
✔ Pandas의 연산
그룹화
- 데이터를 어떤 기준에 따라서 여러 그룹으로 나누어서 관찰하는 것
- 그룹화를 하고, 집계, 변환, 필터링이 이어짐
- 그룹화를 할 때는,
groupby를 이용하고, 변환에는apply를 이용합니다. groupby는 DataFrame의 함수이다.
groupby(self, by=None,... ) - 이때, b
집계 함수
- count
- 누락 값을 제외한 뎅;ㅣ터의 개수- size
- 누락 값을 포함한 데이터의 개수- mean
- std
- min
- quantile(q=값)
- 백분위 수로 값은 0.0 ~ 1.0- max
- sum
- var
- sem
- 평균의 표준 편차- describe
- 데이터의 간단한 집계, 옵션에 따라 문자나 범주형도 포함
- 집계를 수행하고 나서 DataFrame으로 리턴- first
- 첫 행- last
- 마지막 행- nth4
- n 번째 행- 하나의 컬럼을 지정하면 Series를 리턴
# 집계 함수 사용 # print(grouped.std()) # 특정 컬럼 print(grouped['fare'].std()) print(grouped.fare.std()) # . 을 이용해서 컬럼에 접근할 때는 반드시 컬럼이름이 문자열이어야 합니다.
사용자 정의 함수 적용
- agg(매핑 함수)
- 여러 개의 함수를 적용하고자 하는 경우는 함수를 list로 전달하면 됩니다.
- 컬럼 마다 다른 함수를 적용하고자 할 때는 dict를 이용- transform
- 그룹 별로 구분해서 각 원소에 함수를 적용- filter
- apply
# 사용자 정의 함수 적용 # group에 ~ 를 이용해서 적용하게 된다면 매개변수로 각 그룹이 대입되는 구조 def f(group): return (group.max(), group.min()) # 하나의 함수 적용 agg_f=grouped.agg(f) print(agg_f) # 여러 개의 함수 적용 agg_two=grouped.agg([min,max]) print(agg_two) # 컬럼 마다 다른 함수 적용 agg_three=grouped.agg({'fare':min,'sex':max}) print(agg_three) #groupby 는 집계함수와 사용자 정의 함수만 써야 합니다.
# 셀 단위로 함수 적용 - transform이나 apply를 사용합니다. def z_score(x): return (x-x.mean())/x.std() age_zscore=grouped.age.transform(z_score) print(age_zscore.head()) # SQL의 Having(Group By 이후의 조건- 그룹화한 항목의 필터링)-을 만들고자 할 때는 filter 함수를 이용합니다. # 그룹화한 항목의 필터링은 그룹의 집계함수를 이용해서 필터링을 수행해야 합니다. # 행의 개수가 300개가 넘는 그룹의 데이터만 추출을 해보자. group_filter=grouped.filter(lambda x: len(x)>300) print(group_filter)
Multi Index
- 인덱스가 하나가 아니고 여러 개 인 것
- 2개 이상의 항목으로 그룹화를 하면, 멀티 인덱스가 만들어집니다.
- Multi Index로 구성된 데이터에 직접 접근을 하고자 할 때는
loc[(첫 번째 그룹 인덱스, 두 번째 그룹 인덱스,...)]를 이용하거나xs(첫 번째 그룹 인덱스, level=두 번쨰 그룹 인덱스)를 이용합니다.
# multi index print(df) # 2개의 컬럼으로 그룹화 - 멀티 인덱스 생성 grouped=df.groupby(['class','sex']) # First class 이고 sex가 male인 데이터만 골라보자. gdf=grouped.mean() print(gdf.loc[('First','male')]) print(gdf.xs('male', level='sex')) # loc로 보통 하게 된답니다.
Pivot Table
- 집계를 위한 함수 by pandas
- 첫 번째 매개변수로 DataFrame을 설정
- values에는 연산을 수행할 컬럼을 나열
- index는 행 위치에 올 컬럼을 나열
- columns는 열 위치에 올 컬럼을 나열
- margins는 전체 데이터 집계 출력 여부
- aggfunc 가 수행할 함수 나열
- fill_value는 NA일 때의 값
- class와 sex별로 age의 평균 구하기
print(pd.pivot_table(df,index='sex', columns='class', values='age', aggfunc='mean'))
Data를 읽어올 때, 컬럼 이름 및 데이터 확인을 필수적으로 해야 한다.
