
✔ 다변량 회귀 분석
- 독립 변수의 개수가 2개 이상인 경우
- LinearRegression 클래스를 이용해서 수행 가능
- 다변량 회귀를 수행할 때 주의할 점은 다중 공선성 문제
보스톤 주택 가격 예측
- Data Load
# 데이터 가져오기 y_target=bostonDF['PRICE'] X_data=bostonDF.drop(['PRICE'],axis=1,inplace=False) print(y_target.head()) print(X_data.head())
- Data split
# 훈련 데이터와 테스트 데이터 분리 (7:3) from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test=train_test_split(X_data,y_target, test_size=0.3, random_state=42) # shape를 print해서 구조가 맞는지 확인한다. print(X_train.shape) print(X_test.shape) print(y_train.shape) print(y_test.shape)
- Model Train
# 회귀 모델을 생성하고 훈련하기 from sklearn.linear_model import LinearRegression lr=LinearRegression() lr.fit(X_train,y_train)
- Model Evaluate
# 평가 y_pred=lr.predict(X_test) from sklearn.metrics import mean_squared_error, r2_score mse=mean_squared_error(y_test,y_pred) # mse는 제곱을 하기에 실제 데이터보다 스케일이 큰 경우가 있다. # 제곱근해서 많이 사용합니다. rmse=np.sqrt(mse) r2score=r2_score(y_test,y_pred) print('mse : ', mse) print('rmse : ',rmse) print('r2_score : ',r2score)# 회귀 계수와 절편 값을 확인하자 print('절편 : ', lr.intercept_) print('기울기 : ',lr.coef_)
- 간단하게 이 값을 보고도 중요도를 대충 짐작 할 수 있다.
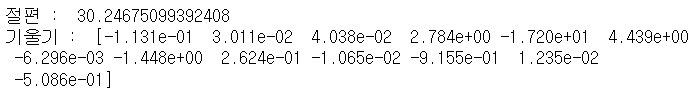
✔ 다중 공선성 - Multicollinearity
- 회귀 분석에서 독립 변수들 간에 강한 상관 관계가 나타나는 문제
- 회귀 분석의 전제 가정을 위배하는 것
확인하는 방법
- R2_Score의 값은 높은데, p-value(유의확률)도 높은 경우
- p-value : 우연히 이 결과가 나올 확률 - 독립 변수들 간의 상관 계수를 확인
- VIF(Variance Inlaction Factor - 분산 팽창 요인)의 값이 10이 넘는 경우
해결하는 방법
- 상관 관계가 높은 변수들 중에서 하나 or 일부를 제거
- 변수를 변형하거나 새로운 변수를 이용
- 주성분 분석 등을 통해서 변수를 하나로 합치기
- 자료를 수집하는 과정에서 이유를 찾아서 해결하기
✔ statsmodel
- 통계 분석을 위한 python 패키지
- http://www.statsmodels.org - 기초 통계와 회귀 분석에 관련된 기능을 제공함
- score.csv파일의 데이터를 이용해서 IQ와 academy, game, tv를 이용한 시간을 이용해 score를 예측해보자
# data load df=pd.read_csv('./data/score.csv', encoding='cp949') df.head()import statsmodels.formula.api as sm result=sm.ols(formula='score ~ iq + academy + game + tv', data=df).fit() print('절편과 기울기 : ', result.params) print("p-value(유의확률) : ", result.pvalues) print("결정 계수 ", result.rsquared) # 1에 가까우면 좋다.
- 결정 계수가 높아서 아주 신뢰할 만한 결과인 것 같지만, pvalue 값도 높다. 0.05 ~ 0.1
# 예측 # iq 130 학원 3개 게임 2시간 tv 1시간 보는 학생의 예상점수 y=result.params.Intercept+130*result.params.iq+ 3*result.params.academy+2*result.params.game+1*result.params.tv print('예상 점수 : ', y)
- 예상 점수 : 83.28448678034155
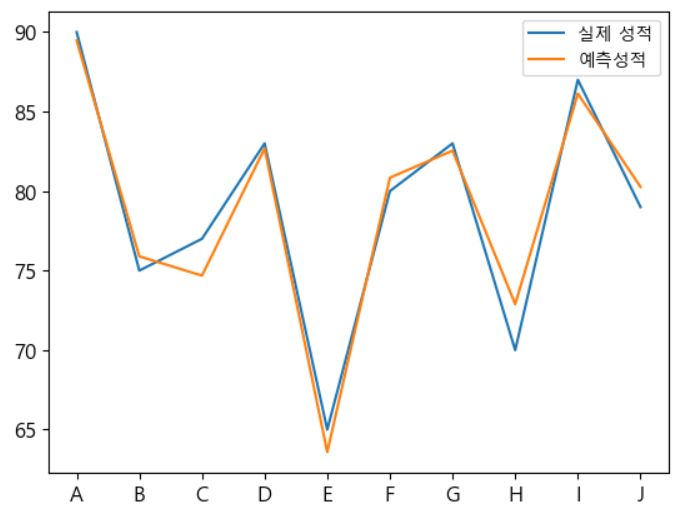
# 예측 값과 실제 값의 시각화 plt.figure() plt.plot(df['score'],label='실제 성적') plt.plot(result.predict(),label='예측성적') plt.xticks(range(0,10,1),df['name']) plt.legend() plt.show()
- 결정 계수가 높기 때문에, 오차가 별로 없음
# VIF(분산 팽창 요인) 출력하기 # 관련 없는 feature drop하기 X=df.drop(['score','name'], axis=1) from statsmodels.stats.outliers_influence import variance_inflation_factor vif=pd.DataFrame() vif["VIF Factor"]=[variance_inflation_factor(X.values,i) for i in range(X.shape[1])] vif["features"]=X.columns print(vif)
- academy를 빼보자. 너무 값이 크다.
