
✔ XG Boost
- Gradient Boosting Machine에 기반을 하고 있는데, 느린 학습 시간과 과적합 규제 부재 등의 문제를 해결한 알고리즘
- 병렬 학습이 가능함
장점
- 예측 성능이 뛰어남
- GBM 대비 빠른 수행 시간
- 과적합 규제가 가능
- GBM에서는 max_depth 로 분할의 깊이를 조절하는데 XG Boost에서는 max_depth를 이용한 방법이 가능하고 tree pruning(가지 치기) 으로 더 이상 긍정 이득이 없는 분할을 가지치기를 해서 분할 수를 더 줄이는 기능
- 자체 내장된 교차 검증
- 결측값 자체 처리
설치
conda install -c anaconda py-xgboost
하이퍼 파라미터 분류
- 일반 파라미터
- 스레드의 개수나 silent 모드 등의 선택을 위한 파라미터로 거의 기본값을 수정하지 않고 사용 - 부스트 파라미터
- 트리 최적화, 부스팅, regularzation 등과 같은 파라미터 - 학습 태스크 파라미터
- 평가 지표 등을 설정하는 파라미터
일반 파라미터
- booster
- gbtree나 gblinear로 설정하는 것인데 기본은 gbtree - silent
- 출력 메시지 설정으로 1을 설정하면 메시지 출력 X - nthread
- 동시에 수행할 스레드의 개수로, 기본적으로 -1이라서 코어 수만큼 사용
- 프로세서의 일부 코어만을 사용하고자 하는 경우, 설정을 변경
부스트 파라미터
- learning_rate
- 0 ~ 1 사이의 값으로 설정, 학습률이 높으면 최적으로 수렴되지 않을 가능성이 높아지고, 낮다면 훈련시간이 오래 걸릴 수 있습니다.
- 기본값은 0.1인데, 0.1이나 0.2정도를 많이 사용 - num_boost_rounds
- n_estimators와 같은 파라미터 - min_child_weight
- 기본값은 1인데, 트리에서 추가적으로 가지를 나눌지를 결정하기 위해 필요한 데이터들의 weight 총합으로, 값이 크면 클수록 분할을 자제 - gamma
- 트리의 leaf node를 추가적으로 나눌 지를 결정할 최소 손실 감소 값으로 해당 값보다 큰 손실이 감소된 경우에 leaf node를 분할합니다.
- 이 값을 크게 설정하면 overfitting 감소 효과가 발생
- 기본값은 0 - math_depth
- 기본값은 6
- 값이 높다면, 특정 feature 조건에 맞는 규칙이 만들어지기에 overfitting 가능성이 높아지기에 3 ~ 10 정도 사이 - sub_sample
- 훈련을 할 때 사용하는 데이터의 비율
- 기본값은 1인데, 1이면 데이터 전체를 사용하겠다는 의미이고, 일반적으로는 0.5~1.0 사이의 값을 사용 - colsample_bytree
- 트리 생성에 필요한 feature를 임의로 샘플링하는데, 그 때 사용되는 feature의 비율로 기본값은 1 - lambda
- L2 규제값, 기본값은 0
- 이 값을 크게 설정하면 overfitting이 감소할 가능성이 높음 - alpha
- L1 규제값, 기본값은 0
- 이 값을 크게 설정하면 overfitting이 감소할 가능성이 높음 - scale_pos_weight
- 기본값은 0
- 특정 값으로 치우친 비대칭한 클래스로 구성된 데이터 세트의 균형을 유지하기 위한 파라미터
학습 Task 파라미터
- objective : 손실 함수를 정의
- binary : logistic은 이진 분류일 때 설정
- multi : softmax는 다중 분류일 때 설정하는데, 이 경우에는 num_class 파라미터를 이용해서 클래스의 개수를 설정해야 합니다.