✔ 서울시 구별 CCTV와 인구 데이터 사용
데이터 수집
- cctv.xlsx, pop.txt 사용 예정
텍스트 파일을 읽을 때 확인할 점
- 구분 기호
- 영문과 숫자를 제외한 특수문자 포함 여부
- 숫자 데이터의 경우, 천 단위 구분 기호가 있는지 여부
- 첫 행이 컬럼 이름인지 여부
- 맨 처음 몇 행이나 마지막 몇 행이 주석이나 의미없는 데이터 인지
- 전체 ㅏ일 사이즈가 어느 정도 되는지
실습 시작
필요 라이브러리 Import
import numpy as np import pandas as pd # 시각화패키지 import matplotlib.pyplot as plt # 시각화 할 때, 한글 출력을 위함 import platform from matplotlib import font_manager, rc
데이터 읽어오기
cctv=pd.read_excel('./data/cctv.xlsx') cctv.head() # pop.txt는 첫 두 행은 의미가 없다. # 한글을 포함한다. # 구분 기호는 탭 # 천 단위 구분 기호가 존재함 pop=pd.read_csv('./data/pop.txt', skiprows=2, delimiter='\t', thousands=',') pop.head() # 계 1, 남자1,... 이런 것은 컬럼 이름이 똑같기에 자동 변경을 한 것이다.
데이터 구조 확인하기
cctv.info() pop.info()
데이터 정보 수정하기 (컬럼 등..)
- pandase의 DataFrame이나 Series의 편집 함수들은 대부분 데이터를 복제해서 작업을 하고 리턴을 하는데, 분석을 아주 길게 해야 되는 경우, 이 방식은 메모리를 많이 사용하게 됩니다.
- pandas에서는 대다수의 편집 함수에 어쩌구
cctv.rename(columns={cctv.columns[0]:'구별'}, inplace=True) pop.rename(columns={pop.columns[1]:'구별'}, inplace=True) # CCTV의 구별 데이터는 중간에 공백이 존재하고, pop은 구 이름에는 공백이 없음 gu=[] for x in cctv['구별']: gu.append(x.replace(' ', '')) cctv['구별']=gu cctv.head()
불필요한 열과 행 제거
- 데이터에서 직접 제거해도 되고, 원하는 데이터만 추출해도 됩니다.
# pop 데이터에서 기간, 구별, 계, 남자, 여자 열만 필요하다. pop=pop[['기간', '구별', '계', '남자', '여자']] # pop 데이터의 첫 번째 행의 전체 데이터의 집계라서 불필요 합니다. pop.drop([0], inplace=True) #새로운 열을 추가합니다. - 없는 열 이름에 데이터를 대입하면 됩니다. pop['여성비율']=pop['여자']/pop['계']*100 pop.head()2개의 데이터 프레임 결합 - merge / join 이용
df=pd.merge(cctv, pop, on='구별') df.head()
결합된 데이터 프레임에서 불필요한 컬럼 삭제
# 2018 이전 버전은 안보고 싶다. # del을 이용해보자. (pandas에서는 비추천) del df['2011년 이전'] del df['2012년'] del df['2013년'] del df['2014년'] del df['2015년'] del df['2016년'] del df['2017년'] del df['기간'] df.head()
인덱스 재설정하기
- Series나 DataFrame은 행 단위 선택을 할 때, 인덱스를 이용합니다.
- DataFrame을 만들 때, primary key 역할을 하는 데이터가 존재한다면 index로 설정하는 것이 좋습니다.
- DataFrame에 인덱스를 잘 설정하면 DataFrame을 이용해서 Pandas의 차트를 만들때 편리함
- 탐색적 시각화는 Pandas의 시각화를 이용하는 것이 편리하다.
df.set_index('구별', inplace=True) df.head()
Pandas의 시각화 기능을 이용해서 소계에 대한 막대 그래프 그리기
- matplotlib의 기본 폰트가 한글을 지원하지 않기 때문에 폰트를 재설정
- 운영체제별로 폰트의 위치가 다르므로 조건문을 이용해서 설정
- Windows의 경로를 설정할 때, / 로 디렉 구분해도 \로 변경해서 적용합니다.
