
✔ Python help() & Docs
- python help docs에서 함수 파라미터에 **kwargs 라 적혀있으면 dict이다.
- 이름, 매개변수, 리턴값 을 제대로 이해해야 한다.
- 내가 처음 본 것이면 help라도 찍어서 어떤 역할을 하는지 확인하자.
- 설명을 보면 대입을 할수 있는지 확인해야 한다.
- =이 없으면 필수, 있으면 기본값이 있기에 optional하다.
- 매개변수에서 이름을 생략할 수 없다. 할 순 있지만, 모든 매개변수를 순서대로 다 입력해야 한다.
- *args는 임의의 개수의 인수(arguments)를 뜻합니다. 여러 개의 인수를 받아서 "튜플"의 형태로 저장해줍니다.
- *kwargs는 임의의 개수의 키워드 인수(keyword arguments)를 뜻합니다. 여러 개의 키워드 인수를 받아서 '딕셔너리'의 형태로 저장해줍니다.
✔ 탐색적 시각화
데이터가 주어진다면, 탐색을 충분히 해야 한다.
탐색이 안된다면, 전처리는 의미가 없다.
히스토그램
- 빈도 분석을 위해서 그리는 차트
- 변수가 하나인 단변수 데이터의 빈도 수를 표현
- Series에
value_counts()라는 메서드를 호출하면, 빈도수를 리턴 hist()를 호출해서 히스토그램을 그릴 수 있다.
-bins옵션으로 구간의 개수를 설정하는 것이 가능하다.
# lovefruits.cvs # 첫행은 컬럼이름, 구분자는 , 한글존재함 df=pd.read_csv('./data/lovefruits.csv', encoding='CP949') # df.head() # 데이터 정보 확인하기 # df.info() # 빈도수 확인을 해보자. data=df['선호과일'].value_counts(sort=False) # print(data) plt.hist(df['선호과일']) plt.show()
df=pd.read_csv('./data/student.csv', encoding='cp949') # df.head() # df.info() # 점수 처럼 여러 값이 존재한다면? # 구간을 나눠서 시각화하는 것이 좋아 보인다. plt.hist(df['수학'], bins=3) plt.show()
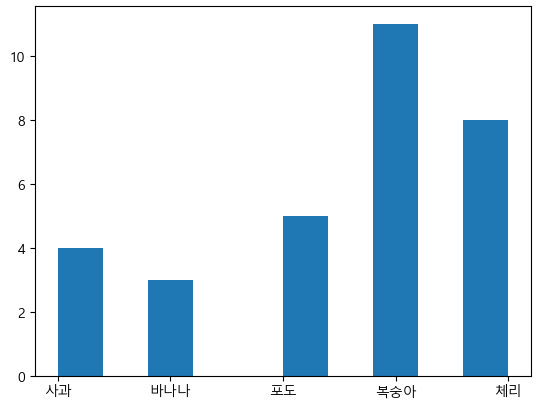
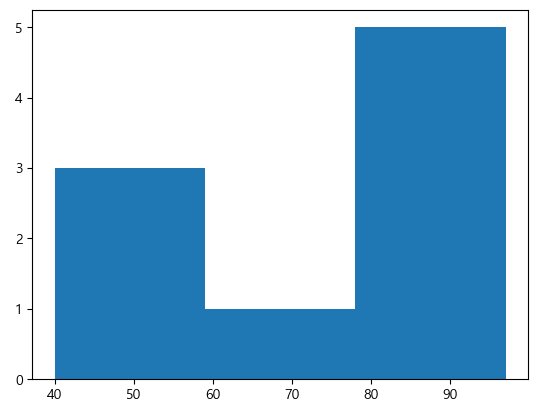
Scatter - 산포도, 산점도
- 자료의 분포를 표시할 때 이용하는 그래프로 서로 다른 두 변수 사이의 관계를 표현
- 각 변수는 연속적인 값이어야 합니다.
