
✔ 임시
ndarray의 연산
ndarray의 broadcast 연산
- ndarray는 빠르다고 했어요.
- 원래는 같은 인덱스끼리 덧셈을 합니다. (순차적 연산 수행)
- vectorized된 연산?
- core가 5개라면 산술연산을 5개 한번에 할 수 있다.
- 속도가 미쳤다.
- 하지만[1,2,3,4,5]+5는?
- 저차원을 고차원으로 늘려버립니다.
-[1,2,3,4,5]+[5,5,5,5,5]
- 이를 브로드캐스트 연산이라 합니다.[1,2,3]+[4,5]는 어떻게 하는데?
차원이 달라야 브로드캐스트 연산을 하지만, 더할 애가 없어서 에러가 납니다.
- vectorized 연산
- ndarray의 연산을 빠르게 수행하기 위해서 사용하는 방식 - broadcast 연산은 차원이 다른 경우 차원을 맞추어서 연산을 수행하는데, 요소의 개수가 다르면 수행을 하지 못합니다.
산술연산 (+*-/%) 가능합니다.
#산술연산 ar=np.array([1,2,3,4,5]) br=np.array([10,20,30,40,50]) result=ar+br print(result) result=ar+4 #이는 2개의 차원이 다른 경우이다. # 이 경우, 적은 차원의 데이터를 큰 차원으로 수정 #ar+[4,4,4,4,4] print(result) kr=np.array(range(1,11)) #1부터 10까지 print(kr) # print(ar+cr) # 요소 개수가 5개, 10개 차이로 오류가 남 cr=kr.reshape((2,5)) #2행 5열로 만들기 print(cr) print(ar+cr)
논리연산
>,>=,<,<=,==,!=가능- numpy의 equal, not_equal, greater, greater_equal, less, less_eqaul 함수 이용 가능
- numpy에서는 logical_and, logical_or, logical_xor, 함수도 제공함
# 논리연산 ar=np.array([1,2,3,4,5]) br=np.array([10,20,30,40,50]) print(ar>br) print(np.not_equal(ar,br)) print(np.logical_xor(ar,br)) # 다 값이 상수로 존재(true)해서 xor는 False # and or xor는 bool(Ture, False)로 변경해서 판정함
연산 하고 할당 가능
op=, 왼쪽의 데이터에 오른쪽의 데이터를 op에 따라 연산한 뒤에 왼쪽에 대입
ar=np.array([1,2,3,4,5]) br=np.array([10,20,30,40,50]) ar+=br # ar=ar+br print(ar) # 일반 list는 * 연산은 반복이다. 배열은 진짜 곱셈이다.
in과 not in 연산 제공
- in은 포함하고 있는지 여부 확인
- not in은 그 반대
ar=np.array([1,2,3,4,5]) br=np.array([10,20,30,40,50]) print(1 in ar) print([1,2] in ar) print([1,100] in ar)
- True, False, False
벡터화 된 함수를 적용
- ndarray에 함수를 적용한 결과를 얻고자 하는 경우는 함수를 만들고 벡터화된 함수를 만들어서 배열을 함수에 대입하면 됩니다.
- 벡터화된 함수를 만드는 방법은numpy.vectorize(함수)를 호출해서 리턴받으면 됩니다.
# 매개변수에 100을 더해서 리턴하는 함수를 만들어보자. def add100(param): return param+100 ar=np.array([1,2,3,4,5]) print(add100(ar)) # 벡터화된 함수로 수정하기 vector_add100=np.vectorize(add100) print(vector_add100(ar)) # 무슨 차이가 있는거지? # 얘는 한줄이라 람다로 쓸 수 있겠다 print(np.vectorize(lambda i:i+100)(ar))
행과 열 전치
- T라는 속성을 이용하면 행과 열을 변경 가능함
- transpose하는 함수를 이용하면 순서도 변경 가능
- 3차원 이상에서 사용합니다.
numpy 함수
random 관련
random.seed(seed=시드번호)
- 시드를 설정(난수표를 설정한다.)
