
✔ 데이터 수집
YAML
- email 양식에서 가져온 데이터 직렬화(Serializable - 데이터 전송) 양식
- 현재는 실제 데이터 전송보다는 프레임워크 또는 애플리케이션의 설정에 주로 이용
- docker-compose나 kubernetes의 설정 파일이 yaml이고 확장자는 yml
- 형태
속성 : 값
- 값이 여러 개 이면 앞에 -를 추가
- 파싱을 위해서는 pyyaml 패키지를 설치해야 합니다.
- 읽어올 때는 load메서드를 이용해서 읽어오고 저장을 할 때는 dump 메서드를 이용합니다.
✔ Pandas를 이용한 RDBMS 데이터 가져오기
RDBMS의 데이터 읽기
- DBMS에서 제공하는 패키지를 이용해서 읽고 쓰기
- Django에서는 Django에서 제공하는 ORM을 이용해서 읽고 쓰기
- Pandas에서는 sqlalchemy 패키지를 이용
pandas에서 읽기
커넥션 생성
connection 변수 = sqlalchemy.create_engine(db ulr)- url을 작성하는 방법은 db마다 다릅니다.
- db 종류에 따라서 별도의 패키지를 설치해야 하는 경우도 있습니다.
sql을 이용해서 읽어오기
pandas.read_sql_query(SQL구문, connection 변수)
Table 데이터 전체를 읽어오기
pandas.read_sql_table(Table 이름, connection 변수)
python에서 sqlite3의 경우는 별도로 설치할 필요가 없고, 패키지도 별도 설치할 필요가 없습니다.
- 하지만 sqlite3는 외부 접속 불가능하고 내부에서만 사용 가능한 db입니다.
- local저장만 하려고 만든 db입니다.
- python에서 db 접속을 해서 데이터를 가져오고 작업을 수행하는 것은 중요한데, db 분석 분야에서는 실제 db에 직접 접속해서 데이터를 가져오는 경우는 드뭅니다.
- 최근에는 db에 직접 접근하지 않고 데이터를 가져다 사용할 수 있도록 API Server를 이용하는 경우가 많습니다.
✔ MySQL의 데이터 가져오기
- MySQL 구동 (docker 구동)
- 접속 도구를 이용해서 접속하기 (dbeaver)
- 샘플 데이터 생성
- mysql 사용을 위한 패키지 설치 :
pip install pymysql
from sqlalchemy import create_engine # 오류나면 pip install sqlalchemy import pymysql pymysql.install_as_MySQLdb() import MySQLdb #연결 connect=create_engine('mysql+mysqldb://ID:비밀번호@localhost/mino') dataframe=pd.read_sql_table('dbms',connect) print(dataframe)
✔ MongoDB의 데이터 가져오기
- NoSQL이라서 별도의 패키지를 설치해서 데이터를 읽어 옵니다.
- pymongo를 이용해서 데이터를 읽어 온 후 DataFrame으로 직접 변환
샘플 데이터
Docker에 설치한 MongoDB Shell에 접속
docker exec -it 컨테이너이름 bash: 쉘 접속cd bin,mongosh: MongoDB 접속
데이터 삽입
use mymongodb.echo.insertOne({num:11, name:"Spark", function:"클러스터 컴퓨팅 프레임워크"})db.echo.find(): 데이터 확인
패키지 설치
pip install pymongo
작업
from pymongo import MongoClient # MongoDB 연결 conn=MongoClient('127.0.0.1') # DB 연결 db=conn.mymongo # 컬렉션 연결 collection=db.echo # 데이터 가져오기 result=collection.find() # print(result) # <pymongo.cursor.Cursor object at ~~> # 커서는 데이터를 가져올 포인터 # 커서를 순회하면서 각 데이터를 list에 삽입하기 # 이후 데이터프레임으로 변환하기 li=[] for r in result: del r['_id'] # print(r) li.append(r) echo=pd.DataFrame(li) print(echo)
✔ 통계 프로그램의 데이터 가져오기
R의 데이터(rds) 사용
- r의 경우는 pyreadr이라는 패키지의 read_r이라는 함수를 이용해서 읽어냅니다.
SPSS 데이터(sav) 사용
- pyreadstat 패키지를 이용해서 읽어냅니다.
- read_sav
SAS 데이터(sas7bdat) 사용
- pyreadstat 패키지를 이용해서 읽어냅니다.
- read_sas7bdat
Stata 데이터(dta) 사용
- pyreadstat 패키지를 이용해서 읽어냅니다.