scatter()를 이용해서 출력하기
df=pd.read_csv('./data/student.csv', encoding='cp949') plt.figure() # 색상 설정 colormap=df.index plt.scatter(x=df.index, y=df['국어'], marker='o', c=colormap) # 이게 무슨 시각화 그래프인데? plt.title('학생 별 국어 점수 분포') # 누가 누군지 모르겠어. plt.xticks(range(0,len(df['국어'])), df['이름'], rotation='vertical') plt.show()
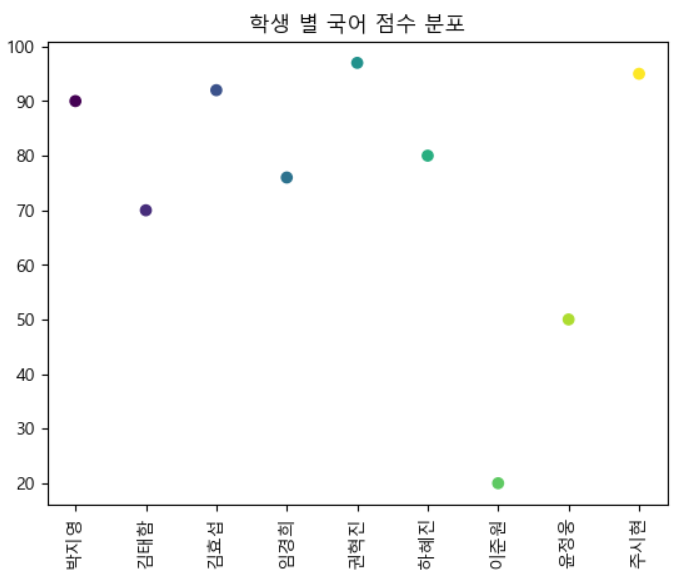
- 산포도는 일반적으로 4개의 항목까지 설정이 가능
- 가로(x), 세로(y), 색상(c), 크기(s) 에 설정이 가능 (Tableau 때도 이랬음)
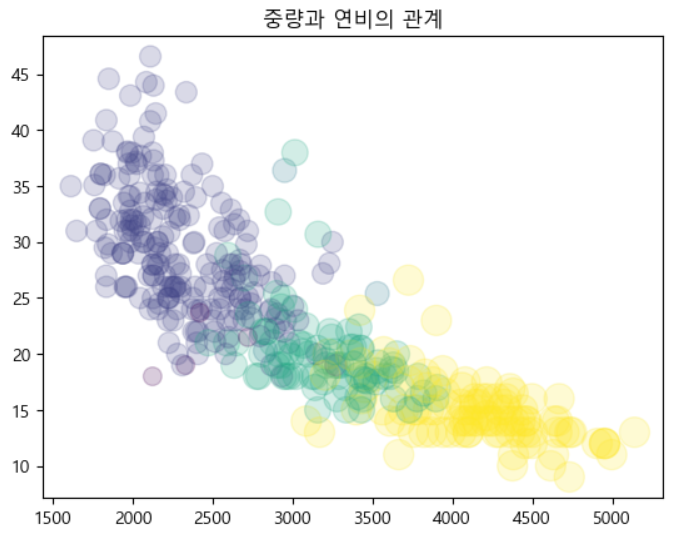
# 여러 개의 컬럼을 이용한 산포도 # 이 데이터는 회귀분석하는데 좋은 데이터임 (다항) df=pd.read_csv('./data/noheader_auto-mpg.csv', header=None) df.columns=['mpg','cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model year', 'origin', 'name'] # df.head() # 존재하지 않는 컬럼 -> 추가됨 df['cylinders_size']=df['cylinders']/df.cylinders.max()*300 # df.head() colormap=df['cylinders'] plt.scatter(x=df['weight'], y=df['mpg'], s=df['cylinders_size'], c=colormap, alpha=0.2) plt.title("중량과 연비의 관계") plt.show()
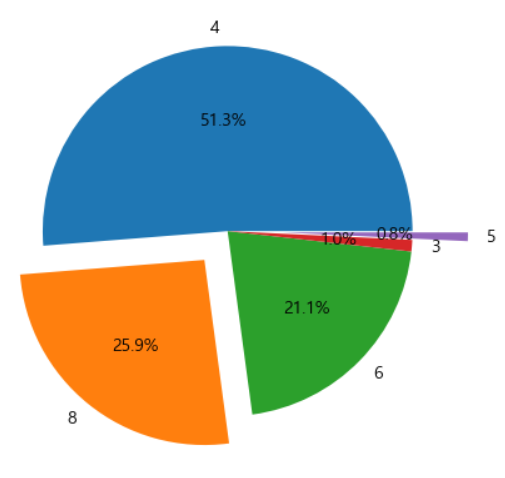
Pie Chart
- 전체에 대한 기여도 확인 가능
- Pie 함수를 이용해서 출력을 하는데, explode 옵션을 이용해서 중앙에서 떨어지는 비율을 설정할 수 있고, autopct를 이용해서 값의 비율을 출력할 수 있습니다.