- 시드값을 고정시키면, 난수가 일정한 패턴으로 리턴, 고정 안하면 난수 랜덤하게 생성되는 것처럼 보이게 됩니다.random(데이터 개수),random_sample(데이터 개수)
- 0.0 ~ 1.0 사이에서 개수만큼 리턴randint()rand()
- 균등 분포에서 표본 추출randn()
- 표준 편차가 1이고 평균 값이 0인 정규 분포에서 표본 추출binomial(n,p,size)
- 이항 분포에서 무작위 추출
- n은 나올 수 있는 개수
- p는 확률
- size는 개수normial(size)
- 정규(가우시안) 분포에서 size만큼 추출logistic()
- 로지스틱 분포에서 추출beta(),gamma()
- 베타, 감마 분포에서 추출chisquare()
- 카이 제곱 분포에서 추출uniform()
- 균등 분포에서 추출permutation
- 정수를 대입하면, 0부터 정수 이전까지 배열을 생성해서 숫자를 랜덤하게 배치하고 리턴
- 배열을 대입하면, 배열의 값을 랜덤하게 배치
- 유사한 함수로shuffle()이 존재함choice()
- 배열에서 복원 추출을 이용해서 데이터를 리턴
- permutation, shuffle (random)
import random cards=np.array(range(1,49)) print(cards) (np.random.shuffle(cards)) print(cards) result=np.random.permutation(cards) print(result) #seed 고정시키면? np.random.seed(seed=41) (np.random.shuffle(cards)) print(cards) result=np.random.permutation(cards) print(result) #고정당했죠?
기본 통계 함수
- sum
- 합계 - prod
- 곱 - nanprod
- none(numpy는 nan)은 1 간주하고 곱 - nansum
- none(numpy는 nan)은 0으로 간주하고 합 - mean, median
- 평균, 중간값 - max, min
- 최대, 최소 - std, var
- 표준편차, 분산
- ddof 옵션을 1로 설정하면 비편향 표준편차와 분산을 구합니다.
- ddof는 자유도 - percentile
- 배열과 백분위 값을 받아서 배열에서 백분위웨 해당하는 데이터를 리턴
- 2차원 배열의 경우는 옵션 없이 사용하면 전체 데이터를 기준으로 통계 값을 구하게 되고, axis 옵션을 이용한다면 행단위나 열단위로 계산이 가능합니다. - keepdims
- 옵션을 True로 설정한다면, 배열과 동일한 차원으로 결과를 리턴
# 기본 통계 함수 matrix=np.array([[10,20],[30,40],[50,60]]) print(matrix) print(matrix.sum()) print(matrix.std()) #표준 편차 print(matrix.std(ddof=1)) # 자유도 1 표준편차, #값이 달라짐을 확인할 수 있다. print(np.percentile(matrix,75)) # percentile은 쓰는 방법이 조금 다르다. print(matrix.sum(axis=0)) #열단위 합계 print(matrix.sum(axis=1,keepdims=True)) #행 단위 합계 하지만 matrix와 동일한 차원으로 리턴
- argmin, argmax
- 최소 값과 최대 값의 인덱스 - cumprod
- 누적 곱 - cumsum
- 누적 합 - diff
- 차분을 구하는 것으로, n값을 1로 설정하면 차분이 되지만, 2로 설정하면 차분의 차분
- 차이를 확인 or 차이의 차이 패턴을 구하거나...
# 기본 통계 함수 matrix=np.random.rand(20).reshape((5,4)) print(matrix) print(matrix.argmax(axis=1)) print(matrix.prod(axis=0))
소수 관련 함수
- round
- n 소수점 자릿수까지 반올림- rint
- 가까운 정수로 올림 혹은 내림- fix
- '0' 방향으로 가장 가까운 정수로 올림 혹은 내림- ceil
- 각 원소 값보다 크거나 같은 가장 정수 값(천장 값)으로 올림- floor
- 각 원소 값보다 작거나 같은 가장 큰 정수 값 (바닥 값)으로 내림- trunc
- 각 원소의 소수점 부분은 잘라버리고 정수 값만 남김- around
- 0.5를 기준으로 올림 혹은 내림
숫자 처리 함수
- abs
- sqrt
- square
- modf
- sign
판별 함수
- isnan
- isfinite
- isinf
집합 관련 함수
- unique
- 중복 제거- intersect1d()
- 교집합- union1d()
- 합집합- in1d()
- 존재 여부- setdiff1d()
- 차집합- setxor1d()
- 한쪽에만 존재하는 데이터
배열의 데이터 정렬
- sort()
- numpy.sort()는 배열을 받아서 정렬한 뒤에 리턴
- 2차원 이상일 때는, 정렬할 축의 번호를 axis를 이용해서 설정합니다.
- kind 매개변수로 정렬 알고리즘을 선택합니다.