- multi : softporb는 다중 분류일 때 설정하는데, 개별 클래스의 확률을 반환 - eval_metric : 검증에 사용하는 함수, 회귀는 기본 rmse 분류는 error
- rmse : Root Mean Square Error
- mse : Mean Square Error
- logloss : Negative log likelihood
- error : 이진 분류일 때 에러율(0.5가 임계치)
- merror : 다중 분류일 때 에러율
- mlogloss : 다중 분류일 때 log loss
- auc
과적합 문제가 심각한 경우
- 학습률을 낮추기
- num_round(n_estimators)를 높이기
- max_depth 낮추기
- min_child_weight 높이기
- gamma 높이기
- subsample과 colsample_bytree를 조정
sklearn에서는 XGBClassifier와 XGBRegressor 클래스 제공
- 별도로 xgboost 패키지에서도 제공
conda install -c anaconda py-xgboostcmd 설치
위스콘신 유방암 데이터 세트에 XGBoost 사용
- 이 데이터는 이미지 데이터 이지만, 이미지 데이터를 숫자 데이터로 변환해 놓은 것
- data load
from sklearn.datasets import load_breast_cancer dataset=load_breast_cancer() X_features=dataset.data y_label=dataset.target cancer_df=pd.DataFrame(data=X_features,columns=dataset.feature_names) cancer_df['target']=y_label cancer_df.head()# 데이터 분포 확인 # 이 비율이 치우치면 층화추출 or 가중치 적용 print(cancer_df['target'].value_counts()) # 학습 / 훈련 데이터 분할 X_train,X_test, y_train, y_test=train_test_split(X_features,y_label, test_size=0.1, random_state=42) print(X_train.shape) print(X_test.shape) print(y_train.shape) print(y_test.shape)# XGBoost를 이용하는 경우의 데이터 생성 # 시각화나 그런게 다 내장되어있음 import xgboost as xgb dtrain=xgb.DMatrix(data=X_train, label=y_train) dtest=xgb.DMatrix(data=X_test,label=y_test)
- hyper parameter
# 하이퍼 파라미터 params={ 'max_depth':3, 'eta':0.1,#학습률 'objective':'binary:logistic', 'eval_metric':'logloss' } num_rounds=400 # 훈련 데이터와 검증 데이터 생성 wlist=[(dtrain,'train'),(dtest,'eval')] # 모델 생성 xgb_model=xgb.train(params=params, dtrain=dtrain, num_boost_round=num_rounds, early_stopping_rounds=100, # 조기종료 옵션 evals=wlist) # 예측 pred_probs=xgb_model.predict(dtest) print(pred_probs[:10])# 확률을 가지고 실제 클래스를 예측 preds=[1 if x>0.5 else 0 for x in pred_probs] print(preds[:10])
- model evaluate
# 평가 지표 from sklearn.metrics import confusion_matrix,accuracy_score from sklearn.metrics import precision_score,recall_score from sklearn.metrics import f1_score,roc_auc_score # roc_acu가 참 중요하다. # 오차 행렬 confusion=confusion_matrix(y_test,preds) print(confusion) # 정확도 accuracy=accuracy_score(y_test,preds) print('정확도 : ',accuracy) # 정밀도 # 실제 true중에 true로 판정한 비율 # 잘못 검색되면 안되는 경우에 중요함 precision=precision_score(y_test,preds) print('정밀도 : ',precision) # 재현율 # true로 판정한 것 중에 실제 true 비율 # 정보 검색에서 중요함 recall=recall_score(y_test,preds) print('재현율 : ',recall) # f1_score # 정밀도와 재현율의 조화 평균 # 데이터가 불균형 할 떄 중요 f1=f1_score(y_test,preds) print('f1_score : ',f1) # roc_auc # 확률을 넘겨줘야해 roc_auc=roc_auc_score(y_test,preds) print('roc_auc_score : ',roc_auc)
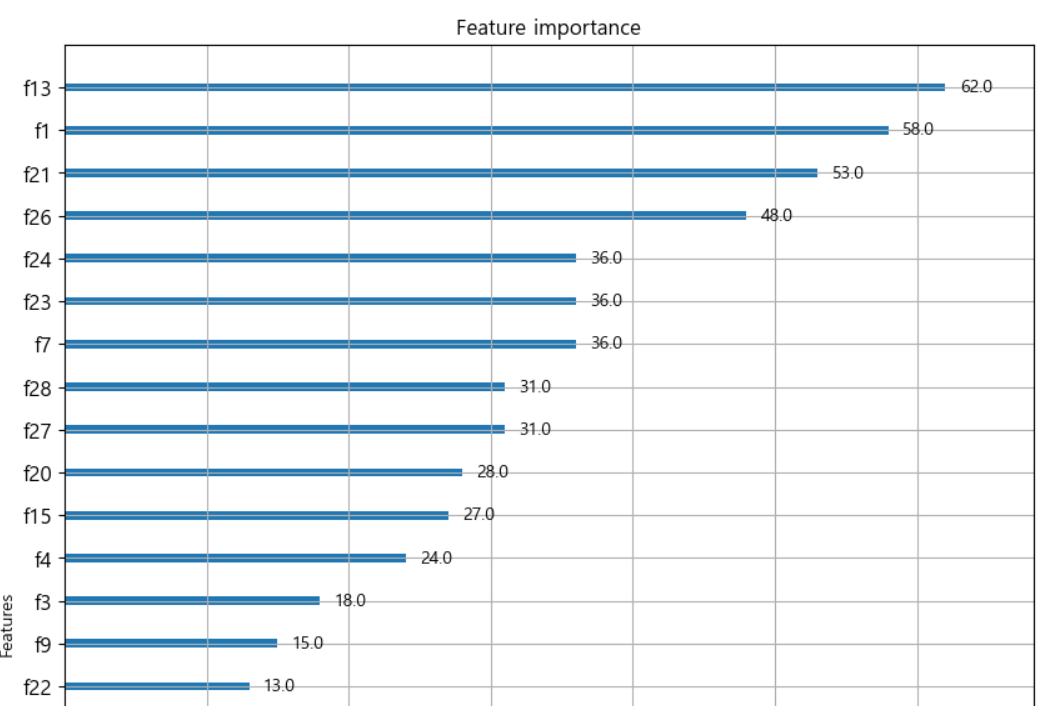
# feature의 중요도 확인 from xgboost import plot_importance fig, ax=plt.subplots(figsize=(10,12)) plot_importance(xgb_model,ax=ax)
- 트리 기반이라서 to_graphviz() API를 이용해서 시각화 가능
- cv() API를 이용해서 교차검증도 가능

✔ Light GBM
- XGBoost는 매우 뛰어난 부스팅 알고리즘이지만 학습 시간이 오래 걸림
- GridSearchCV로 하이퍼 파라미터 튜닝을 하면 수행 시간이 아주 오래 걸림
- GBM이나 XGBoost보다는 학습에 걸리는 시간이 적고, 메ㅗ리 사용량도 상대적으로 적으면서도 거의 성능 차이가 없는 알고리즘
- Light GBM은 적은 데이터 세트(10,000건 이하)에서는 Overfitting이 많이 발생함
- 일반적인 GBM이 시간이 오래 걸리는 이유
- balanced tree를 만들려고 하기 때문에 균형을 맞추는 시간이 오래 걸리는 것
- 하지만 light GBM은 leaf 중심의 알고리즘이기에 빠르다. - 기본제공 패지키가 아니라서 설치를 해야 합니다.
-conda install -c conda-forge lightgbm
-pip install lightgbm - 대부분의 하이퍼 파라미터는 GBM과 유사함
boosting hyper parameter
- 부스팅 트리를 생성하는 알고리즘을 기술
- gbdt
- 그라디언트 부스팅(트리를 연결)과 동일 - rf
- 랜덤 포레스트(깍각의 트리가 독립) 동시에 학습가능
위스콘신 유방암 데이터에 LightGBM 적용
from lightgbm import LGBMClassifier # 예측기의 개수를 400으로 해서 lightgbm 모델 생성 lgbm_clf=LGBMClassifier(n_estimators=400) # 평가 데이터를 생성 evals=[(X_test,y_test)] # lgbm_clf.fit(X_train,y_train,early_stopping_rounds=100, # eval_metric='logloss',eval_set=evals,verbose=True) # # 훈련 lgbm_clf.fit(X_train,y_train,eval_metric='logloss',eval_set=evals)preds=lgbm_clf.predict(X_test) pred_proba=lgbm_clf.predict_proba(X_test)[:,1] print(preds[:10]) print(pred_proba[:10])# 평가 지표 from sklearn.metrics import confusion_matrix,accuracy_score from sklearn.metrics import precision_score,recall_score from sklearn.metrics import f1_score,roc_auc_score # roc_acu가 참 중요하다. # 오차 행렬 confusion=confusion_matrix(y_test,preds) print(confusion) # 정확도 accuracy=accuracy_score(y_test,preds) print('정확도 : ',accuracy) # 정밀도 # 실제 true중에 true로 판정한 비율 # 잘못 검색되면 안되는 경우에 중요함 precision=precision_score(y_test,preds) print('정밀도 : ',precision) # 재현율 # true로 판정한 것 중에 실제 true 비율 # 정보 검색에서 중요함 recall=recall_score(y_test,preds) print('재현율 : ',recall) # f1_score # 정밀도와 재현율의 조화 평균 # 데이터가 불균형 할 떄 중요 f1=f1_score(y_test,preds) print('f1_score : ',f1) # roc_auc # 확률을 넘겨줘야해 roc_auc=roc_auc_score(y_test,preds) print('roc_auc_score : ',roc_auc)