X=df.drop(['score','name', 'iq'], axis=1)
- 좀 괜찮아졌다.
- 그럼 academy를 빼고 식을 세워서 다시 봐보자.
import statsmodels.formula.api as sm result=sm.ols(formula='score ~ iq + game + tv', data=df).fit() print('절편과 기울기 : ', result.params) print("p-value(유의확률) : ", result.pvalues) print("결정 계수 ", result.rsquared) # 1에 가까우면 좋다.
- 많이 좋아졌다.


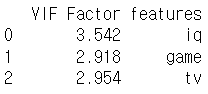

✔ 다항 회귀 - Polynomial
- 모든 관계를 직선으로만 파악할 수 없는데, 이 경우에 회귀가 독립 변수의 단항식이 아니라 2차나 3차 방정식과 같은 다항식으로 표현되는 것
- 비선형 회귀와 유사하지만, 선형 회귀로 분류
- 회귀 모델을 선형과 비선형으로 나누는 것은, 회귀 계수가 선형인지 비선형인지 입니다.
- sklearn은 비선형 회귀를 지원하지 않습니다.
- 비선형 회귀를 하고자 하는 경우에는, PolynomialFeatures 클래스를 이용해서 Feature를 Polynomial(다항식)으로 변환해서 사용합니다.
- degree라는 매개변수를 이용해서 다항식 feature로 변환합니다.
- 이 수치가 높을수록 높은 정확도를 가질 가능성이 높아지지만, overfitting될 가능성도 같이 높아집니다.
✔ 규제
L1과 L2 Loss
- L1 Loss
- 실제 값과 예측 값 사이의 오차의 절대값을 구하고 그 오차들의 합을 구한 것 - L2 Loss
- 실제 값에서 예측값을 뺀 후 제곱한 값들의 합
- 이상치에 더 민감합니다. - Outlier가 적당히 무시되기를 원한다면 L1 Loss를 사용하고, Outlier의 등장에 민감하게 반응하고자 한다면 L2 Loss를 사용합니다.
L1과 L2 norm - 벡터의 크기를 측정하는 방법
- L1 norm
- 맨하튼 거리 - L2 norm
- 유클리드 거리
일반화 - regularization
- 공선성을 다루거나 데이터에서 잡음을 제거해서 과대 적합을 방지하는 것
- 모델의 복잡도에 패널티를 부여해서 Overfitting을 방지하고 성능을 높이는데 도움을 주는 것
패널티를 부여하는 방법 - 선형 회귀 규제
- Ridge
- Lasso
- ElasticNet
- L1 정규화 : Lasso
- 예측 영향력이 떨어지는 피처의 회귀 계수를 0으로 만들어서 회귀 예측을 할 때 선택이 되지 않도록 하는 방식 - L2 정규화 : Ridge
- 회귀 계수의 영향력이 적어지는 방향으로 학습하도록 하는 방식으로 피처가 제거되지는 않음 - ElasticNet
- Lasso와 Ridge를 모두 사용 - 정규화를 수행하게 되면, 영향력이 약한 feature의 가중치를 감소시키거나 제거해서 조금 더 나은 모델을 만들 수 있음
- Lasso를 적용하면, 영향력이 약한 feature의 가중치를 감소시키고, Ridge를 적용하면 영향력이 약한 feature를 제거한다.
- sklearn에서는 Lasso, Ridge, Elasticnet이라는 클래스를 이용해서 제공
- 패널티는 alpha라는 매개변수를 이용해서 설정
boston에 Ridge 적용
from sklearn.linear_model import Ridge y_target=bostonDF['PRICE'] X_data=bostonDF.drop(['PRICE'],axis=1,inplace=False)from sklearn.model_selection import cross_val_score # 적용할 규제 값 alphas=[0,0.1,1,10,100] for alpha in alphas: ridge=Ridge(alpha=alpha) neg_mse_scores=cross_val_score(ridge,X_data,y_target, scoring='neg_mean_squared_error',cv=5) avg_rmse=np.mean(np.sqrt(-1*neg_mse_scores)) print('alpha {0} 일 때 folds의 평균 RMSE : {1}'.format(alpha,avg_rmse))
- 점점 규제를 가하고 있다.

✔ 조기 종료
- 선형 회귀가 경사 하강법을 주로 사용하는데, 경사 하강법은 반복적인 학습 알고리즘입니다.
- 검증 에러가 최소값에 도달하면, 훈련을 조기 중지 시킬 수 있습니다.
- 한 번의 학습이 진행되면, 훈련 세트를 가지고 학습을 한 뒤에 검증데이터를 가지고 검증을 하면 에러를 감소시켜 가면서 학습을 하지만, 어느 정도에 도달하면 다시 에러가 증가하기 시작
- 이 경우가 Overfitting이 발생을 하기 시작한 지점이 되는데, 이 지점에 도달하면 더 이상 학습을 할 필요가 없음
- 제공되는 대다수의 선형 회귀 모델들은 조기 종료를 할 수 있도록 만들어져 있습니다.
- 반복 횟쉬를 설정할 때 max_iter로 설정합니다.