- 기본 quick sort
- help(np.sort)에서 나온 입력 매개변수
ar=np.array([20,30,10,25,26]) result=np.sort(ar) print(result) print(ar) #원본은 그대로 # #2차원 배열에서 행에서의 배열 br=np.array([[10,60,70],[20,50,30],[15,32,29]]) result2=np.sort(br, axis=1) print(result2) print(br) # 보면 아시겠지만, 2차원 배열에서는 sort 거의 안쓸 것 같다. # 데이터는 행, 열단위로 바뀌어야 하지, 단순 데이터 단위로 바뀌면 안된다. # 가능은 하지만 그럴 일이 없는 것이다.

ndarray의 분할과 병합
- split
- 분할해주는 함수
- axis 옵션을 이용해서 행이나 열 단위로 분할이 가능합니다.
- 기본은 행 방양이고 분할하고 axis=1 설정 시, 열방향으로 분할
- 두 번째 파라미터에 N 값을 설정하면, N 개의 동일한 크기로 분할
- list를 설정하면 list에 대입된 인덱스에 따라 분할을 수행
- 행 단위 분할을 많이 하고, 열 단위 분할은 특별한 경우에 수행합니다.
x=range(1,51) matrix=np.array(x).reshape((10,5)) print(matrix) # data x를 7:3으로 분리해보자. x_70,x_30=np.split(x,[35]) #이거 뭔가 이상함 print(x_70) print(x_30) ## 강사님 # 행과 열의 개수 가져오기 print(matrix.shape) cnt=matrix.shape[0] print(cnt) # 이제 7:3 분할을 해보자. k=np.split(matrix,2) #이건 array 2개로 분할 print(k) k=np.split(matrix, [int(cnt*0.7)]) print(k[0]) print(k[1])
- concatenates
- 2개의 배열과 axis 옵션을 이용해서 배열을 합쳐서 하나를 만들어주는 함수
- 이 함수를 사용할 때는 합치고자 하는 방향의 데이터 개수가 같아야 합니다.
- numpy의 ndarray 나 pandas의 datarame은 직사각형 모양만 가능
- 특정 셀이 없는 형태는 불가능
✔ Pandas
- 효과적인 데이터 분석을 위한 고수준의 자료구조와 데이터 분석 도구를 제공하는 패키지 입니다.
- anaconda 사용하면 이미 설치 되어있음
- 설치는
pip install pandas - import는
import pandas as pd로 주로 사용함 - 데이터 분석을 많이하는 경우에는
from pandas import Series, DataFrame으로 도 씁니다.
자료구조
Series
- 인덱스를 갖는 1차원 데이터
- 일차원 배열과 유사하지만, 일차원 배열은 인덱스가 0부터 시작하는 번호이지만, Series는 0부터 시작하는 번호를 인덱스로 하용할 수 있고, 별도의 인덱스를 설정하는 것도 가능
- numpy의 함수나 연산을 그대로 사용할 수 있는데, 이 경우는 values의 데이터를 가지고 수행합니다.
- 연속된 범위를 선택할 때,
[시작번호:종료번호]의 경우는 종료번호가 포함되지 않습니다.
- 하지만,[시작인덱스:종료인덱스]의 경우는 종료 인덱스가 포함이 됩니다.
Series 생성 및 사용
Series(data, index=None, dtype=None, copy=False)
- dtype : 자료형
- data에는 list, tuple, set, ndarray 등이 대입 될 수 있음
- dict를 대입하면 key가 index, value가 value로 처리함
- dict를 제외한 데이터의 모임은 index가 0번부터 시작하도록 만들어 집니다.
- 각 데이터의 접근은이름[인덱스]
- Series의 인덱스 속성을 가져오면, 인덱스 배열을 리턴, values 속성을 호출하면, 값의 배열을 리턴합니다.
series1=pd.Series([10,20,30,40]) series2=pd.Series([10,20,30,40], index=["one", "two", "three", "four"]) print(series1) print(series2) series3=pd.Series({"영어":"Hi", "한국어":"안녕", "중국어":"Ni Hao"}) print(series3)
#인덱싱 print(series3[0]) #일련번호를 가지고 접근 print(series3["영어"]) #인덱스를 가지고 접근 print(series3[0:2]) #영어 한국어까지만 나옴 (종료위치가 포함 x) print(series3["영어":"중국어"]) #영어 한국어 중국어 다 나옴print(series1.values) # 값들만 추출 print(series1+100) # 연산은 ndarray와 동일하게 수행 # values 속성의 멤버들을 가지고 연산 print(np.sum(series1))# 함수 사용 가능

- Series와 Series의 연산은 동일한 인덱스끼리 수행합니다.