- Pie Chart는 항목이 많은 경우에는 사용하기가 곤란합니다.
- 이런 답도 없는 그래프가 될 수 있습니다.
x=df['cylinders'].value_counts() # print(type(x)) # 중심으로부터 떨어뜨리는 비율 explode=(0,0.2,0,0,0.3) plt.pie(x, labels=x.index, autopct='%1.1f%%', explode=explode) plt.show()
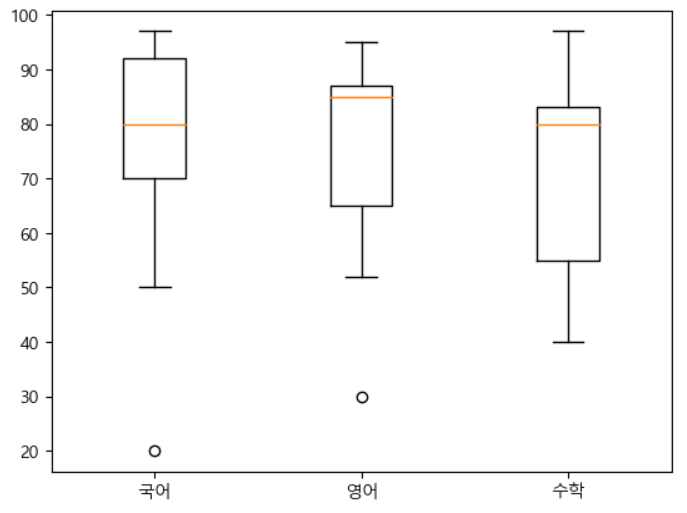
Box Plot
- 상자와 수염으로 출력하는 그래프
Median
- 중간값, 50%가 되는 지점
Q1
- 하위 25%에 위치하는 값
- 상자의 경계선
Q3
- 상위 25%에 위치하는 값
- 상자의 경계선
IQR
- Q3-Q1
수염의 양 끝
Q1-1.5*IQR, Q3+1.5*IQR
- 표준 정규 분포에서는 Median이 Q1과 Q2의 주앙에 위치하고, 수염의 양끝 안에 99.3% 정도의 데이터가 위치하게 됩니다.
Q1-1.5*IQR와Q3+1.5*IQR의 값과 Q1, Q3사이에 24.64% 정도가 위치하게 됩니다.- 상자와 수염 밖의 데이터를 일반적으로 이상치로 간주합니다.
- 값의 분포가 넒지 않으면 이상치가 아닐 수 있는 데이터가 이상치가 될 수 있습니다.
- 하나만 주면 하나를 주지만 여러개 넣으면 여러개 그려줌
df=pd.read_csv('./data/student.csv', encoding='cp949') plt.boxplot((df['국어'], df['영어'], df['수학']), labels=('국어', '영어','수학')) plt.show()
면적 그래프
- 선 그래프와 유사하지만, 영역이 색상으로 채워진 그래프
- 목적은 선 그래프와 동일하다.
