
✔ 농업 분야 대시보드 만들기
지역별 논경지 변화 대시보드
데이터 가져오기 및 편집
- 엑셀 파일 연결
-농경지_면적 _시도_시_군.xlsx - 데이터 시트를 캔버스에 배치
- 이때 필터적용 시, 필터에서 제외된 데이터는메모리에 로드되지 않습니다.
- Tableau는 생각 외로 메모리를 많이 잡아먹습니다. (화면에 시각화)
피벗 적용
- 차원이나 측정값은 데이터의 열 단위로 생성이 됩니다.
- 원본 데이터를 가져오다 보면, 차원이나 측정값이 원하는대로 만들어지지 않는 경우가 있습니다.
- 이런 경우는 행과 열 변환(
전치, transpose, Pivot(차원의 개수 줄이기))을 합니다.
- 단순 행과 열이 바뀌는게 아닌가?
- 차원이 줄어든다는 것을 정확하게 이해하지 못했어요
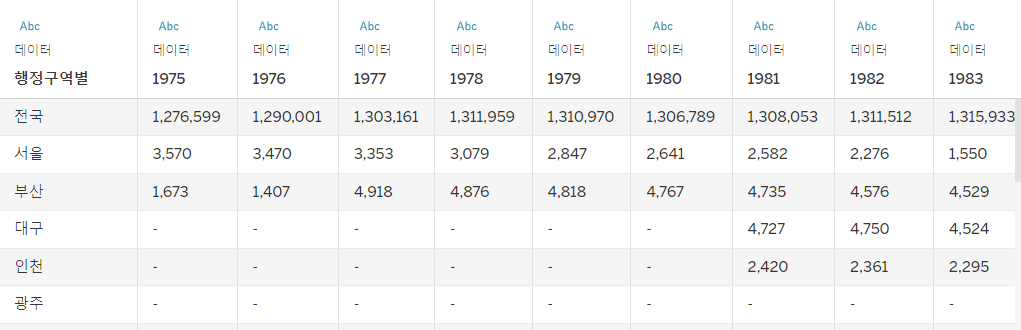
- 처음~2019(끝)까지 선택하고 2019위에 있는 추가버튼에 Pivot을 눌러보자.
- 진짜 줄어들긴 했다.
- 각 열의 이름을 [시도], [연도], [헥타르]로 변경하자.
- 열 이름 더블클릭하면 변경됩니다. - 헥타르는 숫자 데이터인데, 문자 데이터로 인식이 되기에, 숫자 데이터로 변경을 해주자. 피벗으로 변경하기 때문에 문자열이었던 것이 뽑혀 나왔다.
- 그리고 콤마(,)가 들어가 있다면, 이를 문자열로 인식할 수 있다.
- 정수로 바꿔주면 콤마가 사라진다.
- 면적(헥타르)는 원래 문자열이었기 때문에, 정수로 변경했어도 차원에 위치하고 있다. 그러기에 이를 측정값으로 변경해주자.

데이터 탐색
- 행 선반에 시도를 배치하고, 헥타르를 더블 클릭해서 테이블 형태로 출력하였다.
- 데이터를 빠르게 확인하기 위해서 내림차순 정렬을 수행한다.
- 전체를 보기위해 이렇게 본다면, 가장 중요한 것은 내부 비교를 할 때는 전체합계가 없는 것이 나을 때가 많습니다.
- 다른 데이터와 비교하기에는 알맞지 않은 데이터인 것 같다.- 이상치 판단을 제대로 할 수 없을 수 있다.
- 분포를 확인해야 한다.
- 해당 데이터가 어떤 문제가 있는지는 분포를 확인해서 알 수 있다.
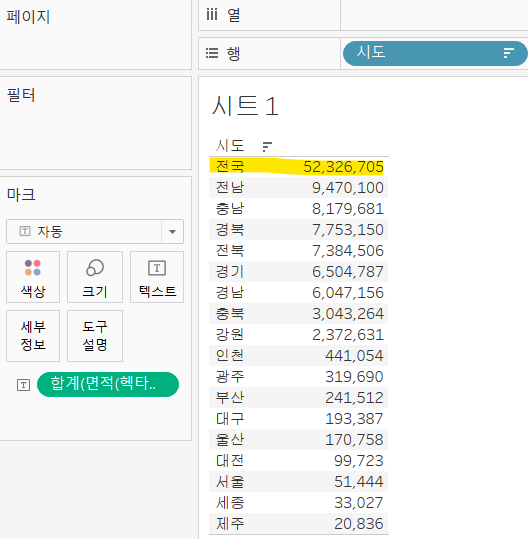
전국 데이터 제거
- 왼쪽 하단의 데이터 원본을 클릭하고 우측 상단의 필터를 눌러 불필요한 데이터 삭제
- 전국을 넣으면 데이터 비교가 어려우니 빼자.
- 상황을 보고(탐색, 분석) 데이터 제거를 하자.- 데이터 분석 작업은 나선형, 혹은 애자일 형태로 작업을 수행합니다.
