
1. Pandas
Pandas(Panel Data)
데이터 처리와 분석에 사용되는 파이썬 라이브러리
다양한 데이터 포맷을 다룰 수 있음
데이터프레임 객체로 모든 데이터를 처리
• 데이터가 여러 출처에서 수집되어 형태나 속성이 다양한 경우, 컴퓨터가 이해할 수 있도록 동일한 구조로 통합되어야 한다.
• 판다스 라이브러리는 시리즈(Series)와 데이터프레임(DataFrame)이라는 데이터 형식을 제공한다.
• 시리즈(Series)는 숫자의 나열인 1차원 배열 형식이고, 데이터프레임(DataFrame) 은 행과 열로 이루어진 2차원 배열 형식으로 만들 수 있어 데이터 분석 실무에서 자주 사용한다.
• 데이터를 다룰 수 있는 내장함수(Built-infunction)을 제공한다.
Pandas : 데이터 입력/불러오기
1.판다스라이브러리호출
Import pandas as pd2.데이터객체데이터프레임으로변환
infor2020 = pd.DataFrame({‘col1’:list1,...’coln’:listn})3.CVS파일불러오기
infor2020 = pd.read_csv('/content/drive/health_infor2020.csv')Pandas : Series
-
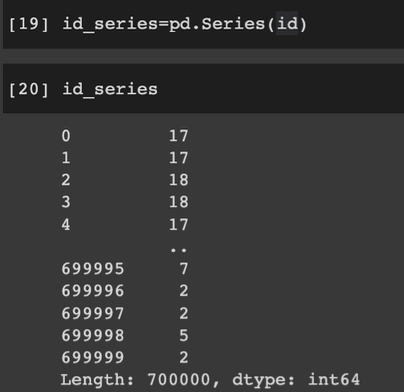
시리즈: 인덱스와 값으로 구성된 1차원 배열
-
