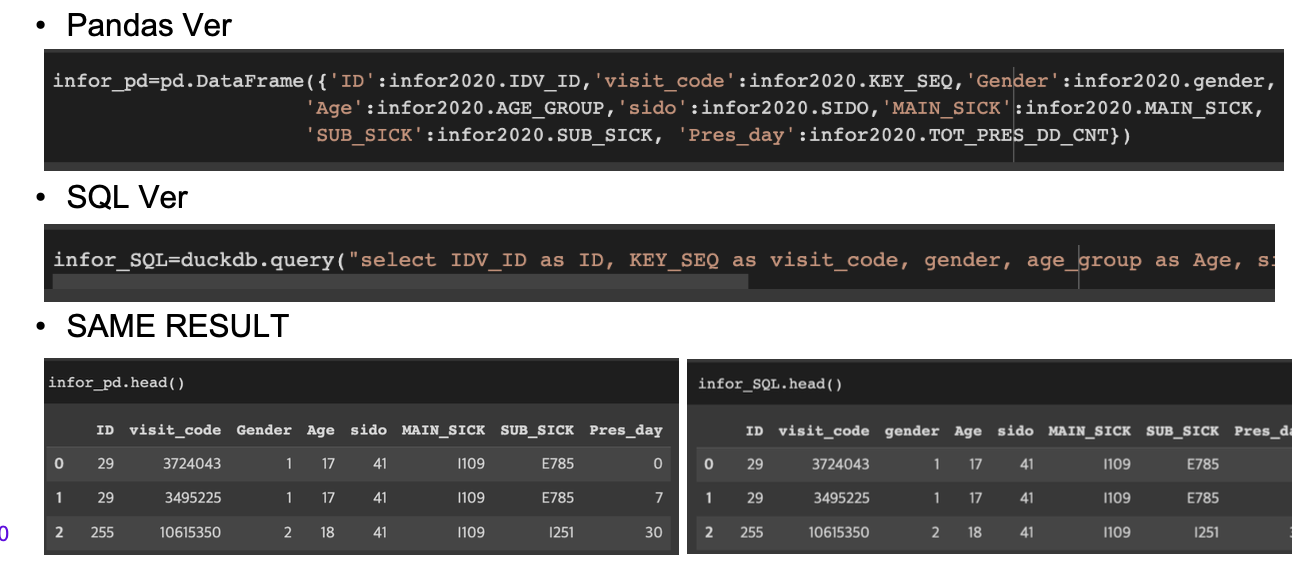
pd.concat - append & duckdb.query - union
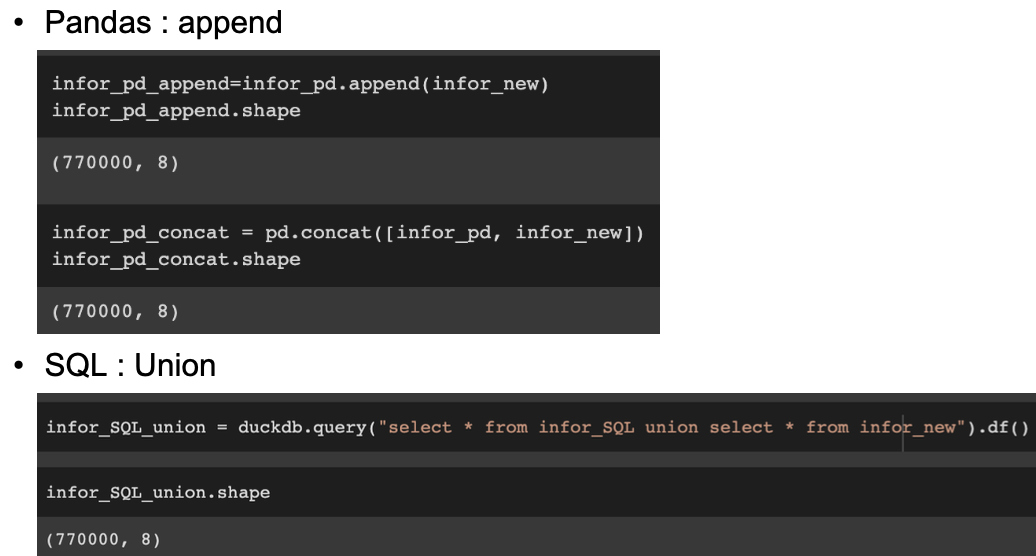
조건 검색 : 조건연산자 & duckdb.query – where
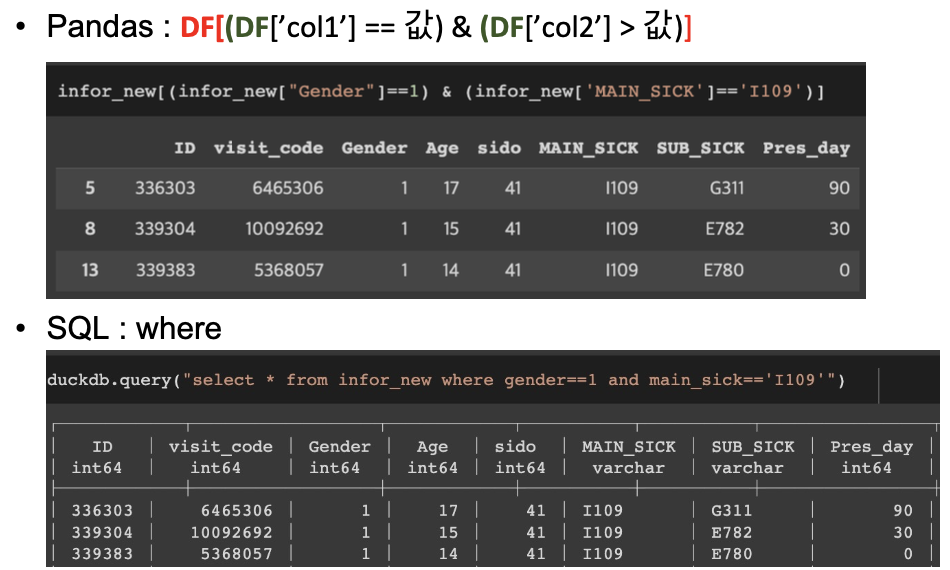
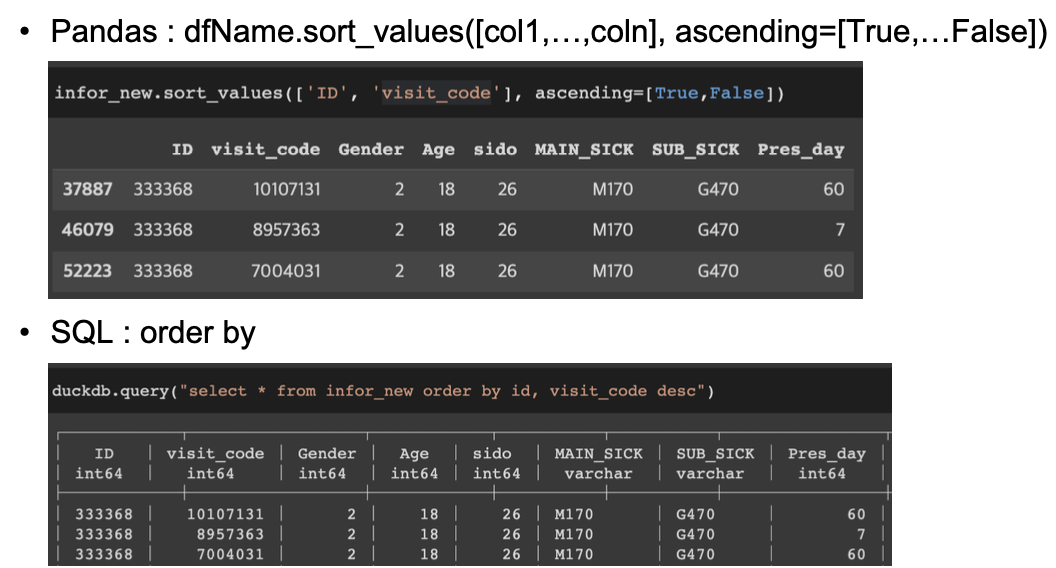
정렬하기 : Sort_values & duckdb.query – order by
그룹별 집계 : Groupby & duckdb.query – group by
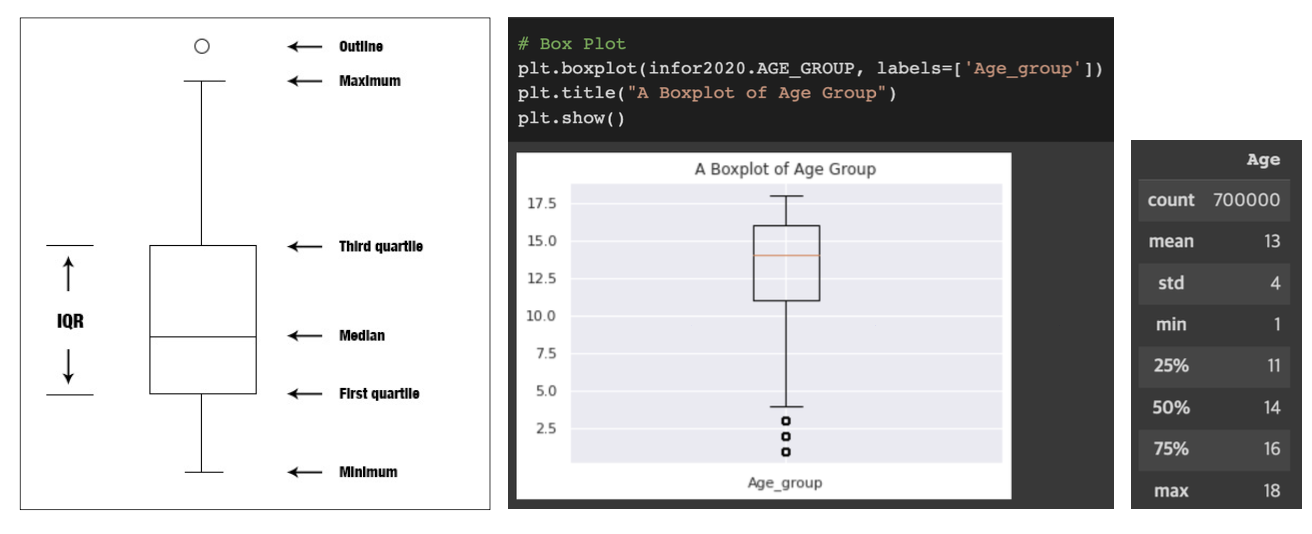
2. EDA - 기초 통계량 산출 (전체, 그룹별, Boxplot)
EDA(Exploratory Data Analysis) : 탐색적 데이터 분석
- 분석하려는 데이터는 어떤 종류의 데이터 타입으로 구성되어 있을까?
- 데이터에 포함된 변수(컬럼)의 분포는 어떠한가? (평균, 분산, 최대, 최소, 이상치, 분포의 형태 등등)