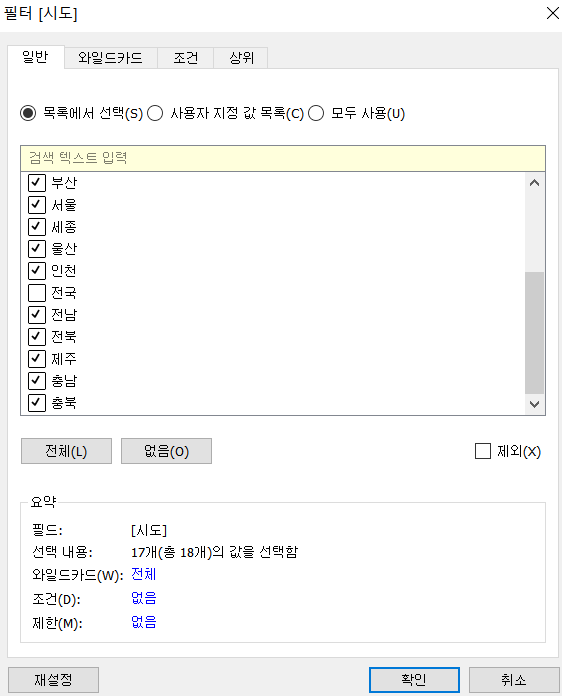
시도별 맵
- 현재 시트 이름을 [시도별 맵]으로 변경
- 시도 필드를 지리적 역할로 변경
- 시도 필드 abc부분 클릭 지리적 역할 주/시/도 클릭 - 지리적 역할을 수행하는 필드를 더블 클릭하면 그에 맞는 지도가 출력됩니다.
- 마크를
맵으로 바꾸면 잘 나온다. - 우리나라 영역만 본다면 [맵] 메뉴 [백그라운드 레이어] 투명도 100% 설정
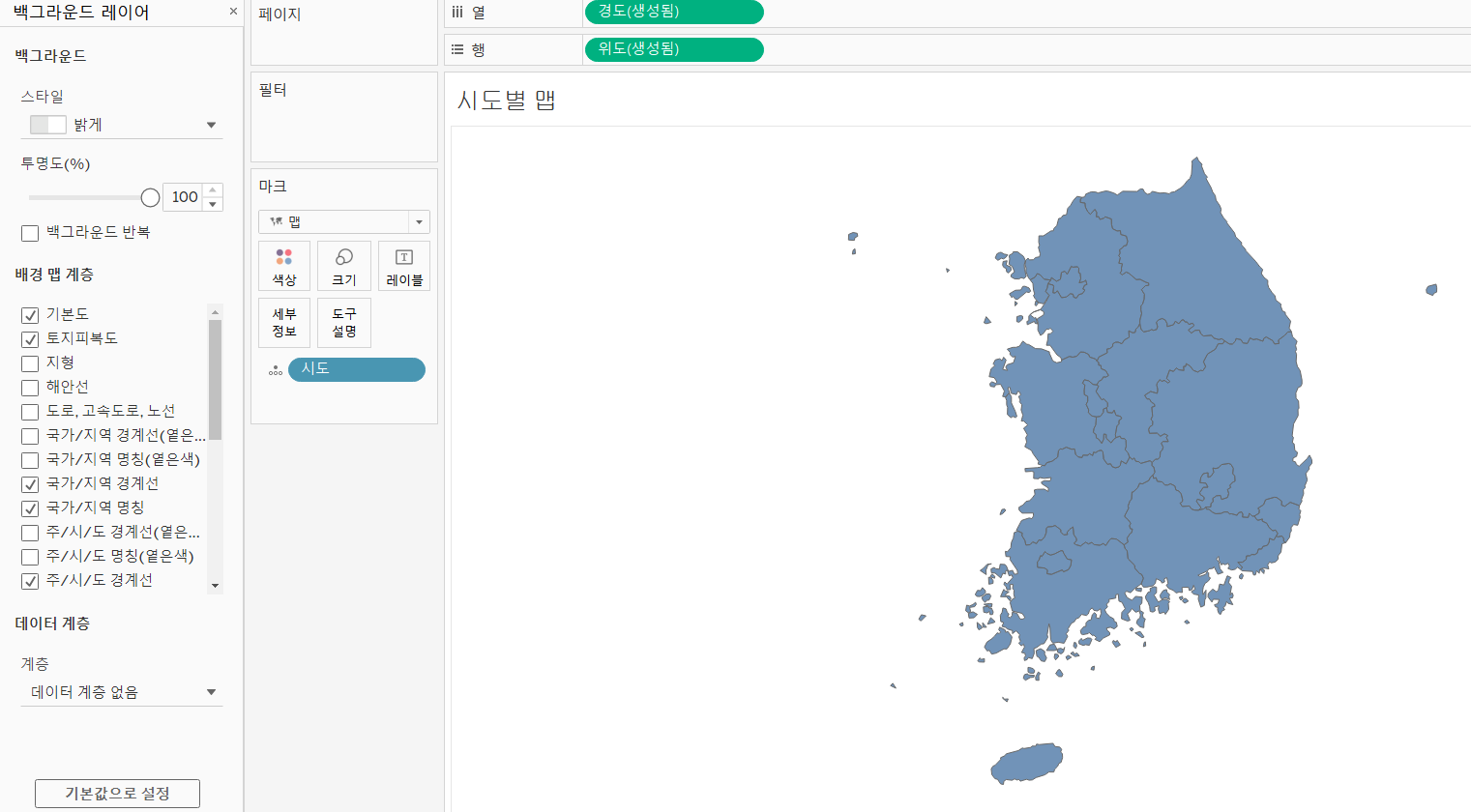
- 마크의 색상을 흰색으로 수정합니다.
