
✔ 시트 가져오기
Car for Tableau.xlsx 파일 연결
여러 개의 시트를 가져와서 JOIN
- 여러 개의 시트를 가져와서 조인을 할 때, 양 시트에 동일한 이름의 필드가 존재하면 자동으로 JOIN을 해주고, 동일한 이름의 필드가 존재하지 않으면 직접 필드를 설정합니다.
- 2개의 필드의 자료형이 일치해야 하는데, 차원이나 측정값의 형태가 같으면 됩니다.
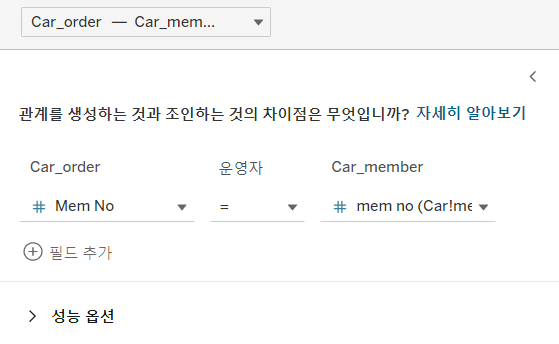
- 실제 DB 볼땐, 외래키 알아야 하지만, 같은 이름의 필드가 있다면 알아서 만들어주고, 외래키가 없다면 ⚠표시를 해준다.
- Inner JOIN(Equi JOIN)
- 이렇게 외래키가 없다면 표시해준다.

- Join의 기반은 Cartesian Product(Cross JOIN) 이다.
- 해당 테이블에 대한 모든 데이터를 전부 결합하여 Table에 존재하는 행 갯수를 곱한 만큼의 결과값이 반환되는 것이다.
- PK, UNIQUE 만 알 수 있다면 FULL TABLE SCAN을 안해도 된다.
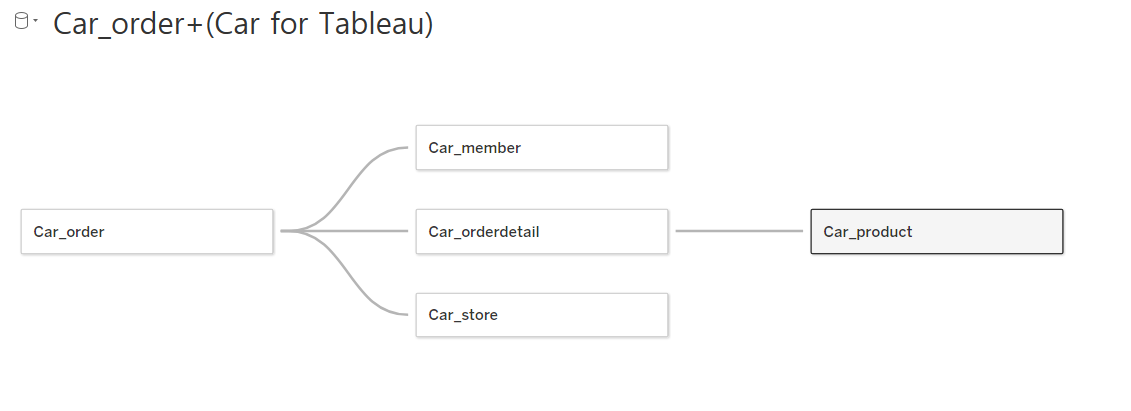
- Car_order
- Car_meber, Car_orderdetail, Cat_store 시트는 Car_order와 JOIN
- Car_product는 Car_orderdetail과 JOIN
워크시트 & 대시보드
- 워크시트 하나에는 View가 한개만 들어간다.
- 시트를 여러개 만들자.
- 하지만, 대시보드는 여러개의 그래프를 보여줄 수 있다.
- 대시보드는 여러 개의 워크시트를 합쳐서 보여주는 것이다.
✔ QUICK TABLE
- 데이터 시각화에 자주 사용되는 누계 / 구성 비율 / 순위 / 전년 대비 성장률 등을 빠르게 적용할 수 있도록 해 주는 기능
실습 - Price * Quantity 수식을 갖는 매출액 필드 생성
- 이를 파생(Derived - 상속) 필드 라고 한다.