fill_between함수로 생성
✔ Seaborn
- matplotlib을 기반으로 다양한 색상 테마와 통계용 차트 등의 기능을 추가한 시각화 캐지지로, numpy와 pandas의 자료구조를 지원
- 샘플 데이터 제공
- 통계기능은 scipy나 statsmodels 패키지에 의존
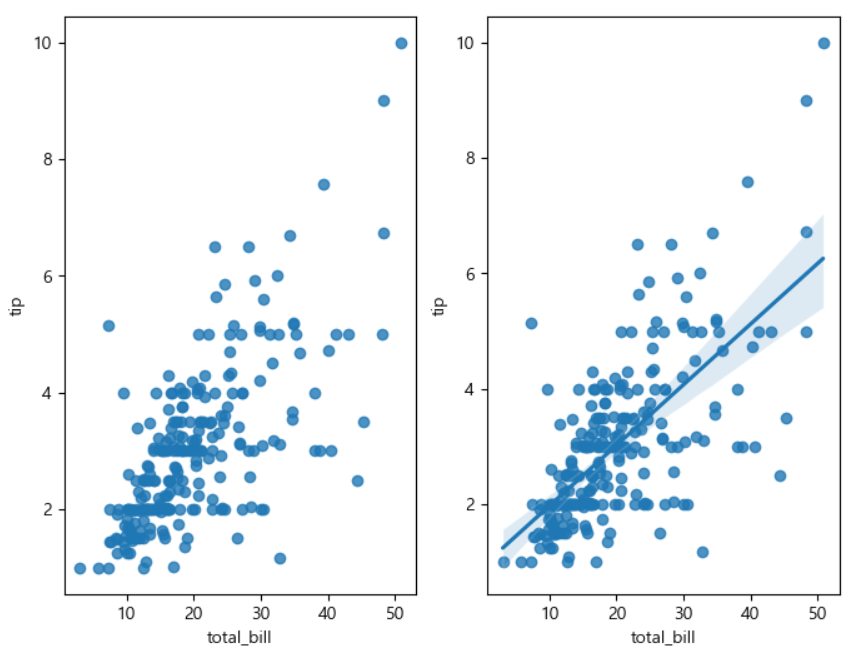
import seaborn as sns tips=sns.load_dataset('tips') tips.head() fig=plt.figure(figsize=(8,6)) ax1=fig.add_subplot(1,2,1) ax2=fig.add_subplot(1,2,2) sns.set_style('darkgrid') sns.regplot(x='total_bill', y='tip', data=tips, fit_reg=False, ax=ax1) sns.regplot(x='total_bill', y='tip', d ata=tips, fit_reg=True, ax=ax2) plt.show()
Folium
- 지도를 출력할 때 사용하는 패키지로, html 출력을 만들 수 있다.
- 정적인 지도입니다.
- 다양한 지도를 원한다면 developer.kakao.com 생각해보자.
- JS 기반으로 Interactive하게 출력이 가능합니다.
- Chrome 브라우저에서는 바로 출력이 가능하고, 다른 곳에서는 맵을 저장한 후 출력
- document : http://python-visualization.github.io/folium
- 단계 구분도를 만들 수 있는데, 이 때는 지역 경계에 대한 좌표를 json으로
import folium m=folium.Map(location=[37.572656, 126.973304], zoom_start=15) # 마커 출력 folium.Marker(location=[37.572656, 126.973304], popup='KB카드', icon=folium.Icon(icon='cloud')).add_to(m) folium.Marker(location=[37.569027, 126.987279], popup='Mega IT', icon=folium.Icon(icon='cloud')).add_to(m) folium.RegularPolygonMarker(location=[37.602638,126.955252], popup='mino', icon=folium.Icon(icon='cloud'), number_of_sides=6, radius=30, color='magenta').add_to(m) # 저장하기 # m.save('map.html') m