- [시도]필드를 마크의 레이블로 배치해서 각 영역에 시도가 출력되도록 설정합니다.
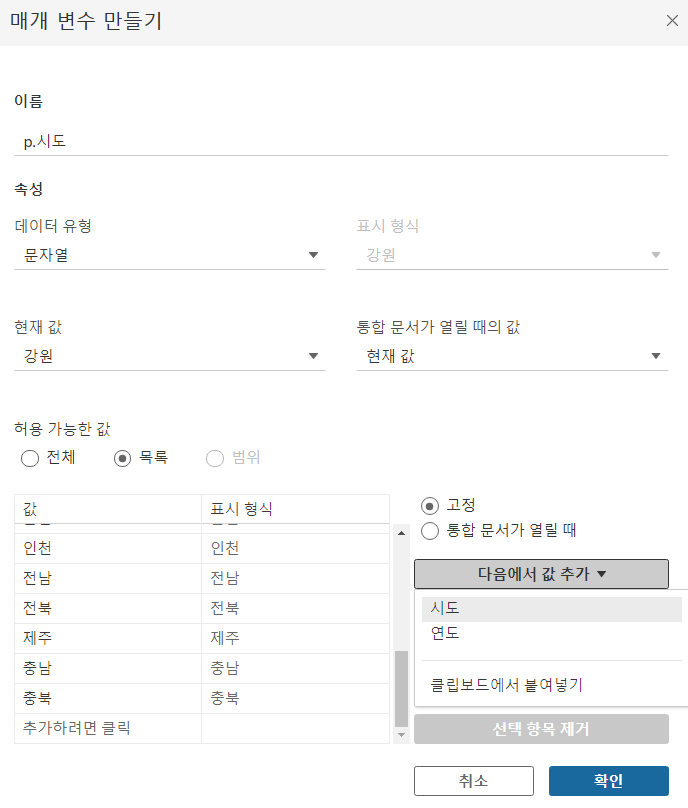
- 이제 영역을 선택하기 쉽도록 매개변수를 생성합니다.
- 이름 : p.시도
- 사용 가능한 값을 목록으로 해서 시도 필드를 선택
- 목록하고 다음에서 값 추가 누르면 [시도]필드 나온다.
- 사용 가능한 값을 목록으로 해서 [시도]필드를 선택(대화상자에서 다음에서 값 추가를 누르고 시도를 선택)
- 다 만들고
매개변수 표시를 하면 우측에 표시된다.
- 매개변수에서 선택한 데이터의 색상을 변경하기 위해서 계산된 필드를 추가합니다.
- 필드 이름은h.시도로 하겠습니다.
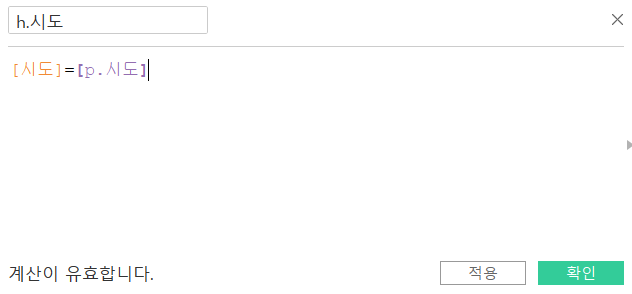
- h.시도 필드를 색상 마크에 배치하고, 색상을 수정합시다.