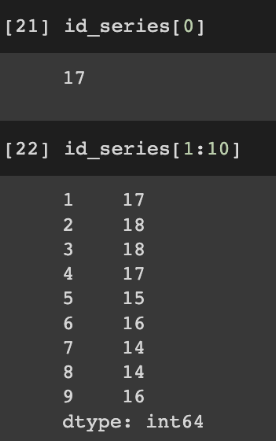
인덱스로 값에 접근 가능
-
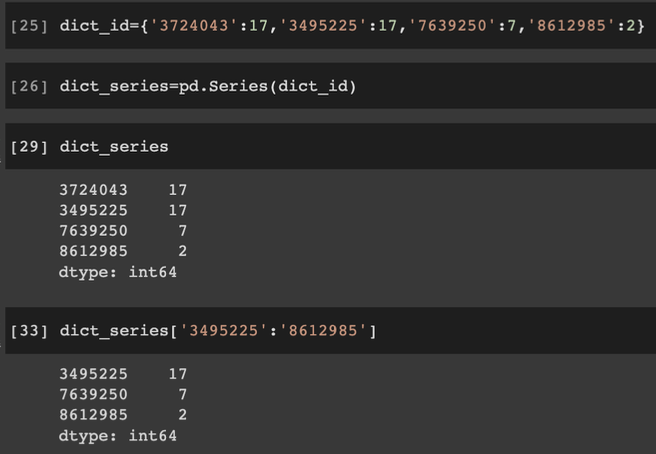
딕셔너리 타입을 활용하면, 인덱스를 문자로 활용 가능
Pandas : DataFrame
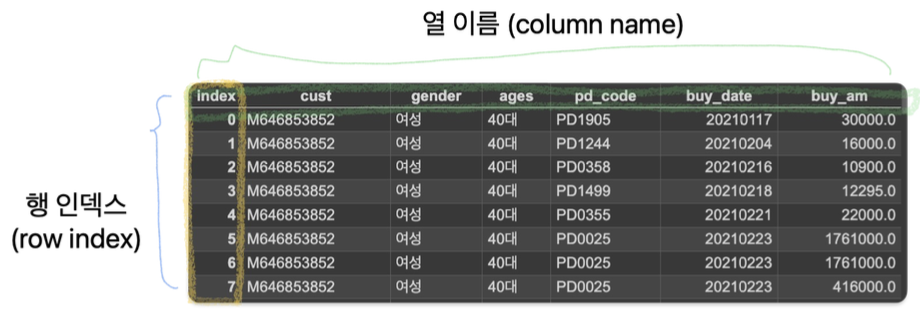
- 데이터 프레임: 행인덱스와 열이름으로 구성된 2차원 배열
- 행 (row): 개별 관측값 (Observation)
- 열 (column): 공통의 속성이나 범주를 나타내는 변수 (Variable)
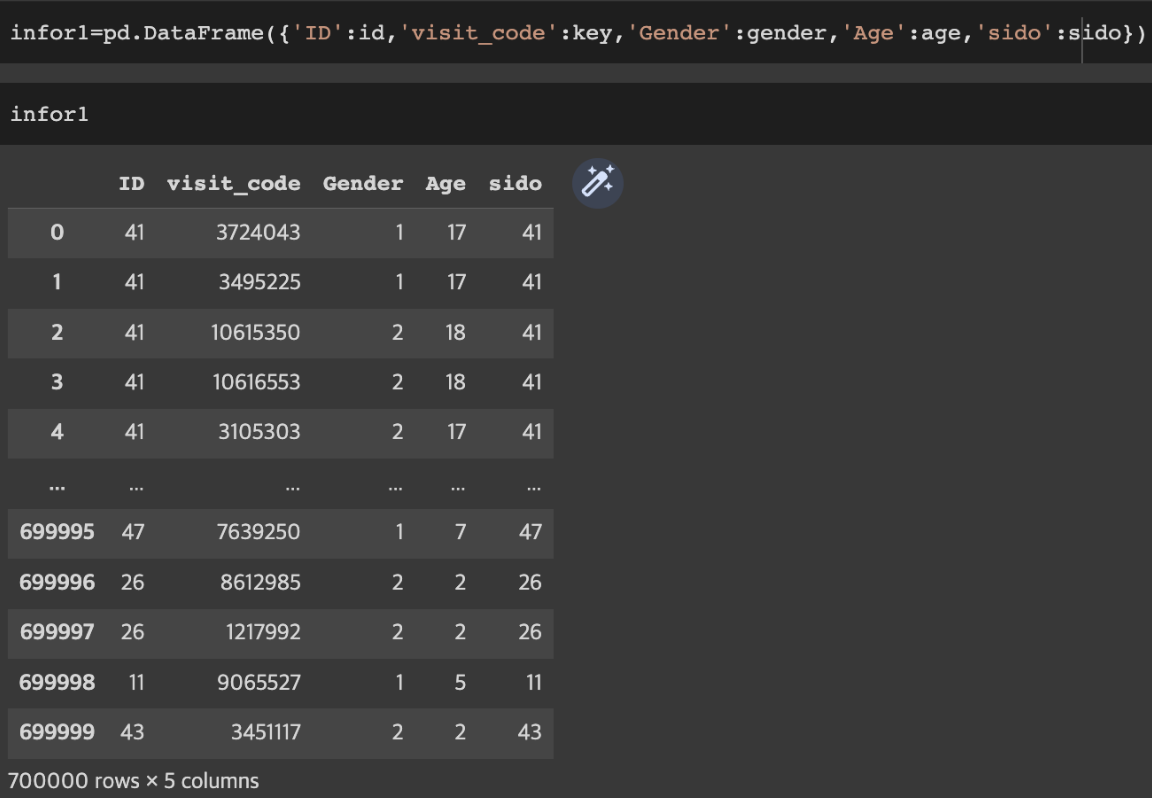
인덱스 지정 없이 데이터 프레임 생성
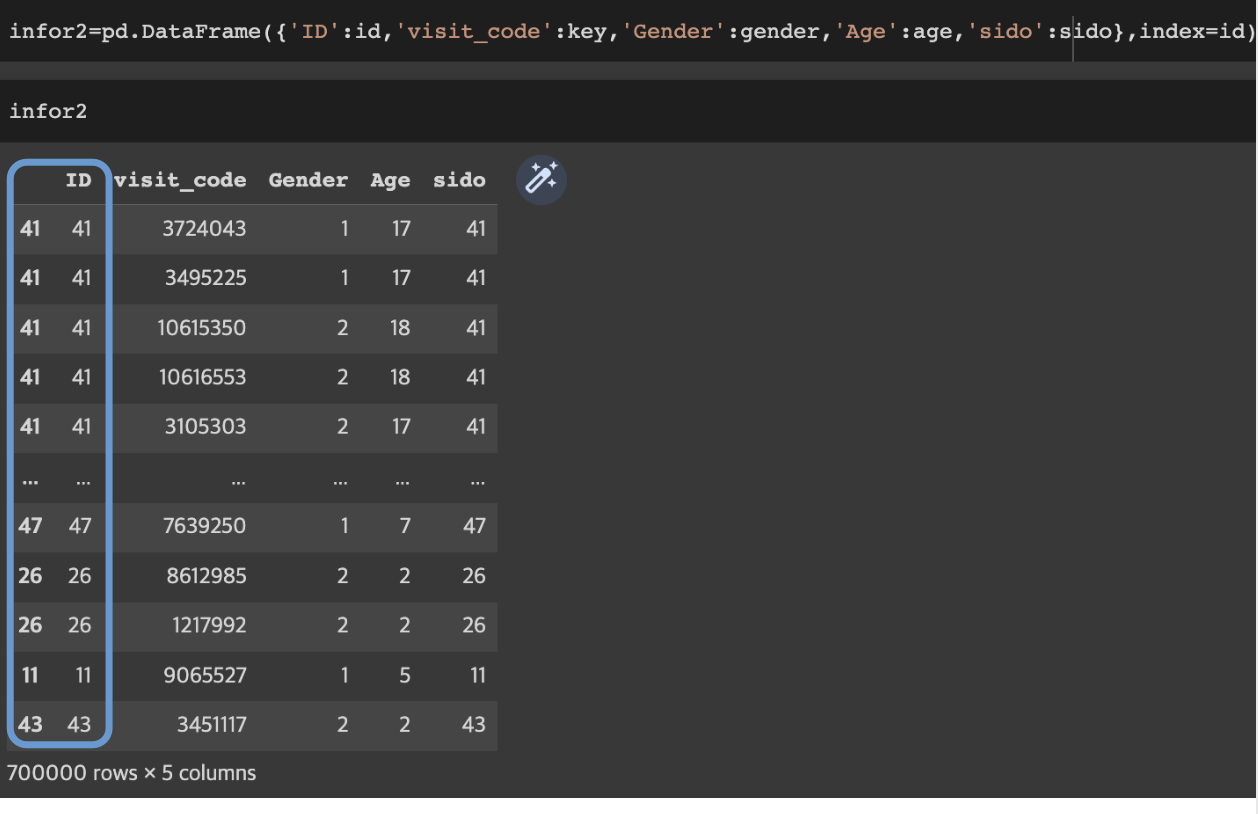
인덱스 지정해서 데이터 프레임 생성
행 정보 가져오기
DataFrameName.iloc[index_Number] DataFrameName.iloc[index_start:index_end]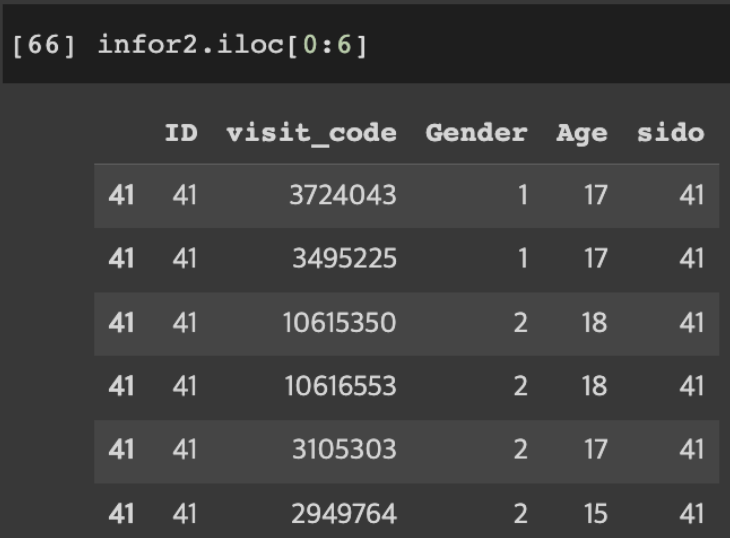
열 정보 가져오기
DataFrameName.iloc[ : , column_Number]
DataFrameName.iloc[ : , column_start: column _end]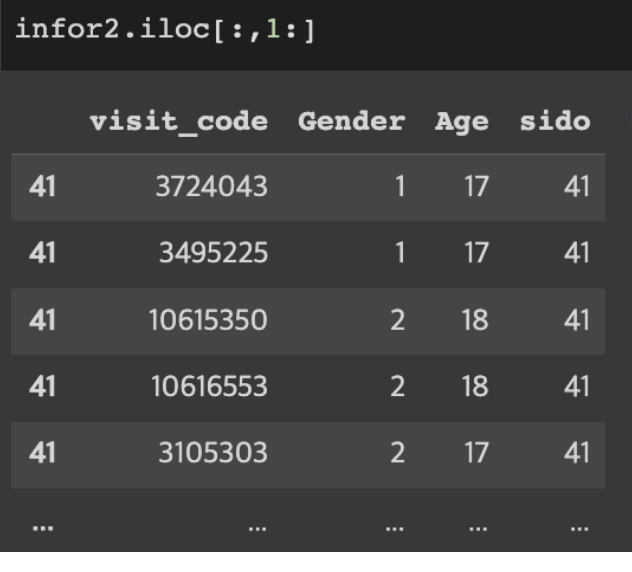
행/열 구간 모두 지정
