
✔ 데이터 읽기 및 쓰기
- 데이터 분석 과정에서 데이터 저장을 하는 이유
- 전처리를 수행한 데이터를 다음에 다시 사용하기 위해서
- numpy npz 저장
- pandas csv 저장
- R rda 저장
- R vs Python
- R은 데이터 분석만(머신러닝 가능, 딥러닝 불가능)
- Python은 데이터 분석도 한다.(서비스 만드는 언어)
csv 파일 저장
- Series나 DataFrame 객체가
to_csv()를 호출하면 된다.
- 호출할 때, 매개변수로 파일의 경로를 설정 - 저장할 때 옵션
- sep : 구분자 설정
- np_rep : NaN값을 원하는 형식으로 저장
- index나 header에 False 대입시, 그 둘은 출력 X
- cols에 필요한 컬럼 list 지정하면, list에 설정된 컬럼만 저장
# 데이터프레임 생성 items={ 'code':[1,2,3], 'name':['apple','banana','kiwi'], 'price':[3000,2000,5000] } df=pd.DataFrame(items) print(df) # 데이터 저장하기 df.to_csv('./data/pdData0809.csv')
엑셀 파일 사용
엑셀 파일 읽기
- 패키지
- xlrd 패키지를 이용하는 anaconda 배포판에는 설치가 되어 있음 read_excel(엑셀 파일 경로)를 이용하는데, 대부분의 옵션은read_csv와 유사하고,sheet_name옵션을 이용해서 읽어올 시트를 지정하는 것이 가능함
엑셀 파일 저장
- 패키지
- openpyxl 패키지 이용, anaconda 배포판에는 설치가 되어 있음 writer 변수 = pandas.ExcelWriter(저장할 파일 경로, engine='xlswriter')데이터프레임.to_csv(writer변수)writer변수.save()
# 첫 번째 열을 인덱스로 활용해서 읽기 df=pd.read_excel('./data/excel.xlsx',sheet_name='Sheet1', index_col=0) print(df) # 저장해보기 writer=pd.ExcelWriter('./data/excelwriter.xlsx') df.to_excel(writer) writer.save()
HTML 페이지에서 table 태그의 내용을 가져오기
- read_html(URL)로 읽어 올 수 있는데, 하나의 페이지에 table이 여러 개 있을 수 있어서 list로 리턴합니다.
- 옵션으로는 천 단위 구분 기호나 인코딩 방식, 그리고 na 데이터 설정 등이 존재합니다.
li=pd.read_html("https://ko.wikipedia.org/wiki/ %EC%9D%B8%EA%B5%AC%EC%88%9C_%EB%82%98%EB%9D%BC_%EB%AA%A9%EB%A1%9D") print(li)
✔ 웹에서 데이터 가져오기
- 웹에서 제공하는 Open API 데이터나 HTML 페이지를 읽어 내는 것
Python에서 제공하는 API
- urllib와 urllib2 라는 패키지는 제공합니다.
- 이 안에서
request라는 모듈이 웹에서 데이터를 읽어옵니다. request모듈의urlopen이라는 함수가 존재하고, 해당 함수에 url을 문자열로 대입을 하면response객체가 리턴됩니다.- return 되는 객체의
getheaders()를 호출하면 서버의 정보를 읽을 수 있고,status를 이용하면 상태 코드를 확인할 수 있고,read()를 호출하면 읽은 내용을 가져올 수 있습니다. - Encoding 문제로 텍스트가 깨진다면?
-read().docde(인코딩방식)을 호출하면 됩니다.
import urllib.request # 데이터 읽어오기 response=urllib.request.urlopen("https://www.kakao.com") # 읽은 정보 저장 data=response.read() # print(data) 하니 데이터가 깨져있다. 인코딩 문제 발생 # 이 부분은 꼭 기억하자 encoding=response.info().get_content_charset() html=data.decode(encoding) print(html)
- url의 파라미터에 한글이나 특수문자가 있는 경우에는 url을 인코딩해야 합니다.
- get 방식의 경우, 애플리케이션 서버가 파라미터 인코딩을 하지 않고 web server가 파라미터 인코딩을 하기 떄문에, 보낼 때 인코딩을 해서 보내야 합니다.
- 애플리케이션 서버는 데이터의 인코딩을 변경할 수 있지만, 웹 서버는 데이터의 인코딩을 변경할 수 없습니다.