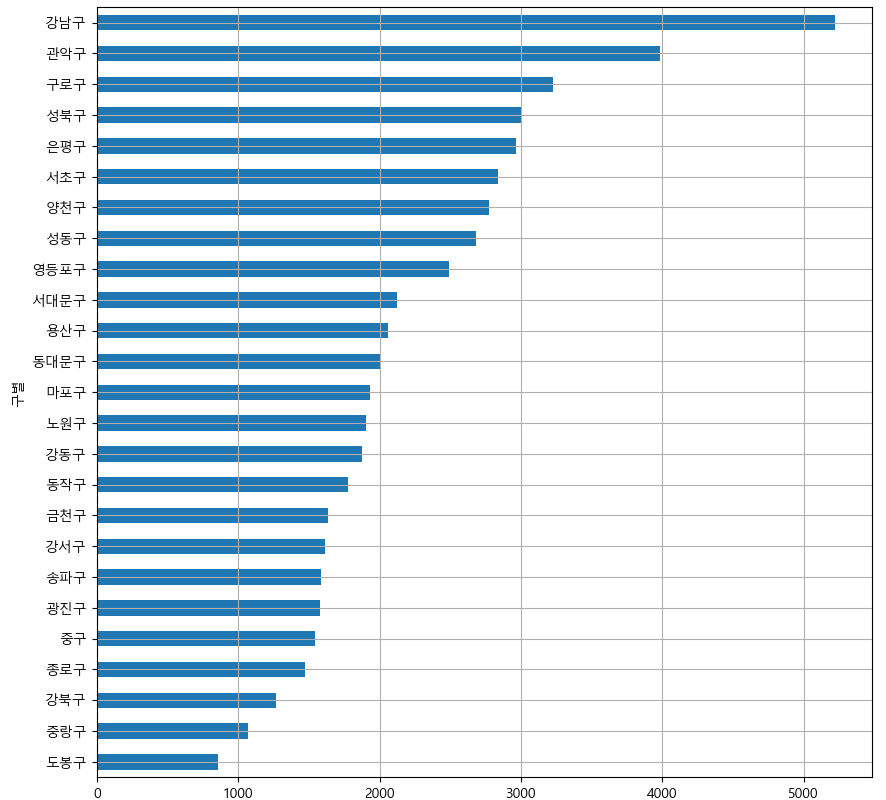
if platform.system()=='Darwin': rc('font', family='AppleGothic') elif platform.system()=='Windows': font_name=font_manager.FontProperties(fname='c:/Windows/Fonts/ malgun.ttf').get_name() rc('font', family=font_name) df['소계'].plot(kind='barh', grid=True, figsize=(10,10)) plt.show()
데이터를 정렬해서 막대그래프로 다시 그려보기
df['소계'].sort_values().plot(kind='barh', grid=True, figsize=(10,10)) plt.show()
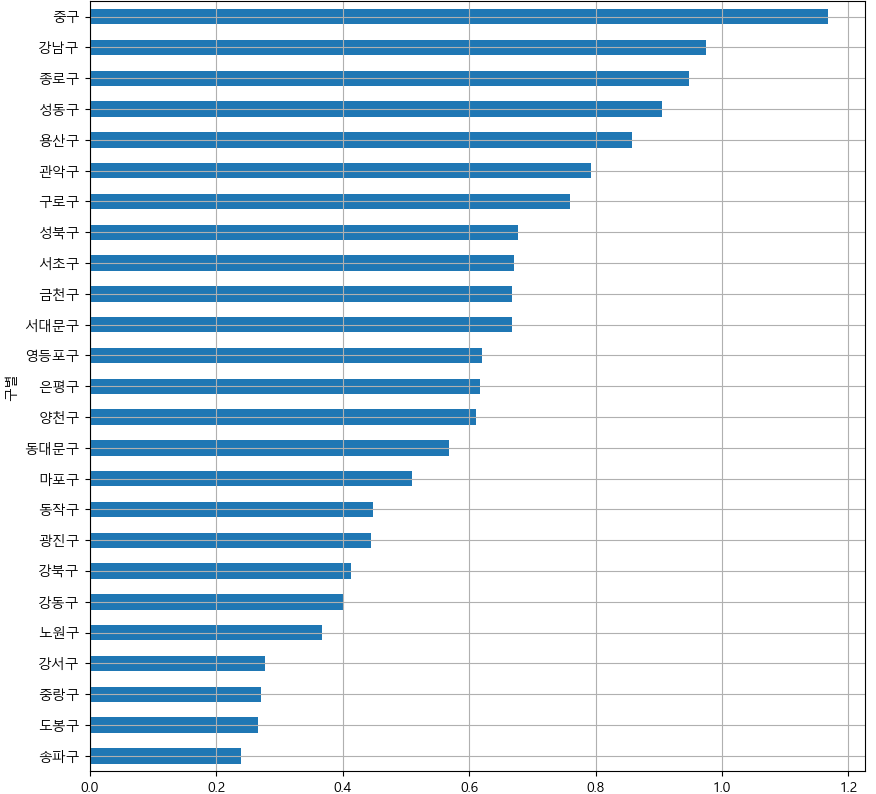
인구수 대비 CCTV 비율을 만들어서 시각화해보자.