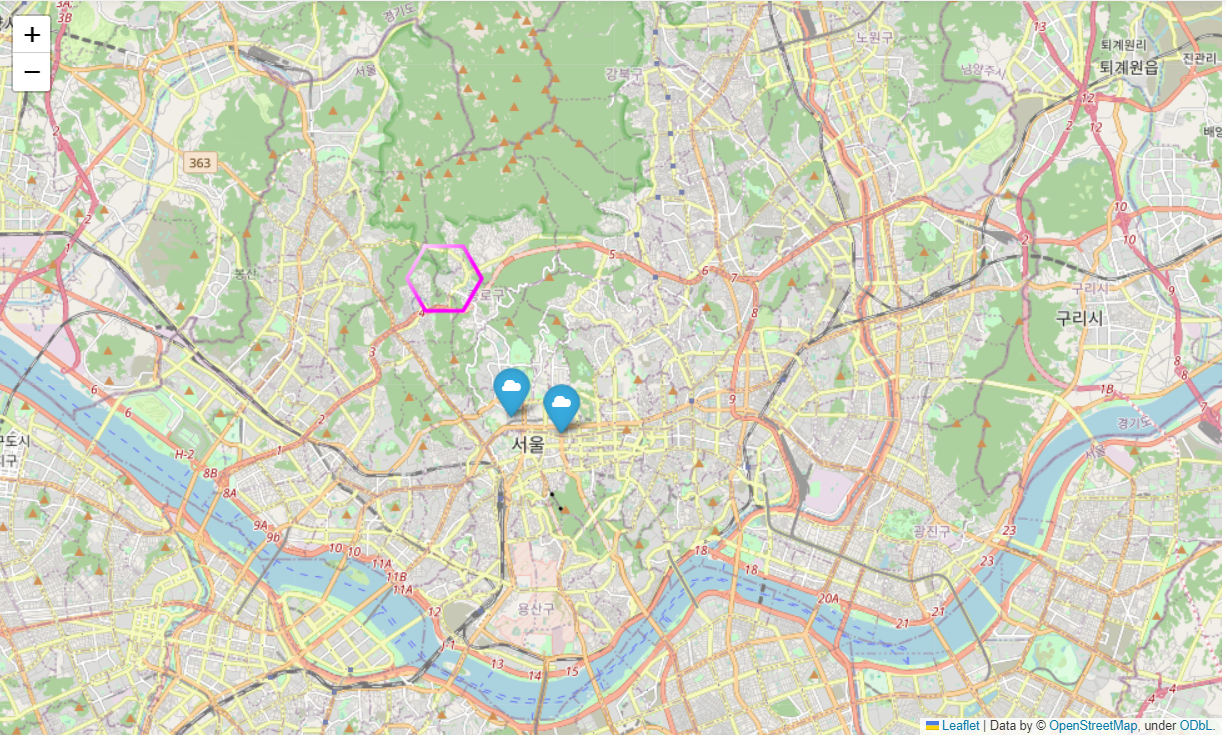
서울지역 대학교 위치 데이터를 받아서 표시해보자.
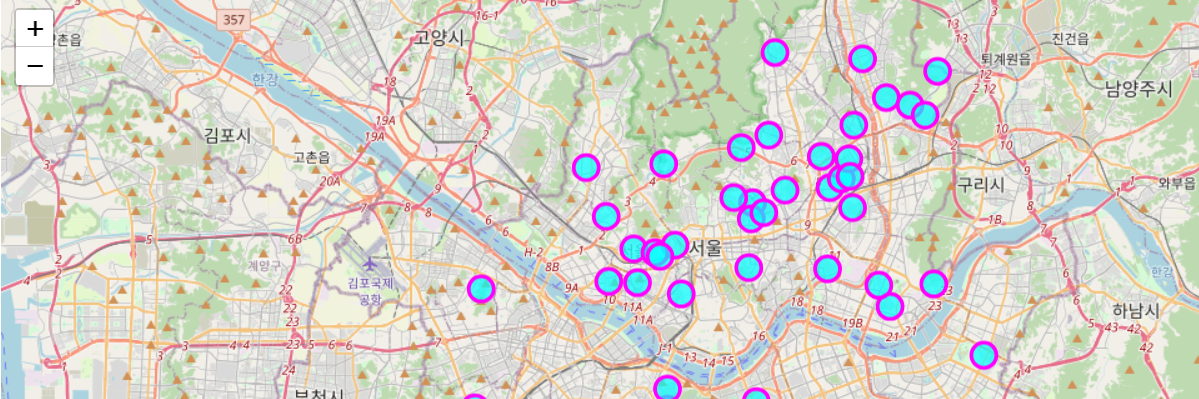
df=pd.read_excel('./data/서울지역_대학교_위치.xlsx') df.head() df.info() # 서울 지도 출력하기 m=folium.Map(location=[37.55, 126.98], zoom_start=12) # df의 데이터를 순회해보자. # 우선 확인 먼저 # for name, lat, lng in # zip(df['Unnamed: 0'], df['위도'], df['경도']): # print(name, lat, lng) for name, lat, lng in zip(df['Unnamed: 0'], df['위도'], df['경도']): folium.CircleMarker(location=[lat, lng], popup=name, radius=10, color='magenta', fill=True, fill_color='cyan', fill_opacity=0.7).add_to(m) m
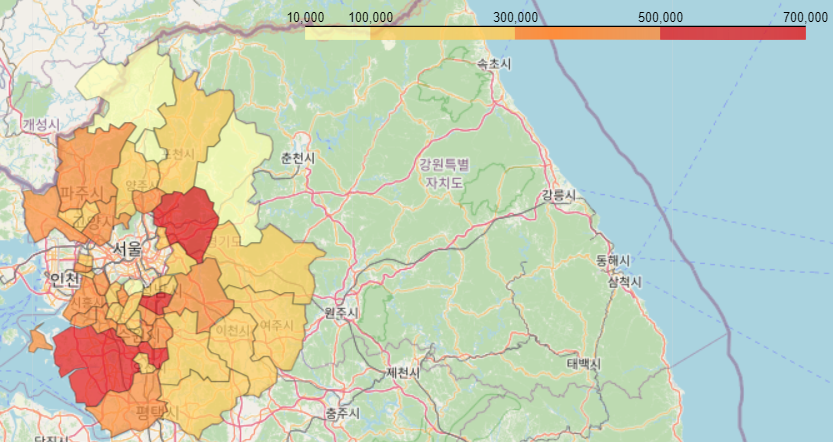
단계 구분도
- 지도에 색상을 이용해서 값의 크기를 표현하는 방법
- 행정 구역에 대한 경계선 좌표가 필요
- 이 좌표는
# json 파싱을 위한 패키지 import json # 경기도 인구 데이터 가져오기 df=pd.read_excel('./data/경기도인구데이터.xlsx') # df.head() # df.info() # 컬럼의 이름이 숫자 형태라서 사용하기 번거로울 수 있기에, 문자열로 변환 df.columns=df.columns.map(str) # 행정 구역 경계와 관련된 json파일을 열어서 파싱 try: geo_data=json.load(open('./data/경기도행정구역경계.json', encoding='utf-8')) except: geo_data=json.load(open('./data/경기도행정구역경계.json', encoding='utf-8-sig')) # print(geo_data) # 지도 생성 df.index=df['구분'] g_map=folium.Map(location=[37.5502, 126.982], zoom_start=9, titles='Stamen Terrain') # g_map # 단계 구분도 만들기 