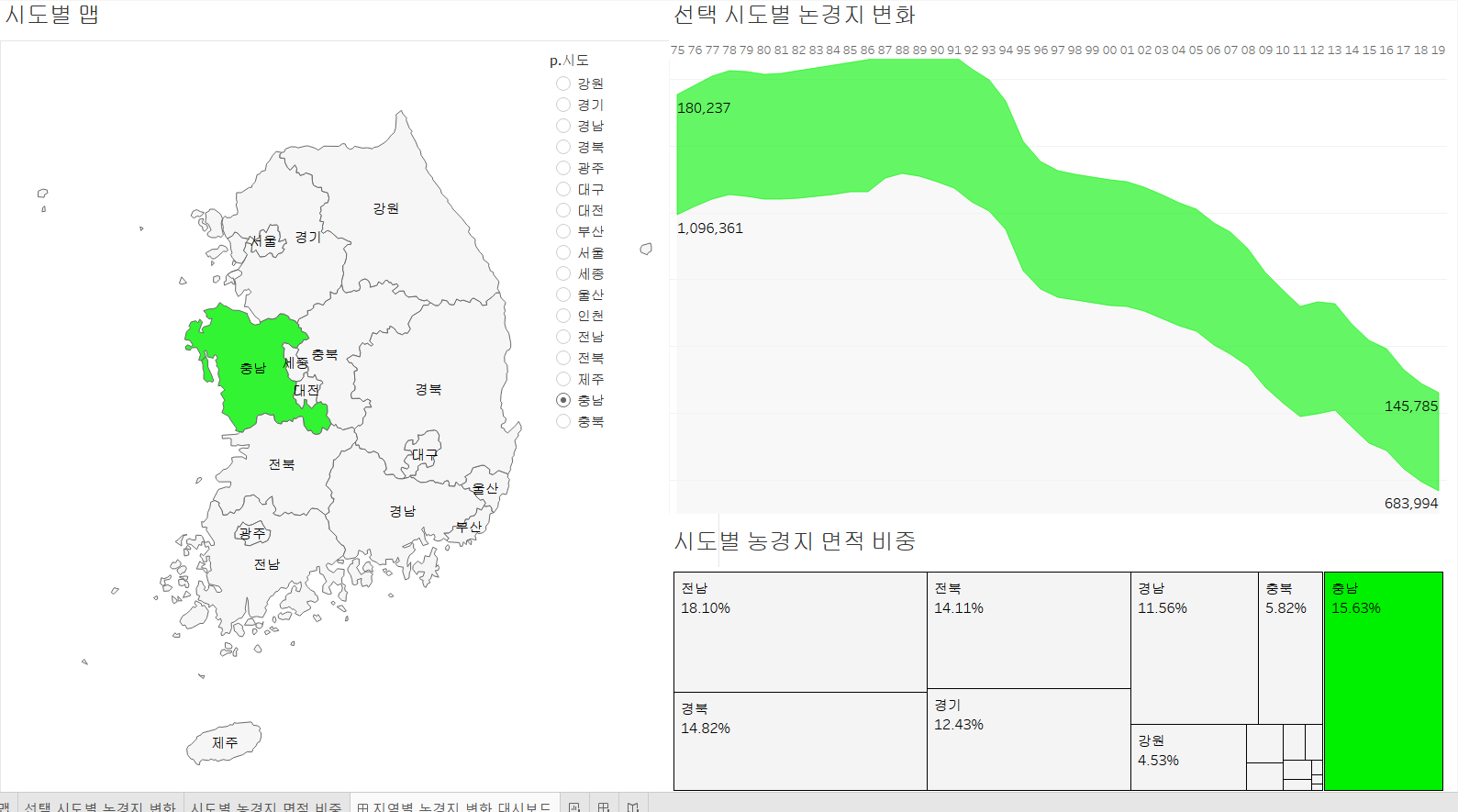
선택된 시도별 논경지 변화를 출력하는 시트
- 새로운 워크시트를 추가하고 [선택 시도별 논경지 변화]으로 이름을 수정
-
연도 필드를 열 선반에, 면적(헥타르) 필드를 행 선반에 배치하고, 마크는 [영역]으로 설정한 후 툴바에서 전체보기로 맞춤 설정
-
h.시도를 색상에 배치
- 우측에 있는 계산된 필드에서 참을 거짓 위로 올리기 -
연도 필드의 머리글이 하단에 있어서, 상단으로 배치하기 위해, [분석][테이블 레이아웃] [고급] 세로 축이... 체크박스 해제
-
연도가 4자리라 제대로 표시가 안되기에, 연도를 숫자로 우선 변환 하고, 열 선반에 있는 연도의 [추가메뉴][서식][기본값][날짜][사용자 지정]
YY로 설정 -
연도 라는 필드 레이블을 삭제
- 연도라는 텍스트 위에서 마우스 우클릭 후 [열에 대한 필드 레이블 숨기기] 선택 -
레이블 마크에 면적(헥타르) 배치 후, 마크 클릭해서 최소/최대 선택하고, 범위를 패널로 변경하고 필드를 연도를 선택하면, 연도의 초소와 최대에 해당하는 값만 출력합니다.
-
[h.시도] 필드에 대한 참과 거짓을 구분해서 표시하기 위한 계싼된 필드를 생성
- 필드 이름 : h.시도_레이블
- 계산식 :IIF([h.시도],[시도],"기타 지역") -
[h.시도_레이블]을 마크-도구 설명에 배치
- 기존에는 해당 지역이 어디인지 몰랐지만, h.시도_레이블을 도구설명에 배치하고 데이터를 확인해볼 때, 해당 지역이 어디인지 설명해준다.