- 별 차이가 없다
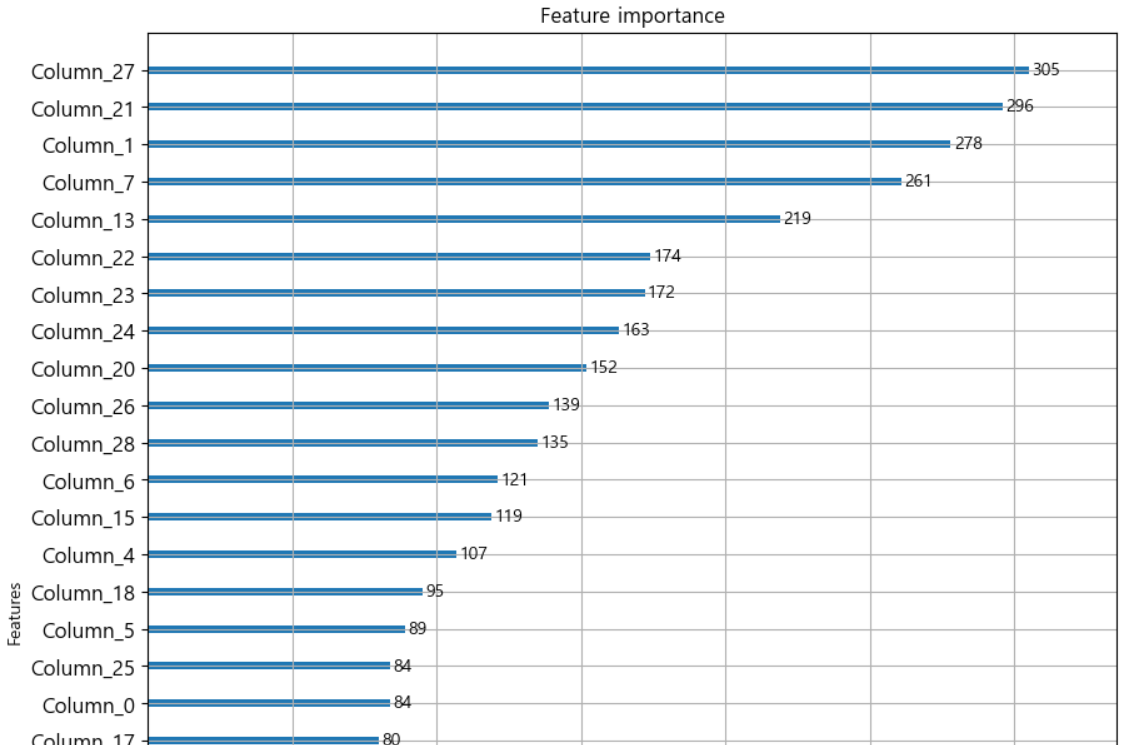
# feature의 중요도 확인 from lightgbm import plot_importance fig, ax=plt.subplots(figsize=(10,12)) plot_importance(lgbm_clf,ax=ax)
- 중요도를 평가하는 값은 좀 다르다.
✔ Stacking
개요
- 여러 모델을 한꺼번에 훈련시키자는 생각에서 등장
- 개별 알고리즘의 예측 결과 데이터 세트를 모아서 최종적인 메타 데이터 세트로 만들고 이를 별도의 ML 알고리즘으로 최종 학습을 수행하고 테스트 데이터를 기반으로 다시 최종 예측을 수행하는 방식
- 여러 개의 예측기가 예측한 내용을 가지고 다시 예측
- 결과를 가지고 예측하는 예측기를
블랜더라고 하는데, 블랜더를 학습하는 방법은홀드 아웃이다. - Stacking은 2종류의 모델이 필요하다
- 하나는 개별적인 기반 모델이고, 이들이 예측한 데이터를 가지고 최종학습하는 모델 - sklearn에서는 스태킹 지원안해서 직접 구현하거나 오픈 소스를 이용해서 구현
위스콘신 유방암 데이터로 개별훈련기와 stacking의 차이를 학습
import numpy as np from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import AdaBoostClassifier from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 데이터 생성 cancer_data=load_breast_cancer() X_data=cancer_data.data y_label=cancer_Data.target X_train,X_test,y_train,y_test=train_test_split(X_data,y_label, test_size=0.2, random_state=26)# 개별 모델 생성 knn_clf=KNeighborsClassifier(n_neighbors=4) dt_clf=DecisionTreeClassifier() rf_clf=RandomForestClassifier(n_estimators=100,random_state=26) ada_clf=AdaBoostClassifier(n_estimators=100) # 최종 모델 생성 lr_final_clf=LogisticRegression(C=10)# 개별 모델 훈련 knn_clf.fit(X_train,y_train) dt_clf.fit(X_train,y_train) rf_clf.fit(X_train,y_train) ada_clf.fit(X_train,y_train)# 개별 훈련기의 정확도 측정 knn_pred=knn_clf.predict(X_test) dt_pred=dt_clf.predict(X_test) rf_pred=rf_clf.predict(X_test) ada_pred=ada_clf.predict(X_test) print("KNN의 정확도 : ", accuracy_score(y_test,knn_pred)) print("Decision Tree의 정확도 : ", accuracy_score(y_test,dt_pred)) print("Random Forest의 정확도 : ", accuracy_score(y_test,rf_pred)) print("AdaBoost의 정확도 : ", accuracy_score(y_test,ada_pred))
# 모델이 예측한 결과를 가지고 새로운 데이터를 생성 pred=np.array([knn_pred,dt_pred,rf_pred,ada_pred]) # print(pred.shape) # 행렬 전치 pred=np.transpose(pred) print(pred.shape)# 결과를 가지고 다시 훈련하기 lr_final_clf.fit(pred,y_test) final_pred=lr_final_clf.predict(pred)print("최종 모델의 정확도 : ", accuracy_score(y_test, final_pred)) # random_state를 바꿔볼래? # data마다 조금씩 다른데 최종 모델이 엄청 더 좋네용
- 실행을 해보면 stacking 모델이 개별 모델보다 더 나쁘게 나오는 경우는 거의 없음
- 테스트 비율을 수정하거나 random_state의 값을 수정하면서 비교해보자.