- max_iter로 설정하고 wram_start=True설정
✔ 선형 회귀를 수행할 때 데이터 변환
- 데이터 인코딩을 할 때는 이진인지 순서형인지 무순서 형인지 판단해서 인코딩을 수행해야 합니다.
- feature들의 범위가 다른 경우에는 scaling을 해주는 것이 좋습니다.
- target의 분포 차이가 너무 많이 난다면(범위가 너무 넓으면) 로그 변환을 해주는 것이 좋습니다.
- 로그 변환을 했을 때, 만들어진 모델이 성능이 좋은 경우가 많이 떄문입니다.
✔ 비선형 회귀
KNN(최근접 이웃)
- 이웃의 개수를 설정해서 거리가 가까운 이웃을 구하고, 그 이웃의 값을 가지고 예측을 하는것
- 분류의 경우는 다수결의 원칙을 따르고, 회귀의 경우는 평균을 구해서 예측
- 평균을 구할 때 가중치를 부여할 수 있습니다.
- KNN
from sklearn.neighbors import KNeighborsRegressor # 거리를 가지고 가중 평균을 구해서 예측 # uniform을 설정하면 일반 평균 regressor=KNeighborsRegressor(n_neighbors=3,weights='distance') X_train=[ [0.5,0.2,0.1], [0.9,0.7,0.3], [0.4,0.4,0.7], [0.2,0.3,0.5] ] y_train=[5.0,6.8,9.0,4.3] regressor.fit(X_train,y_train)X_test=[ [0.8,0.1,0.2], [0.4,0.7,0.6], ] pred=regressor.predict(X_test) print(pred)
트리 기반 회귀
- 트리 형태로 분할 한 뒤, leaf node의 평균을 이용해서 예측
- 모든 트리 기반 알고리즘은 분류와 회귀 모두에 사용 가능
- Classifier를 Regressor로 바꾸기면 하면 끝이다.
# 샘플 데이터 생성 np.random.seed(42) m=200 X=np.random.rand(m,1) y=y*(X-0.5)**2 y=y+np.random.randn(m,1)/10from sklearn.tree import DecisionTreeRegressor tree_reg=DecisionTreeRegressor(max_depth=2, random_state=42) tree_reg.fit(X,y) from graphviz import Source from sklearn .tree import export_graphviz export_graphviz( tree_reg, out_file='decision_tree.dot', feature_names=['X'], class_names=['y'], rounded=True, filled=True ) #화면출력 with open('decision_tree.dot')as f: dot_graph=f.read() src=Source(dot_graph) src
from sklearn.tree import DecisionTreeRegressor # 터미널(자식이 없는 노드 - LEAF NODE)의 개수가 10이상이어야 한다는 제약도 가능함 # min_samples_leaf 설정하면 각 터미널의 dpeth가 일정하지 않을 수 있다. tree_reg=DecisionTreeRegressor(min_samples_leaf=10, random_state=42) tree_reg.fit(X,y)
- depth가 다르다.
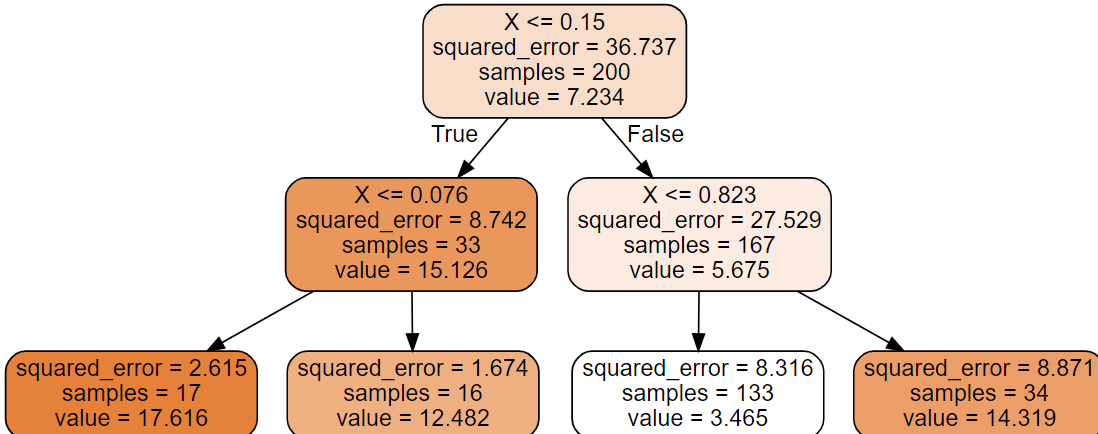