- 파라미터 인코딩을 하고자 하는 경우에는 python에서는urllib.parse모듈의quote_plus함수와quote함수를 이용하면 됩니다.
- 파라미터로 인코딩해서 읽기
from urllib.parse import quote keyword=quote("바밤바아이스크림") # 데이터 읽어오기 response=urllib.request.urlopen("https://www.coupang.com/np/search? q="+keyword+"&channel=relate") # 읽은 정보 저장 data=response.read() #print(data) 하니 데이터가 깨져있다. 인코딩 문제 발생 encoding=response.info().get_content_charset() html=data.decode(encoding) print(html)
- url은 알아서 잘 긁어와야 할 것같다.
requests
- 파이썬의 기본 패키지가 아님
- 데이터 인코딩이 편리하고 전송 방식(GET, POST, PUT, DELETE)에 따른 요청을 수행하는 것이 편리하기 때문에 사용합니다.
- 설치
-pip install requests
- GET
import requests # GET 방식 response=requests.get('http://httpbin.org/get') print(response.text)
- 결과
{ "args": {}, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate, br", "Host": "httpbin.org", "User-Agent": "python-requests/2.28.1", "X-Amzn-Trace-Id": "Root=1-64d2f008-7a3f01ee442f4e1b0d0fffd0" }, "origin": "1.220.201.110", "url": "http://httpbin.org/get" }
- POST
# POST 는 데이터를 만드니까.. dic={'id':'mino', 'name':'민호', 'alias':'sonic'} response=requests.post('http://httpbin.org/post',data=dic) print(response.text)
- 결과
{ "args": {}, "data": "", "files": {}, "form": { "alias": "sonic", "id": "mino", "name": "\ubbfc\ud638" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate, br", "Content-Length": "43", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.28.1", "X-Amzn-Trace-Id": "Root=1-64d2f0cc-59ea932804ac48d47b679cea" }, "json": null, "origin": "1.220.201.110", "url": "http://httpbin.org/post" }
- 읽어 오는 것을 스크래핑이라고 한다.
- 이후 할 작업은 파싱이다.
HTML Parsing
- HTML 문자열에서 원하는 데이터만 추출하는 것
beautifulsoup4라는 패키지 이용
- anaconda에는 설치가 되어 있음
- 모듈 이름은bs4이다.- HTML을 DOM의 형태로 펼치기
import bs4 변수명=bs4.BeautifulSoup(html,'html.parser')
- 태그를 이용해서 찾는 방법
-변수명.태그이름.get_text()
- 하지만, 동일한 태그가 너무 많다.
try: response=requests.get('http://finance.daum.net') # print(response.text) # 실제로 이렇게 하면 터질 가능성이 존재합니다. # 1. 내 인터넷이 안되거나 2. 상대방 서버가 터지거나. # 예외처리를 해두자. bs=bs4.BeautifulSoup(response.text, 'html.parser') except Exception as e : print("예외 발생 : ") else: print(bs.body.span.get_text()) #이거 잘 안씀
- 다른 것은 몰라도. 예외처리를 해야 한다는 것을 잊지 말자.
- 파싱 함수
find(태그): 태그에 해당하는 것 1개만 리턴find_all(태그): 태그에 해당하는 것 모두 리턴
- 함수로 찾아온 객체를 가지고 attrs 속성에 태그 안의 속성과 값을 dict로 소유
- a 태그의 href속성을 많이 찾아옵니다.
- a 태그의 href 속성은 링크를 소유하고 있습니다.
- 소셜 네트워크 분석을 할 때는 대부분의 경우 한 번에 검색된 내용만 가지고 하는게 아니고 검색 한 후 나온 결과의 링크를 타고 가서 데이터를 수집하는 경우가 많습니다.
select(선택자)
- 선택자에 해당하는 값을 찾아옵니다.
- 여러 개가 리턴됩니다.xpath
- 단 한개씩만 존재합니다. 태그하나당
네이버 팟 캐스트에서 타이틀을 가져오기
https://tv.naver.com/r/category/drama
# 네이버 팟 캐스트에서 원하는 데이터 가져오기 try: response=requests.get("https://tv.naver.com/r/category/drama") html=response.text # print(html) bs=bs4.BeautifulSoup(html,'html.parser') tags=bs.select("a > strong > span") for tag in tags: print(tag.getText()) except Exception as e: print("예외 발생", e)
Selenium
- 웹 앱을 테스트하는 프레임워크
- request나 requests 라이브러리는 정적인 HTML을 가져오는 라이브러리 이다.