df['cctv비율']=df['소계']/df['계']*100 df['cctv비율'].sort_values().plot(kind='barh', grid=True, figsize=(10,10)) plt.show()
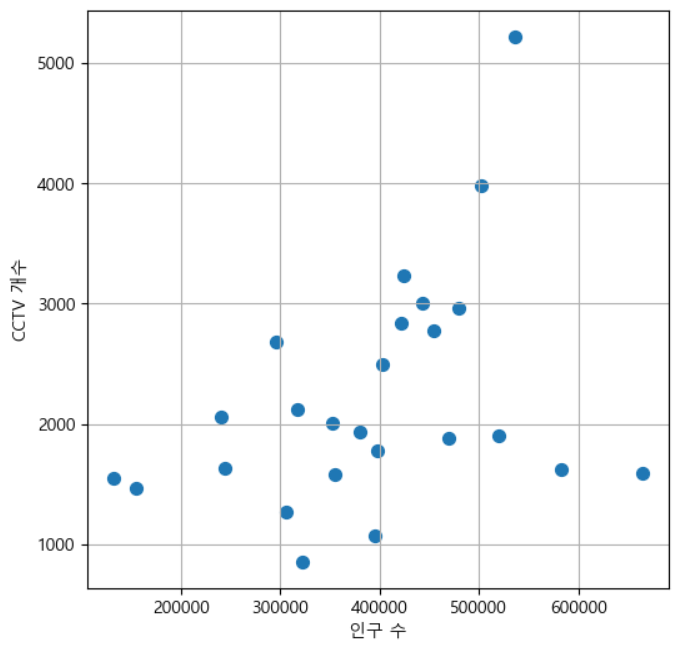
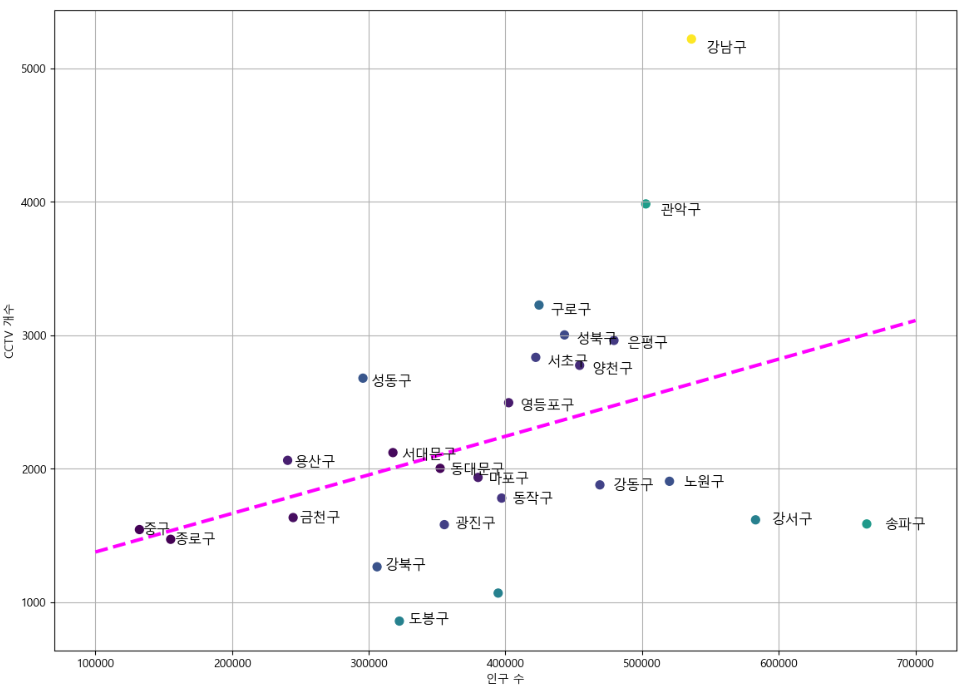
인구수와 CCTV 개수 사이에 연관성이 있는지 확인 - 산점도가 유용합니다.