- 상위 클래스 - based class
- 하위 클래스 - derived class
<데이터 분야>- 데이터의 속성(필드)에서는
파생 필드는 물리적으로는 존재하지 않고,
필요에 따라 다른 속성을 이용해서 생성 가능한 속성을 파생이라고 한다.- 이 속성이 자주 사용된다면 해당 속성은 DB에 미리 만들어 두어도 된다.
- 조회 속도를 높이기 위해서입니다.
- 조회 속도를 높이는 작업을 반정규화 혹은 역정규화라고 합니다.
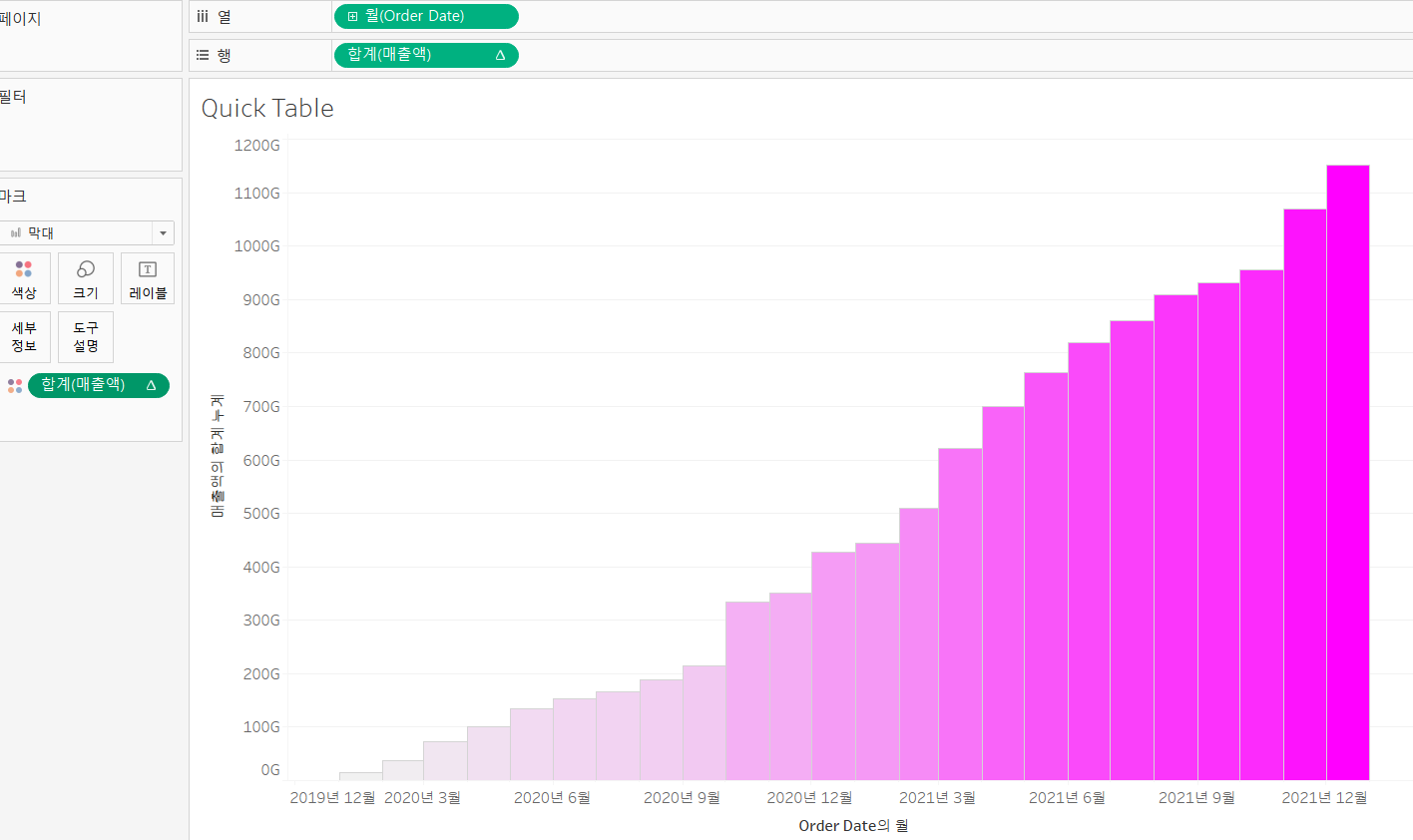
- 매출액 수식은
[Price]*[Quantity]이며, 계산된 필드를 만들어 두자.- 매출액과 Order Date를 이용해서 누적 막대 차트 생성
- 마크 카드에서 유형 -막대
- 행 , 열에 매출액과 Order Date 배치하고, 년월 연속형으로 변경
- [합계(매출액)]을 클릭하고 [퀵테이블 계산] - [누계] 를 해보자.