- 정적? : 현재 보여지는 HTML만 가져온다.
- ajax 형태의 데이터는 가져올 수 없습니다. - 동적으로 변경되는 데이터는 브라우저를 실행시켜서 동적으로 데이터를 읽어와야 합니다.
- 브라우저를 실행시켜서 html을 읽어올 수 있는 프레임워크가 Selenium이다.
실행환경 구성
pip install selenium- 브라우저 버전에 맞는 드라이버를 다운로드 받아야 합니다.
- 크롬을 쓰면 크롬드라이버
- 드라이버.exe를 같은 디렉에 놓고 쓰면 됩니다.
# 크롬 브라우저 실행 from selenium import webdriver import os os.environ['webdriver.chrom.driver']='./' driver=webdriver.Chrome() while(True): pass
함수
- implicitly_wait(시간)
- 시간동안 대기- get(url)
- url로 접속- page_source 속성
- html 코드- DOM에 접근
- find_element(by_name, 값) 아래들 다 똑같은 형태
- find_element_by_id
- find_element_by_xpath
- 위에 3개는 여러개
- find_element_by_css_selector
- find_element_by_class_name
- find_element_by_tag_name
- 여기 3개는 한개만 존재- quit()
- execute_script(스크립트 코드)
- DOM의 메서드
- send_keys("값") : DOM에 값이 설정
- click()이나 submit()을 하면 클릭한 효과
from selenium import webdriver from selenium.webdriver.support.ui import Select from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys # 크롬드라이버 실행파일을 같은 디렉에 놓고 하면 됩니다. # 크롬 브라우저 실행 from selenium import webdriver import os os.environ['webdriver.chrom.driver']='./' driver=webdriver.Chrome() driver.get("https://accounts.kakao.com/login/?continue=https%3A%2F%2Faccounts.kakao.com%2Fweblogin%2Faccount%2Finfo#login") # 입력 상자를 찾아서 입령 상자에 데이터 설정 driver.find_element(By .XPATH,'//*[@id="loginId--1"]').send_keys("카카오이메일입력") driver.find_element(By .XPATH,'//*[@id="password--2"]').send_keys("카카오 비밀번호 입력") driver.find_element(By .XPATH,'//*[@id="mainContent"]/div/div/form/div[4]/button[1]').click() while(True): pass
- 물론 로그인 할 때, reCAPTCHA가 발생할 수 있다.
이번엔 유튜브 스크롤하면서 데이터를 가져와보자.
# 유튭 import bs4 # by 랑 keys 임포트함 from selenium import webdriver import os import time os.environ['webdriver.chrom.driver']='./' driver=webdriver.Chrome() keyword="lck" driver.get("https://www.youtube.com/results?search_query="+keyword) # 현재 페이지가 아닌, N번 스크롤해보자. num_of_pagedowns=5 while num_of_pagedowns: # body 태그에 페이지 다운을 전송해서 하단으로 그래그 driver.find_element(By .TAG_NAME, 'body').send_keys(Keys.PAGE_DOWN) time.sleep(3) num_of_pagedowns -=1 # N 번 스크롤한 결과 가져오기 html=bs4.BeautifulSoup(driver.page_source, 'html.parser') print(html)
html 가져오기
- request
- 파이썬의 기본 패키지 - requests
- 설치를 해야 하는 패키지
- get, put, post, delete 등 의 요청 방식을 쉽게 처리합니다. - Selenium
- html을 동적으로 읽어와야 하는 경우
- 로그인처럼 동작을 취해야만 읽을 수 있는 데이터를 가져오고자 할 때 사용
HTML에서 원하는 데이터 추출
- beautifulSoup
- html과 xml을 파싱하는 패키지
Open API 데이터 가져오기
- HTML은 데이터가 아니다.
- OPEN API에서 제공되는 데이터 타입
- XML : 태그를 이용해서 데이터를 표현하는 방식
- 설정 아니면 RSS에서..