- read_dta
- spss, sas, stata는 실제 데이터와 메타 데이터를 리턴합니다.
- R은 dict 형태로 리턴하는데, 데이터의 key가 None입니다.
- SPSS로 보는 예시
# SPSS # import pandas, numpy, and pyreadstat import pandas as pd import numpy as np import pyreadstat # 데이터 와 메타 데이터 가져오기 # 이 함수는 데이터와 메타 데이터를 튜플로 리턴한다. # 그렇기 떄문에 변수를 나눠서 받는 것이 훨씬 좋다. nls97spss, metaspss = pyreadstat.read_sav('data/nls97.sav') print(type(nls97spss)) print(type(metaspss)) print(nls97spss.head())
✔ 데이터 탐색
선택
열 선택
DF이름['열이름']또는DF이름.열이름으로 접근할 때는 열 이름이 반드시 문자열이어야 합니다.- 하나의 열을 선택하면 자료형은 Series입니다.
행 선택
DF이름.loc[인덱스 이름]또는iloc[정수형 위치 인덱스]- 선택된 행이 1개이면 Series가 된다.
하나의 셀 선택
[열이름][인덱스]loc[인덱스][열이름]iloc[행위치, 열위치]
여러 개 선택
- list로 설정하면 되는데, 이 경우는 DataFrame으로 리턴됩니다.
df[열이름]: Series로 리턴df[[열이름]]: DataFrame으로 리턴
# csv 파일 읽어서 df로 변환하기 df=pd.read_csv('./data/item.csv') # print(df) # 인덱스 변경 df.index=['사과','수박','참외','바나나','레몬','망고'] # print(df) # 열 선택 # print(df['code']) # 열 선택할 때, list이용하면 DataFrme이다. # 자료형 보기 # print(type(df['code'])) # 행 선택 : 하나의 행을 선택한다면 Series # print(df.loc[1]) # print(df.iloc[0]) # 하나의 셀 선택 print(df) # 열 이름과 위치 인덱스 이용하기 print(df['name'][0]) # 인덱스와 열 이름을 이용해서 셀 선택 print(df.loc['참외','name']) # 위치 인덱스로만 셀 선택 print(df.iloc[1,2])
범위의 데이터를 선택 가능 - 슬라이싱
:을 이용해서 지정- 위치를 이용하면 뒤의 데이터가 포함되지 않지만, 인덱스나 열 이름을 이용하면 뒤의 데이터가 포함됩니다.
불리언 색인
- bool 타입의 Series를 대입하면 True인 데이터만 골라낼 수 있습니다.
isin
- list를 대입해서 list에 속한 데이터만 골라낼 수 있씁니다.
## 범위 선택 # 사과부터 사과부터 참외까지 print(df.loc['사과':'참외', 'name']) print(df.iloc[0:3]) # 불리언 색인 print(df[df['price']>1000]) print(df[(df['price']>1000)&(df['price']<2000)]) # isin -list에 있는 항목은 True 아니면 False로 리턴 print(df[df['price'].isin([1000,1500])])
확인
head와 tail
- 기본적으로는 앞이나 뒤에서 5개의 데이터를 리턴하지만, 정수를 대입한다면 해당 정수만큼의 데이터를 리턴
- 데이터가 많을 때, 데이터 구조를 빠르게 확인하기 위해서 사용합니다.
속성
- shape
- 행과 열의 개수를 tuple로 리턴- dtypes
- 각 열의 자료형을 리턴합니다.
정보 확인 함수
- info()
- 데이터 유형, 행 인덱스의 구성, 열 이름의 종류와 개수, 자료형, 메모리 사용량 등의 정보를 리턴합니다.- describe()
- 기술 통계 정보를 리턴합니다.
-include='all'을 설정하면, 숫자가 아닌 열의 정보도 리턴한다.- count()
- 데이터 개수- value_counts()
- 고유한 값의 종류와 등장 횟수 리턴- unique()
- 고유한 값의 종류를 리턴- nunique()
- 고유한 값의 개수- dropna
- 옵션이 있는 경우, 이 옵션에 True를 설정하면 None은 제외
데이터의 개략적인 정보 확인
## 범위 선택 # 사과부터 사과부터 참외까지 print(df.loc['사과':'참외', 'name']) print(df.iloc[0:3]) # 불리언 색인 print(df[df['price']>1000]) print(df[(df['price']>1000)&(df['price']<2000)]) # isin -list에 있는 항목은 True 아니면 False로 리턴 print(df[df['price'].isin([1000,1500])])
인덱스나 컬럼의 재구성
- index 전체를 수정할 때는 index 속성에 데이터를 대입하면 됩니다.