- 산점도(산포도)를 그리는 경우에는 방향성과 그룹화 가능성을 확인합니다.
plt.figure(figsize=(6,6)) plt.scatter(df['계'], df['소계'], s=50) plt.xlabel('인구 수') plt.ylabel('CCTV 개수') plt.grid() plt.show()
- 그룹도 아니고, 방향도 애매합니다.
- 실제로 인구하고는 매우 밀접하지는 않다는 것을 알 수 있습니다.
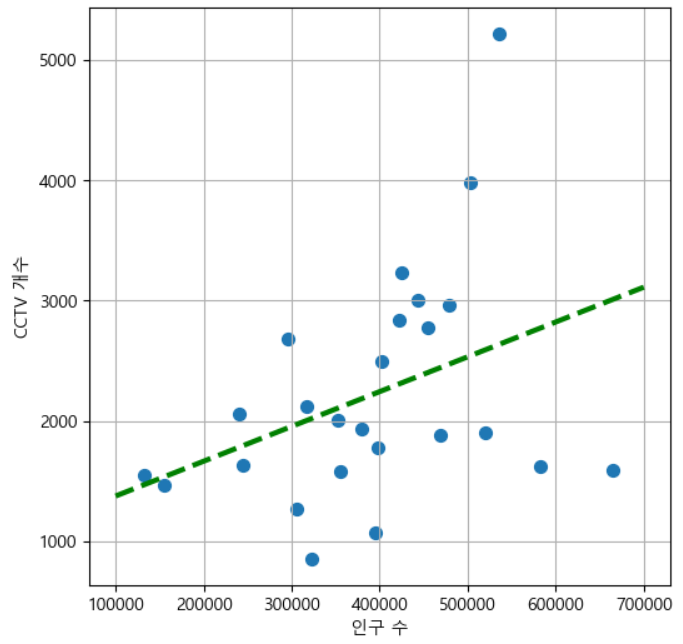
추세선을 만들고 Scatter 위에 그려보자.
fp1=np.polyfit(df['계'],df['소계'], 1) f1=np.poly1d(fp1) print(f1)
0.002892 x + 1087라는 값이 나왔다.# 산점도 와 단항식을 같이 출력 fx=np.linspace(100000, 700000, 100) plt.figure(figsize=(6,6)) plt.scatter(df['계'], df['소계'], s=50) plt.plot(fx,f1(fx), ls='dashed', lw=3, color='g') plt.xlabel('인구 수') plt.ylabel('CCTV 개수') plt.grid() plt.show()
그래프에 추세선과의 차이를 출력해보자
# 2개 항목의 단항식을 구하기 fp1=np.polyfit(df['계'],df['소계'], 1) f1=np.poly1d(fp1) print(f1) # 산점도 와 단항식을 같이 출력 fx=np.linspace(100000, 700000, 100) # 오차를 구해보자. # 오차가 크다면 해당 추세선은 믿을 수 없다. df['오차']=np.abs(df['소계']-f1(df['계'])) plt.figure(figsize=(14,10)) plt.scatter(df['계'], df['소계'],c=df['오차'], s=50) plt.plot(fx,f1(fx), ls='dashed', lw=3, color='magenta') # 좌표를 지정해서 레이블을 출력하기 for n in range(24): plt.text(df['계'][n]*1.02, df['소계'][n]*0.98, df.index[n], fontsize=12) plt.xlabel('인구 수') plt.ylabel('CCTV 개수') plt.grid() plt.show()
✔ Choropleth - 단계 구분도
- 지도에 색상이나 마커를 이용해서 크기를 표시하는 시각화 방법
- 카토그램과 다른 점은 영역의 크기를 왜곡하지 않습니다.