✔ 개별 / 단일 /이중 축
- 여러 측정 값을 어떻게 하나의 뷰에서 볼 것 인지 결정
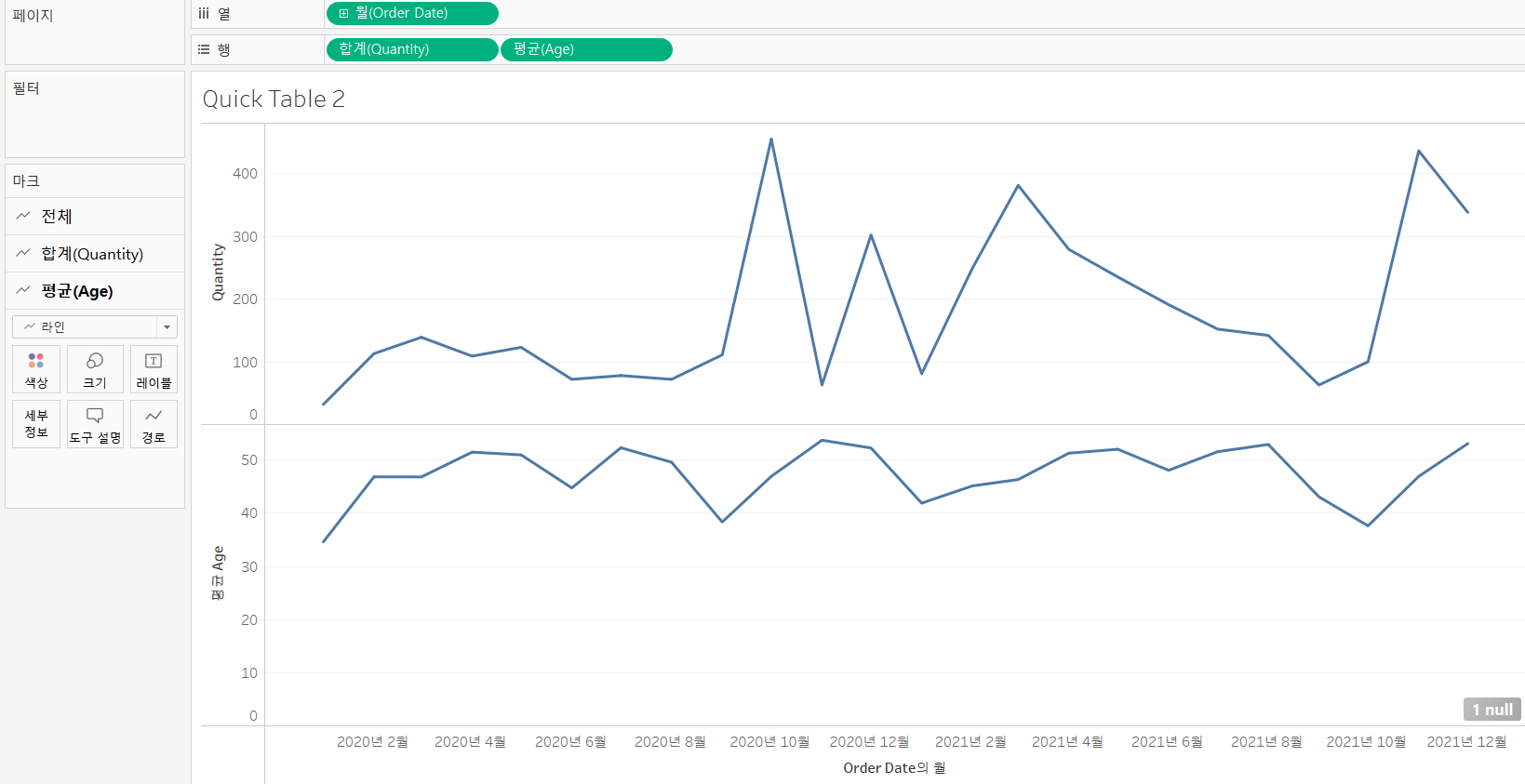
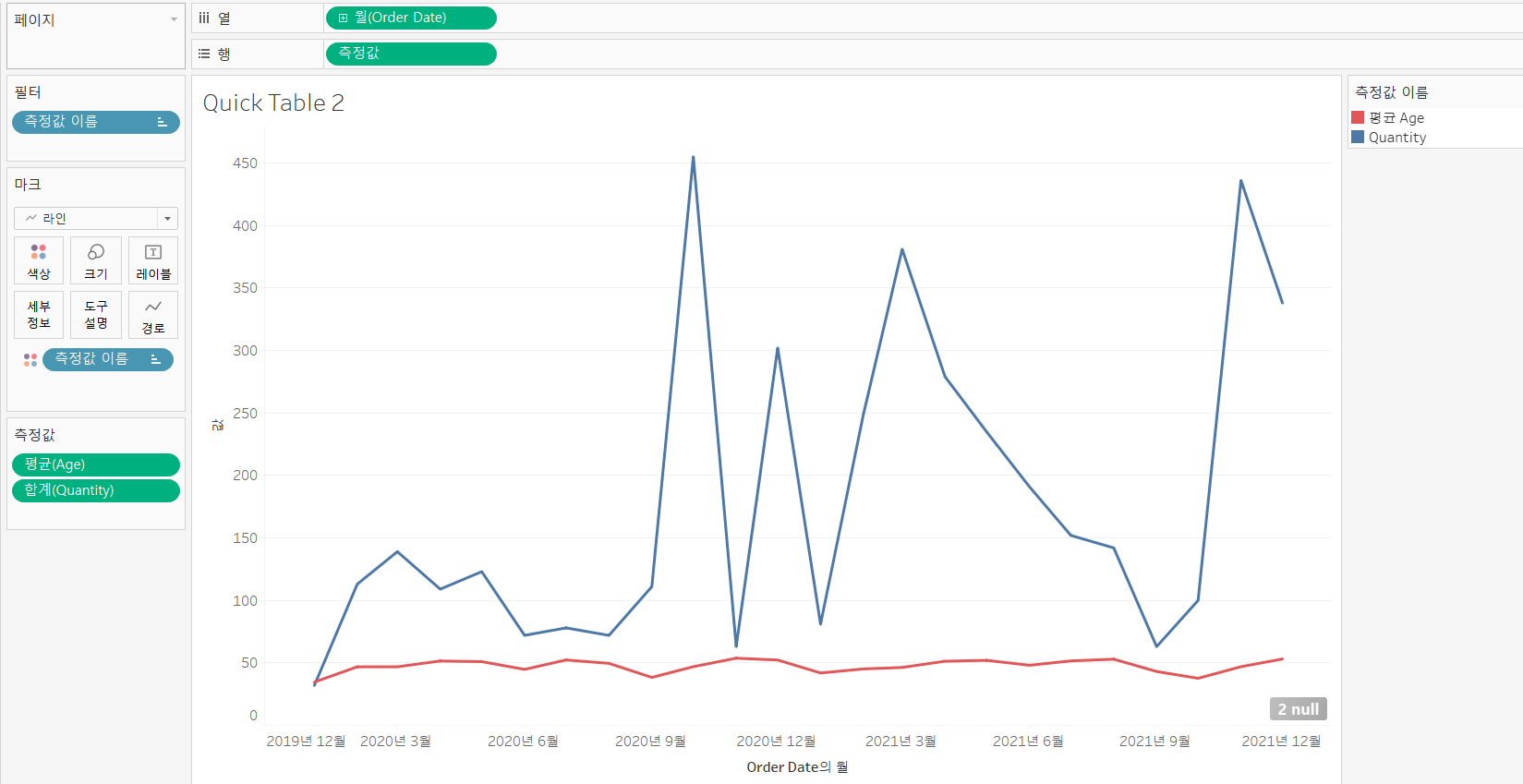
개별 축
- 측정 값 필드들을 개별의 축으로 뷰에 표시
- 각각 표시
- 마크 카드 유형을 라인으로
- 열에 Order Date 배치하고 연속형 년월로 변경
- 행에 Qunatity와 Age를 각각 배치하고 Age의 측정 값을 평균으로 변경
단일 축
- 측정 값 필드들을 하나의 뷰에 표시
- 선반에 측정 값을 배치할 때, 축에 겹쳐 놓으면 됩니다.