- 이후 전체 그래프에서 면적 축축편집 0포함 제거를 하면 차트가 커지는 효과가 있습니다.
- 변경 내역만 보면 되기에, 헥타르의 머리글을 해제합니다.
시도별 논경지 면적 비중 시트
- 논경지 면적을 트리 맵으로 출력
- 시도 필드와 면적 필드를 선택하고, 표현방식 트리 맵 형태 선택
- 색상 마크에 지정된 면적(헥타르) 제거하고, h.시도를 색상에 배치
- 이후, 트리맵 구분을 위해 색상 테투리 설정을 해서 잘 보이게 해주자.
- 면적(헥타르) 필드를 레이블 마크에 배치하고, [퀵 테이블 계산] [구성 비율]을 선택하고, 서식을 백분율로 설정하고 소수점 첫째짜리까지 출력하도록 설정
대시보드
- 대시보드를 추가하고, 1600*900 으로 크기 설정(PowerPoint)
- 대시보드에 가로 컨테이너 배치
- 시도별 맵을 가로 컨테이너에 배치
- 빈 페이지 배치를 우측에 두자
- 대시보드 표현 방식을 바둑판식에서 부동으로 변경하면 원하는 곳에 컨테이너 배치 가능함
- 세로 컨테이너를 적절한 위치에 배치하기
- 선택시도 논경지 면적 시트를 shift누른 채 세로 컨테이너에 배치
- 얼레벌레 첫 대시보드 만들기
✔ 하나 더 만들기 - 심화
- 17개 시도를 개별 맵으로 분할하고, 해당 맵에 마우스 오버를 했을 때, 전국 맵에서 해당 시도 위치에 하이라이팅 처리를 하고 PDF 다운로드 버튼을 배치하기
시도 별 맵 분할 시트
-
워크시트를 추가하고, 이름을 [시도 별 맵 분할] 로 해두자.
-
화면 분할 개수를 설정하기 위한 매개변수를 생성
- p.화면분할
- 값은 3에서 6까지 -
2개의 계산된 필드 생성
- 이름 : X
- 계산식 :(INDEX()-1)%([p.화면분할])
- 이름 : Y
- 계산식 :INT((INDEX()-1)/([p.화면분할]))
- 둘 다 불연속형으로 변환
- 마크를 맵으로 변경, x를 열 Y를 행 선반에 배치, 시도를 레이블에 배치
- 열 선반에 있는 X를 선택하고 우클릭 테이블 계산 편집 특정차원 시도 체크
- 행 선반에 있는 Y를 선택하고 우클릭 테이블 계산 편집 특정차원 시도 체크
- [시도]필드에서 우클릭 [만들기] [집합] 시도 set이름 설정 및 한개 체크해두기
- [시도 set]을 색상에 배치
- 깨진다. - 열 선반에 있는 X 필드에서 우클릭 [테이블 계산 편집] [특정 차원] [시도 set의 In/Out] 체크
- Y도 동일하게 작업
- 레이블 - 맞춤 - 가로 가운데, 세로 위쪽 설정
- 행 열 머리글 해제, 색상 정하기
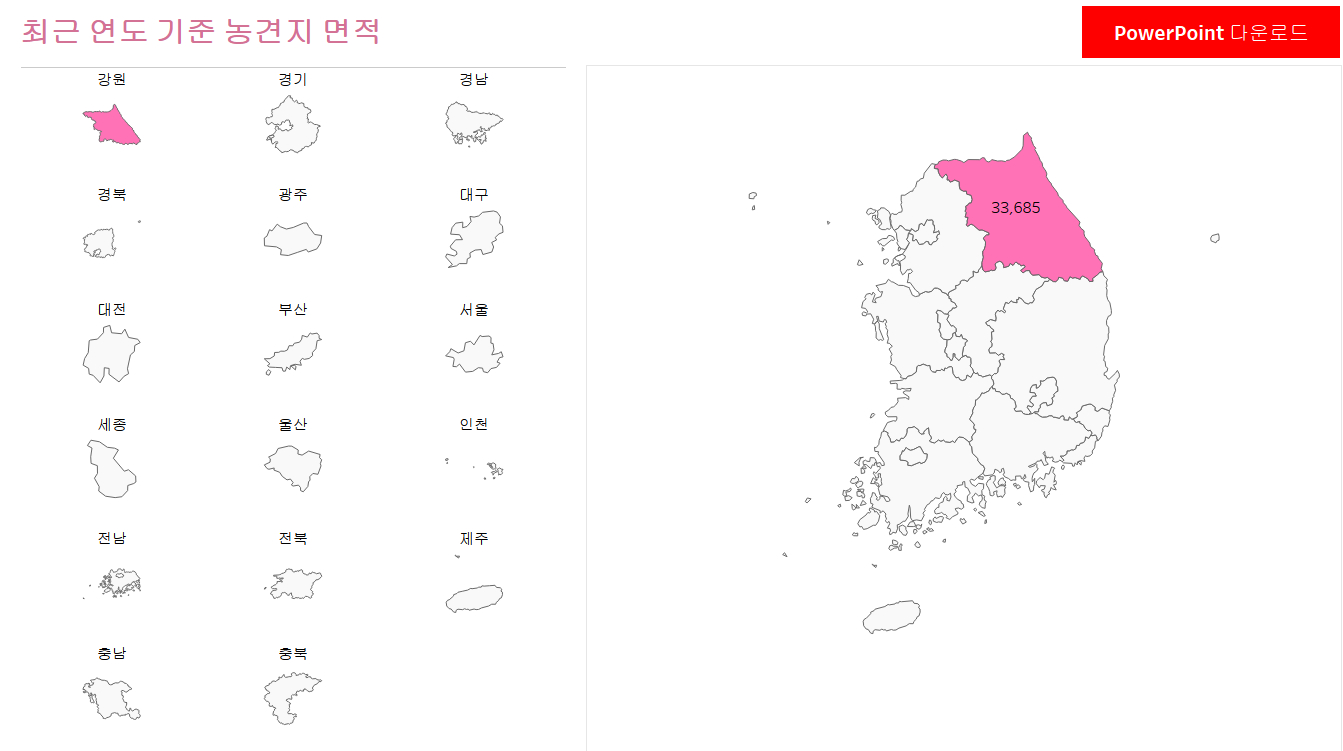
최근 연도 기준 면적 시트
- 워크시트를 추가하고 시트 이름을 최근 연도 기준 면적으로 변경하기
- 시도 필드를 더블 클릭해서 지도를 표시하고, 마크를 맵으로 수정
- [시도 set]을 색상에 배치
- 마지막 연도의 논경지 면적을 계산하는 필드 생성
- 이름 : c.최근 연도 시도 면적(헥타르)
- 계산식 :IIF[연도]={FIXED:MAX(연도)}THEN [면적(헥타르)]END - 새로 계산된 필드를 레이블 마크에 배치
대시보드
- 대시보드를 추가
- 크기를 1366*768(일반 데스크탑) 으로 설정
대시보드 동작 추가
- 시도 별 맵 분할 시트에서 마우스 오버를 하면, 최근 연도 기준 면적 시트가 오버된 지역을 활성화 하도록 동작하게 만들자.
- 선택한 것만 값이 보이게 하려면