생성방법
- Folium 패키지를 이용해서 지도를 출력하고,
choropleth함수를 호출해서 geo_data옵션에 ID와 위도, 경도를 가진 json 파일 경로를 설정 - key_on 에 json 파일에서 사용되는 id 컬럼을 지정
한국 지리 정보
- 미국 지리는 내장이지만, 한국 지리는 가져와야 합니다.
- https://github.com/southkorea/southkorea-maps
✔ 데이터 구조화
- 인덱스와 컬럼을 변경하는 작업
- Stack
- 행을 컬럼으로 피벗시키는 작업 - Unstack
- 컬럼을 행으로 피벗시키는 작업
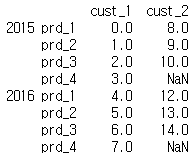
Stack 함수
- 컬럼을 인덱스로 변경해주는 함수
mul_index=pd.MultiIndex.from_tuples([('cust_1', '2015'), ('cust_1', '2016'), ('cust_2', '2015'), ('cust_2', '2016')]) data=pd.DataFrame(data=np.arange(16).reshape(4,4), index=mul_index, columns=['prd_1','prd_2','prd_3','prd_4'], dtype='int') print(data) data_stacked=data.stack() print(data_stacked)
- 컬럼들이 하위 인덱스가 됩니다.

- dropna 옵션을 이용해서 None인 데이터를 제외할 지 여부를 설정
- 기본은 True라서 제외됩니다.
Unstack 함수
- 인덱스를 컬럼으로 변경해주는 함수
- 매개변수로 level을 받는데, level은 몇 번째 레벨의 인덱스를 컬럼으로 변경할 지 설정
- stack을 할 때, dropna 속성을 False로 설정한 경우는 완전한 복원이 이루어지지만, True로 한 경우는 완전한 복원이 이루어지지 않을 수 있습니다.
- 0레벨의 인덱스가 컬럼으로 변경됩니다.
print(data_stacked.unstack(level=0))
시계열 데이터의 재구조화
- 시계열 데이터를 만들다 보면, 년월일 등을 쪼개서 저장하는 경우가 있는데, 데이터를 분석할 때 이렇게 쪼개져 있는 것이 불편한 경우가 많습니다.
- 이런 경우, 년월일을 합쳐서 하나의 컬럼으로 만들고 시간 순으로 나열해서 인덱스로 만드는 경우가 있습니다.
시계열 인덱스 만들기
data=pd.read_csv('./data/macrodata.csv') data.head() # year와 quarter를 합쳐 시계열 데이터를 만들어보자. # 시계열 인덱스 생성 periods=pd.PeriodIndex(year=data['year'], quarter=data['quarter'], name='date') print(periods) columns=pd.Index(['realgdp', 'infl', 'unemp'], name='item') # print(columns) data=data.reindex(columns=columns) print(data) data.index=periods.to_timestamp('D', 'end') data
melt
- pivot과 반대되는 연산으로, 여러 개의 컬럼을 하나의 컬럼으로 만들 때 사용
pandas.melt(DataFrame, id_vars=[남겨둘 컬럼 나열])- 남겨둘 컬럼을 제외한 컬럼의 이름은 열(variable)의 값이 됩니다.
- 컬럼의 데이터들은 열(value)의 값이 됩니다.
- 너무 많은 컬럼들이 존재할 때, 컬럼의 개수를 줄이기 위해서 사용합니다.
data=pd.DataFrame({'cust_id':[1,2,3,4], 'prod_id':['a','b','c','d'], 'pch_cnt':[1,2,3,4],'pch_price':[100,200,300,400], 'pch_amt':[10,20,30,40]}) print(data) result=pd.melt(data, id_vars=['cust_id','prod_id']) print(result)

crosstab
- 도수분포표 만들 때 사용
- 범주형 컬럼의 교차 분석에 사용합니다.