- 열의 이름도 저눕 수정하고자 한다면 columns 속성에 데이터를 대입하면 됩니다
- rename 함수를 이용해서 일부분만 수정하고자 할 때는 index나 columns 속성에 dict를 대입하면 되는데, 이 때
{기존이름 : 새로운 이름, ...}를 이용하면 됩니다.
- 수정된 결과를 리턴하는데, inplace 옵션을 True로 한다면 기존 데이터를 수정합니다. - 첫 번째 매개변수로 변환 함수를 대입하고, axis=index나 columns를 설정해서 변환함수를 이용해서 이름을 변경하는 것도 가능합니다.
- 인덱스를 수정하고자 하는 경우, reindex 함수를 이용해서 list를 대입하면, 기존의 인덱스가 수정됩니다.
- 인덱스를 제거하거나 추가하는 것이 가능합니다.
- fill_value 옵션을 이용해서 누락된 인덱스에 특정 값을 설정하는 것이 가능하며, 기본값을 numpy.nan method 옵션에 fill이나 bfill을 설정해서 누락된 경우 앞의 값이나 뒤의 값을 설정하는 설정하는 것도 가능 set_index(열 이름 또는 [열이름 나열])을 이용해서 기존 컬럼의 값을 인덱스로 사용하는 것이 가능한데, 이 경우 기존 컬럼은 제거됨reset_index()를 호출하면 기존 인덱스가 제거되고 0부터 시작하는 숫자로 인덱스를 재설정
# DataFrame 이나 Series의 메서드나 함수가 # inplace 옵션을 가지고 있따면, # 원본에 작업할지 작업한 뒤에 리턴할 지 결정할 수 있습니다. # inplcae 가 False면 작업을 복사본에 수행하고 리턴을 합니다. # inplace 에 True를 설정하면 원본에 작업을 수행하게 됩니다. # df.set_index('name') # print(df) # 이러면 name이 안넘어감 # df.set_index('name', inplace=True) # name을 index로 설정 # print(df) # 이러면 name이 넘어감 # 인덱스를 일반 컬럼으로 변경하고 정수의 일련번호로 인덱스를 수정 df.reset_index(inplace=True) print(df)
데이터 삭제
행 삭제 : drop 함수에 인덱스나 인덱스의 list 대입
열 삭제 : drop함수에 열 이름이나 열 이름의 list를 넘겨주고 axis=1을 추가
- 열 이름이 없는 경우는 ``DataFrame.columns[정수 인덱스]```를 넘겨주면 됩니다.
del 이름[열이름]을 이용할 수 있지만, 비추천- inplace 옵션도 사용이 가능하다.
# origin 열을 제거 # df.drop('origin', inplace=True, axis=1) # print(df.head()) # 0 번 행을 삭제 df.drop(0,inplace=True) print(df.head())
데이터 수정 및 추가
- 데이터를 선택한 후 값을 대입하면 되는데, 이 때 존재하는 경우에는 수정이 되고, 존재하지 않는 경우에는 추가가 됩니다.
- 행이나 열 단위로 추가나 변경을 할 때의 하나의 값을 대입하면 그
# df.head() # df['색상']='red' # 색상은 없는 컬럼이고, 값은 red로만 해놔서 모두가 red # df.head() # df['색상']='blue' # '색상' 이 존재하므로 수정 # df.head() # 행 수정 # df.loc[1]=5 # df.head() # 셀 수정 df.loc[2,'cylinders']=9 df.head()
행 과 열 전치
- 행을 열로 만들고, 열을 행으로 만드는 작업
- T라는 속성을 이용할 수 있고, transpose라는 함수를 이용할 수 있습니다.
# df.T print(df.transpose()) # numpy에서는 3차원배열이 있을 수 있기에, # T와 transpose의 기능이 다르다. # np transpose는 행과 열의 순서를 지정 # pandas에서는 2차원 배열까지만 존재하기에, T와 transpose는 동일
✔ 연산
연산
- DataFrame이나 Series와 Scala 데이터의 연산은 모든 셀을 가지고 스칼라 데이터와 연산을 수행해서 리턴합니다.
- 연산이 불가능한 컬럼이 있다면, Error가 발생합니다.
- DataFrame과 DataFrame 그리고 Series의 연산은 동일한 인덱스끼리 수행합니다.