최근 연도 기준 면적 시트에서c.최근 연도 기준 면적계산된 필드 계산식을IF([시도 set]==True AND[연도]={FIXED:MAX([연도])})THEN [면적(헥타르)]END로 설정하면 된다.
그냥 집합값 true인 것만 보여주겠다는 것이다.
✔ Python 데이터 분석 패키지
numpy
- 고성능의 과학적 계산을 수행하기 위한 패키지
- python 머신러닝 스택의 기초
- 딥러닝에서는 numpy의 ndarray만을 이용
- 다차원 배열인 ndarray를 제공하고, 빠른 배열 계산과 유연한 브로드캐스팅 연산을 지원
- C와 Fortran으로 만들어져서 CPython에서만 사용 가능
- 설치
-pip install numpy
- 아나콘다를 설치하거나 머신러닝이나 딥러닝 패키지를 설치하면 자동 설치
- import
import numpy : numpy 패키지는 numpy라는 이름으로 가져와서 사용 - numpy.array() from numpy import * : numpy의 모든 내용을 현재 패지키로 가져와서 사용 - array() import numpy as np : numpy패키지를 np라는 이름으로 가져와서 사용 - np.array() (권장)
ndarray
- 배열
- 모두 동일한 자료의 grid - list나 tuple보다 생성 방법이 다양하고, 사용 가능한 작업도 많음
- 벡터화 된 연산을 지원하기 때문에, 연산속도가 빠릅니다.
- 머신러닝이나 딥러닝에서 사용하는 자료의 기본 단위입니다.
- 딥러닝은 머신러닝 중에서 신경망을 이용하는 지도 학습의 일종 입니다. - 작업시간 비교
# list 생성 li=range(1,1000000) #현재 시간 저장 s=datetime.datetime.now() #시작 시간 print("시작시간: ",s) #모든 요소에 10을 곱해서 list를 수정 for i in li: i=i*10 # guswo tlrks wjwkd s=datetime.datetime.now() # 종료시간 print("종료시간: ",s)
- 시작시간: 2023-08-07 15:24:12.477583
종료시간: 2023-08-07 15:24:12.544297ar=np.arange(1,1000000) #현재 시간 저장 s=datetime.datetime.now() #시작 시간 print("시작시간: ",s) #모든 요소에 10을 곱해서 list를 수정 ar=ar*10 # guswo tlrks wjwkd s=datetime.datetime.now() # 종료시간 print("종료시간: ",s)
- 시작시간: 2023-08-07 15:26:31.650011
종료시간: 2023-08-07 15:26:31.653016- 일반적으로 list보다 ndarray가 10배정도 빠르다.
ndarray 생성
ndarray((행의 수 ,)): 권장하지 않음array(iterator 객체)
- 생성가능한데, copy 매개변수 값을 True시 복제해서 생성, False 설정시 참조만 복사
- 기본값은 Ture이다.asarray함수는 입력 데이터가 ndarray가 아니면, 복제를 해서 ndarray를 리턴하고, 입력데이터가 ndarray라면 참조만 복사합니다.- 각 데이터의 자료형은 모두 일치해야 하는데, 자료형 설정은 dtype옵션을 이용해서 설정하는데, 설정하지 않으면 유추해서 설정합니다.