DataFrameName.iloc[index_start:index_end , column_start: column _end]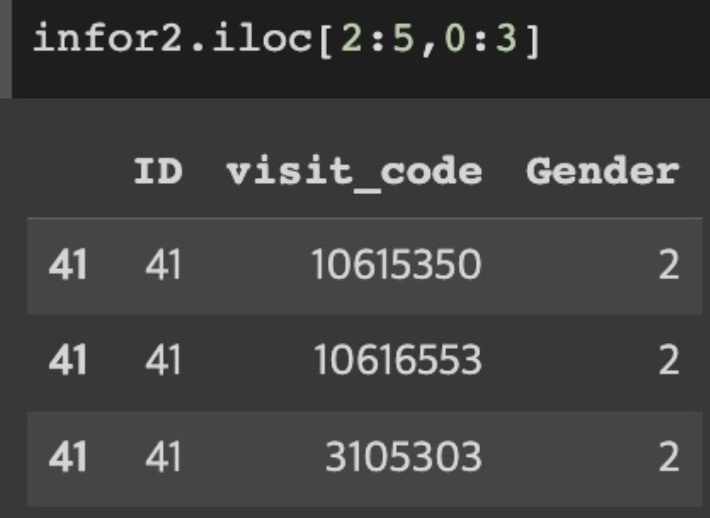
컬럼 이름으로 특정 컬럼 불러오기
DataFrameName.columnName
DataFrameName[“columnName”]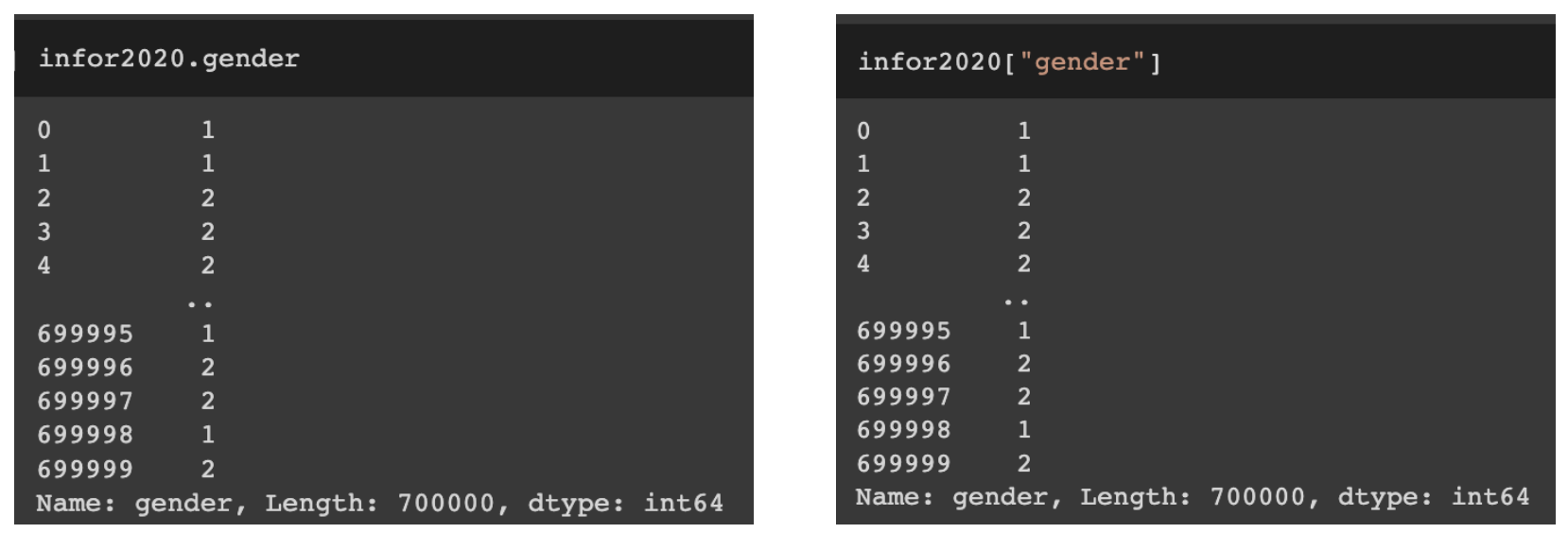
컬럼 이름으로 여러 컬럼 불러오기
DataFrameName[[“columnName1”, ... ,“columnName_n”]]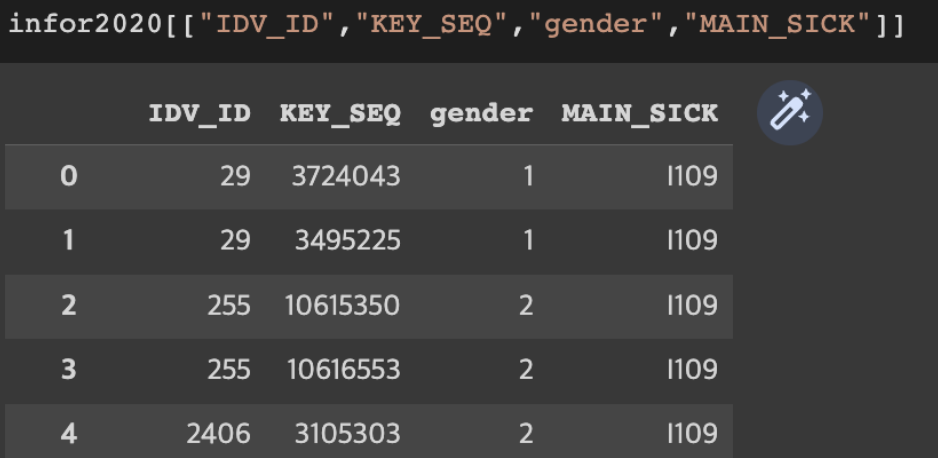
데이터 프레임에 여러 컬럼 추가
DataFrameName [[“NewcolName1”, ... ,“NewcolName_n”]] = DF [[“ColName1”, ... ,“ColName_n”]]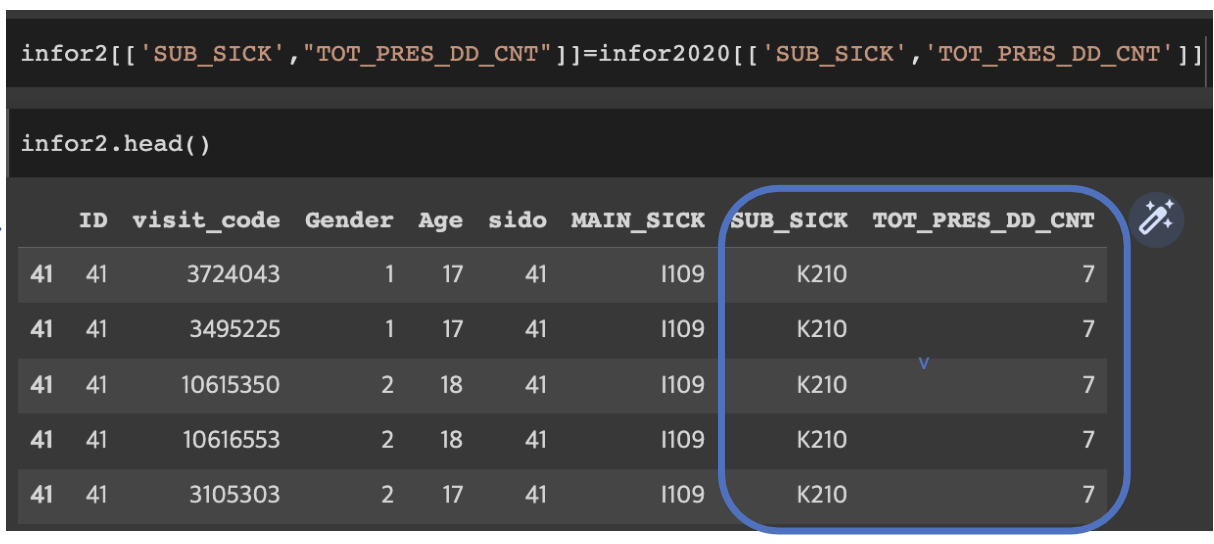
데이터 프레임에 행 추가 하기
DataFrameName.loc[last_Index+1] = [값1,값2,...,값n]
DataFrameName.loc[last_Index+1]=dfName.loc[추가할 index]
인덱스가 겹치면 추가가 아니라 기존 값을 바꿔치기 하게 됨append: 데이터 프레임 위아래로 결합하기