- 한쪽에만 존재하는 인덱스는 NaN이 됩니다.(NULL) - add, sub, div, mul 이라는 함수를 이용해서 산술 연산을 수행할 수 있는데, 이 경우에는
fill_value라는 옵션을 이용해서, 한쪽에만 존재하는 인덱스에 기본값을 설정하는 것이 가능합니다.
items1={'1':{'price':1500},'2':{'price':15000},'3':{'price':1000}} items2={'1':{'price':2700},'2':{'price':7000},'4':{'price':1200}} data1=pd.DataFrame(items1).T data2=pd.DataFrame(items2).T print(data1) print() print(data2) # 스칼라 데이터와의 연산은 모든 셀에 적용 # print(data1+10) # DataFrame이나 Series 끼리의 연산은 동일한 인덱스끼리 수행 # print(data1+data2) # 함수 이용 - 기본값 설정이 가능 print(data1.add(data2, fill_value=0))
통계 함수
- count, min, max, sum, mean, median, var, std, mode(최빈값)
- kurt(첨도), skew(비대칭도, 왜도), sem(평균의 표준 오차)
- argmin, argmax, idxmin, idxmax (위치를 주느냐 인덱스를 주느냐의 차이)
- quantile
- cumsum, cummin, cummax, cumprod
- diff(이전 데이터와의 산술적인 차이), pct_change(이전 데이터와의 백분율)
- unique() : 유일한 값을 찾기
df=pd.read_csv('./data_ex/noheader_auto-mpg.csv', header=None) # 헤더 설정 df.columns=['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model year', 'origin', 'name'] #mpg의 평균 # print(df['mpg'].mean()) #수치값이라면 여러개 가능합니다. # print(df[['mpg', 'cylinders']].mean()) #이전 데이터와의 차이를 구해보자. # print(df[['mpg', 'cylinders']].diff()) print(df[['mpg', 'cylinders']].pct_change())
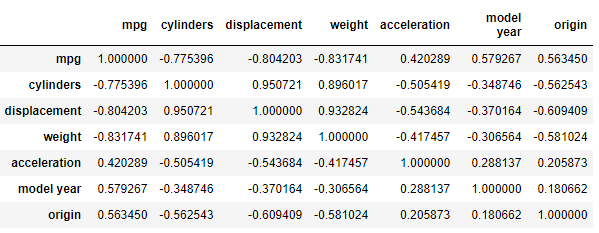
상관계수와 공분산
공분산 : cov
- 공분산은 2개의 확률 변수의 상관 정도를 나타내는 값
- 측정 단위의 크기에 따라 달라집니다.
- 이를 이용해서 상관 정도를 파악하기가 어려워서 상관 계수를 도입했씁니다.
상관계수 : corr
- 두 변수 간의 관련성의 정도
-1 ~ 1- 양수는 한쪽이 증가할 때 같이 증가하고, 음수는 어느 한쪽 값이 증가할 때 다른 값은 감소한다.
# 전체 다 하면 우선 수치값이 아닌 컬럼은 빠지게 된다. # 모든 숫자 컬럼의 상관 계수를 전부 구하기 df.corr()
- 관련성이 있다고 하려면 abs(corr)>0.4
- 수치값이 0에 가까울 수록 관련성이 없다고 한다.
# mpg와 weight 컬럼의 상관계수를 구하기 print(df[['mpg', 'weight']].corr())
- 음의 상관관계를 갖는다.

정렬
sort_index()함수를 호출하면 인덱스 순서대로 오름차순 정렬을 한다.- 내림차순 정렬을 하고자 하는 경우는 ascending 옵션에서 값을 False로 설정
- Series 객체를 정렬할 때는
sort_values이용합니다. - 인덱스가 아닌, 특정 컬럼을 기준으로 정렬할 때는
sort_values호출하는데, by 매개변수 변수에 컬럼의 이름이나 컬럼의 이름 list를 설정
df=pd.read_csv('./data_ex/noheader_auto-mpg.csv', header=None) # 헤더 설정 df.columns=['mpg', 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model year', 'origin', 'name']
순위
rank()함수를 이용하는데, 기본은 오름차순입니다.- 정렬과 동일하게 ascending 옵션을 이용해서 내림차순 한 순서대로 설정 가능.
- axis 옵션을 이용해서 행 단위 순서 변경이 가능하다.
- 동일한 값인 경우는 method 속성을 확인합니다. - max, min, first(먼저나오는거 먼저 뽑아내기)
✔ 시각화
시각화를 하는 이유
- 데이터를 탐색을 할 때, 기술 통계만 사용을 하게 된다면 데이터를 왜곡해서 해석할 수 있습니다.