- 하나의 축을 가지고 2개의 필드를 출력
- 축에 겹쳐 놓으면 단일 축을 사용하면서 두 개의 그래프를 합쳐 볼 수 있다.
이중 축
- 축이 2개입니다.
- 왼쪽과 오른쪽에 축이 생성됩니다.
- 단일 축이 아닙니다. 축이 양쪽에 있습니다.
- 이중 축에서도
[축 동기화]를 해줄 수 있습니다. 하지만, 값의 크기를 확인하고 동기화를 해 줘야 할 지 확인해야 합니다.
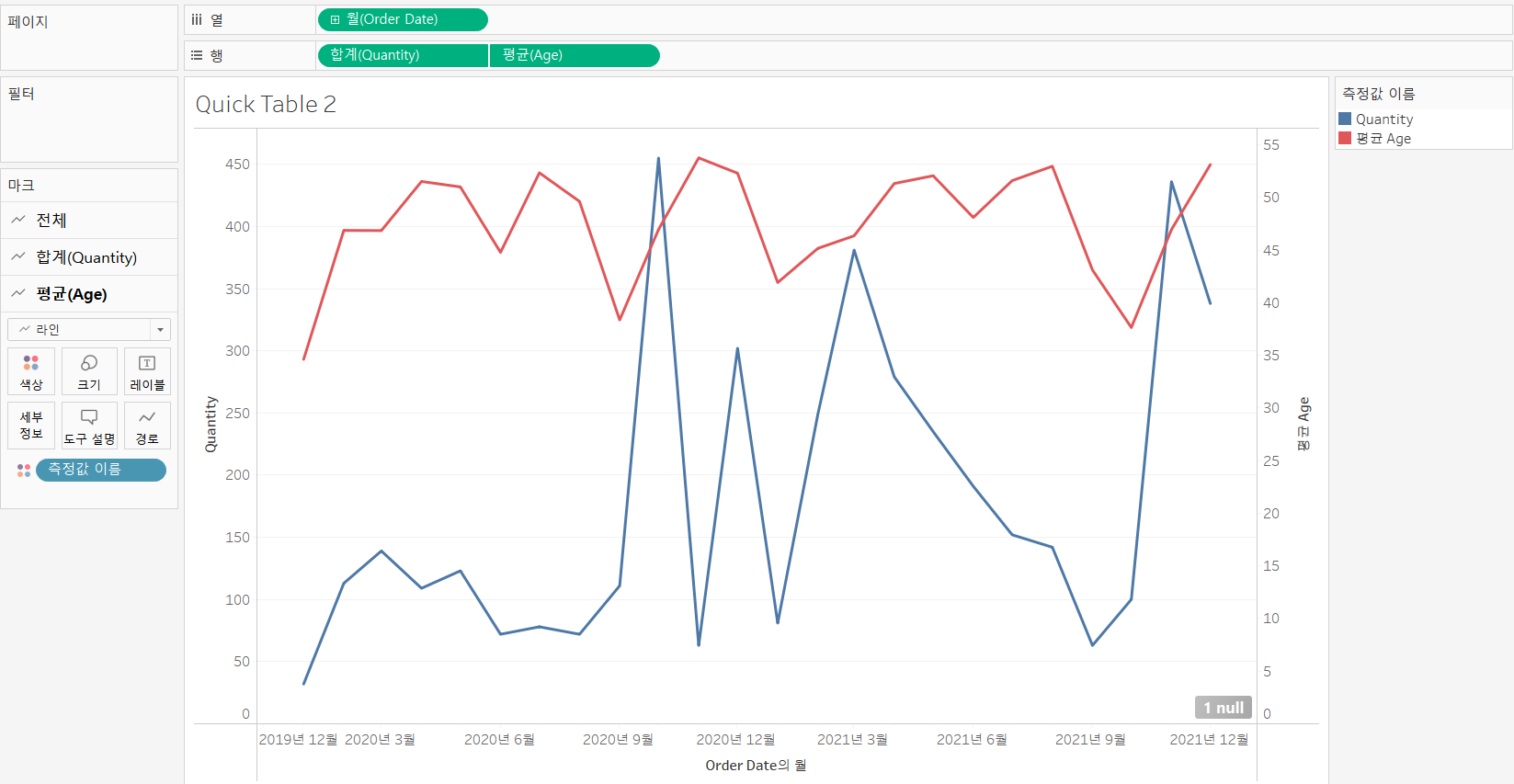
⚠ 2개의 필드를 하나의 그래프에 표현하고자 할 때, 2개의 필드 값이 유사한 경우에는 단일 축을 사용해도 되지만, 그렇지 않은 경우는 이중축을 사용해야 합니다.
