
✔ 뉴스 그룹 분류하기
- data load
# 데이터 가져오기 from sklearn.datasets import fetch_20newsgroups news_data=fetch_20newsgroups(subset='all', random_state=42) print(news_data.keys())
- 데이터 한 번 까보기
# 분포 확인 # print(pd.Series(news_data.target).value_counts().sort_index()) print(news_data.target_names) #데이터 확인 print(news_data.data[0]) print(news_data.filenames) print(news_data.target_names) print(news_data.DESCR)
- 분포 확인을 해야 한다.
- 치우쳐 진다면 층화추출, 로그변환 등을 수행해야 할 지 생각해야 한다.- 훈련 데이터 생성하기
# 실제 데이터 가져오기 # headers 나 footers, quotes를 제거하고 가져와야한다. train_news=fetch_20newsgroups(subset='train', remove=('headers','footers','quotes'), random_state=42) # 훈련 데이터 생성 X_train=train_news.data y_train=train_news.target # 실제 데이터에서 이게 없으면 군집임 print(type(X_train)) print(type(y_train))
- 피처 벡터화 : 문자열을 벡터화
- 문자열 데이터를 가지고 데이터의 개수를 기반으로 벡터화
-sklearn.feature_extraction.text.CountVectorizefrom sklearn.feature_extraction.text import CountVectorizer # 단어가 등장한 개수 기반의 벡터화를 위한 인스턴스 생성 cnt_vect=CountVectorizer() # 벡터화 cnt_vect.fit(X_train) X_train_cnt_vect=cnt_vect.transform(X_train) print(type(X_train_cnt_vect)) print(type(X_train_cnt_vect[0])) print(type(X_train_cnt_vect[0][0])) # test도 해줬어 X_test_cnt_vect=cnt_vect.transform(X_test)
- 분류 - 희소 행렬이기에 로지스틱 회귀로 분류 수행하기
from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # 모델 생성 lr_clf=LogisticRegression(max_iter=1000, solver='lbfgs') # 훈련 lr_clf.fit(X_train_cnt_vect, y_train) # 예측 pred=lr_clf.predict(X_test_cnt_vect) # 평가지표 print("정확도 : ", accuracy_score(y_test, pred))
- 피처 벡터화 할 때, TF-IDF 사용해보기
from sklearn.feature_extraction.text import TfidfVectorizer tdidf_vect=TfidfVectorizer() tdidf_vect.fit(X_train) X_train_tdidf=tdidf_vect.transform(X_train) X_test_tdidf=tdidf_vect.transform(X_test) # 모델 생성 lr_clf=LogisticRegression() # 훈련 lr_clf.fit(X_train_tdidf, y_train) # 예측 pred=lr_clf.predict(X_test_tdidf) # 평가지표 print("정확도 : ", accuracy_score(y_test, pred))
- TF-IDF parameter 추가
from sklearn.feature_extraction.text import TfidfVectorizer tfidf_vect=TfidfVectorizer(stop_words='english', ngram_range=(1,2), max_df=300) tfidf_vect.fit(X_train) X_train_tfidf=tfidf_vect.transform(X_train) X_test_tfidf=tfidf_vect.transform(X_test) # 모델 생성 lr_clf=LogisticRegression() # 훈련 lr_clf.fit(X_train_tfidf, y_train) # 예측 pred=lr_clf.predict(X_test_tfidf) # 평가지표 print("정확도 : ", accuracy_score(y_test, pred))
✔ 감성 분석
개요
- 감성 분석(Sentiment Analysis)은 문서의 주관적인 감성/의견/감정/기분 등을 파악하기 위한 방법이다.
- 문서 텍스트가 나타내는 여러 가지 주관적인 단어와 문맥을 기반으로 감성 수치를 계산합니다.
- 감성 수치는 긍정과 부정으로 나뉘며, 이들 지수를 합산해서 긍정 또는 부정으로 결정합니다.
- 지도 / 비지도 둘 다 가능
- 비지도 학습의 경우에는 영문일 때 Lexicon이라는 감성 어휘 사전을 이용
- 한국어는 Google의 BERT 나 한국에서 만든 koBERT 또는 기업에서 제공하는 pre_trained_model을 이용할 수 있습니다.
- 나이브 베이즈(확률 기반) 분류를 많이 사용합니다.