- ndarray에는 copy 메서드가 제공되어서 복제를 하고자 하는 경우에는 copy 메서드를 이용하면 된다.
정보 확인
- 데이터 출력은 print 함수에 ndarray를 대입
- ndarray의 속성
- dtype
- 요소의 자료형
- type(전체 자료형)과 혼동 하면 안된다.- ndim
- 배열의 차원- shape
- 각 차원의 크기를 저장한 정수 튜플
- 이미지 크기를 확인할 때나 데이터 구조를 확인할 때 많이 사용- size
- 데이터의 개수- itemsize
- 하나의 항목이 차지한 메모리 크기- nbytes
- 전체 메모리 크기
# 배열 정보 확인 ar=np.array([1,2,3,4]) print(type(ar)) # ar의 자료형 print(ar.dtype) # ar에 저장된 요소의 자료형 print(ar.ndim) print(ar.shape)
- 결과
<class 'numpy.ndarray'> int32 1 (4,)ar=np.array([[1,2,3],[4,5,6]]) print(ar.ndim)# 2 print(ar.shape) # 2행 3열 # 이미지 데이터를 가져왔을 때, 반드시 ndim과 shape돌리기 하자
생성 함수
arrange([start,]stop,[step,],dtype=None)
- 개수를 지정하지 않고 시작위치, 종료이치, 간격을 설정해서 데이터 생성linspace(start,stop,num=50,endpoint=True, retstep=False, dtype=None);
- 확률이나 통계 실습을 할 때 많이 사용
- num이 개수이다.
ar=np.arange(1,100,2) print(ar) ar=np.linspace(1,100,num=10) print(ar)[ 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47
49 51 53 55 57 59 61 63 65 67 69 71 73 75 77 79 81 83 85 87 89 91 93 95 97 99]
[ 1. 12. 23. 34. 45. 56. 67. 78. 89. 100.]
특수 행렬
- zeros()나 ones()를 이용한 0이나 1로 채워진 배열을 생성
- 차원은 매개변수로 받는데, 1차원은 숫자 하나만 입력
- 2차원 이상은 튜플로 설정(데이터 나열)
- (10) 은 튜플 x (10,) 이게 튜플 - zeros_like나 ones_like 함수는 배열을 매개변수로 받아서 동일한 모양의 0이나 1로 채워진 배열을 리턴
- empy나 empty_like는 값을 초기화하지 않고 배열을 생성해서 리턴
- eye나 identity 함수를 이용하면 대각선 방향으로 1을 채운 배열을 리턴함
-eye(N,M=,k=,dtype=)
- M은 열의 수, k는 대각의 위치, 기본은 0(0이면 가운대 대각선), 정수를 입력하면 좌 우로 이동함 - diag()는 정방행렬을 대입받아서 대각 요소만 추출해서 배열을 생성해주는 함수이다.
- eye와 k 옵션의 성질은 동일함
# eye - 대각선 방향으로 1을 채운 행렬 ar=np.eye(3) print(ar) ar=np.eye(3, k=1) # 3x3 대각행렬 생성후, 기본에서 위로 1 올라감 print(ar) ar=np.eye(3, k=-1) # 얘는 기본에서 1 내려감 print(ar)
ar=np.array([[1,2,3],[4,5,6],[7,8,9]]) print(ar) br=np.diag(ar) # 대각 방향이기에 1,5,9 print(br) cr=np.diag(ar,k=-1) # -1 한칸 내려간 대각이라 4,8만 print(cr)ar=np.array([[1,2,3],[4,5,6],[7,8,9]]) print(ar) br=np.diag(ar) # 대각 방향이기에 1,5,9 print(br) cr=np.diag(ar,k=-1) # -1 한칸 내려간 대각이라 4,8만 print(cr)[[1 2 3][4 5 6]
[7 8 9]]
[1 5 9]
[4 8]

dtype
- 배열의 요소의 자료형
- 배열은 동일한 자료형으로 만들어진 빈 공간없이 연속된 리스트
- 데이터를 만들 때, 자료형을 설정하지 않으면 numpy가 유추해서 설정을 하고 dtype옵션을 이용해서 자료형을 설정하면, 그 자료형으로 만드는데 자료형 변경에 실패하면 예외가 발생합니다.
- dtype 속성을 이용해서 확인이 가능합니다.
- astype함수를 이용하면 자료형을 변경해서 생성하는 것도 가능합니다.