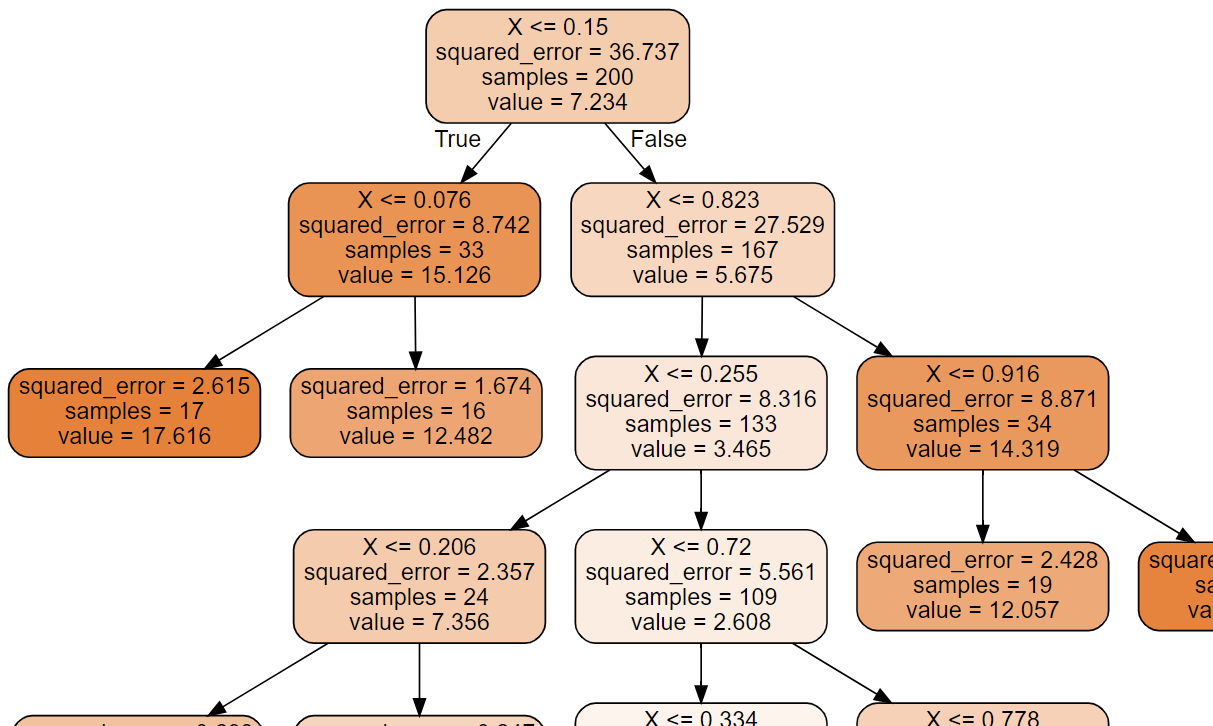
- max_depth를 높게 설정하면 중간 가지를 많이 만들어 냅니다.
SVM - Support Vector Machine
- 초평면을 이용하는 방식
- 선형과 비선형 커널을 이용하는 방식이 존재
- 중규모 정도의 데이터에 잘 맞습니다.
- 하이퍼 파라미터로는 epsilon이 있는데, 이 파라미터의 역할은 결정 경계 사이의 거리(margin)
np.random.seed(42) m=50 X=2*np.random.rand(m,1) #ravel은 차원을 하나 줄이는 역할을 수행해주는 함수 # X 떄문에 2차원 배열로 만들어지는 타겟은 # 1차원이어야 하기 때문에 차원을 수정 # flatten이나 reshape도 가능합니다. # flatten() # reshape는 데이터의 개수를 알아야 한다. y=(4+3*X+np.random.randn(m,1)).ravel() print(y)X_train=X[:40] X_test=X[40:] y_train=y[:40] y_test=y[40:] from sklearn.svm import LinearSVR svm_reg=LinearSVR(epsilon=1.5,random_state=42) svm_reg.fit(X_train,y_train)y_pred=svm_reg.predict(X_test) mse=mean_squared_error(y_test,y_pred) rmse=np.sqrt(mse) print(y_test) print(y_pred) print(rmse)
- MSE로 하면 너무 큰 값이 나올 수 있기에 root 해주기
- epsilon(margin) 줄이면 rmse 줄어들 것이다.
- 비선형 데이터도 할 수 있다.
## 비선형 데이터 생성 np.random.seed(42) m = 100 X = 2* np.random.rand(m,1) -1 y = (0.2 + 0.1 * X + 0.5 * X**2 + np.random.randn(m,1) / 10).ravel() X_train = X[:80] X_test = X[80:] y_train = y[:80] y_test = y[80:]
- 이걸 기존 있던거 그대로 해주면
- 이런 문제가 생긴다.
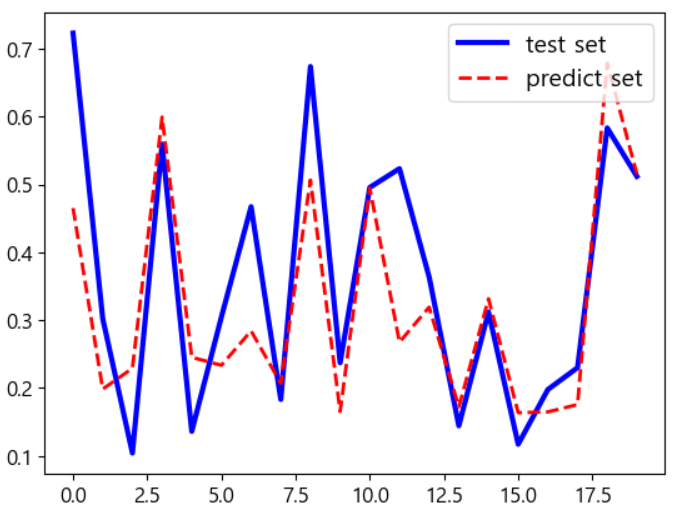
from sklearn.svm import SVR # 샘플 데이터를 2차 방정식으로 했기 때문에 지금은 degree가 2인 경우가 잘 맞습니다. svm_poly_reg = SVR(kernel='poly', gamma='auto', degree=2, C=10, epsilon=0.1) svm_poly_reg.fit(X_train,y_train) # 예측 및 결과 비교 y_pred = svm_poly_reg.predict(X_test) print(y_test) print(y_pred) mse = mean_squared_error(y_test, y_pred) rmse = np.sqrt(mse) print(rmse) plt.plot(y_test, "b-", linewidth=3, label="test set") plt.plot(y_pred, "r--", linewidth=2, label="predict set") plt.legend(loc="upper right", fontsize=14) plt.show()
- 다항식도 괜찮다 이러면.