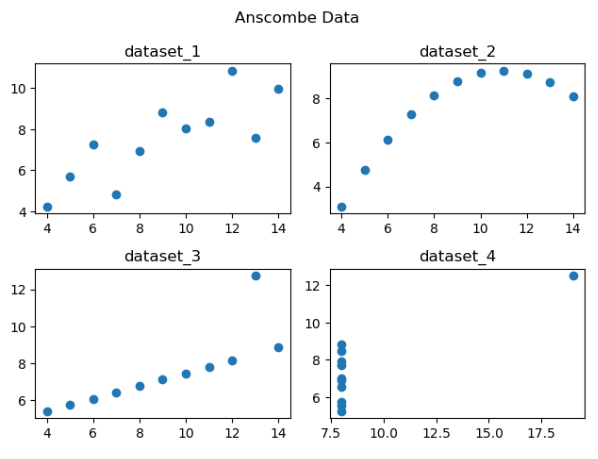
- 앤스콤 4분할 그래프
- 4개의 데이터 그룹을 만들었는데, 이 4개의 그룹은 기술 통계나 상관 계수 그리고 회귀선이 모두 일치
- 4개의 그룹의 데이터는 동일하다라고 판단
- 하지만 분포는 전혀 달랐다.
- 단순한 기술 통계를 보고 A와 B는 같다라고 하면 큰일난다.
- 시각화를 해서 검증을 해야 한다.
앤스콤의 데이터로 검증을 해보자.
# 앤스콤 데이터 가져오기 import seaborn as sns anscombe=sns.load_dataset("anscombe") anscombe.head() # info로 데이터셋의 구성을 확인해보자. # dataset 과, x, y 컬럼으로 구성되어있다. anscombe.info() print(anscombe['dataset'].unique()) # 각 그룹의 기술통계값 # 거의 비슷합니다. print(anscombe[anscombe['dataset']=='I'].describe()) print(anscombe[anscombe['dataset']=='II'].describe()) print(anscombe[anscombe['dataset']=='III'].describe()) print(anscombe[anscombe['dataset']=='IV'].describe()) #데이터 분리시키기 dataset_1 = anscombe[anscombe['dataset']=='I'] dataset_2 = anscombe[anscombe['dataset']=='II'] dataset_3 = anscombe[anscombe['dataset']=='III'] dataset_4 = anscombe[anscombe['dataset']=='IV'] # 그래프를 그려보자. import matplotlib.pyplot as plt fig=plt.figure() # 영역을 4개로 분할 / subplot(행개수, 열개수, 번호) axes1=fig.add_subplot(2,2,1) axes2=fig.add_subplot(2,2,2) axes3=fig.add_subplot(2,2,3) axes4=fig.add_subplot(2,2,4) # 각 영역에 각 dataset의 그래프를 출력하기 axes1.plot(dataset_1['x'],dataset_1['y'],'o') axes2.plot(dataset_2['x'],dataset_2['y'],'o') axes3.plot(dataset_3['x'],dataset_3['y'],'o') axes4.plot(dataset_4['x'],dataset_4['y'],'o') # 제목 출력 axes1.set_title('dataset_1') axes2.set_title('dataset_2') axes3.set_title('dataset_3') axes4.set_title('dataset_4') # 전체 제목 출력 fig.suptitle("Anscombe Data") fig.tight_layout()
- 그래프 상에서 확인했을 때, 데이터의 분포가 아예 다른 것을 확인하였따.
시각화 라이브러리
- matplotlib
- seaborn
- matplotlib 기반- pandas
- matplotlib 기반- folium
- 지도 출력
시각화의 목적
- 데이터를 탐색해서 새로운 비즈니스 인사이트나 데이터의 특성을 알아내기 위해서
- 가독성
matplotlib
- 시각화에 가장 많이 사용하는 라이브러리 중 하나
line plot
- 선 그래프
- 시계열 데이터와 같은 연속적인 값의 변화와 패턴을 파악하는데 적합하기 때문이다.