나이브 베이즈 분류기를 이용한 감성 분석
- 샘플 데이터 생성
- 직접 크롤링을 해서 수행이 가능하다
- 평점이 제공되는 경우에는 평점에 threshold 설정해서 긍정/부정 분류 가능
train=[('i like you', 'pos'), ('i do not like you', 'neg'), ('i hate you', 'neg'), ('i do not hate you', 'pos'), ('i love you' ,'pos'), ('i do not love you', 'neg')] # TF-IDF 여러 문장에서 반복적으로 나오면 좋은 것이 아니다. # 등장한 모든 단어를 찾아보자. from nltk.tokenize import word_tokenize import nltk # 단어 단위로 분할해서 등장한 단어 전부 추출해보자. # for는 앞에거 먼저 작업하고 뒤어거 보면 된다. all_words=set(word.lower() for sentence in train for word in word_tokenize(sentence[0])) print(all_words)
- 분류기 만들기
# 단어 토큰화 t=[({word:(word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train] print(t)
- model
# 텍스트 분류를 위한 나이브 베이즈 분류기를 이용해서 모델 생성 classifier=nltk.NaiveBayesClassifier.train(t) classifier.show_most_informative_features()
- predict
# 예측 test_sentence='i do not like babamba' test_sent_features={word.lower():(word in word_tokenize(test_sentence.lower())) for word in all_words} print(test_sent_features) print(classifier.classify(test_sent_features))

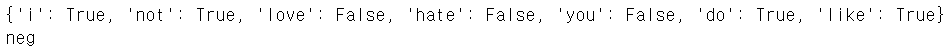
한글 감성 분석
- 한글을 이용할 때는 형태소 분석을 수행해서 품사를 같이 이용하는 것이 좋습니다.
train=[('나는 당신을 사랑합니다','긍정'),('나는 당신을 사랑하지 않습니다.', '부정'), ('나는 당신을 만나는 것이 지루합니다.', '부정'),('나는 당신을 만나는 것이 좋습니다','긍정'), ('나는 당신을 만나기를 하루종일 기다립니다.', '긍정'),('나는 노는게 좋습니다.','긍정'), ('나는 일하는 것이 싫습니다', '부정'), ('나는 비오는 날은 별로인 것 같습니다.', '부정'), ('오늘 칼퇴할 생각에 기대가 됩니다.' '긍정'), ('오늘은 야근을 해서 짜증이 납니다', '부정')] # 한글만 있다면 lower는 필요없음, 혹시 몰라서 쓰는 것이다. all_words=set(word.lower() for sentence in train for word in word_tokenize(sentence[0])) print(all_words)from konlpy.tag import Twitter twitter=Twitter() # 문장 단위로 형태소 분석기에 넣어서 # 단어와 품사를 / 로 구분해서 추출해주는 함수 def tokenize(doc): return ["/".join(t) for t in twitter.pos(doc, norm=True, stem=True)] train_docs=[(tokenize(row[0]),row[1]) for row in train] print(train_docs) # 단어만 추출해보자 tokens=[t for d in train_docs for t in d[0]] print(tokens)# 분류기 만들기 def term_exists(doc): return {word: (word in set(doc)) for word in tokens} # 모든 문장을 해석해서 단어의 존재 여부와 감성을 가진 튜플의 list 생성 train_xy=[(term_exists(d),c) for d, c in train_docs] print(train_xy)classifier=nltk.NaiveBayesClassifier.train(train_xy) classifier.show_most_informative_features()test_sentence=[('나는 오늘 비가와서 카페에 가질 못할 것 같아')] test_docs=twitter.pos(test_sentence[0]) test_sent_features={word:(word in tokens) for word in test_docs} print(classifier.classify(test_sent_features))
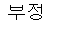
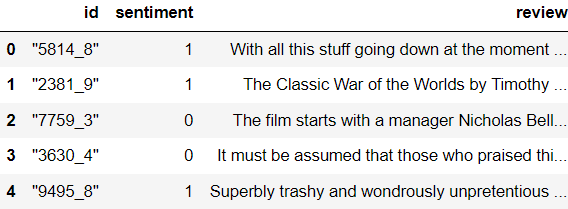
IMDB 영화평 데이터를 이용한 지도학습 기반 감성 분석
- 데이터 로드
review_df=pd.read_csv('./data/IMDB/labeledTrainData.tsv',header=0, sep='\t',quoting=3) print(review_df.head()) review_df.info() # id는 review를 구분하기 위한 데이터 # sentiment가 감성인데, 1이면 긍정 2이면 부정 # review가 review 데이터
- 데이터 전처리(정규표현식)
# 정규식을 이용해서 불필요한 데이터 제거하기 import re # 개행문자로 쓰인 html 태그를 공백문자로 review_df['review']=review_df['review'].str.replace('<br />',' ') # 영어 대소문자 아닌 애들은 공백으로, 그 이외는 그대로 review_df['review']=review_df['review'].apply(lambda x: re.sub('[^a-zA-Z]',' ',x)) review_df.head()
# 훈련 데이터와 테스트 데이터 분할 from sklearn.model_selection import train_test_split # 감정이 타겟 class_df=review_df['sentiment'] # 리뷰가 특징 