✔ Ensemble
집단 지성 프로그래밍
- 무작위로 선택된 수천명의 사람들에게 복잡한 질문을 하고, 대답을 모은다고 가정하면, 이렇게 모은 답이 전문가의 답보다 나을 가능성이 높다.
- 대중의 지혜(wisdom the crowd)
- 여러 예측기로부터 예측을 수집하면 가장 좋은 모델이 될 수 있다. - 이러한 방식의 예측기를 앙상블이라고 하고, 이를 앙상블 학습이라고 합니다.
- 훈련 세트로부터 무작위로 각기 다른 서브 세트를 만들어서 결정 트리 분류기를 훈련시키고 모든 결정 트리의 예측을 구하고, 가장 많은 선택을 받은 클래스를 예측으로 선정하는 방식이 Random Forest
투표 기반 분류기
- 정확도가 80% 인 분류기를 여러 개 가지고 훈련
- KNN, SVM, RandomForest 등 - 각 분류기의 예측을 모아서 가장 많이 선택된 클래스를 예측
- 다수결 투표로 이루어진 분류기를 직접 투표 분류기(Hard Voting)
- 다수결 투표 분류기가 앙상블에 포함된 가장 좋은 분류기보다 정확도가 높을 가능성이 많음
# 데이터 생성 from sklearn.model_selection import train_test_split from sklearn.datasets import make_moons X, y = make_moons(n_samples=500, noise=0.30, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) #모델 생성 및 훈련 from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import VotingClassifier from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC log_clf = LogisticRegression(solver="lbfgs", random_state=42) rnd_clf = RandomForestClassifier(n_estimators=100, random_state=42) svm_clf = SVC(gamma="scale", random_state=42) voting_clf = VotingClassifier( estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)], voting='hard') voting_clf.fit(X_train, y_train)# 각 모델의 정확도 확인해보기 from sklearn.metrics import accuracy_score for clf in (log_clf, svm_clf, rnd_clf, voting_clf): clf.fit(X_train,y_train) y_pred=clf.predict(X_test) print(clf.__class__.__name__,"정확도 : ",accuracy_score(y_test,y_pred))
- 개별 분류기로 가장 높게 나온 RandomForest 분류기보다 투표 기반의 VotingClassifier가 더 정확도가 높다.

간접 투표 기반 분류기
- 모든 분류기가 클래스 별 확률을 예측할 수 있는 경우, 모든 분류기의 클래스 별 확률을 평균을 내서 예측이 가능한데, 이러한 방식을 간접 투표 기반 분류기라고 합니다.
- SVM 모델은 확률을 제공하지 않는데, 생성할 때, probability 매개변수를 True로 설정하면 predict_proba 메서드 사용 가능
- 확률을 계산하기 위해서 probability 매개변수를 True로 설정하면, 확률을 계산하기 위해서 교차 검증을 수행하므로 훈련 속도가 느려집니다.
- VotingClassifier에서는 voting이라는 매개변수를 soft로 설정해서 생성
# 간접 투표 방식 log_clf = LogisticRegression(solver="lbfgs", random_state=42) rnd_clf = RandomForestClassifier(n_estimators=100, random_state=42) svm_clf = SVC(gamma="scale",probability=True, random_state=42) voting_clf = VotingClassifier( estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)], voting='soft') from sklearn.metrics import accuracy_score for clf in (log_clf, svm_clf, rnd_clf, voting_clf): clf.fit(X_train,y_train) y_pred=clf.predict(X_test) print(clf.__class__.__name__,"정확도 : ",accuracy_score(y_test,y_pred))

Bagging과 Pasting
- 같은 알고리즘을 사용하고, 훈련 세트의 서브 세트를 무작위로 구성해서 분류기를 각기 다르게 학습시키는 것
- Bagging : 훈련 데이터의 중복 허용
- Pasting : 훈련 데이터 중복 불허
- 모든 예측기가 훈련을 마치면 모든 예측기의 예측을 모아서 새로운 샘플에 대한 예측을 생성
- 분류의 경우는 최빈값(statistical mode)을 사용하고 회귀의 경우는 평균을 사용
- 개별 예측기는 원본 훈련 세트 전체로 훈련시킨 것 보다 훨씬 편향되지만, 수집 함수를 통과하면 편향과 분산이 모두 감소합니다.
- 예측기들은 다른 cpu 코어나 병렬로 학습시킬 수 있어서 인기가 높음
- sklearn에서는 BaggingClassifier 클래스로 기능을 제공하는데,
bootstrap=False설정하면 Pasting으로 된다. - n_jobs 속성에 코어의 개수 설정 가능
- 기반이 되는 분류기가 클래스 확률을 추정할 수 있으면, 직접 투표 대신 자동으로 간접 투표 사용
Bagging을 이용한 앙상블
from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier bag_clf=BaggingClassifier( DecisionTreeClassifier(), n_estimators=500, max_samples=100, bootstrap=True, random_state=42 ) bag_clf.fit(X_train,y_train) y_pred=bag_clf.predict(X_test) print("정확도 : ", accuracy_score(y_test,y_pred))tree_clf = DecisionTreeClassifier(random_state=42) tree_clf.fit(X_train, y_train) y_pred_tree = tree_clf.predict(X_test) print(accuracy_score(y_test, y_pred_tree))
- 부스트트래핑은 각 예측기가 학습하는 서브 세트에 다양성을 증가시키기 때문에, bagging이 pasting보다 편향이 조금 더 높지만, 다양성을 추가한다는 것은 예측기들의 상관 관계를 줄이기 떄문에 앙상블의 분산을 감소시킴
- 일반적으로는 배깅이 페이스팅보다 더 나은 모델을 만들기 떄문에 더 선호
oob(out-of-bag) 평가
- 배깅을 사용하게 되면, 한 예측기를 위해 여러 번 샘플링되는 샘플이 존재하고, 어떤 샘플은 한 번도 샘플링되지 않는 경우가 발생하는데, 이렇게 샘플링되지 않은 데이터를 oob라고 합니다.