folium.Choropleth(geo_data=geo_data, data=df['2015'], columns=[df.index, df['2015']], fill_color='YlOrRd', fill_opacity=0.7,line_opacity=0.3, threshold_scale=[10000,100000,300000,500000,700000], key_on='feature.properties.name').add_to(g_map) g_map
pandas에서도 시각화 지원
- 데이터를 가지고 plot()을 호출해서 추력
- 축 제목 등을 설정하지 않아도 자동으로 설정
- DataFrame을 이용해서 plot을 호출하면 index가 x축이 되고, 숫자 데이터들이 y축이된다.
선 그래프 : plot
df.pd.read_Csv('./data/seoul.csv', ecoding='cp949')df.plot()막대 그래프
plot(kind='bar')산점도 그래프
plot(kind='scatter')히스토그램
plot(kind='hist')커널 밀도
plot(kind='bar')박스 플롯
plot(kind='box')
kind에 지정만 해주면 해당 모양의 차트를 만들어줍니다.
jupyter에서 애니메이션 효과 보려면?
✔ Pandas 활용
중복 데이터 처리
- 동일한 데이터가 여러 개 존재하면 분석 결과를 왜곡하는 경우가 발생할 수 있음
duplicated()
- 데이터의 중복 여부를 bool의 Series로 리턴
drop_duplicates()
- 중복 데이터를 제거해주는 함수
- 아무런 옵션이 없다면 모든 컬럼의 값이 같은 경우를 제거
- subset 옵션에 컬럼 이름이나 컬럼 이름의 list를 대입하면, 대입된 컬럼의 값이 같은 경우 중복 데이터로 간주하고 제거함
- keep 옵션에 남길 데이터를 설정할 수 있음(첫 번째 데이터, 마지막 데이터,.. 뭐 남길래?)
- inplace 옵션이 존재합니다. 수정해서 바로 리턴 혹은 복사해서 보여줄거냐.
- 이 옵션의 기본값은 항상 False이다.
df=pd.DataFrame([['바밤바','안녕하세요','헬로우', '니하오', '바밤바'], ['한국', '미국', '중국', '일본','한국']]) df=df.T # 전치 # 중복 여부 확인 # print(df.duplicated()) df.drop_duplicates(inplace=True) print(df.duplicated()) df
함수 적용
❗ apply
- Series(DataFrame의 하나의 열)에서 호출하면, 모든 요소에 함수를 적용
- DataFrame에서 호출하면 axis=0은 열단위로 함수 적용, axis=1은 행 단위로 함수를 적용합니다.