feature_df=review_df.drop(['id','sentiment'],axis=1,inplace=False) X_train,X_test,y_train,y_test=train_test_split(feature_df,class_df,test_size=0.3, random_state=42) print(X_train.shape) print(X_test.shape) print(y_train.shape) print(y_test.shape)# 훈련 및 예측을 해보자 from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer from sklearn.pipeline import Pipeline from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, roc_auc_score pipeline=Pipeline([ ('cnt_vect', CountVectorizer(stop_words='english', ngram_range=(1,2) )), ('lr_cls', LogisticRegression(C=10)) ]) pipeline.fit(X_train['review'],y_train) pred=pipeline.predict(X_test['review']) pred_probs=pipeline.predict_proba(X_test['review'])[:,1] print('정확도 : ', accuracy_score(y_test,pred)) print('ROC_AUC : ',roc_auc_score(y_test,pred_probs))
# TF-IDF훈련 및 예측을 해보자 from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer from sklearn.pipeline import Pipeline from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, roc_auc_score pipeline=Pipeline([ ('cnt_vect', TfidfVectorizer(stop_words='english', ngram_range=(1,2) )), ('lr_cls', LogisticRegression(C=10)) ]) pipeline.fit(X_train['review'],y_train) pred=pipeline.predict(X_test['review']) pred_probs=pipeline.predict_proba(X_test['review'])[:,1] print('정확도 : ', accuracy_score(y_test,pred)) print('ROC_AUC : ',roc_auc_score(y_test,pred_probs))
- 확실히 영문은 TF-IDF 벡터화가 더 좋은 성능을 가진다.

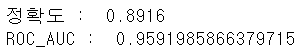
비지도 학습 기반의 감성 분석
- 감성 분석 사전을 이용합니다.
- 영문은 Lexicon 이라는 사전이 존재함
- 한글은 따로 없어서 Bert, koBert, 기업체 pre_trained_model등..
네이버 식당리뷰 데이터 기반 한글 지도학습 기반의 감성 분석
- score
- 평점 - review
- 사용자 리뷰 - y
- 감성
- score >= 4 then 1(긍정) else 0(부정)
# 데이터 불러오기 df=pd.read_csv('./data/review_data.csv') df.head() # 레이블이 있으니 지도 학습이다.# 한글 데이터만 뽑아보자. import re def text_cleaning(text): kor=re.compile('[^ㄱ-ㅣ 가-힣]') result=kor.sub('',text) return result df['ko_text']=df['review'].apply(lambda x:text_cleaning(x)) del df['review'] df.head()
- 형태소 분석, 이제는 Twitter가 아닌 Okt
from konlpy.tag import Okt def get_pos(x): tagger=Okt() pos=tagger.pos(x) pos=['{}/{}'.format(word,tag) for word, tag in pos] return pos result=get_pos(df['ko_text'][0]) print(result)
- 피처 벡터화를 해두자
from sklearn.feature_extraction.text import CountVectorizer index_vectorizer=CountVectorizer(tokenizer=lambda x : get_pos(x)) X=index_vectorizer.fit_transform(df['ko_text']) print(X.shape)
- tf-idf
from sklearn.feature_extraction.text import TfidfTransformer tfidf_vectorizer=TfidfTransformer() X=tfidf_vectorizer.fit_transform(X) print(X.shape) print(X[0]) # 가중치로 나오네 tfdif는
- train/test dataset
from sklearn.model_selection import train_test_split y=df['y'] X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3, random_state=42) print(X_train.shape) print(X_test.shape)
- 훈련 및 평가
from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score lr=LogisticRegression(random_state=42) lr.fit(X_train, y_train) y_pred=lr.predict(X_test) y_pred_proba=lr.predict_proba(X_test)[:1] print('정확도 : ', accuracy_score(y_test,y_pred)) print('precision : ', precision_score(y_test,y_pred)) print('recall : ', recall_score(y_test,y_pred)) print('f1 : ', f1_score(y_test,y_pred))
- 뭔가 이상한데
from sklearn.metrics import confusion_matrix conf_matrix=confusion_matrix(y_true=y_test, y_pred=y_pred) # 전부 1로 예측 print(conf_matrix)
- 전부 1로 예측한다.