- 서울과 전라남도 사이 인구인동에 관한 시각화
- 데이터 : http://kosis.kr/search/search.do
- 서울과 전라남도 사이의 인구 이동에 대한 시각화
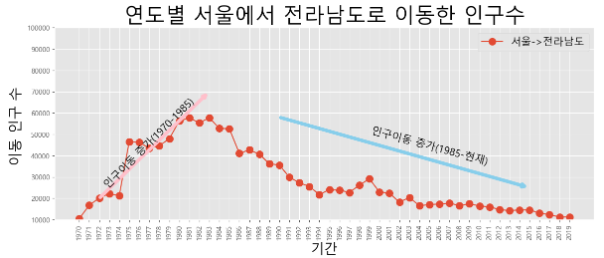
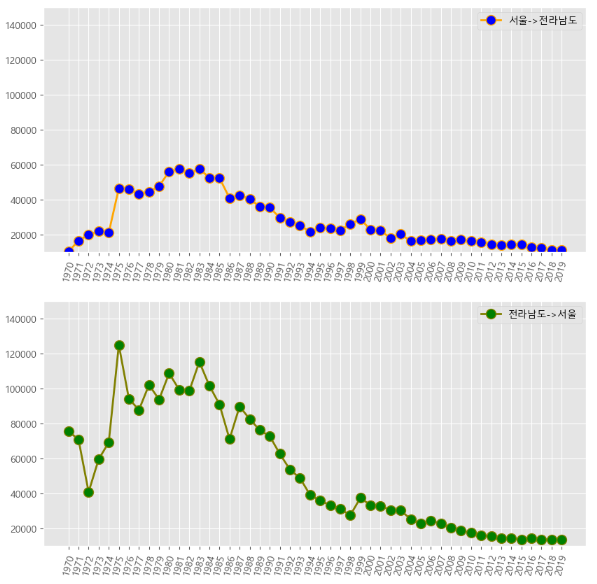
# 데이터 읽어오기 df=pd.read_excel('./data/시도_별_이동자수.xlsx',header=0) print(df) # NaN 이라면 앞에 있는 데이터로 값을 채워버리자. df=df.fillna(method='ffill') # 서울에서 다른 곳으로 이동한 데이터만 추출 # 추출 조건을 걸어버리자. mask=(df['전출지별']=='서울특별시')&(df['전입지별']!='서울특별시') df_seoul=df[mask] print(df_seoul) # 전출지별 이라는 열을 삭제하자. df_seoul.drop(['전출지별'], axis=1, inplace=True) print(df_seoul) # 전입지별 -> 전입지 로 컬럼의 이름 변경 df_seoul.rename({'전입지별':'전입지'}, axis=1, inplace=True) print(df_seoul) # 전입지를 index로 설정하기. # 현재는 단순 수치 index가 있기에, 전입지가 key가 될 수 있기에 index로 설정 df_seoul.set_index('전입지',inplace=True) print(df_seoul) # 서울->전라남도 이동한 사람들을 보고 싶다. # index가 전라남도인 데이터만 추출해보자. sr_one=df_seoul.loc['전라남도'] print(sr_one) sr_one.info() # 연도 & 인구수 -> 선 그래프가 좋겠다. plt.plot(sr_one.index, sr_one.values) # 한글 출력을 위한 설정 from matplotlib import font_manager, rc import platform if platform.system()=='Darwin': rc('font', family='AppleGothic') elif platform.system()=='Windows': font_name=font_manager.FontProperties(fname='c:/Windows/Fonts/malgun.ttf').get_name() rc('font', family=font_name) plt.style.use('ggplot') # 스타일 설정 plt.figure(figsize=(14,5)) # 크기 설정 # X축 눈금 회전 plt.xticks(size=10, rotation='vertical') # 그래프 설정 plt.plot(sr_one.index, sr_one.values, marker='o', markersize=10) # 제목 설정 - 한글 (아마 깨질 것이다.) plt.title('연도별 서울에서 전라남도로 이동한 인구수', size=30) plt.xlabel('기간', size=20) plt.ylabel('이동 인구 수 ', size=20) # 범례 plt.legend(labels=['서울->전라남도'], loc='best', fontsize=15) # y축 범위 지정 plt.ylim(10000,100000) # 화살표 출력 plt.annotate("",xy=(13,70000), xytext=(2,20000), xycoords='data', arrowprops=dict(arrowstyle='->', color='pink', lw=5)) # 화살표 출력 2 plt.annotate("",xy=(45,25000), xytext=(20,58000), xycoords='data', arrowprops=dict(arrowstyle='->', color='skyblue', lw=5)) # 텍스트 출력 plt.annotate("인구이동 증가(1970-1985)", xy=(7, 25000), rotation=45, va='baseline', ha='center', fontsize=15) plt.annotate("인구이동 증가(1985-현재)", xy=(35, 36000), rotation=-15, va='baseline', ha='center', fontsize=15) # 그래프 출력 plt.show()
- 결과물
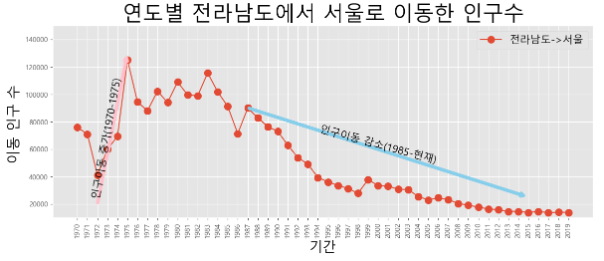
- 전남 -> 서울로 만들어보자.