- DataFrame에서 셀 단위로 적용하고자 하는 경우에는
applymap함수를 호출합시다. 근본적으로 열, 행 단위 호출이라 셀 단위는 안된다.
def f(data): return data+'...' # lambda 라면? lmabad data : data+'...' # print(df[0].apply(f)) # Series는 셀 단위 적용 # print(df.apply(f)) # DataFrame은 행이나 열 단위 적용, 기본은 열 단위적용 # 이번엔 람다로 바꿔보자. print(df[0].apply(lambda data : data+'..')) print(df.apply(lambda data : data+'..!')) # python 람다식은 한줄인 것을 기억하자.titanic=sns.load_dataset('titanic') # titanic.head() # 특정한 셀만 쪼개보기 df=titanic[['age','fare']] # df.head() def min_max(data): return data.max()-data.min() result=df.apply(min_max, axis=0) result # 열 단위로 들어가니까 # 결과는 열 당 1개씩만 나올 수 밖에 없어. # 행 단위로 한다면? # result2=df.apply(min_max, axis=1) # result2 # 한 행에서 하기에 말이 안되는 연산이긴 함.
pipe
- DataFrame에 사용하는 함수
- 대입되는 함수에 따라서 결과가 달라집니다.
- scala Data를 가지고 작업하는 함수를 대입하면 DataFrame을 리턴합니다.
- 셀 단위로 적용 - 집계를 하는 함수를 대입하면 Series를 리턴합니다.
- Series를 리턴하는 함수를 대입하면, 하나의 값을 리턴합니다.
- Pipe는 대입되는 함수에 따라서 리턴도 달라집니다.
df=titanic[['age','fare']] # df.head() # 하나의 데이터를 가지고 null 여부를 판단하는 함수 대입 # 셀 단위로 적용을 해서 DataFrame 리턴 def missing_value(x): return x.isnull() # 집계 함수를 곁들인, 열 단위로 대입해서 집계를 수행한 뒤에 Series 리턴 print(df.pipe(lambda x: missing_value(x).sum())) def missing_count(x): return missing_value(x).sum() # Series를 리턴하는 함수를 대입하면 하나의 값을 리턴 print(df.pipe(lambda x: missing_count(x).sum()))
열 편집
열의 순서 변경
- 열의 순서 변경은 큰 의미가 없는 경우가 많습니다.
- RDBMS TABLE의 특징 중 하나가 열의 순서는 없다 입니다.
- 열의 순서를 변경하고자 하는 경우에는
DataFrame객체[[컬럼 이름 나열]]
열 분리
- 날짜 형태로 되어 있는 컬럼의 경우, 년 월 일로 분리하는 경우가 있습니다.
- 문자열의 경우는
split 함수를 이용하면 분리가 가능합니다.
df=pd.read_excel('./data/주가데이터.xlsx') # df.head()# 연월일에 - 가 들어간다. # df.info() # 연월일은 datetime64[ns] 타입이다. # 자료형이 datetime이라 split 사용 불가능 # 데이터 타입 변경 # astype을 호출해서 변경하자. # map 함수에 형을 변경할 수 있는 함수를 대입하자. df['연월일']=df['연월일'].astype('str') dates=df['연월일'].str.split('-') # dates.head() # list 형태로 쪼개졌습니다. df['연']=dates.str.get(0) df['월']=dates.str.get(1) df['일']=dates.str.get(2) df.head() # 연/ 월 / 일로 잘 쪼개놨다.