- JSON : JS의 객체 표현법을 이용해서 데이터를 표현하는 방식
- YML : 이메일 표현 형식을 이용해서 데이터를 표현하는 방식- YML은 코드형 인프라 구축에 주로 이용(클라우드)
- 최근에는 인프라 구축을 코드로 많이 함. (가독성이 높아 수정 용이)
- docker, kubernetes public cloud 에서의 환경 구축에 이용
- 이름을 잊어버리면 안됩니다... YML은 아직까진 일반데이터에선 잘...
XML 데이터를 이용해서 DataFrame 생성
- XML은 pandas에서 파싱하는 API를 제공하지 않음
- XML은 직접 다운로드 받아서 파싱한 후 DataFrame을 생성
- http://www.hani.co.kr/rss/sports/ 에서 title과 link의 태그 내용을 읽어서 DataFrame을 만들어보자.
import xml.etree.ElementTree as et # xml 파싱을 위한 import import urllib.request #웹에서 문자열 다운로드 받기 위해 import #데이터 다운로드 url="http://www.hani.co.kr/rss/sports" request=urllib.request.Request(url) response=urllib.request.urlopen(request) # print(response.read()) # 루트를 찾기 tree=et.parse(response) xroot=tree.getroot() print(xroot) # 찾고자 하는 태그의 내용을 가져오기 channel=xroot.findall('channel') print(channel) # channel의 0번 데이터에서 item 태그의 내용 찾아오기 items=channel[0].findall('item') print(items) # 자료를 DataFrame으로 만들자. rows=[] for node in items: s_title=node.find('title').text s_link=node.find('link').text rows.append({'title':s_title, 'link':s_link}) df=pd.DataFrame(rows,columns=['title','link']) print(df)
JSON 데이터를 이용해서 DataFrame 생성
- pandas에서
read_json이라는 함수를 이용하면 바로 데이터 프레임으로 생성 - 옵션으로는 encoding과 orient를 주로 이용합니다.
df=pd.read_json("http://swiftapi.rubypaper.co.kr:2029/hoppin/movies?version=1&page=1&count=30&genreId=&order=releasedateasc") df.head() hoppin=df['hoppin'] # print(hoppin) #아직 안에 데이터가 더 들어있다. movies=hoppin['movies'] # print(movies) # movie라는 키가 있네 movie=movies['movie'] # print(movie) #이제야 리스트에 나옴 # for temp in movie: # print(temp['title']) rows=[] for temp in movie: s_title=temp['title'] s_link=temp['linkUrl'] rows.append({'title':s_title, 'link':s_link}) df=pd.DataFrame(rows,columns=['title','link']) print(df)# 최신 라이브러리를 사용하면 이런 경우에도 df로 잘 변환이 되지만 # 컬럼에 객체가 존재하는 경우에는 제대로 파싱이 수행되지 않는 경우가 있음 # 컬럼 이름에 객체가 존재하는 경우는 orient 옵션에 columns를 설정하면 된다. df=pd.read_json("https://raw.githubusercontent.com/chrisalbon/simulated_datasets/master/data.json", orient='columns') print(df)
OPEN API
- 우리 조직 외부에서도 사용할 수 있다 가 주요 내용입니다.
KAKAO open API 데이터 가져오기
- developers.kakao.com 에서 애플리케이션 생성
- html 화면에서 js키, 데이터를 가져오자 rest api 키, 관리자의 역할을 수행하려 할 때 Admin 키, ios&안드로이드 개발 시 필요한 네이티브 앱 키
- 플랫폼은 지금은 안해도 됩니다. 지금은 REST API 키 사용 예정입니다.
- 이걸 좀 해보자.