✔ 범주형 데이터 feature를 이용한 이진 분류
개요
미션
- 범주형 데이터를 이용해서 Target값에 속할 확률을 예측하자
- 문제 유형
- 이진분류 - 평가 지표
- ROC AUC - 데이터 크기
- 64.8MB - 데이터
- 인위적으로 만든 데이터 : 사전 지식이 없음
- 각 feature와 target에 대한 의미를 제공하지 않음
- 제공되는 데이터는 모두 범주형이다.
- bin : 이진 feature
- nom : 명목형 feature - 순서 의미 X
- ord_ : 순서형 feature - 순서 의미 O
- day, month : 날짜 feature
데이터 다운로드
- kaggle 로그인해서 data tab에서 Download All 하기
데이터 가져오기
import pandas as pd data_path='./data/cfec/' train=pd.read_csv(data_path+'train.csv',index_col='id') test=pd.read_csv(data_path+'test.csv',index_col='id') submission=pd.read_csv(data_path+'sample_submission.csv', index_col='id')데이터 탐색하기
# 데이터 탐색 print(train.shape) print(test.shape) print(train.head()) # 답안은 어떻게 제출해? print(submission.head()) # 0.5로 나오는 것을 보니 확률이구나# feature의 정보를 요약해주는 함수 def resumetable(df): print('데이터의 구조 :',df.shape) summary=pd.DataFrame(df.dtypes, columns=['데이터 타입']) summary=summary.reset_index() summary=summary.rename(columns={'index':'Feature'}) summary['결측값 개수']=df.isnull().sum().values summary['고유값 개수']=df.nunique().values summary['첫 번째 값']=df.loc[0].values summary['두 번째 값']=df.loc[1].values summary['세 번째 값']=df.loc[2].values return summary resumetable(train)# 순서형 feature 목록 확인 for i in range(3): feature='ord_'+str(i) print(feature+' 고유 값 : ',train[feature].unique()) # 순서형 feature 목록 확인 for i in range(3,6): feature='ord_'+str(i) print(feature+' 고유 값 : ',train[feature].unique()) print('day 고유값 : ', train['day'].unique()) print('month 고유값 : ', train['month'].unique()) print('target 고유값 : ', train['target'].unique())기술정보를 봤다면, 이제 시각화를 시작하자
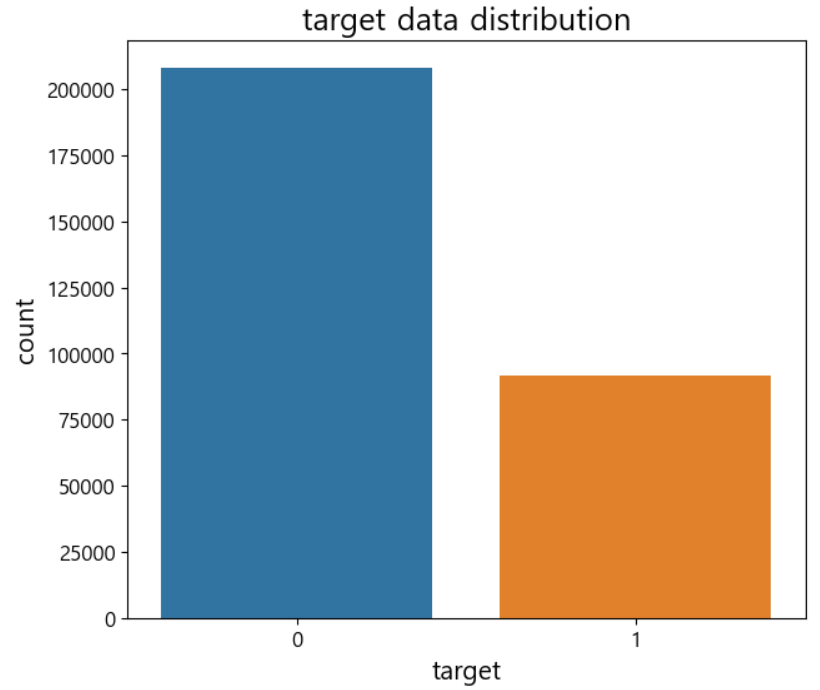
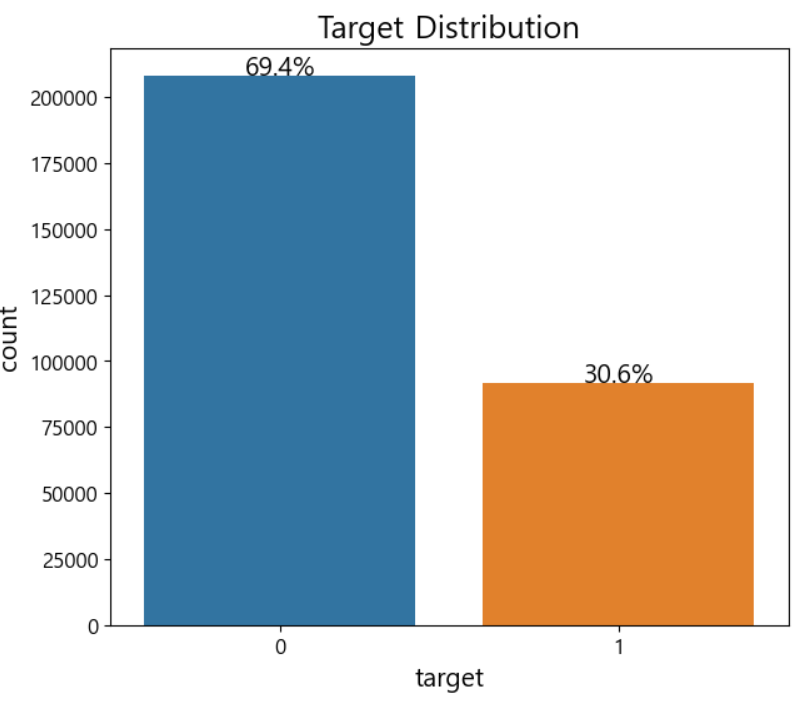
import seaborn as sns import matplotlib as mpl import matplotlib.pyplot as plt mpl.rc('font',size=15) plt.figure(figsize=(7,6)) # target의 분포 확인하기 ax=sns.countplot(x='target', data=train) ax.set(title='target data distribution') # 0 : 1 = 2 :1 비율이에요
그래프 텍스트 출력
- 그래프에 텍스트를 출력할 때는 위치를 설정해서 출력
- 현재 화면에 그려진 그래프에 대한 정보를 알고자 하는 경우는 ax.patches 속성 이용 가능
- 막대 그래프의 경우는 막대에 대한 정보가 pathces에 저장되어 있습니다.