- 위의 예시를 본다면, 이중 축으로 보게 된다면, Age(평균)의 변화도 확실하게 볼 수 있다는 장점이 있습니다.
- 단일 축으로 봤다면, Age(평균)의 변화를 확인하기 어렵다는 단점이 있습니다.
- 두 개의 추세를 비교하고자 하는 경우에는 반드시 이중 축을 사용해야 합니다.
- 데이터 편집이 가능하다면, 표준화나 정규화를 수행해서 비교를 해야 합니다.
- 정규화 : 범위를 줄임 (깎아 만듦, scailing)
- 표준화 : 값의 편차를 줄임
✔ 기본 함수
숫자 함수
- ABS
- MAX/MIN
- ZN
- NULL 이면 0을 반환하고 그렇지 않으면 식 반환
-ZN([매출액]): 매출액이 NULL이면 0 아니면 매출액
- 프로그래밍 언어는 대부분의 경우 NULL과 연산하면 예외 발생
- DB는 NULL과 연산하면 NULL을 제외하거나 연산 결과를 NULL로 리턴
- DB에서 평균 구할 때,SUM(컬럼이름)/COUNT(*)로 하는 것은 잘못된 결과를 가져올 수 있습니다.- ROUND
- 소수가 나오는 경우, 적절한 위치에서 반올림을 해주어야 합니다.
문자 함수
- LEFT/RIGHT
- 왼쪽이나 오른쪽에서 필요한 만큼 잘라내서 리턴하는 함수- LEN
- 문자 개수 리턴- LOWER/UPPER
- REPLACE
- CONTAINS
- SPLIT
날짜 관련 함수
- DATEADD
- 단위, 수치, 날짜를 매개변수로 받아서 날짜에 수치에 단위를 적용한 만큼 더해주는 함수
-DATEADD('MONTH',2,#2023-08-04): 2023-10-04- DATEDIFF
- 단위와 날짜 2개를 매개변수로 받아 2개 날짜의 차이를 구해줍니다.
- 쇼핑몰에서는 이 함수를 이용해서 주문 후 실제 배송받는데 걸리는 시간이나, 고객의 재구매 간격 등을 알고자 할 때 이용합니다.- DATENAME
- 단위와 날짜를 매개변수로 받아서 단위에 해당하는 부분을 문자열로 리턴- DATEPART
- 단위와 날짜를 매개변수로 받아서 단위에 해당하는 부분을 숫자로 리턴- YEAR, QUARTER, MONTH, WEEK, DAY
- 단위 없이 날짜만 매개변수로 받아서 해당하는 부분을 리턴합니다.- MAX, MIN 사용 가능
- 날짜 및 시간을 숫자로 간주하기 때문
- 추세선은 측정 값에만 사용할 수 있는데, 날짜 및 시간의 경우는 데이터를 읽어올 때는 차원으로 읽어오지만, 추세선에 사용이 가능합니다.