- 각 예측기에 훈련 샘플의 63% 정도가 샘플링 됩니다.
- 남은 37%의 데이터를 가지고 검증을 하게 되고, 앙상블의 평가는 각 예측기의 oob 평가를 평균해서 얻어냄
- BaggingClassifier를 만들 때,
oob_score=Ture라는 매개변수를 추가하면 oob 평가를 수행하고, 결과를oob_score_로 저장
#oob 평가 bag_clf = BaggingClassifier( DecisionTreeClassifier(), n_estimators=500, max_samples=100, bootstrap=True, random_state=42, oob_score=True ) bag_clf.fit(X_train, y_train) print(bag_clf.oob_score_)
특성 샘플링도 지원
-
샘플링은 max_features, bootstrap_features 두 매개변수로 조절
각 예측기는 무작위로 선택한 입력 특성의 일부분으로 훈련 -
훈련하는 특성 과 데이터를 모두 샘플링하는 방식을 random patches method 라고 합니다.
-
훈련 데이터는 모두 사용하고(bootstrap=False 이고 max_samples=1.0) 특성만 샘플링(bootstrap_features=True 그리고 max_features는 1.0 보다 작게)하는 것을 random subspaces method 라고 합니다.
-
특성 샘플링을 하게 되면 더 다양한 예측기를 만들기 때문에 편향을 늘리는 대신 분산을 낮춤
Random Forest
개요
- 동일한 알고리즘으로 여러개의 분류기를 만들어서 보팅으로 최종 결정하는 배깅의 대표적인 알고리즘
- 동일한 데이터에 결정 트리 여러 개를 동시에 적용해서 학습 성능을 높이는 앙상블 기법
- 동일한 데이터로부터 부트스트랩 샘플을 생성해서 샘플 데이터에 각각 결정 트리를 적용한 뒤, 학습 결과를 취합하는 방식
- 각각의 결정 트리는 전체 변수 중 일부만 학습하는데, 개별 트리들이 데이터를 바라보는 관점을 다르게 해서 다양성을 높이고자 하는 시도이다.
- random_state를 이용해서 고정된 트리를 만드는데, 트리의 개수를 늘리면 random_state의 효과는 줄어든다.
장점
- 결정 트리의 단점을 보완
- 하이퍼 파라미터 튜닝을 하지 않아도 잘 작동
- 데이터의 스케일을 맞출 필요가 없음
- 트리 모델을 여러 feature를 가지고 결정하는 것이 아닌, feature 각각을 바로 보기 때문에, 하나의 feature가 다른 feature와 비교되지 않습니다. - 매우 큰 데이터 세트에도 잘 동작하고, 여러 cpu 코어로 병렬화 가능
단점
- 대량의 데이터에서 수행하게 된다면 수행 시간이 오래 걸림
- 차원이 높고 희소한 데이터에는 잘 작동하지 않음
- 선형 모델이 더 우수한 성능을 발휘함
Bagging과 Random Forest
- 배깅
bag_clf = BaggingClassifier( DecisionTreeClassifier(max_features="sqrt", max_leaf_nodes=16), n_estimators=500, random_state=42) bag_clf.fit(X_train, y_train) y_pred = bag_clf.predict(X_test
- 랜덤 포레스트
from sklearn.ensemble import RandomForestClassifier rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, random_state=42) rnd_clf.fit(X_train, y_train) y_pred_rf = rnd_clf.predict(X_test) print(np.sum(y_pred == y_pred_rf) / len(y_pred))
- 결과는 1.0 : bag_clf 와 rnd_clf 가 예측한 결과가 정확히 일치
- RandomForest 는 DecisionTreeClassifier 의 매개변수 와 앙상블 자체를 제어하는데 필요한 BaggingClassifier의 매개변수를 모두 가지고 있음
- RandomForest 알고리즘은 트리의 노드를 분할할 때 전체 특성 중에서 최선의 특성을 찾는 대신 무작위로 선택한 특성 후보 중에서 최적의 특성을 찾는 식으로 무작위성을 더 주입해서 트리를 더욱 다양하게 만들고 편향을 손해보는 대신에 분산을 낮춰서 전체적으로는 더 훌륭한 모델을 만드는 방식
특성 중요도
- RandomForest의 장점 중 하나는 특성의 상대적 중요도를 측정하기 쉽다는 것이다.
- 평균적으로 불순도를 얼마나 감소시켰는지 확인해서 특성의 중요도를 측정하는데, 이것은 연관된 샘플의 수이다.