- 막대가 순서대로 0,1,2,3,4 번 인덱스에 저장이 됩니다.# 첫 번쨰 막대에 대한 정보를 확인 rectangle=ax.patches[0] print('높이 :', rectangle.get_height()) print('너비 :', rectangle.get_width()) # 왼쪽 테두리의 x좌표가 중요해 print('왼쪽 테두리의 x좌표 : ', rectangle.get_x())# 텍스트 출력 - 비율을 표시하자 def write_percent(ax,total_size): for patch in ax.patches: height=patch.get_height() width=patch.get_width() left_coord=patch.get_x() #막대의 높이를 이용해서 비율 구하기 percent=height/total_size*100 #텍스트 출력 ax.text(x=left_coord+width/2.0, y=height+total_size*0.001, s=f'{percent:1.1f}%', ha='center') plt.figure(figsize=(7,6)) ax=sns.countplot(x='target',data=train) write_percent(ax,len(train)) ax.set_title("Target Distribution")
bin feature 시각화
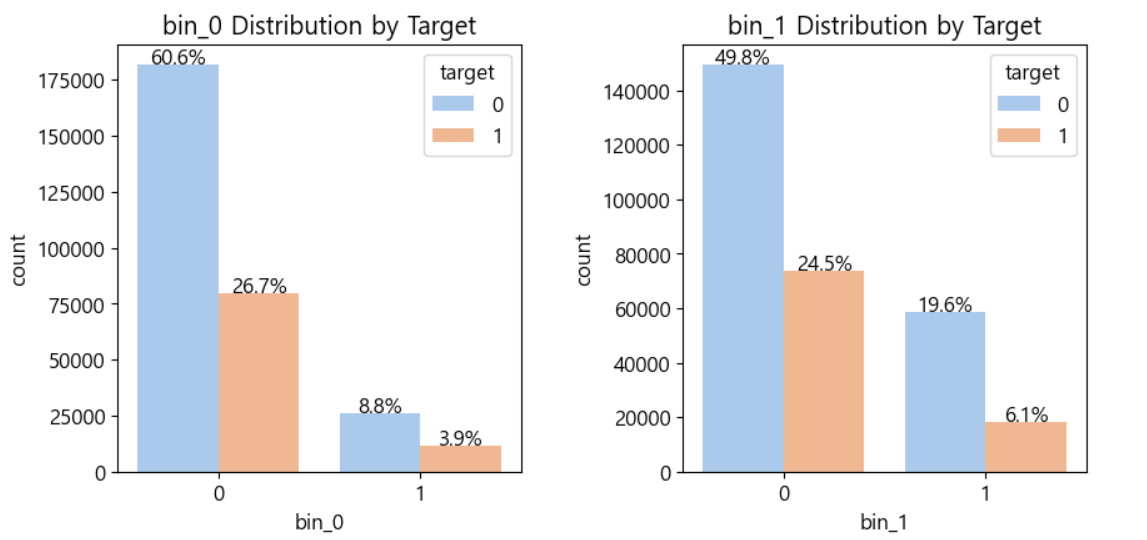
# 여러 개의 이진 데이터 분포를 확인해보자. # 여러 개의 이미지를 출력할 때 사용하는 격자 import matplotlib.gridspec as gridspec mpl.rc('font',size=12) grid=gridspec.GridSpec(3,2)#행,열 plt.figure(figsize=(10,16)) plt.subplots_adjust(wspace=0.4,hspace=0.3) # 시각화할 컬럼 리스트 bin_features=['bin_0','bin_1','bin_2','bin_3','bin_4'] for idx,feature in enumerate(bin_features): ax=plt.subplot(grid[idx]) sns.countplot(x=feature,data=train,hue='target', palette='pastel',ax=ax) #hue는 색상 : target에 나눠서 색상 부여 ax.set_title(f'{feature} Distribution by Target') write_percent(ax,len(train))
교차 분석표를 이용한 데이터 분포 확인
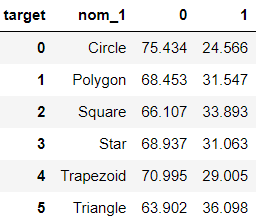
pd.crosstab(train['nom_0'],train['target']) # 백분율로 보고싶다면? cross=pd.crosstab(train['nom_0'],train['target'], normalize='index')*100 # 인덱스 좀 보기 싫으면 이렇게 밀자 cross=cross.reset_index() # cross # 이것도 함수로 만들면 편하지 않을까? def get_crosstab(df,feature): crosstab=pd.crosstab(df[feature],df['target'], normalize='index')*100 crosstab=crosstab.reset_index() return crosstab crosstab=get_crosstab(train, 'nom_1') crosstab
이와 같은 시각적 탐색을 한다면 알 수 있는 결론
- 결측치의 존재 여부 (여기 존재 X)
- 제거할 feature 여부
- feature의 의미를 알지 못하기에 제거할 feature X데이터 전처리를 해보자.
- 순서가 있는 범주형 데이터라면 내가 직접 해줘야 한다.