NEWDF = DataFrameName.append(dfName.loc[startIndex:endIndex])
NEWDF = DataFrameName.append(dfName)
결합된 데이터프레임을 객체로 만들어야 결합 결과가 저장됨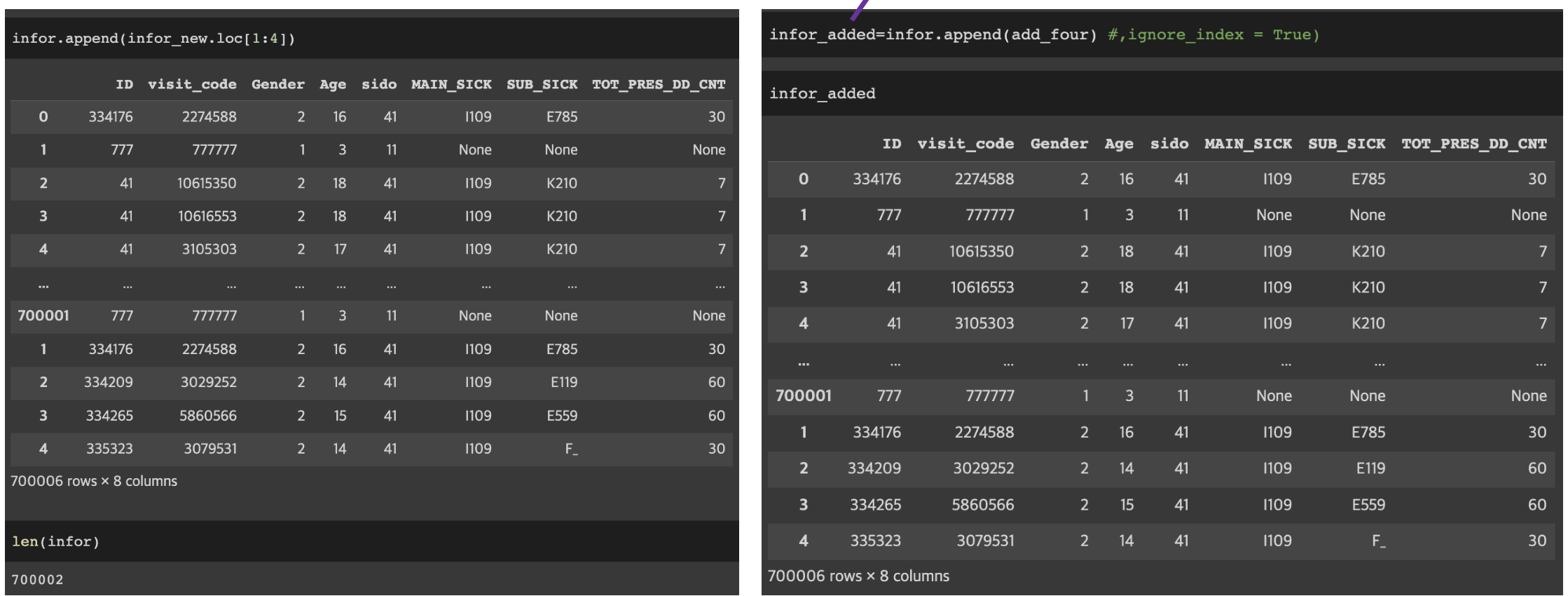
concat:데이터프레임위아래로결합하기
NEWDF = pd.concat([DataFrameName,dfName])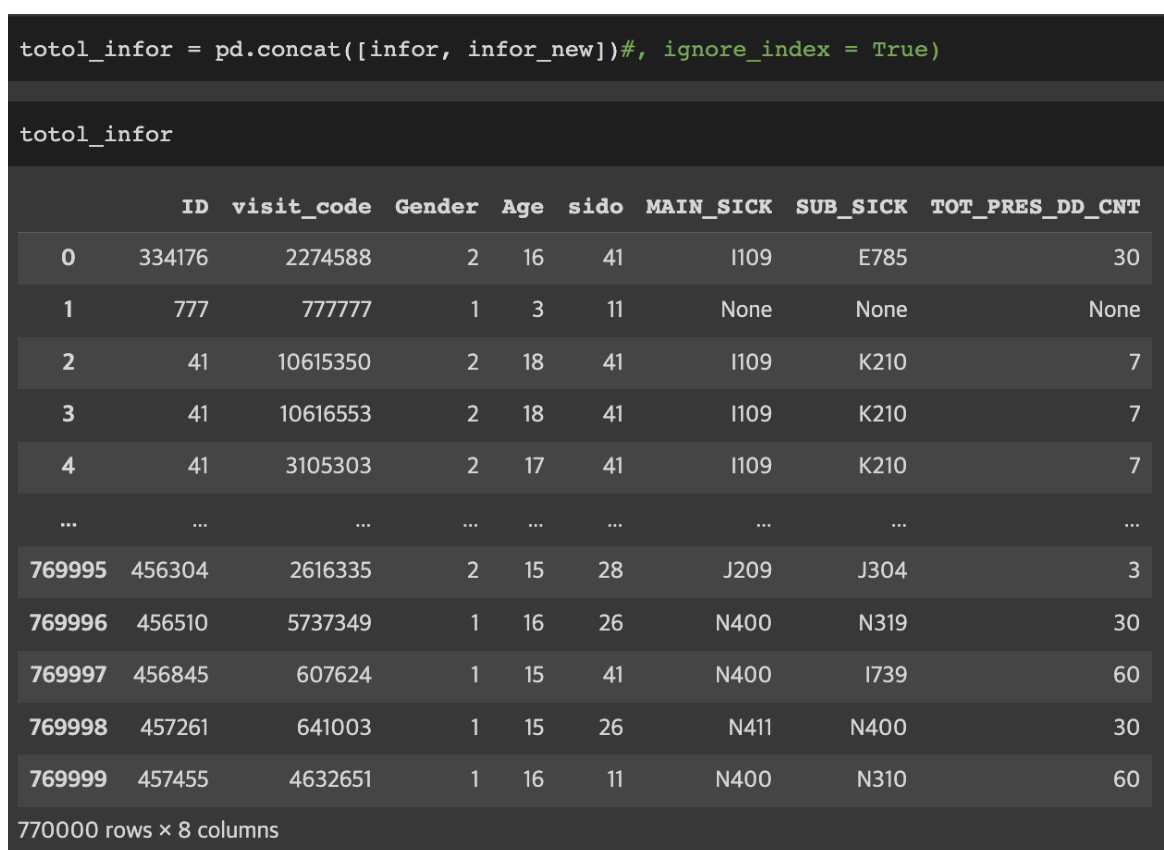
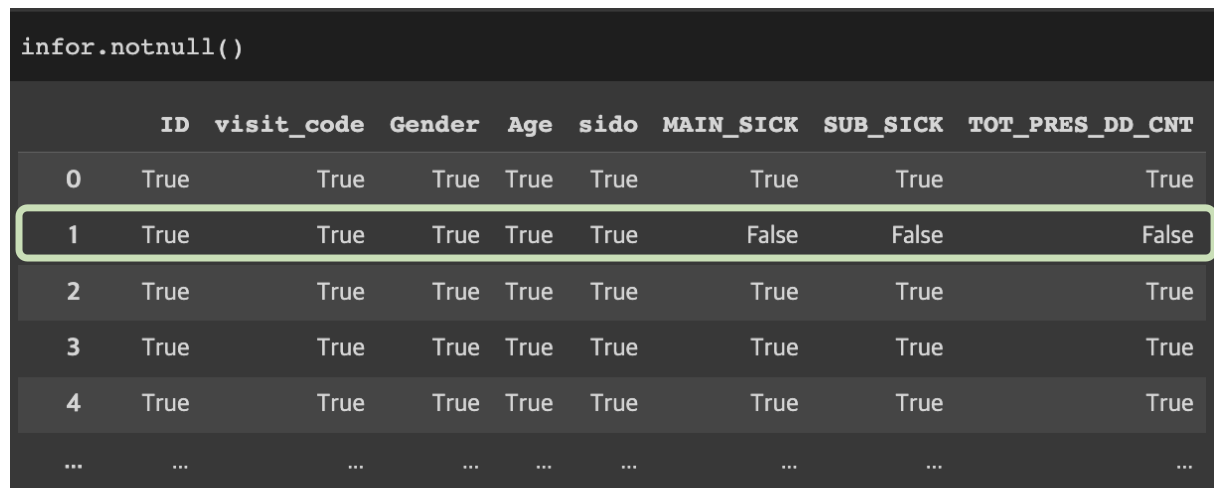
isnull():결측치확인하기
DataFrameName.isnull()
DataFrameName.notnull()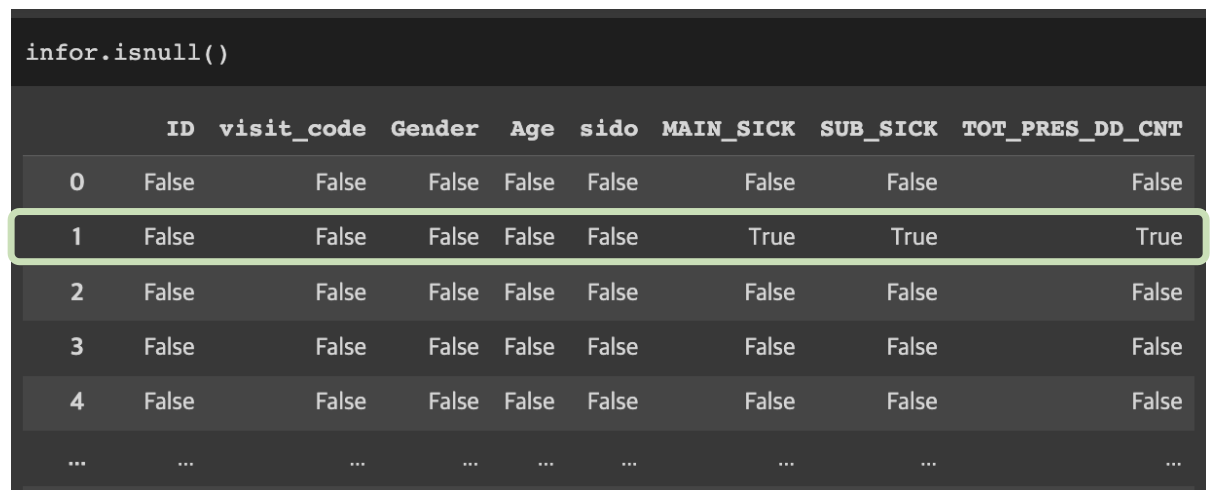
dropna: 결측치 제거 하기
DataFrameName.dropna(inplace=True)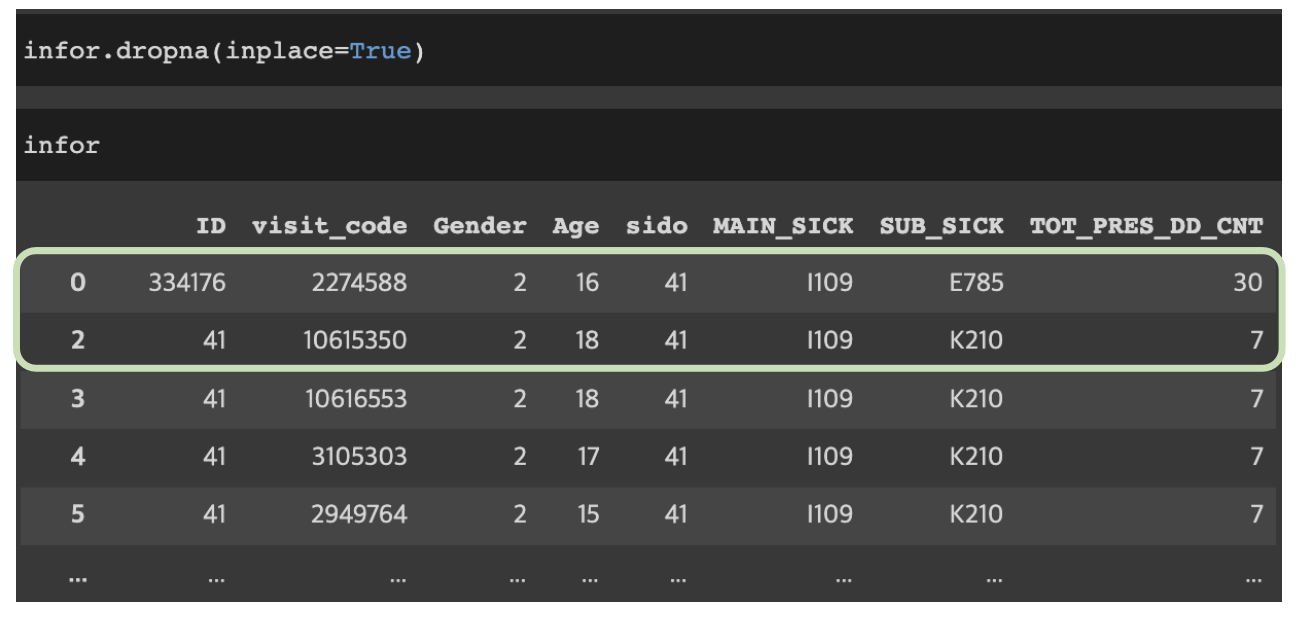
sort_values(): 오름차순 정렬하기
DataFrameName.sort_values(‘col’)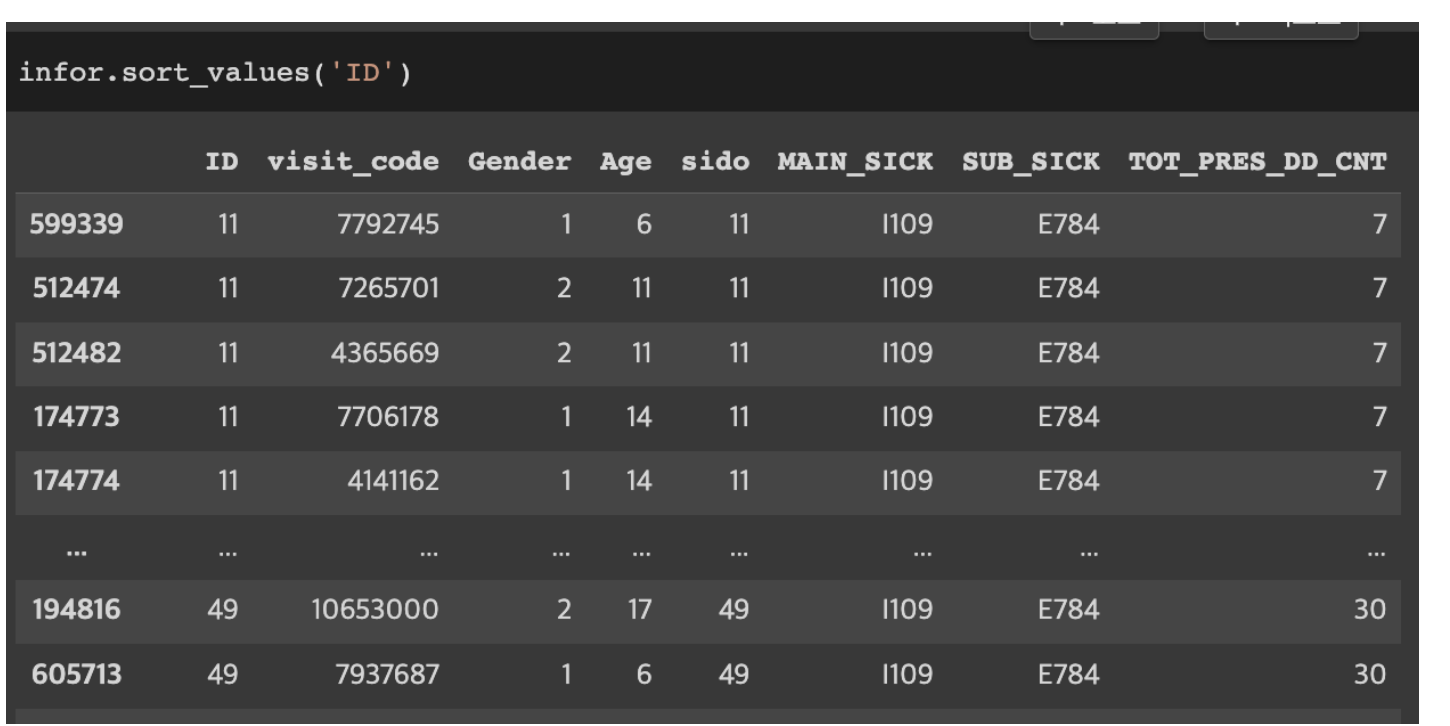
sort_values(): 내림차순 정렬하기
DataFrameName.sort_values(‘col’, ascending=False)