변환 함수
- DATE
- DATETIME
- FLOAT
- INT
- 소수 부분은 반올림하지 않고 버림- STR
논리 함수
- IF ~ ELSELIF ~ ELSE
- IFNULL(식1,식2)
- 식1이 NULL 아니면 식1, NULL이면 식2 return
집계 함수
- COUNT
- COUNTD
- 고유한 데이터의 건수- SUM
- AVG
- MAX/MIN
- STDEV
- VAR
- ATTR
- 데이터가 1개의 값인지 여부를 리턴
테이블 계산 함수
- INDEX
- 인덱스 리턴- RANK
- 동일한 값은 동일한 순위로 return, 동일순위 있을 때, 다음 순위 건너뜀- RANK_DENSE
- 동일한 값은 동일한 순위로 return, 동일순위 있을 때, 다음 순위 건너뜀X- RANK_MODIFIED
- 동일한 값은 동순위를 리턴할 때, 낮은 순위를 부여- RANK_UNIQUE
- 동일한 순위를 만들지 않음- RUNNING_AVG
- 누적 평균- RUNNING_SUM
- 누적 합계- RUNNING_MAX/MIN
- RUNNING_COUNT
- TOTAL
- 전체 합계 (SUM은 근복적으로 그룹 별 합계임)
실습하기
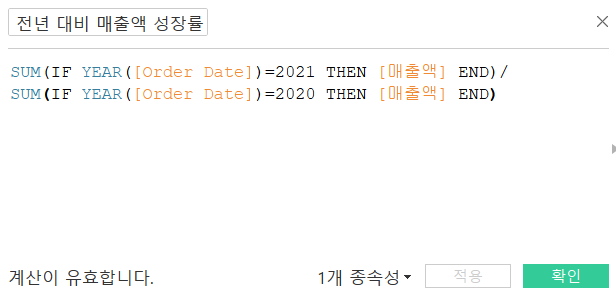
- 전년 대비 매출액 성장률을 구해보자.(21년 / 20년으로 설정)
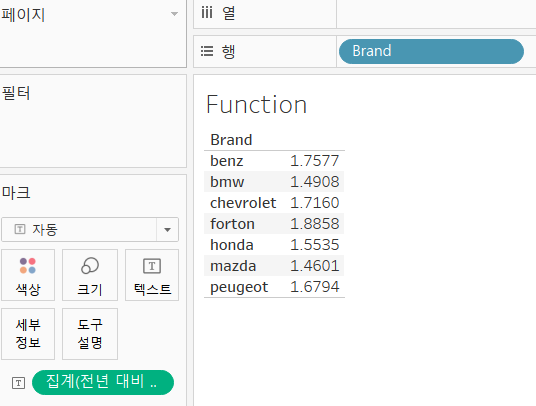
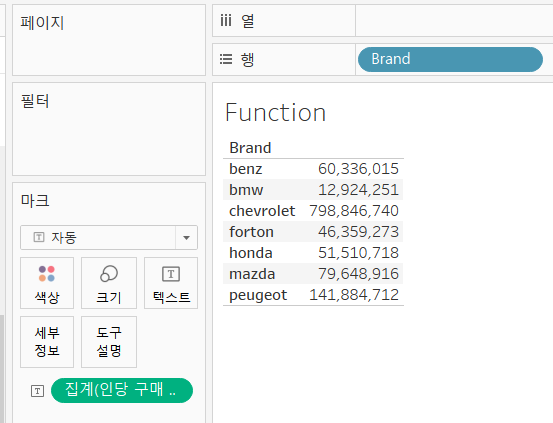
- Brand별 인당 구매 금액 알아보기