- 결측치가 있는가? 있다면 얼마나 빈번하고 어느 변수에 주로 포함되어 있을까?
- 일부 변수 간 선형관계(상관관계)가 존재하는가?
- 분석과 관련이 없어서 제외할 수 있는 변수는 무엇일까?
데이터 구조 및 특성 파악하기
• 공공데이터 활용
데이터 타입
• 변수별 데이터 타입 확인하기
DfName.dtypes기초통계량
• 연속형변수
DfName.describe().round(2).transpose()• 범주형변수
DfName.describe(include=‘object’).round(2).transpose()Boxplot
그룹별 기초통계량 산출
- 기초 통계량을 시리즈 형태로 산출하는 함수 선언
def getdesc(x):
out={}
out['min']=x.min()
out['qr1']=x.quantile(0.25)
out['med']=x.median()
out['qr3']=x.quantile(0.75)
out['max']=x.max()
out['count']=x.count()
return pd.Series(out)
- 기초 통계량 산출 함수를 apply에 활용
DfName.groupby([‘groupIndex_col'])[‘desc_col'].apply(getdesc).unstack()3. EDA - 데이터 시각화 (Seaborn 라이브러리)
시각화 라이브러리 : Seaborn
- Matplotlib보다 세련된 시각화 방식을 제공
- Pandas DataFrame과 함께 사용하도록 설계
- 통계 데이터 탐색과 모형 적합에 유용한 플롯 생성 가능
1.seaborn 라이브러리 호출
Import seaborn as sns2.sns 라이브러리에 속한 메소드로 그래프 그리기
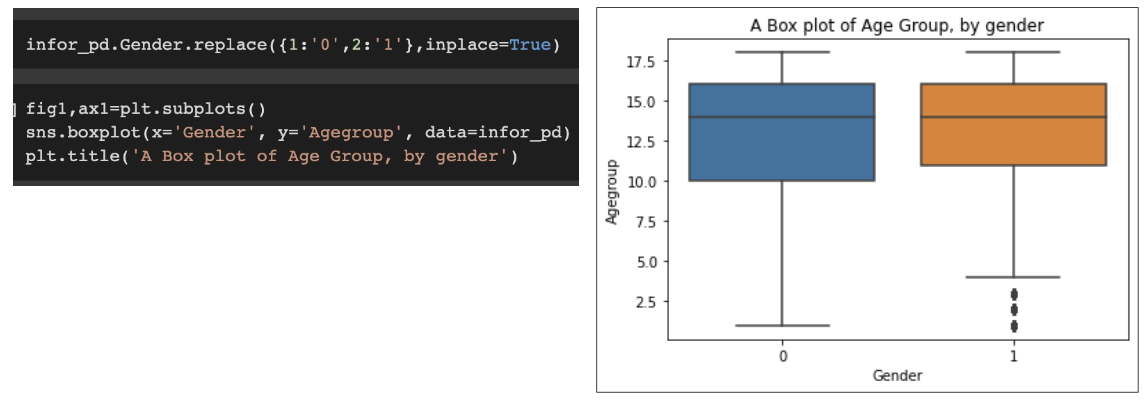
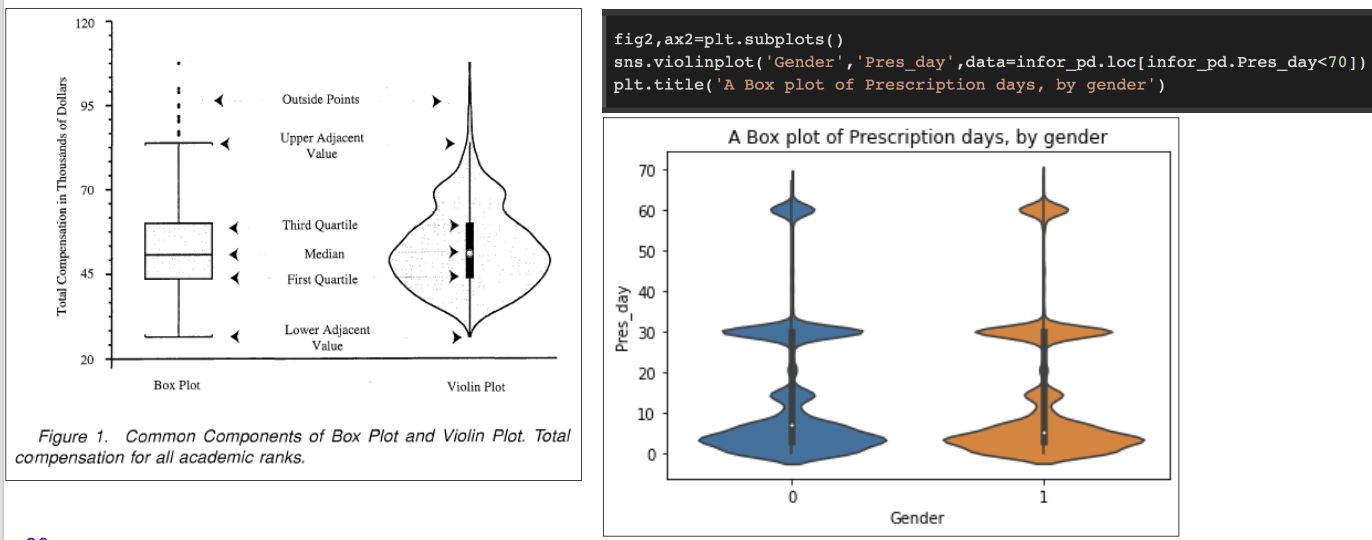
sns.boxplot(x=‘group_col', y=‘desc_col', data=df_Name)
sns.violinplot(‘group_col’ ',’desc_col’,data= df_Name.loc[df_Name.desc_col<100])