# 서울에서 다른 곳으로 이동한 데이터만 추출 # 추출 조건을 걸어버리자. mask2=(df ['전출지별']=='전라남도')&(df['전입지별']!='전라남도') df_jn=df[mask2] print(df_jn) # 전출지별 이라는 열을 삭제하자. df_jn.drop(['전출지별'], axis=1, inplace=True) print(df_jn) # 전입지별 -> 전입지 로 컬럼의 이름 변경 df_jn.rename({'전입지별':'전입지'}, axis=1, inplace=True) print(df_jn) # 전입지를 index로 설정하기. # 현재는 단순 수치 index가 있기에, 전입지가 key가 될 수 있기에 index로 설정 df_jn.set_index('전입지',inplace=True) print(df_jn) # 서울->전라남도 이동한 사람들을 보고 싶다. # index가 전라남도인 데이터만 추출해보자. sr_two=df_jn.loc['서울특별시'] print(sr_two) sr_two.info() plt.style.use('ggplot') # 스타일 설정 plt.figure(figsize=(14,5)) # 크기 설정 # X축 눈금 회전 plt.xticks(size=10, rotation='vertical') # 그래프 설정 plt.plot(sr_two.index, sr_two.values, marker='o', markersize=10) # 제목 설정 - 한글 (아마 깨질 것이다.) plt.title('연도별 전라남도에서 서울로 이동한 인구수', size=30) plt.xlabel('기간', size=20) plt.ylabel('이동 인구 수 ', size=20) # 범례 plt.legend(labels=['전라남도->서울'], loc='best', fontsize=15) # y축 범위 지정 plt.ylim(10000,150000) # 화살표 출력 plt.annotate("",xy=(5,130000), xytext=(2,20000), xycoords='data', arrowprops=dict(arrowstyle='->', color='pink', lw=5)) # 화살표 출력 2 plt.annotate("",xy=(45,25000), xytext=(17,90000), xycoords='data', arrowprops=dict(arrowstyle='->', color='skyblue', lw=5)) # 텍스트 출력 plt.annotate("인구이동 증가(1970-1975)", xy=(3, 25000), rotation=80, va='baseline', ha='center', fontsize=15) plt.annotate("인구이동 감소(1985-현재)", xy=(30, 50000), rotation=-15, va='baseline', ha='center', fontsize=15) # 그래프 출력 plt.show()
- 결과물
- 이번에는 그래프를 2개 그려보자.
# 2개의 그래프 그리기 fig=plt.figure(figsize=(10,10)) # 영역 생성 ax1=fig.add_subplot(2,1,1) ax2=fig.add_subplot(2,1,2) ax1.plot(sr_one, marker='o', markerfacecolor='blue', markersize=10, color='orange', linewidth=2, label='서울->전라남도') ax2.plot(sr_two, marker='o', markerfacecolor='green', markersize=10, color='olive', linewidth=2, label='전라남도->서울') ax1.legend(loc='best') ax2.legend(loc='best') ax1.set_ylim(10000,150000) ax2.set_ylim(10000,150000) ax1.set_xticklabels(sr_one.index, rotation=75) ax2.set_xticklabels(sr_two.index, rotation=75) plt.show()
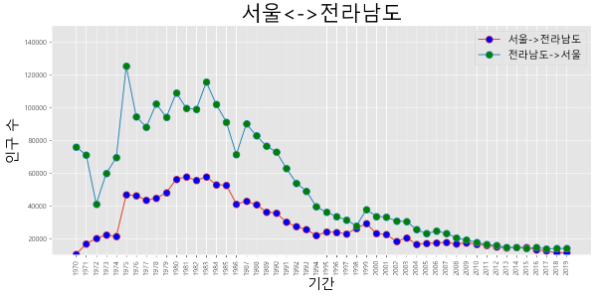
- 두 선 그래프가 한 평면에 있으면 조금 더 잘 보일 것 같다.