s1=pd.Series({"영어":79, "한국어":97, "중국어":45}) s2=pd.Series({"영어":np.nan, "한국어":97, "중국어":30}) print(s1) print(s2) print(s1+s2)
- nan 있으면 바로 터짐 해당 key값은
DataFrame
- 행과 열로 구성된 2차원 데이터
- 행열은 모든 데이터의 자료형이 일치해야 하지만, DataFrame(Table)은 열 방향으로만 데이터의 자료형이 일치하면 됩니다.
- 여러 개의 컬럼으로 구성된 2차원 테이블 구조
- dict(DTO 클래스나 VO 클래스)의 배열과 유사한 구조
- 프로그래밍 언어에서 하나의 행을 만드는 방법
- 클래스를 만들고 동일한 클래스의 인스턴스를 생성하는 방법
- 이런 용도와 글래스를 Domain이나 Entity, Model, DTO(Data Transfer Object), VO(value Object) 클래스라고 합니다.
- Dictionary(Dict, map이나 hashtable)의 인스턴스를 만드는 방법
- named tuple을 이용하는 방법
- tuple의 각 속성에 name을 부여할 수 있는 것
DataFrame 생성 및 사용
- dict를 만들 때, 각 키에 데이터의 모임을 할당하고, DataFrame 함수에 넘겨주면 key를 열의 이름으로 만들어서 DataFrame을 생성해 줍니다.
- 생성할 때, 열의 순서를 변경하고자 하면 columns 옵션에 열의 순서를 나열하면 됩니다.
items={ 'cdoe':[1,2,3], 'name':["바밤바","배뱀배","벼볌벼"], 'price':[850,900,1000] } #딕셔너리 생성 df=pd.DataFrame(items) #데이터프레임 생성 print(df) - 생성할 때, index와 columns 옵션을 이용해서 행의 이름이나 열의 이름을 설정할 수 있고, 만든 뒤에 index속성이나 columns 속성으로 읽고 변경이 가능합니다.
print(df.index) print(df.columns) df.index=range(1,4) #index 변경 df.columns=['코드','이름','가격'] #columns 변경 print(df) - 탐색 관련 함수나 속성
- values
- 데이터를 2차원 배열(ndarray)로 리턴- head(개수)
- 앞에서부터 개수만큼 리턴하는데, 개수 생략시 5개- tail(개수)
- 뒤에서부터 개수만큼 리턴, 생략시 5개- info()
- 데이터 프레임에 대한 정보 확인
- 행과 열의 개수 그리고 각 열에 대한 결측치 개수 및 자료형, 전체 메모리 사용량을 확인할 수 있습니다.#head나 tail 함수는 데이터가 제대로 불려왔는지 확인할 때 이용 print(df.head()) print(df.tail(1)) # 이 데이터를 머신러닝을 하고자 하면 머신러닝은 numpy의 ndarray로만 가능 print(type(df.values)) # 데이터 분석을 하기 전에, 데이터를 가져왔으면 데이터에 대한 정보를 확인 df.info()
Pandas를 이용한 데이터 수집
클림 보드의 데이터 가져오기
pandas.read_clipobard()
머신러닝을 학습하기에 알맞은 데이터 셋
- scickit-learn이나 seaborn 등 파이썬 라이브러리에서 제공하는 데이터 셋
- load_digits()
- 숫자 이미지 데이터 - 분류- load_boston()
- 보스톤 주택 가격 - 회귀- load_iris()
- 붓꽃 데이터 - 분류- load_diabates()
- 당뇨병 데이터 - 회귀- load_linnerud()
- 체력 검사 데이터 - 회귀- load_wine()
- 와인 품질 데이터 - 분류- load_breast_cancer()
- 유방암 데이터 - 분류- 아니면 캐글 : https://www.kaggle.com
- 데이콘
- UCI 머신러닝 저장소
- OpenAPI
# sklearn 데이터 가져와보기 from sklearn import datasets iris=datasets.load_iris() print(iris.target)
텍스트 파일 읽기
- 종류
- 일반 텍스트 파일
- fwt(일정한 간격을 갖는 텍스트)
- csv(콤마로 구분된 텍스트)
- tsv(탭으로 구분된 텍스트)
최근에는 거의 csv만 사용된다. - csv 읽는 함수
pandas.read_csv(파일경로 - 기본 구분자가 ,)pandas.read_table(파일경로 - 기본 구분자가 탭)- 특별한 옵션을 서정하지 않으면 첫 행의 데이터가 컬럼의 이름이 됩니다.