sort_values(): 컬럼 여러개 & 특정 컬럼만 내림차순 설정해서 정렬하기
DataFrameName.sort_values([‘col1’,’col’2,...,’coln’], ascending=[True,...,False])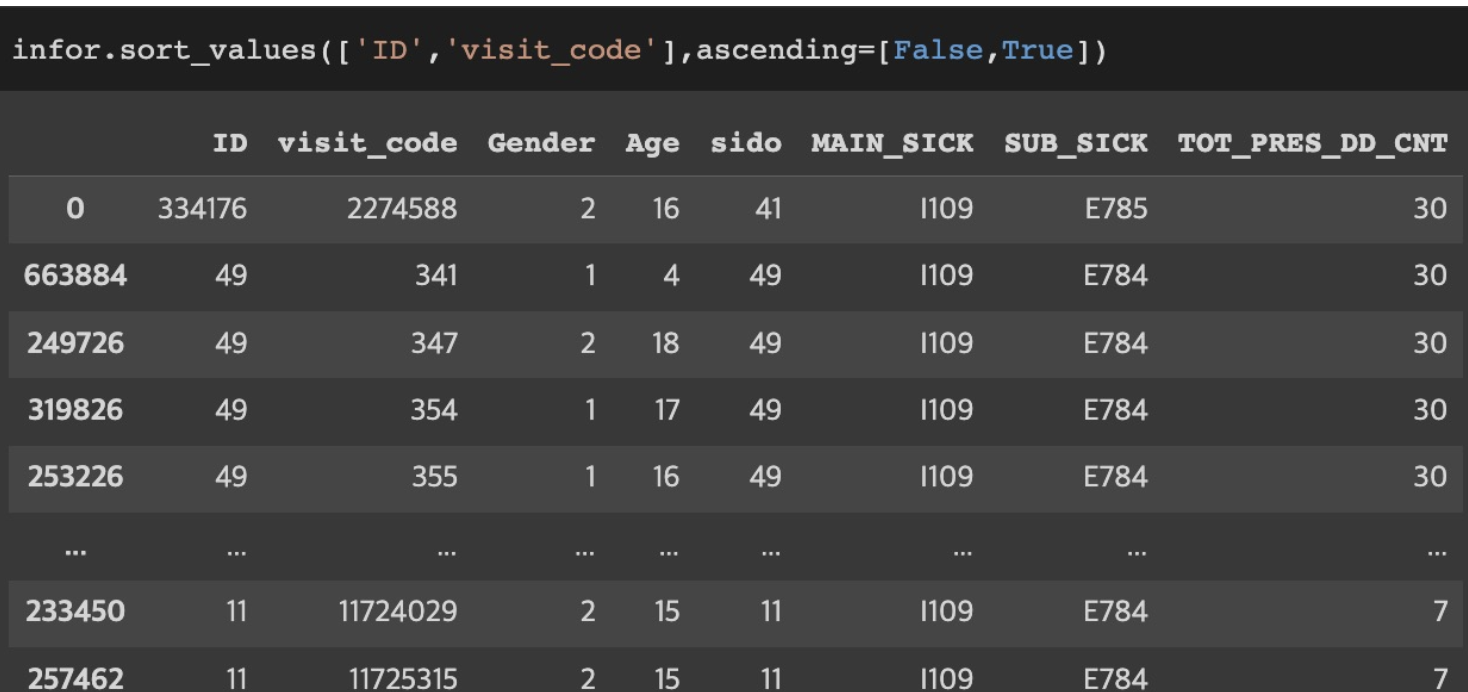
조건으로 검색하기
DataFrameName[’col1’] == 값
#== 외에 <, >,>=,<=,!= 조건 연산자 활용 가능
다중 조건으로 검색하기 & 데이터 프레임 형식으로 보기
DF[(DF[’col1’] == 값) & (DF[’col2’] > 값)]
#& 외에 |(or) 연산자 활용 가능
문자열인 경우,조건으로 검색하기
DF[DF.col1.str.match(‘문자열’)]
DF[DF[‘col1’].str.contains(‘문자열’)]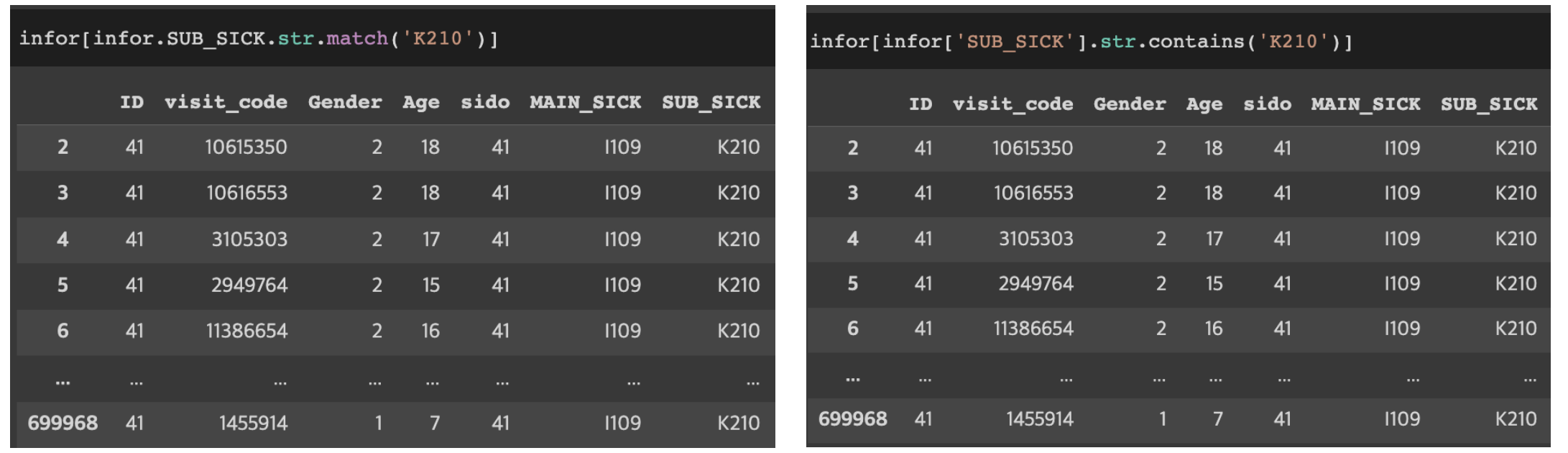
replace: 값 대체하기
DataFrameName.replace({대체될값1:대체할값1,..., 대체될값n:대체할값n},inplace=True)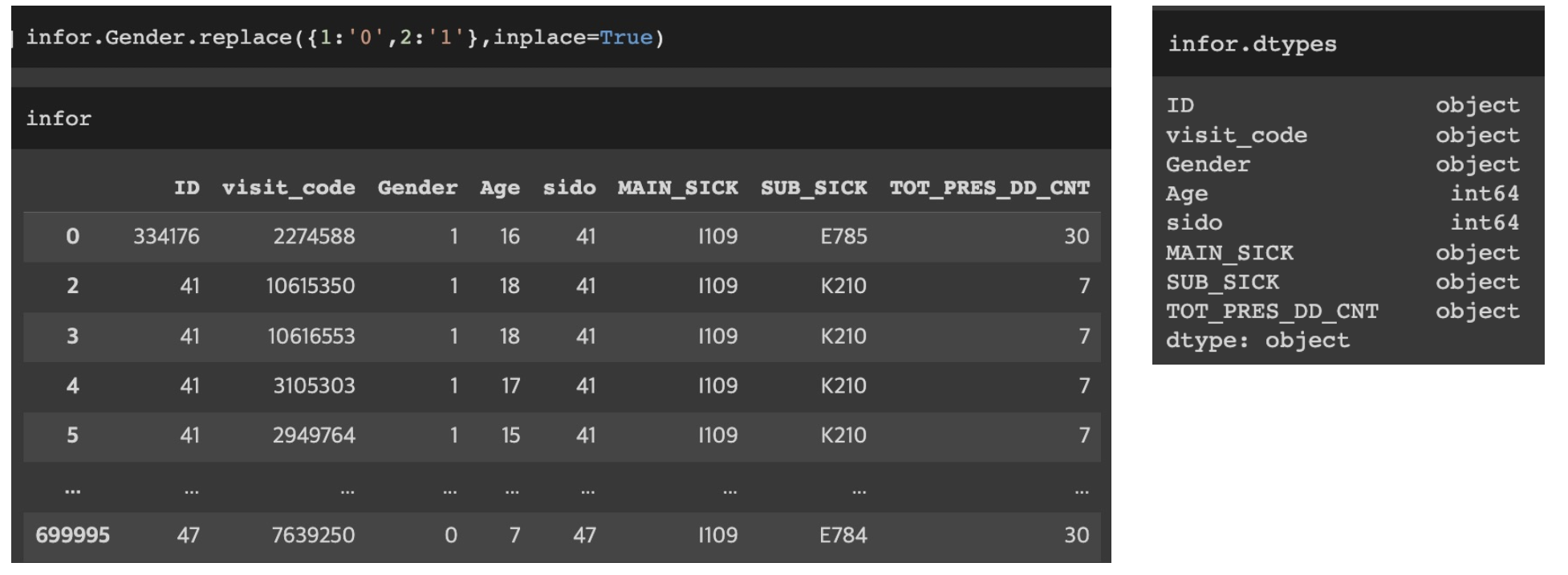
apply: 함수로 특정 열의 값 처리하기
DF[‘처리할칼럼’].apply(처리에사용할함수)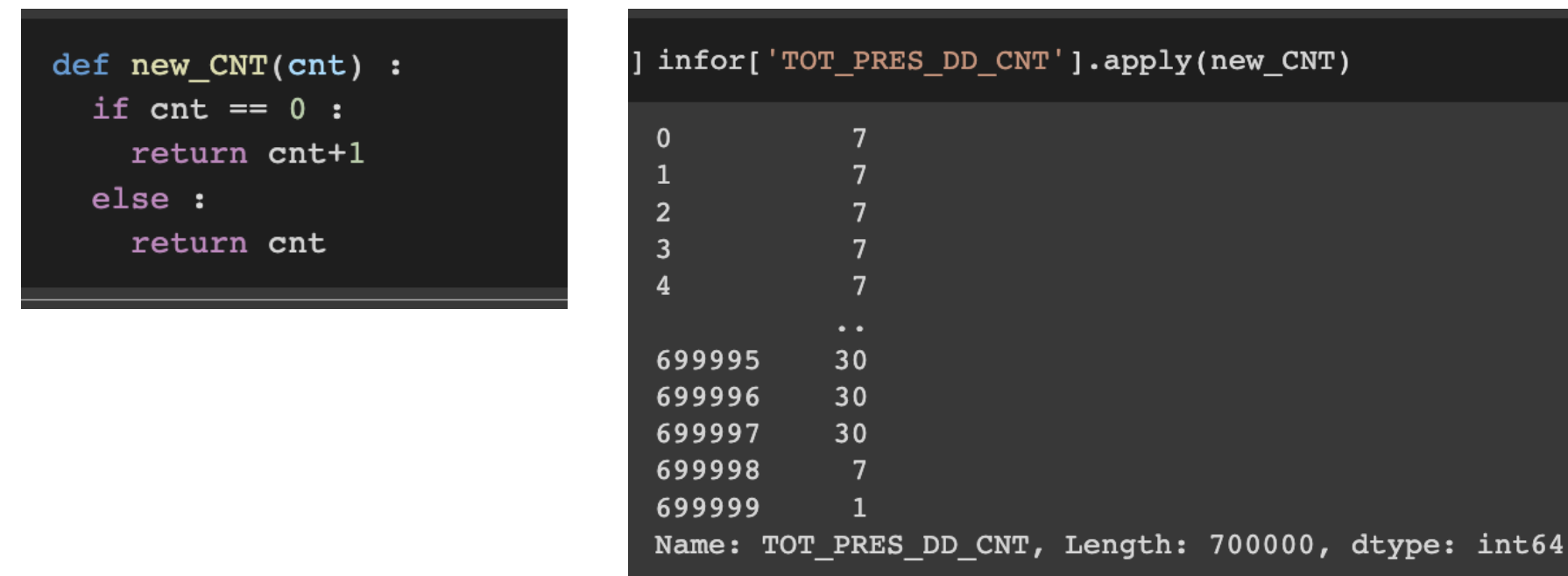
apply: 특정 열의 값에 함수를 적용하고, 해당 값을 새로운 칼럼으로 만들기