- 훈련이 끝난 뒤 특성마다 자동으로 점수를 계싼하고 중요도의 전체 합이 1이 되도록 결과값을 정규화 해서
feature_importances_변수에 저장
타이타닉 데이터에 RandomForest 적용
- 데이터 가져오기
df = sns.load_dataset('titanic') df
- 결측치 처리
rdf = df.drop(['deck', 'embark_town'], axis=1) rdf = rdf.dropna(subset=['age'], how='any', axis=0) most_freq=rdf['embarked'].value_counts(dropna=True).idxmax() rdf['embarked'].fillna(most_freq, inplace=True) rdf.info()
- 원핫 인코딩
#분석에 사용할 데이터 골라내기 ndf = rdf[['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'embarked']] #순서가 없는 범주형 데이터의 원 핫 인코딩 onehot_sex = pd.get_dummies(ndf['sex']) ndf = pd.concat([ndf, onehot_sex], axis=1) onehot_embarked = pd.get_dummies(ndf['embarked'], prefix='town') ndf = pd.concat([ndf, onehot_embarked], axis=1) ndf.drop(['sex', 'embarked'],axis=1, inplace=True) print(ndf.head())
- 정규화 - RandomForest 만 사용할 거라면 하지 않아도 결과에 별 영향이 없음
#피처 와 타겟을 분리 X = ndf[['pclass', 'age', 'sibsp', 'parch', 'female', 'male', 'town_C', 'town_Q', 'town_S']] y = ndf['survived'] #정규화 from sklearn import preprocessing X = preprocessing.StandardScaler().fit(X).transform(X) print(X[0:5])
- 훈련 데이터 와 테스트 데이터 분할
#훈련 데이터 와 테스트 데이터 분할 #데이터가 랜덤하게 배치되어 있다면 분할을 할 때 순서대로 앞에서 일정 부분은 #훈련 데이터로 사용하고 일정 부분은 테스트 데이터로 할당하면 됨 #타겟의 비율을 고려 #타겟의 비율이 고르지 않다면 여러가지 고려 #층화 추출이나 oversampling 이나 undersampling #이상치 탐지에서 이 부분이 항상 고려 대상 #훈련 데이터의 비율 - 일반적으로 0.7 이나 0.8을 많이 사용 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=42)
- 모델을 만들어서 훈련
#불순도 지표는 entropy - 기본은 gini 계수 #트리의 개수는 25개 #코어는 최대한 사용 forest = RandomForestClassifier(criterion='entropy', n_estimators=25, random_state=42, n_jobs=-1) forest.fit(X_train, y_train)
- 평가 지표 확인
y_hat = forest.predict(X_test) print(y_hat[0:10]) print(y_test.values[0:10]) from sklearn import metrics #오차 행렬 확인 tree_matrix = metrics.confusion_matrix(y_test, y_hat) print(tree_matrix) #정확도 계산 print((tree_matrix[0, 0] + tree_matrix[1,1]) / np.sum(tree_matrix)) tree_report = metrics.classification_report(y_test, y_hat) print(tree_report)
- 특성 중요도 확인
n_features = X.data.shape[1] plt.barh(np.arange(n_features), forest.feature_importances_, align='center') plt.yticks(np.arange(n_features), ['pclass', 'age', 'sibsp', 'parch', 'female', 'male', 'town_C', 'town_Q', 'town_S']) plt.xlabel('특성 중요도') plt.ylabel('특성') plt.ylim(-1, n_features) plt.show()✔ Boosting
개요
- 약한 학습기 여러 개를 연결해서 강한 학습기를 만드는 앙상블 기법
- 앞의 모델을 보완해 가면서 예측기를 학습시키는 것
Ada Boost
- 이전 예측기를 보완하는 방법으로 이전 모델이 과소 ㅈ거합했던 훈련 샘플의 가중치를 더 높이는 것으로 보완을 해나가는 방식
- 다음에 있는 예측기는 학습하기 어려운 샘플에 더 맞춰지게 되는 방식
- sklearn에서는 SAMME라는 Ada Boost의 다중 클래스 버전을 사용
- calss가 2개일 때는 Ada Boost와 동일하게 동작 - 예측기가 클래스의 확률을 추정할 수 있다면(predict_proba 사용가능) SAMM.R 이는 변종을 사용
- 클래스 확률에 기반함
## AdaBoost from sklearn.ensemble import AdaBoostClassifier #algorithm 은 확률을 계산할 수 있으면 SAMME.R 이고 없으면 SAMME #learning_rate 는 학습률 #학습률이 너무 크면 최적화 되지 않을 가능성이 높아지고 너무 작으면 훈련 속도가 느려지고 #overfitting 될 가능성이 발생 ada_clf = AdaBoostClassifier( DecisionTreeClassifier(max_depth=1), n_estimators=200, algorithm="SAMME.R", learning_rate=0.5, random_state=42 ) ada_clf.fit(X_train, y_train) y_hat = ada_clf.predict(X_test) print(y_hat[0:10]) print(y_test.values[0:10])#오차 행렬 확인 ada_matrix = metrics.confusion_matrix(y_test, y_hat) print(ada_matrix) #정확도 계산 print((ada_matrix[0, 0] + ada_matrix[1,1]) / np.sum(ada_matrix)) ada_report = metrics.classification_report(y_test, y_hat) print(ada_report)
Gradient Boosting
- 여러 개의 결정 트리를 이용하는 앙상블 기법
- Random Forest는 각각의 결정 트리가 독립적으로 동작하고 Boosting에서는 앞에서 잘못 예측한 데이터의 오차를 보완하는 방식으로 동작
- 얕은 트리(depth가 5 이하)를 여러 개 연결하는 방식
- Random Forest보다 하이퍼 파라미터에 더 민감하지만, 잘 조정하면 더 높은 정확도를 제공함
- Ada Boost 는 기본적으로 확률을 이용하고 Gradient Boosting은 경사하강법을 이용함
- sklearn에서는 GradientBoostingClassifier를 제공함
%%time #주피터 노트북에서 시간 측정할 때 사용 ## Gradient Boosting from sklearn.ensemble import GradientBoostingClassifier gbm_clf = GradientBoostingClassifier(random_state=42) gbm_clf.fit(X_train, y_train) y_hat = gbm_clf.predict(X_test) print(y_hat[0:10]) print(y_test.values[0:10])
하이퍼 파라미터
- max_depth
- max_features
- n_estimators
- 약한 학습기의 개수로, 숫자가 클수록 학습기를 많이 생성하므로 예측 성능이 좋아질 가능성이 높지만, 일정 수준까지 좋아지면 더 이상 좋아지지 않으며, 속도가 느립니다.