- ROC_AUC 값을 그래드로 출력 했을 때
- 특정 시점에서 곡선이 만들어지지 않고 계단 처럼 보이는 현상 발생
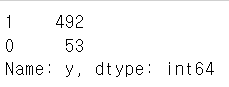
- 이런 경우는 대부분 데이터 불균형 문제가 많음df['y'].value_counts() # 10배 차이가 난다
- 오버샘플링보다는 언더 샘플링을 하는게 더 좋아보임
positive_random_idx=df[df['y']==1].sample(50,random_state=24).index.tolist() negative_random_idx=df[df['y']==0].sample(50,random_state=24).index.tolist() random_idx=positive_random_idx+negative_random_idx sample_X=X[random_idx, :] y=df['y'][random_idx] X_train,X_test,y_train,y_test=train_test_split(sample_X,y,test_size=0.3, random_state=42)# 다시 평가하기 lr=LogisticRegression(random_state=42) lr.fit(X_train, y_train) y_pred=lr.predict(X_test) y_pred_proba=lr.predict_proba(X_test)[:1] print('정확도 : ', accuracy_score(y_test,y_pred)) print('precision : ', precision_score(y_test,y_pred)) print('recall : ', recall_score(y_test,y_pred)) print('f1 : ', f1_score(y_test,y_pred)) conf_matrix=confusion_matrix(y_true=y_test, y_pred=y_pred) # 오차행렬 - 이제 좀 나오기 시작한다 print(conf_matrix)


- 크롤링해서 데이터를 만드는 경우에, 데이터의 비율을 맞추는 것이 중요하다.
- 리뷰의 경우는 긍정적인 리뷰가 많습니다.
- 부정적인 데이터가 부족해서 감성 분류를 하게 된다면 부정이 나오는 경우가 드뭅니다.
- 정확도는 높게 나올 가능성이 높습니다.
✔ 토픽 모델링
개요
- 문서 집합에 숨어있는 주제를 찾아내는 것
- 머신러닝 기반의 토픽 모델은 숨겨진 주제를 효과적으로 표현할 수 있는 중심 단어를 함축적으로 추출함
- 군집처럼 몇 개로 분류할 것인지를 설정하면 그룹을 나누어서 중심 단어를 찾아줍니다.
- sklearn에서는 LDA(Latent Dirichlet Allocation) 기반의 토픽 모델링을 수행해주는
LatentDirichletAllocation클래스 제공 - 중요 단어를 추출하기 때문에, 개수 기반의 피처 벡터화만 이용해도 됩니다.
차원축소
- 피처 선택
- 중요한 피처만 선택 - 새로운 피처 추출
- 여러 개의 피처의 상관관계를 확인해서 여러 개의 피처에서 작은 개수의 피처를 추출하는 것(이것이 주성분 분석)
- 토픽 모델링
from sklearn.datasets import fetch_20newsgroups from sklearn.feature_extraction.text import CountVectorizer from sklearn.decomposition import LatentDirichletAllocation # 데이터를 가져올 카테고리 설정 cats=['rec.motorcycles','rec.sport.baseball','comp.graphics','comp.windows.x', 'talk.politics.mideast','soc.religion.christian','sci.electronics', 'sci.med'] # 카테고리에 해당하는 데이터만 가져오기 news_df=fetch_20newsgroups(subset='all',remove=('headers','footers','quotes'), categories=cats,random_state=42)#LDA 는 Count기반의 Vectorizer만 적용합니다. count_vect = CountVectorizer(max_df=0.95, max_features=1000, min_df=2, stop_words='english', ngram_range=(1,2)) feat_vect = count_vect.fit_transform(news_df.data) print('CountVectorizer Shape:', feat_vect.shape)#토픽의 개수는 8개 lda = LatentDirichletAllocation(n_components=8, random_state=0) lda.fit(feat_vect) print(lda.components_.shape)
- 각 토픽에서 중요한 10개 단어 추출하기
# 각 토픽에서 중요한 10개 단어 추출하기 def display_topics(model, feature_names, no_top_words): for topic_index, topic in enumerate(model.components_): print('Topic #',topic_index) # components_ array에서 가장 값이 큰 순으로 정렬했을 때, #그 값의 array index를 반환. topic_word_indexes = topic.argsort()[::-1] top_indexes=topic_word_indexes[:no_top_words] # top_indexes대상인 index별로 feature_names에 #해당하는 word feature 추출 후 join으로 concat feature_concat = ' '.join([feature_names[i] for i in top_indexes]) print(feature_concat)#sklearn 의 최신 버전에서 get_feature_names 함수가 없어지고 # count_vect.get_feature_names_out으로 변경되었습니다 feature_names=count_vect.get_feature_names_out() display_topics(lda, feature_names, 15)

✔ 군집
문서의 군집
- 일반 군집과 알고리즘 자체는 동일하지만, 문장을 가지고 하기 때문에 피처 벡터화를 수행하고, 거리를 계산해서 수행한다는 것이 다른 점이다.
실습

밀가루 귀여워요