# print(train['ord_1']) # 순서가 있다면, 순서대로 만들어줘야 한다. # train['ord_1'].unique() # ord_1는 Novice, Contributor, Expert, Master, Grandmaster 순서 # ord_2는 Freezing, Cold, Warm, Hot, Boiling Hot, Lava Hot 순서 from pandas.api.types import CategoricalDtype ord_1_value=['Novice', 'Contributor', 'Expert', 'Master', 'Grandmaster'] ord_2_value=['Freezing', 'Cold', 'Warm', 'Hot', 'Boiling Hot', 'Lava Hot'] # 문자열 리스트를 type으로 생성 -enum ord_1_dtype=CategoricalDtype(categories=ord_1_value,ordered=True) ord_2_dtype=CategoricalDtype(categories=ord_2_value,ordered=True) train['ord_1']=train['ord_1'].astype(ord_1_dtype) train['ord_2']=train['ord_2'].astype(ord_2_dtype)기본적인 처리를 수행하고 제출해보자
데이터 로드
# 데이터 오염 문제로 다시 데이터를 가져오자. data_path='./data/cfec/' train=pd.read_csv(data_path+'train.csv',index_col='id') test=pd.read_csv(data_path+'test.csv',index_col='id') submission=pd.read_csv(data_path+'sample_submission.csv', index_col='id')데이터 전처리
## 훈련 데이터와 테스트 데이터를 합쳐야 합니다. (전처리 전) all_data=pd.concat([train,test]) # target은 전처리 대상이 아닙니다. all_data=all_data.drop('target',axis=1) # all_data.head()# 범주형 데이터를 원핫인코딩 from sklearn.preprocessing import OneHotEncoder encoder=OneHotEncoder() all_data_encoded=encoder.fit_transform(all_data) # fit_transform하면 ndarray로 나와요 all_data.head()# 훈련 / 테스트 분리 num_train=len(train) X_train=all_data_encoded[:num_train] X_test=all_data_encoded[num_train:] y=train['target']# 훈련에 사용할 데이터와 검증을 위한 데이터 분리 from sklearn.model_selection import train_test_split # 2:1 target 차이 많이 나이게 층화 추출로 # 테스트 데이터와 검증용 데이터 생성하기 X_train,X_valid,y_train,y_valid=train_test_split(X_train,y, test_size=0.1, random_state=42, stratify=y)모델 생성 및 훈련
# 이진 분류 이므로 모든 분류기 사용 가능 from sklearn.linear_model import LogisticRegression # 모델 만들기 logistic_model=LogisticRegression(max_iter=1000,random_state=42) # 훈련 logistic_model.fit(X_train,y_train)# 예측 pred=logistic_model.predict(X_valid) # 예측 확률 pred_proba=logistic_model.predict_proba(X_valid)평가지표 확인하기 - ROC AUC
# 평가지표 - ROC AUC : pred_proba가 필요하다 y_valid_preds=logistic_model.predict_proba(X_valid)[:,1] from sklearn.metrics import roc_auc_score roc_auc=roc_auc_score(y_valid, y_valid_preds) print("평가 점수 : ", roc_auc)제출할 결과 파일을 생성
y_preds=logistic_model.predict_proba(X_test)[:,1] submission['target']=y_preds submission.to_csv('submission.csv') submission.head()
- 이제 kaggle에 제출하면 된다.