- 기본값은 100 - learning_rate : 학습률
- 약한 학습기가 순차적으로 유라 값을 보정해 나가는데 사용하는 계수
- 0 ~ 1 사이의 값으로 설정하며 기본값은 0.1
- 너무 적은 값을 설정하면 업데이트 되는 값이 작아져서 최소 오류 값을 찾아 예측 성능이 높아질 간으성이 높지만, 많은 약한 학습기는 순차적인 반복이 필요해서 수행시간이 오래 걸리고 최소 오류 값을 찾지 못하는 경우도 발생합니다.
- 큰 값을 적용하면 최소 오류 값을 찾지 못하고 그냥 지나쳐 버려서 예측 성능이 떨어질 가능성이 높지만, 빠른 수행이 가능합니다.
- learning_rate와 n_estimators는 상호 보완적으로 조합해서 사용
- learning_rate를 작게하고 n_estimators를 크게하면 성능이 좋아지지 않는 지점까지 조금씩 좋아질 수 있지만, 수행시간이 너무 오래 걸리는 단점이 발생함 - subsmaple
- 약한 학습기가 사용하는 데이터의 샘플링 비율로 기본값은 1로, 전체 데이터를 가지고 학습을 하는 것이고 0.5를 설정하면 전체 데이터 중에서 50%만 샘플링해서 사용하다라는 의미인데, overfitting이 의심된다면 이 값을 1보다 작은 값으로 설정하면 된다.
- 하이퍼 파라미터 튜닝
%%time
#하이퍼 파라미터 튜닝 - 시간이 있을 때는 여러 값을 설정
from sklearn.model_selection import GridSearchCV
#실제로는 4가지
params = {
'n_estimators':[100, 500],
'learning_rate': [0.05, 0.1]
}
grid_cv = GridSearchCV(gbm_clf, param_grid=params, cv=2, verbose=1)
grid_cv.fit(X_train, y_train)
print("최적의 파라미터:", grid_cv.best_params_)
print("최적의 정확도:", grid_cv.best_score_)
#튜닝의 결과로 예측
gbm_pred = grid_cv.best_estimator_.predict(X_test)
gbm_report = metrics.classification_report(y_test, gbm_pred)
print(gbm_report)특징
- 특성 중요도 그래프가 RandomForest와 거의 유사
- Gradient Boosting 은 일부 특성을 완전히 무시함
- 일반적으로는 Random Forest를 먼저 적용하고 예측하는 시간이 중요하거나 성능을 조금이라도 좋게 만들어야 하는 겨웅에 사용함
- 스케일 조정이 필요없고 범주형 데이터나 연속적인 특성을 가진 데이터에서도 잘 동작함
- 매개변수를 잘 조절해야 하며, 훈련시간이 길다.
- 트리 기반의 모델들은 희소한 고차원 데이터에는 잘 작동하지 않음
- 범주형 데이터가 많은 경우에는 성능이 떨어집니다. - 회귀를 하고자 하는 경우에는 GradientBoostingRegressor
-warm_start=True를 설정하면, 일정 횟쉬 동안 성능이 좋아지지 않으면 조기 종료가 가능함
XG Boost
- Gradient Boosting Machine에 기반을 하고 있는데, 느린 학습 시간과 과적합 규제 부재 등의 문제를 해결한 알고리즘
- 병렬 학습이 가능함
장점
- 예측 성능이 뛰어남
- GBM 대비 빠른 수행 시간
- 과적합 규제가 가능
- GBM에서는 max_depth 로 분할의 깊이를 조절하는데 XG Boost에서는 max_depth를 이용한 방법이 가능하고 tree pruning(가지 치기) 으로 더 이상 긍정 이득이 없는 분할을 가지치기를 해서 분할 수를 더 줄이는 기능
- 자체 내장된 교차 검증
- 결측값 자체 처리
설치
conda install -c anaconda py-xgboost
하이퍼 파라미터 분류
- 일반 파라미터
- 스레드의 개수나 silent 모드 등의 선택을 위한 파라미터로 거의 기본값을 수정하지 않고 사용 - 부스트 파라미터
- 트리 최적화, 부스팅, regularzation 등과 같은 파라미터 - 학습 태스크 파라미터
- 평가 지표 등을 설정하는 파라미터
일반 파라미터
- booster
- gbtree나 gblinear로 설정하는 것인데 기본은 gbtree - silent
- 출력 메시지 설정으로 1을 설정하면 메시지 출력 X - nthread
- 동시에 수행할 스레드의 개수로, 기본적으로 -1이라서 코어 수만큼 사용
- 프로세서의 일부 코어만을 사용하고자 하는 경우, 설정을 변경

밀가루 귀여워요