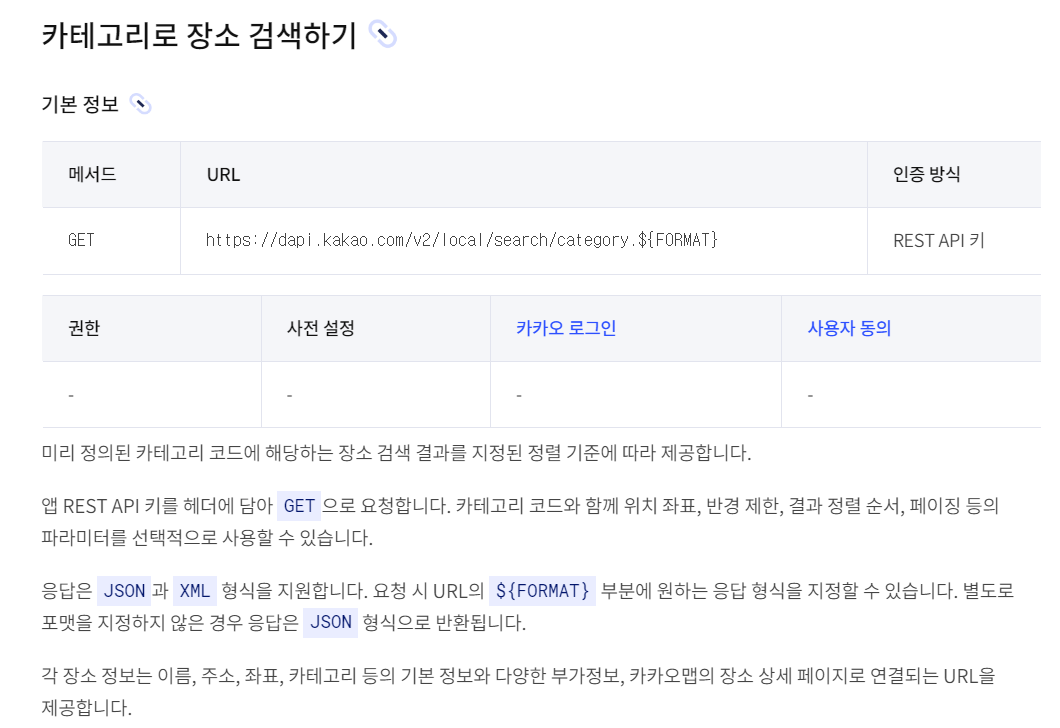
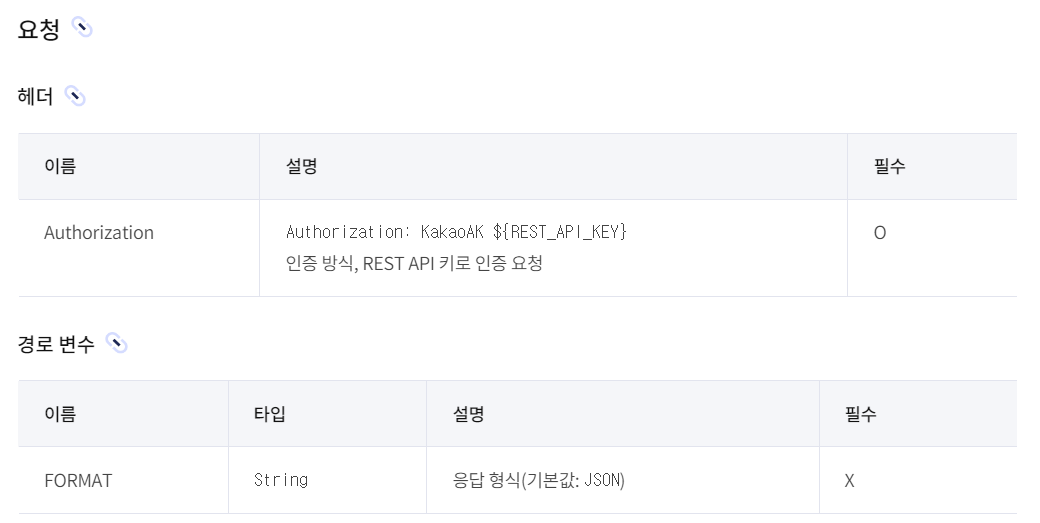
- 헤더 인증 모양 -Authorization : KaKaoAK {REST API 발급받은 키}
- URL : https://dapi.kakao.com/v2/local/search/category.json?category_group_code=PM9&rect=위도경도
import requests import json url="https://dapi.kakao.com/v2/local/search/category.json?category_group_code=PM9&rect=126.95,37.55,127.0,37.60" headers={'Authorization': 'KakaoAK restAPI키값'} data=requests.post(url,headers=headers) # print(data.text) result=json.loads(data.text) # print(result) for data in result['documents']: print(data['place_name'], end='\t') print(data['address_name'])

밀가루 귀여워요
좋은 글이네요. 공유해주셔서 감사합니다.