sns.kdeplot(df_Name.col)그룹별 박스 플랏 그리기
fig,ax=plt.subplots()
sns.boxplot(x=‘Group_col', y=‘Col', data=DF_Name)
plt.title(‘~~Title Name~~')
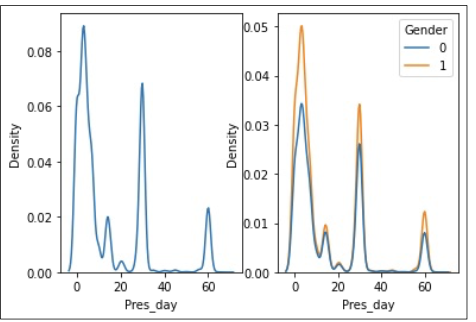
밀도함수 그리기
fig,ax=plt.subplots()
sns.kdeplot(data=DF_Name, x=col, hue=‘Group_col)
plt.title(‘~~Title Name~~')
밀도함수 그리기 & 2개를 하나로
fig,ax=plt.subplots(1,2)
sns.kdeplot(data=DF_Name, x=col ,ax=ax4[0])
sns.kdeplot(data=DF_Name, x=col, hue=‘Group_col ,ax=ax4[1])
바이올린 플롯 = 박스플롯 + 밀도함수(pdf)
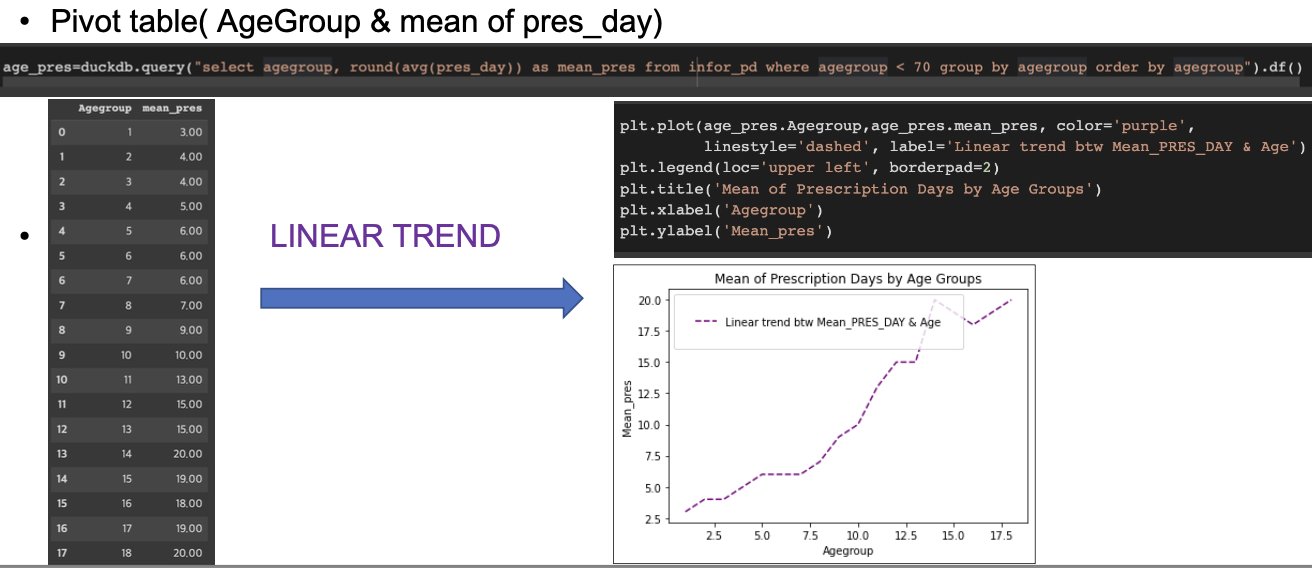
Pivot table & Line Plot - 선형 관계 파악하기
4. 모형 선택 & 분석 & 피드백
선형관계 예상 : 선형모델 중 회귀분석 선택
• 사이킷런 라이브러리 호출
from sklearn.linear_model import LinearRegression• 독립변수, 반응변수: numpy 배열로 생성
y=np.array(df_Name.Response_col)
x=np.array(df_Name.Indep_col).reshape((-1, 1))
• 모형 적합
model = LinearRegression().fit(x,y)• 결정계수 산출
r_sq = simple_model.score(x, y)5. 금융 데이터 분석
데이터 분석 프로세스
시계열데이터?
• Time-based ordering: 시간의 흐름에 따라 수집된 데이터
• 자기상관성: 이전 데이터가 현재의 값에 영향을 미침
• 비정상성: 평균과 분산이 시간이 지남에 따라 변화
• 가격을 수익률로 변환함으로써, 정상성을 띄게할 수 있다.
• 단순 수익률
• 로그 수익률
데이터 수집 : 크롤링
• API를이용하여네이버금융페이지에있는데이터를가져올수있다.