- csv 파일을 확인할 때는 항상
- 첫 행의 데이터가 컬럼인지 확인하고
- 구분자가 무엇인지 확인
- 한글 존재 여부 확인
- 데이터 건수가 어느 정도인지 확인
- 첫 몇개의 행이 데이터가 아닌지 (주석을 달아 놓을 수 있어서)
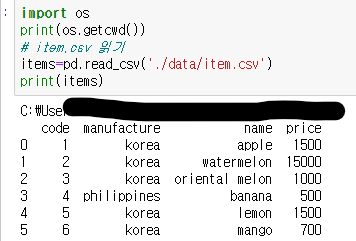
item.csv 읽기
- 첫 행이 컬럼 이름, 구분자는 쉼표, 한글은 없었음
read_csv 옵션
- 첫 번째 매개변수는 파일의 경로로 생략 불가능
- sep
- 구분자- header
- 컬럼 이름으로 사용할 행 번호로, 기본은 0인데 없을 때는 None 설정- index_col
- 인덱스로 사용할 컬럼 번호나 컬럼 이름- encoding
- 인코딩 종류를 지정(한글이 있으면 사용)- thousands
- 천 단위 구분 기호 설정- skiprows
- 건너 뛸 행의 개수- nrows
- 처음 읽을 때, 몇 개의 행을 읽을 것인지 설정- skip_footers
- 마지막 몇 개의 행을 읽지 않을 것인지 설정- na_values
- NA 값을 처리, 여기에 들어있으면 자동으로 NAN으로 변경
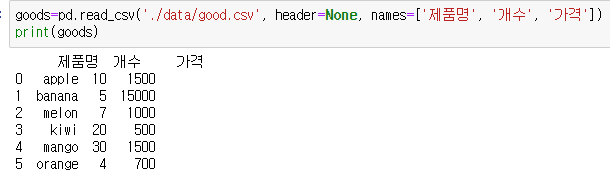
good.csv 읽어오기
- good.csv는 첫번쨰 행도 일반 데이터이다.
- 첫 행이 헤더가 아니라 하고, names를 이용해서 헤더 이름을 설정해야 한다.
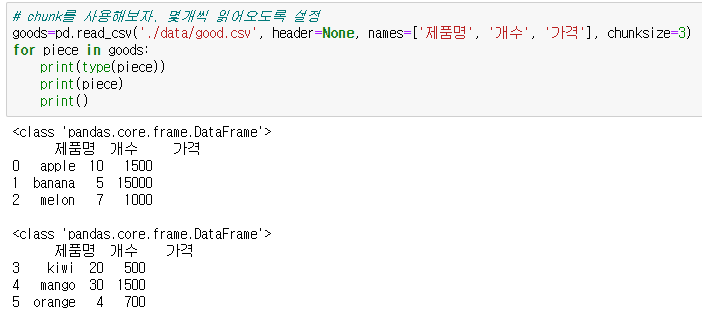
데이터의 양이 많을 때
- 실제 로그 데이터는 파일 사이즈가 매우 큽니다.
- 이런 경우는 pc에서 읽으려고 하면 읽어지지 않는 경우가 많음
- 이런 경우에는 일정한 크기로 분할해서 읽어서 모델을 만든 후 일부분을 다시 읽어서 모델을 재생성하는 방식을 사용
- 이를 청크라고 한다. - 읽을 때, chunksize라는 옵션을 사용해서 데이터를 읽으면 데이터를 순회하면서 읽을 수 있는 TextParser 객체를 리턴하는데, 이 객체를 이용해서 데이터를 부분적으로 읽어 올 수 있습니다.
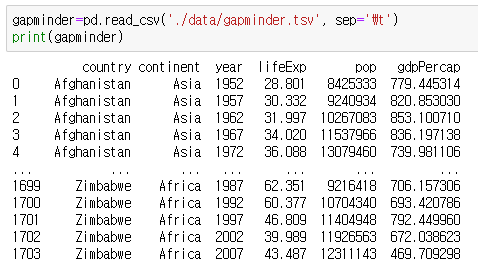
- nrows옵션과 skiprows 옵션을 이용하면 일부분씩 읽어올 수 있습니다.

밀가루 귀여워요