모델을 수정해보자
데이터 다시보기
# 데이터 확인 all_data.head()이진 feature Encoding을 수정하자
# 문자로 된 경우, 숫자로 수정하는 것이 매우 좋습니다. all_data['bin_3']=all_data['bin_3'].map({'F':0,'T':1}) all_data['bin_4']=all_data['bin_4'].map({'N':0,'Y':1})순서가 있는 feature Encoding
# print(all_data.head()) # ord_1, ord_2,... 다 문자다 순서는 지켜주는게 좋다. ord1dict={'Novice':0,'Contributor':1,'Expert':2,'Master':3, 'Grandmaster':4} ord2dict={'Freezing':0,'Cold':1,'Warm':2,'Hot':3, 'Boiling Hot':4,'Lava Hot':5} all_data['ord_1']=all_data['ord_1'].map(ord1dict) all_data['ord_2']=all_data['ord_2'].map(ord2dict) print(all_data.head())# ord_3, ord_4, ord_5는 순서가 있는 범주형 # One Hot이 아닌 Ordinal Encoding 수행 # 명확한 순서를 모른다면 그냥 OrdinalEncoder 해주면 된다. from sklearn.preprocessing import OrdinalEncoder ord_345=['ord_3','ord_4','ord_5'] ord_encoder=OrdinalEncoder() all_data[ord_345]=ord_encoder.fit_transform(all_data[ord_345]) for feature, categories in zip(ord_345,ord_encoder.categories_): print(feature) print(categories)순서가 의미없는 feature Encoding
nom_features=['nom_'+str(i) for i in range(10)] from sklearn.preprocessing import OneHotEncoder onehot_encoder=OneHotEncoder() encoded_nom_matrix=onehot_encoder.fit_transform(all_data[nom_features]) all_data=all_data.drop(nom_features,axis=1) print(all_data.head())날짜 목록 Encoding
date_features=['day','month'] encoded_date_matrix=onehot_encoder.fit_transform(all_data[date_features]) all_data=all_data.drop(date_features, axis=1) print(encoded_date_matrix)순서형 목록은 스케일링을 해줘야한다
from sklearn.preprocessing import MinMaxScaler ord_features=['ord_'+str(i) for i in range(6)] all_data[ord_features]=MinMaxScaler().fit_transform(all_data[ord_features]) all_data[ord_features]인코딩한 데이터와 스케일링한 데이터를 합쳐야 한다
from scipy import sparse all_data_sprs=sparse.hstack([sparse.csr_matrix(all_data), encoded_nom_matrix, encoded_date_matrix], format='csr')훈련 데이터와 검증 데이터 생성
num_train=len(train) X_train=all_data_sprs[:num_train] X_test=all_data_sprs[num_train:] y=train['target'] X_train,X_valid,y_train,y_valid=train_test_split(X_train, y, test_size=0.1, stratify=y, random_state=42)하이퍼 파라미터 튜닝을 통한 모델 학습
from sklearn.model_selection import GridSearchCV logistic_model=LogisticRegression() lr_params={ 'C':[0.1,0.125,0.2], 'max_iter':[800,900,1000,1200], 'solver':['liblinear'], 'random_state':[42,20,26] } grdisearch_logistic_model=GridSearchCV(estimator=logistic_model, param_grid=lr_params, scoring='roc_auc', cv=5) grdisearch_logistic_model.fit(X_train,y_train) print("최적의 파라미터 : ", grdisearch_logistic_model.best_params_)
- 꼭 복잡한 모델을 사용해야만 높은 점수를 얻는 것이 아니다.
- 데이터 처리가 중요하다.

밀가루 귀여워요