pandas.crosstab(행 방향에 사용할 컬럼 이름 나열, 열 방향에 사용할 컬럼 이름 나열, rownames=행의 이름, colnames=열의 이름, margins=전체 합계 출력 여부, normalize=정규화 여부)
data=pd.DataFrame({'id':['id1','id1','id1','id2','id2','id3'], 'fac_1':['a','a','a','b','b','b'], 'fac_2':['c','c','d','d','d','d']}) #fac_1과 fac_2의 빈도 분석을 해봅시다. print(pd.crosstab(data['fac_1'],data['fac_2'], rownames=['사실'], colnames=['거짓'], normalize=True)) print('\n\n') print(pd.crosstab(data.id, [data['fac_1'],data['fac_2']]))

Cartogram
- 변량 비례도 or 왜상 통계 지도
- 지도의 면적을 왜곡해서 데이터를 표현하는 방식
✔ 데이터 전처리 - Pre Processing
- 데이터를 분석하기 전에 분석하기에 알맞은 데이터로 변환하는 작업
- 소스에서 가공하는 경우도 있고 읽어내고 가공을 하기도 합니다.
- DB에서 가져오는 경우 SQL 이나 함수를 이용해서 가공된 형태로 가져오기도 합니다.
- 데이터 전처리는 하고자 하는 분석 방법에 따라서 데이터 형태에 따라서 달라집니다.
- 데이터 형태를 구분할 때는 수치 데이터, 문자열 데이터, 범주형 데이터, 이미지 데이터, 시계열 데이터로 분류를 합니다.
수치 데이터
단위 환산
- 여러 나라에서 데이터를 수집하는 경우, 나라마다 단위를 다르게 사용해서 직접 비교하기가 곤란한 경우가 있을 수 있습니다.
- 이런 경우, 데이터를 동일한 단위로 환산을 해주어야 하고, 데이터를 분석해서 결과를 만들 때 그 나라에 맞는 단위로 환산을 해서 결과를 만들어야 합니다.
자료형 변환
- 데이터의 자료형을 변경하고자 하는 경우, 읽을 때는 dtypes 속성을 사용해서 자료형을 확인하고 astype 함수를 이용해서 형 변환이 가능합니다.
- 데이터를 읽을 때, 천 단위 구분 기호가 있는 경우 옵션 설정을 하지 않으면 문자열로 판단합니다.
- None이 있는 경우도 종종 문자열로 판단하는 경우가 있습니다.
# 첫 번째 행이 컬럼 이름이 아닌 경우, df=pd.read_csv('./data/auto-mpg.csv', header=None) df.columns=['mpg','cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model year', 'origin', 'name'] df.head() print(df.dtypes) df.info()
- 데이터의 자료형 확인은 dtypes 속성이나 info()를 호출하면 됩니다.
- horsepower는 마력인데, 마력은 숫자 데이터로 알고 있지만, object 형태로 되어있다.
- 그렇다면 이 데이터는 회귀분석 등에 사용할 수 없다.
- 즉, 숫자 데이터로 바꿔야 합니다.# horsepower 컬럼의 자료형을 float으로 변경하려 한다. # df['horsepower']=df['horsepower'].astype('float') # 데이터의 종류가 많지 않다면 중복제거 한 것을 print해서 봐보자. # print(df['horsepower'].unique()) # ? 값을 NaN으로 설정하고, NaN인 데이터를 제거하자. df['horsepower'].replace('?',np.nan, inplace=True) df.dropna(subset=['horsepower'], axis=0, inplace=True) df['horsepower']=df['horsepower'].astype('float') # 에러 없이 잘 되는 것을 확인할 수 있다. print(df['horsepower'].unique())
- origin 이라는 열은 1, 2, 3이라는 값만 소유하고 있습니다.
- 이 값은 실제로 미국 , 유럽, 일본을 의미하는 숫자입니다.
- 분석을 할 때는 미국, 유럽, 일본으로 보여지는 것이 더 나을 수 있습니다.
- 이런 경우는 새로운 컬럼을 추가해서 보여지도록 할 수 도 있고, 컬럼의 값을 변경할 수 도 있습니다.
- 범주형으로 변경해 두는 것이 분석 속도를 높이는데 도움이 됩니다.
df['origin'].replace({1:'미국', 2:'유럽', 3:'일본'}, inplace=True) # 범주형으로 변환하기 df['origin']=df['origin'].astype('category') df.head()

밀가루 귀여워요
많은 도움이 되었습니다, 감사합니다.