- 자료형
- 정수 : int8,16,32,64, uint8,16,32,64 - int음수양수, uint는 양수만
- 실수 : float16,32,64,128
- 복소수 : complex64,128,256
- 불린 : bool
- 객체 : object
- 문자열 : string
- 유니코드 : unicode
ar=np.array([1,2,'3']) #문자열로 배열이 생성됩니다. print(ar) ar=np.array([1,2,'3'], dtype=np.int32) #정수로 자료형을 지정하자 print(ar) ar=np.array([1,2,'3']) #다시 문자열로 저장 print(ar) br=ar.astype(np.int32) #br은 정수형태임 print(br)['1' '2' '3']
[1 2 3]
['1' '2' '3']
[1 2 3]
(중요) 행렬의 차원 변환
- reshape(변경할 차원을 튜플로 대입)
- 기존의 배열을 수정해서 새로운 배열로 생성
- -1을 대입하면 1차원 배열로 생성
- 저차원을 고차원으로 변경하기도 하고 고차원의 데이터를 저차원으로 변경하기도 합니다. - flatten()
- 다차원 배열을 1차원으로 변경하는데, 복사본을 가지고 작업해서 새로운 배열을 리턴합니다. - 딥러닝에서 이미지의 경우에는 모두 동일한 차원인 경우에만 학습이 가능합니다.
- 이미지 데이터를 가져오면 모든 이미지를 동일한 차원의 데이터로 수정을 해야 하는데, 이때 reshape나 flatten 함수를 이용합니다.
- 딥러닝에서는 차원의 개수도 맞아야만 학습이 가능합니다.
# 주의사항 matrix=np.array([[1,2,3],[4,5,6],[7,8,9]]) print(matrix) ar=matrix.reshape(-1) print(ar) # 여기까진 잘 나와 ar[0]=101 print(matrix) # 그런데 ar을 바꿨는데 matrix가 바뀐다. 둘이 동일하다. br=matrix.flatten() print(br) br[0]=201 print(matrix) print(br) #reshape는 접근 방법을 바꾼 것이라 동일한 데이터 #flatten은 복사본에 작업하는 것이라 다른 데이터이다.
- 이 2개는 무조건 외워야 합니다.
- 1차원으로 바꿀때는 flatten을 사용함

인덱싱
- 배열 내에서 데이터를 골라 내는 것
- 일차원 배열
[인덱스] [시작위치:종료위치] [시작위치:] [:종료위치] [:]
- 단, 종료위치는 종료위치 앞까지이다.
- 다차원 배열
-[행번호][열번호]
- 행 번호나 열번호를 생략하면, 생략한 부분 전체 - 기본 인덱싱은 참조를 리턴합니다!
- 원본과 동일한 데이터라는 말입니다.
- 슬라이싱은 복제를 합니다. - Fancy Indexing
- 인덱싱을 할 때, list를 사용하는 것
- 이것도 복제를 합니다. (참조 리턴 x)
-여기하단부분 약간 문제있어요
matrix=np.array([[1,2,3],[4,5,6],[7,8,9]]) print(matrix) #전체 출력 ar=matrix[0] br=matrix[0,] print(ar) print(br) # 둘다 0번행을 인덱싱하였다. ar[0]=100 # 인덱싱 해서 가져온 리스트의 값을 변경 print(ar) print(br) print(matrix) #참조 리턴이라 해당 부분이 싹 바뀐다. cr=matrix[[0]] # list를 이용하는 인덱싱을 팬시 인덱싱이라 한다. dr=matrix[0][:] # 범위를 이용하는 형태를 슬라이싱이라 한다. #복제된 데이터를 수정해도 원본에 영향을 주지 않습니다. print(cr) print(dr) cr[0,0]=486 dr[1]=972 print(cr) print(dr) print(matrix)

- boolean indexing
- 인덱스에 bool 배열을 대입해서 true인 데이터만 골라내는 것
- 배열 대신에 연산을 삽입해도 됩니다.
- numpy에서는 배열과 scala 데이터의 연산은 배열의 모든 데이터를 순회하면서 연산을 수행하고 그 결과를 배열로 리턴합니다.
arr=np.array([10,2,30,5,22,37]) brr=np.array([1,2,3,4,5,6]) # 길이는 맞춰주자. print(brr[arr>=30])# arr이 30 이상인 인덱스를 가져옴 # 대신 이건 false false true false false true 이러고 true만 가져옴 # 그래서 길이가 동일하다고 가정하고 하는 것임
- 이때, and와 &가 다른 것을 기억하자.
전체 vs 개별이다.- 즉 저 안에서 and 조건을 주려면 and 쓰면 터진다. (ambiguous)
- | 이걸 써줘야 할 것이다
- 배열과 연산을 할 때, and 나 or는 배열 자체를 true false로 간주하고 연산을 하고, | & ^ ! 는 배열의 데이터가 각각을 가지고 연산을 수행합니다.