1. 라이브러리 설치 & 호출
!pip install xmltodict
import requests
import xmltodict
import json
from pandas import json_normalize• KODEX200: KOSPI200 지수의 변동에 따라 수익률이 결정되는 펀드, 주식처럼 거래가 가능하고, 적은 투자금으로 분산투자 가능
#종목 코드
stockCode = ["069500"]
df_stock = pd.DataFrame()• KOSPI200지수 : 유가증권시장에 상장된 전체 종목 중에서 시장대표성,업종대표성, 유동성 등을 감안하여 선정된 200개 종목을 시가총액 가중방식으로 산출한 지수
2.반복문으로데이터프레임에저장하기
for code in stockCode:
count = '181’
url = f'https://fchart.stock.naver.com/sise.nhn?symbol={code}&timeframe=day&count={count}&requestType=0’
print(url)
rs = requests.get(url)
dt = xmltodict.parse(rs.text)
js = json.dumps(dt,indent = 4)
js = json.loads(js)
data = pd.json_normalize(js['protocol']['chartdata']['item’])
df = data['@data'].str.split('|',expand = True)
df.columns = ['date','OpeningPrice','High','Low','ClosingPrice','Volumn’]
df["code"] = code
df_stock = df_stock.append(df)
df_stock["date"] = pd.to_datetime(df["date"])
데이터전처리
1. 데이터 타입 확인
Df_Name.col1=pd.to_numeric(Df_Name.col1)2. 수익률 변수 만들기: 단순 수익률, 로그 수익률 변수 생성
df_Name["simple_rtn"]=df_Name.Price.pct_change()
df_Name["log_rtn"]=np.log(df_ Name. Price /df_ Name.Price.shift(1))3. EDA : Line plot: 종가,단순수익률,로그수익률그래프그려서추세확인하기
fig, ax = plt.subplots(3, 1,figsize=(12,7))
fig.suptitle(‘~~plot name~~')
sns.lineplot(df_Name.date,df_Name.Price, color='purple', ax=ax[0])
sns.lineplot(df_Name.date,df_Name.simple_rtn, color='blue', ax=ax[1])