- 이번에는 한 좌표평면 위에 선 그래프 2개를 그려보자.
# 한 영역 안에 그래프를 2개 그려보자. # 한개의 plt에다가 그리면 된다. (subplot x) plt.figure(figsize=(14,6)) plt.xticks(size=10, rotation='vertical') plt.plot(sr_one.index, sr_one.values, marker='o', markersize=10, markerfacecolor='blue', label='서울->전라남도') plt.plot(sr_two.index, sr_two.values, marker='o', markersize=10, markerfacecolor='green', label='전라남도->서울') plt.title('서울<->전라남도', size=30) plt.xlabel('기간', size=20) plt.ylabel('인구 수', size=20) plt.legend(loc='best', fontsize=15) plt.ylim(10000,150000) plt.xticks(size=10, rotation='vertical') plt.show()
- 여러개 넣고 싶으면 plt 하나에 계속 작성하면 됩니다.
bar plot
- 막대 그래프
- 높이나 너비의 차이를 이용해서 크고 작음을 표현하거나 시간에 따른 변화를 표현할 때 주로 이용
- bar와 barh 함수로 막대 그래프 출력 (수직, 수평)
- 하나의 영역에 2개의 막대를 옆으로 배치하고자 하면,
width속성을 이용한다.
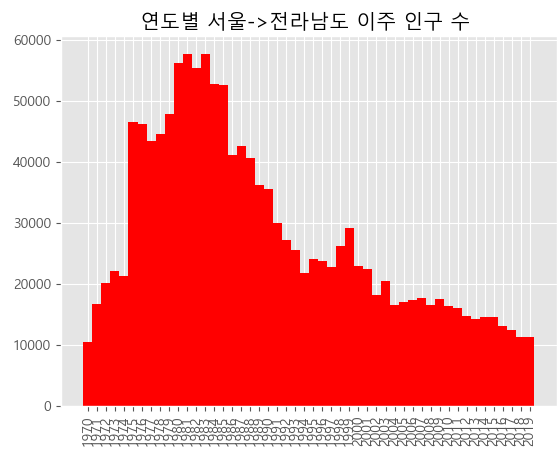
sr_one을 이용해 막대 그래프 출력
- 데이터는 선그래프때 만든 데이터를 이용했다.
# 막대 그래프 출력 plt.bar(sr_one.index, sr_one.values, width=1.0, color='r') plt.xticks(range(0,len(sr_one.index),1),sr_one.index, rotation='vertical') plt.title('연도별 서울->전라남도 이주 인구 수 ') plt.show()
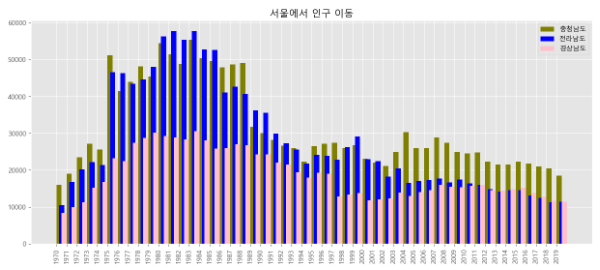
여러 개의 데이터를 하나의 막대에 누적
# 서울에서 경기도, 충청남도, 전라남도, 경상남도 로 이주한 인구수를 표현 sr=df_seoul.loc[['경기도', '충청남도', '전라남도', '경상남도']] # 행과 열 전치 sr=sr.T # print(sr) # 인덱스의 자료형을 정수로 변환(계산을 위해) sr.index=sr.index.map(int) plt.figure(figsize=(15,6)) # 축 이동을 위한 변수 x=pd.RangeIndex(0,len(sr.index),1) # 경기도가 너무 차이나니까 잠깐 주석처리하고 그래프를 보자. plt.bar(x,sr['경기도'], width=0.5, color='orange', label='경기도') plt.bar(x+0.25,sr['충청남도'], width=0.5, color='olive', label='충청남도') plt.bar(x+0.5,sr['전라남도'], width=0.5, color='blue', label='전라남도') plt.bar(x+0.75,sr['경상남도'], width=0.5, color='pink', label='경상남도') plt.xticks(range(0,len(sr_one.index),1), sr_one.index, rotation='vertical') plt.title('서울에서 인구 이동') # 범례를 넣어주자. plt.legend() plt.show()

밀가루 귀여워요