DF[‘함수가적용된새로운열’] =DF[‘처리할칼럼’].apply(처리에사용할함수)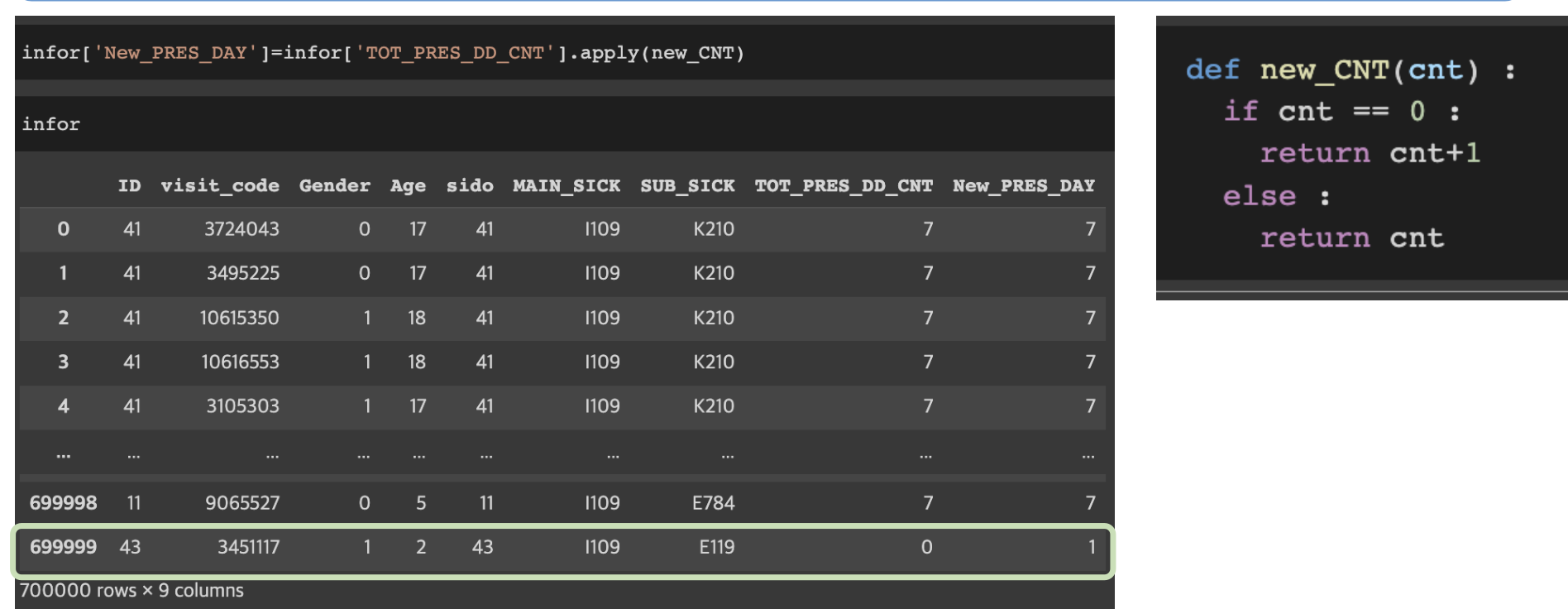
Pandas : 내장함수
집계함수
dfName[‘col_Name’].mean()
dfName[‘col_Name’].sum()
dfName[‘col_Name’].max()
dfName[‘col_Name’].min()groupby: 조건부로 집계하기
dfName[[‘col1’,...,’coln’].groupby(‘집계기준열’).mean()
dfName[[‘col1’,...,’coln’].groupby(‘집계기준열’).sum()
dfName[[‘col1’,...,’coln’].groupby(‘집계기준열’).max()
dfName[[‘col1’,...,’coln’].groupby(‘집계기준열’).min()groupby: 조건부로 집계하기 + aggregate: 통계량 여러개 내기
dfName[[‘col1’,...,’coln’].groupby(‘집계기준열’).aggregate([‘min’,’mean’,...)groupby: 조건부로 집계하기 + aggregate: 통계량여러개 + 변수별로 다른 통계량
dfName[[‘col1’,...,’coln’].groupby(‘집계기준열’).aggregate({‘col1’:‘min’,...,’coln’:’mean’})groupby: 조건부로 집계하기 + get_group: 특정 그룹 정보만 선택
dfName[[‘col1’,...,’coln’].groupby(‘집계기준열’).get_group(’col’)groupby: 조건부로 집계하기 + apply: 묶인 데이터에 함수적용
dfName[[‘col1’,...,’coln’].groupby(‘집계기준열’).apply(lambda x: x.max()-x.min())
groupby:조건부로집계하기+filter:그룹별속성으로필터링조건을담은함수적용
dfName.groupby(‘집계기준열’).filter(함수)
Pivot_table: 데이터에서 필요한 자료만 뽑아서 요약하기
dfName.pivot_table(index=’행인덱스컬럼’,column=‘열인덱스컬럼’,values=‘요약할컬럼’)
dfName.pivot_table(index=’행인덱스컬럼’,column=‘열인덱스컬럼’, values=‘요약할컬럼’,aggfunc=[‘min’,...])2. Numpy
Numpy : Numerical Python
- 숫자 배열을 효과적으로 저장하고 가공할 수 있는 라이브러리
- Array(배열) : 복합자료형 List와 비슷하지만, 배열의 규모가 클 수록 데이터 저장 및 처리에 더 효율적
- 다차원 배열 &행렬과 연산, 다양한 수학 함수를 지원
- 배열에는 동일한 자료형만 포함될 수 있다.