데이터 결합
concat
- Series나 DataFrame을 열 방향이나 행 방향으로 이어 붙이는 함수
- Series 객체는 값과 인덱스를 연결
- Series 객체끼리 concat을 할 때, axis=1을 설정하면 컬럼 방향으로 붙여서 DataFrame을 만듭니다. - 기본적으로 인덱스가 같은 것 끼리 결합을 하게 되는데, Outer Join방식으로 결합
- Join 옵션에 inner를 설정하면 inner join 방식으로 결합
- DataFrame 끼리는 동일한 컬럼을 기준으로 행 단위로 결합
- 존재하지 않는 컬럼의 값은 None
- 열 방향으로 합치고자 한다면 axis=1을 추가
df1=pd.DataFrame({ 'a':['a0','a1','a2','a3'], 'b':['b0','b1','b2','b3'], 'c':['c0','c1','c2','c3'] }, index=[1,2,3,4]) df2=pd.DataFrame({ 'a':['a2','a3','a4','a5'], 'b':['b2','b3','b4','b5'], 'd':['d2','d3','d4','d5'] }, index=[2,3,4,5]) print(pd.concat([df1,df2])) # 기본적으로 행 방향으로 결합 # 동일한 컬럼은 값이 있지만, 한쪽에만 존재하는 컬럼은 # 반대쪽은 NaN 처리가 된다. print(pd.concat([df1,df2], axis=1)) #행방향 결합 - outer join print(pd.concat([df1,df2], axis=1, join='inner')) #행방향 결합 # inner join, 양쪽 모두에 존재하는 데이터만 결합
append
- 인덱스가 의미없는 숫자인 경우 무조건 행 방향으로 결합하는 함수
print(df1.append(df2))- concat을 옵션없이 수행하는 것과 동일함
combine_first
- 첫 번째 데이터가 None(NaN, numpy.nan, NULL, NIL)인 경우, 두 번째 데이터를 가져오는 것
- numpy의 where 함수를 이용해서 구현이 가능하고 pandas의 combine_first를 이용해서 구현 가능
a=pd.Series([np.nan, 2.5,np.nan, 3.5, 4.6, np.nan]) b=pd.Series(np.arange(len(a), dtype=np.float64)) # print(a) # print(b) # NaN 있는 series랑 없는 series 생성 r=np.where(pd.isnull(a),b, a) # 조건이 true 면 data1, False면 Data2를 적용 # a값이 null이면 b의 값을 넣어주고 싶다. 이말이야 print(r) #가로 방향 print(a.combine_first(b)) # 세로 방향 # numpy의 일차원 배열은 출력할 때, 행방향이기 때문이다.
merge
- RDBMS의 JOIN과 유사한 동작을 수행해주는 함수
- 2개의 Series나 DataFrame을 합치는 함수
- key를 가지고 결합
- 옵션 없이 호출하면 동일한 컬럼 이름을 찾아서 그 컬럼의 값이 같은 경우에만 결합을 수행
- on 옵션에 명시적으로 컬럼 이름을 설정할 수 있습니다.
- 동일한 컬럼 이름이 2개 이상 존재하는 경우에 명시
- 양쪽의 컬럼 이름이 다를 때는
lef_on과right_on이라는 속성에 양쪽의 컬럼 이름을 설정하면 된다.
price=pd.read_excel('./data/stock price.xlsx') valuation=pd.read_excel('./data/stock valuation.xlsx') # price.head() # value.head() inner_join=pd.merge(price, valuation) print(inner_join) # 헉 겹치는 컬럼 이 있네? # 1. 지우기 , 2. 골라서 복사해오기(필터)
- how 옵션에 inner나 left, right, outer를 설정할 수 있어요
# outer join도 가능하답니다. outer_join=pd.merge(price, valuation, how='outer') print(outer_join) # outer로 하니까 슬슬 NaN이 보인다.
- index를 가지고 JOIN을 하고자 할 때는
left_index=True와right_index=True를 지정 - sort옵션의 기본값은 True이다.
- sort는 key로 정렬할 지 여부를 설정하는 옵션이다.
Join
- 행 인덱스를 기준으로 결합
- DataFrame을 만들 때, 되도록이면 Primary Key 역할을 할 수 있는 column을 Index로 지정하는 것이 좋습니다.
- Join을 이용해서 합치는 경우가 종종 있습니다.
price=pd.read_excel('./data/stock price.xlsx', index_col='id') valuation=pd.read_excel('./data/stock valuation.xlsx', index_col='id') # bound 호출, unbound 호출, 둘은 같은 결과를 나오게한다. # python만 class이름으로 부를 수 있다. 인스턴스로 부르는게 아니라. # class로 instance 메서드 호출 : unbound 호출 print(pd.DataFrame.join(price, valuation)) # 인스턴스로 메서드 호출 : bound 호출 print(price.join(valuation))

밀가루 귀여워요