sns.lineplot(df_Name.date,df_Name.log_rtn, color='green', ax=ax[2])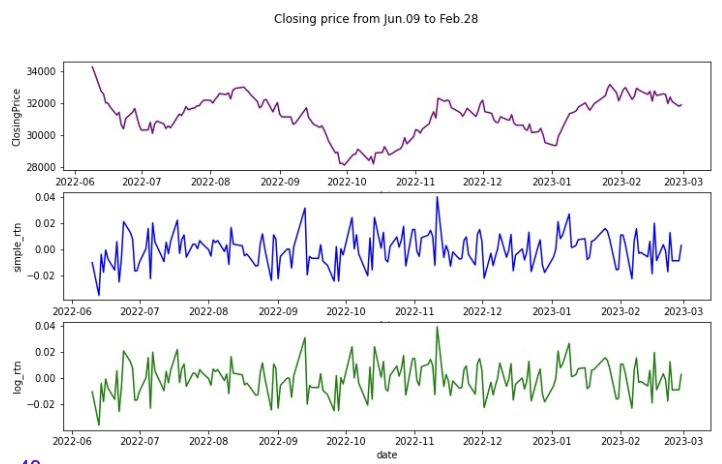
4. EDA : OUTLIERS 아웃라이어 확인하기: 3𝜎 rule (거의 대부분의 값이 평균값의 표준편차 근방에 있다)
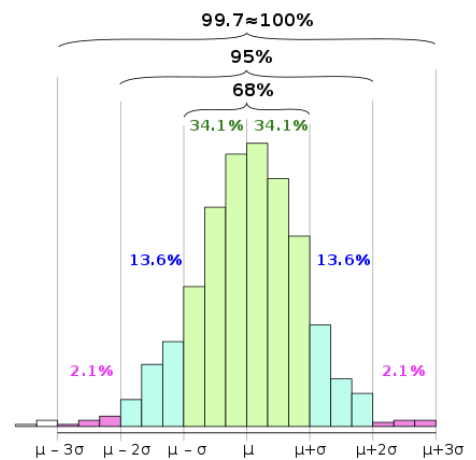
EDA : OUTLIERS (3𝜎 rule)
• 롤링평균(21일을기준으로앞으로밀어가며구하는평균)과표준편차를계산
• 특이값을탐지하는함수를정의
• 특이값을탐지하는함수를적용하고,해당값을저장
• Lineplot으로시각화
시계열 모델 적합 & 예측
1. 라이브러리설치 & 호출
!pip install prophet
import prophet2. 로그 수익률 활용
df_Name_pro=df_Nane.rename(columns={'date':'ds','log_rtn':'y'})3. 학습 & 테스트 데이터 나누기
train_indices= df_Name_pro.ds.apply(lambda x:x.year)<2023
df_train= df_Name_pro.loc[train_indices].dropna()
df_test= df_Name_pro.loc[~train_indices].reset_index(drop=True)
4.모델 적합
model_prophet=prophet.Prophet(seasonality_mode='additive')
model_prophet.fit(df_train)
5. 생성한 모델로 60일 예측 값 추정
df_future=model_prophet.make_future_dataframe(periods=60)
df_pred=model_prophet.predict(df_future)6. 추정값 그래프로 시각화
model_prophet.plot(df_pred)7. 테스트와 예측값 비교하기위해 데이터 결합
df_pred=df_pred.loc[:,selected_columns].reset_index(drop=True)
df_test=df_test.merge(df_pred,on=['ds'],how='left')
df_test.ds=pd.to_datetime(df_test.ds)
df_test.set_index('ds',inplace=True)
8. 실제와 추정차이 시각화
fig,ax=plt.subplots(figsize=(12,5))
ax=sns.lineplot(data=df_test[['y','yhat_lower','yhat_upper','yhat']])
ax.fill_between(df_test.index, df_test.yhat_lower, df_test.yhat_upper, alpha=0.3)
ax.set(title='ETF - Actual rtn vs Predicted', xlabel='Date', ylabel='Price')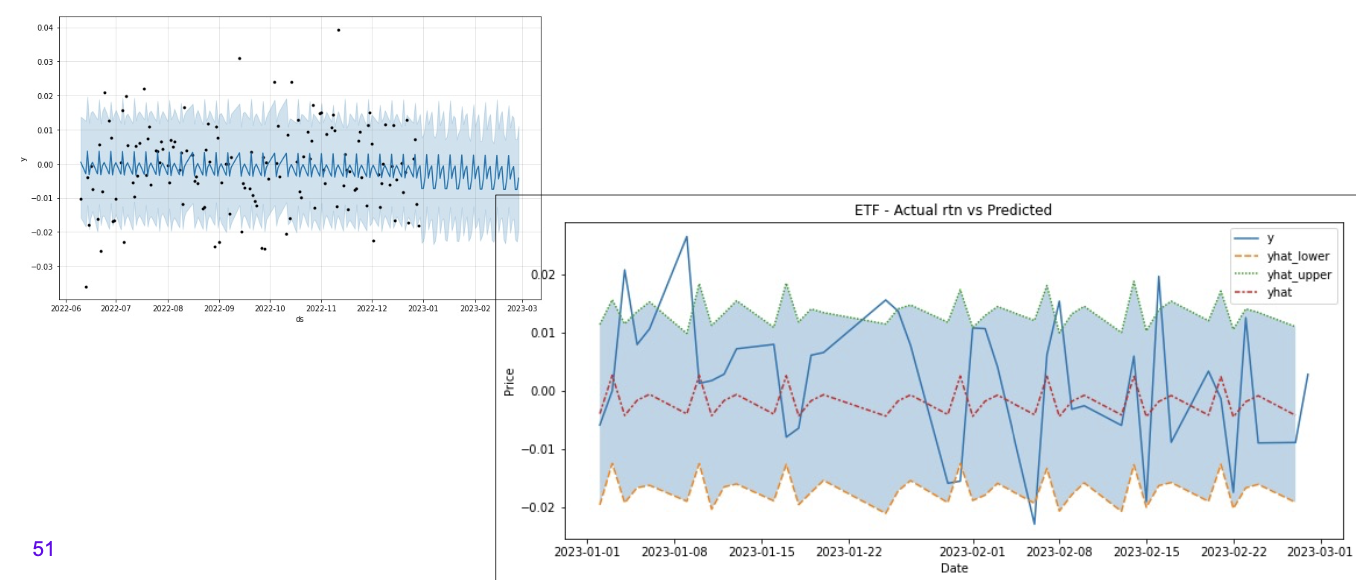

👩🏻💻