Numpy : 배열(Array)
• 1차원/2차원/3차원배열
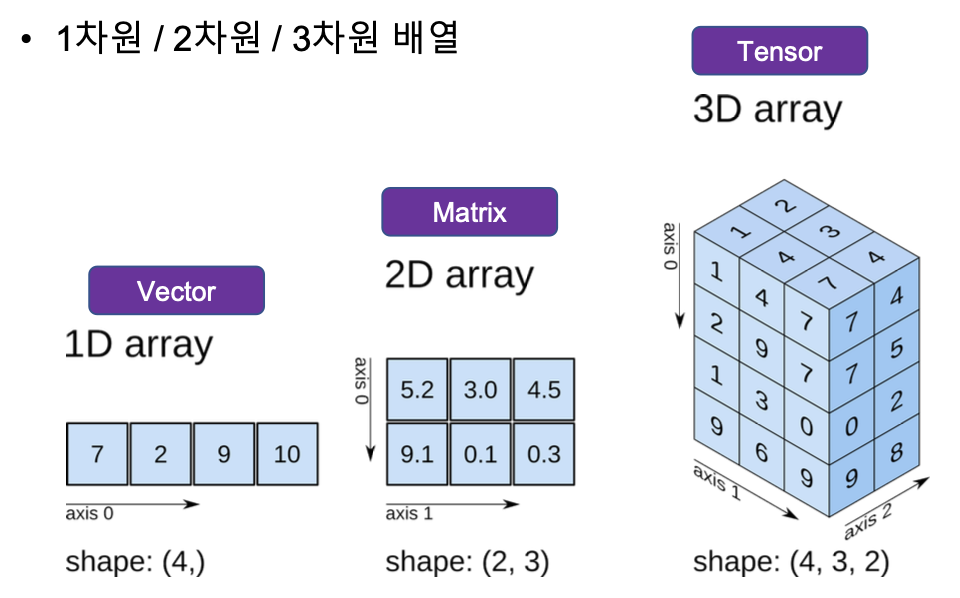
1차원 배열 선언하기
Array_Name=np.array([원소1,...,원소n])
Array_Name=np.array(리스트객체)Indexing, Slicing: List 인덱싱, 슬라이싱 규칙과 같음
Array_Name[index_number]
Array_Name[start_index_num:]
Array_Name[: end_index_num]
Array_Name[:: step_num]배열 요소의 데이터형
Array_Name.dtype특정 규칙으로 채워진 1차원 배열 선언하기
Array_Name=np.arange(시작값, 마지막값+1, step) Array_Name=np.random.random(생성할 난수 갯수)특정 규칙으로 채워진 2차원 배열 선언하기
Array_Name=np.random.random(생성할 난수 갯수, size=(행,열)) Array_Name=np.random.randint(생성할 정수 시작, 끝 수, size=(행,열))1차원 배열로 2차원 배열 만들기
Array_Name=np.reshape((행,열))
Concatenate: 1차원 배열 붙이기
Array_Name=np.concatenate([array1,array1])
Concatenate: 2차원 배열 붙이기
Matrix_Name=np.concatenate([matrix1, matrix2], axis=0) # 위아래
Matrix_Name=np.concatenate([matrix1, matrix2], axis=1) # 양 옆Split: 2차원 배열 분리하기
Matrix_Name1, Matrix_Name2=np.split(matrix, [위에 둘 행 갯수], axis=0) # 위 아래
Matrix_Name1, Matrix_Name2=np.split(matrix, [왼쪽 에 둘 열 갯수], axis=1) # 양 옆1,2차원 배열 사칙연산: 원소 각각에 적용
Array_Name + 숫자
Array_Name - 숫자
Array_Name * 숫자
Array_Name / 숫자2차원 배열 사칙연산: 행렬 간 덧셈
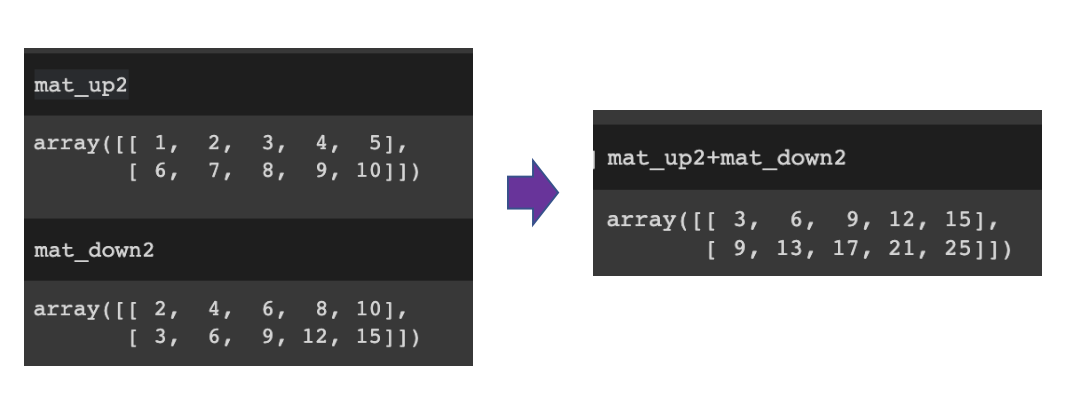
2차원 배열 BroadCasting: 행렬 간 연산
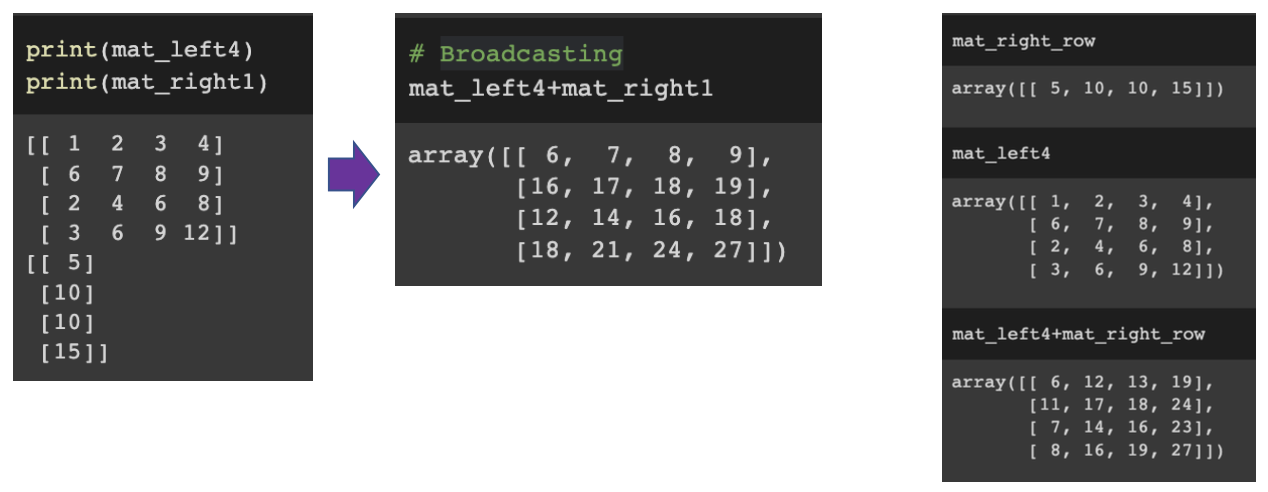
1차원 배열 집계함수
np.sum(Array_Name)
np.mean(Array_Name)
np.max(Array_Name)
np.min(Array_Name)
2차원 배열 집계함수
np.sum(Matrix_Name) #모든원소
np.mean(Matrix_Name)
np.max(Matrix_Name,axis=0) #열기준
np.min(Matrix_Name, axis=1) # 행 기준배열에 속한 원소에 조건 연산자(>,<,>=,<=,==,!=) 대입
Array_Name < 숫자
Array_Name[Array_Name < 숫자]
Matrix_Name > 숫자
Matrix_Name[Matrix_Name > 숫자]3. Matplotlibs
Matplotlib
• 시각화에 필요한 다양한 그래프 형식과 디자인 기능을 제공하는 라이브러리
• 다양한 형식의 데이터를 입력 받을 수 있지만, 넘파이 배열이 기본
• Pyplot 모듈은 MATLAB과 같은 인터페이스를 제공하고, 가장 많이 사용됨
• 그래프를 활용하면, 데이터의 구조와 패턴을 파악하기 편리하다.
- Matplotlib 라이브러리 호출
Import matplotlib.pyplot as plt- 플롯 그램과 축객체 생성
fig=plt.figure()
ax=plt.axes()- 라인 플롯 그리기
plt.plot(x,y,options....)산점도 그리기
plt.scatter(x,y,options....)
👩🏻💻