- 인당 평균 구매 금액을 알아보기 위해서AVG([구매금액])를 사용하면, 이 결과는 하나의 거래당 구매금액의 평균SUM([구매금액])/COUNTD([회원번호])
- 이 시트에서 인당 구매 금액 :SUM([매출액])/COUNTD([Mem No])
- 행에 Brand를 배치하고 인당 구매 금액을 마크 카드의 텍스트에 배치
- 모델 별 매출액 순위
- 매출액은 RANK를 사용
-RANK_UNIQUE(SUM([매출액]))
LOD 함수
종류
- Fixed
- 지정된 차원을 기준으로 집계
-{Fixed[Brand]:SUM([매출액])}- Include
- 지정된 차원 + 뷰 차원 기준 측정값 집계- Exclude
- 지정된 차원이 뷰에 존재하는 경우는 제외하고 측정값 집계
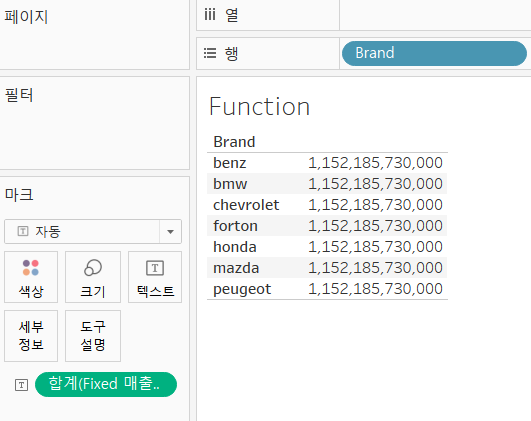
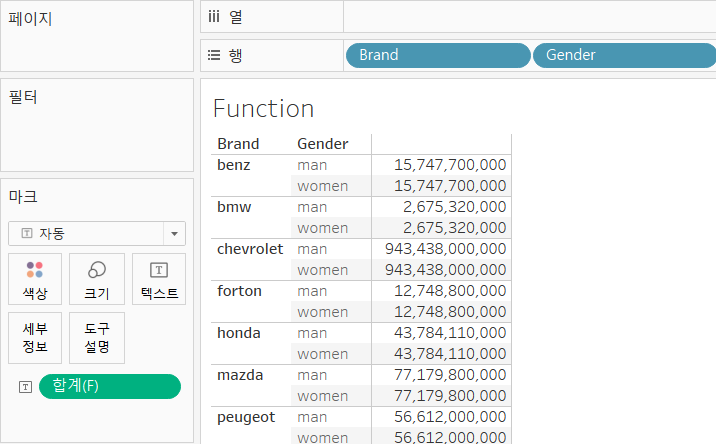
Fixed
- 계산된 필드를 만드는 것이다.
- Fixed 매출액 합계를 얻어보자.
-{Fixed:SUM([매출액])}
- 다 똑같네...?
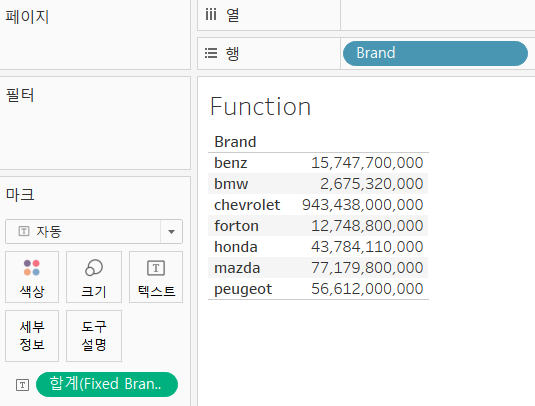
- 브랜드 별 매출액 합계를 구하고자 한다면,
{Fixed[Brand]:SUM([매출액])}이렇게 써야 한다.
- 이제 나온다.
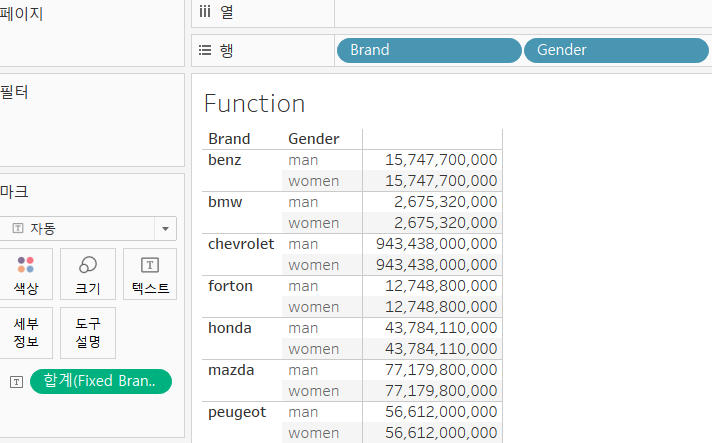
- 그런데 여기서 행에 Gender를 넣어도 그에 맞게 분류가 되는건 아니다.
- Fixed는 자신의 수식의 포함된 경우만 그룹 별 집계를 수행합니다.
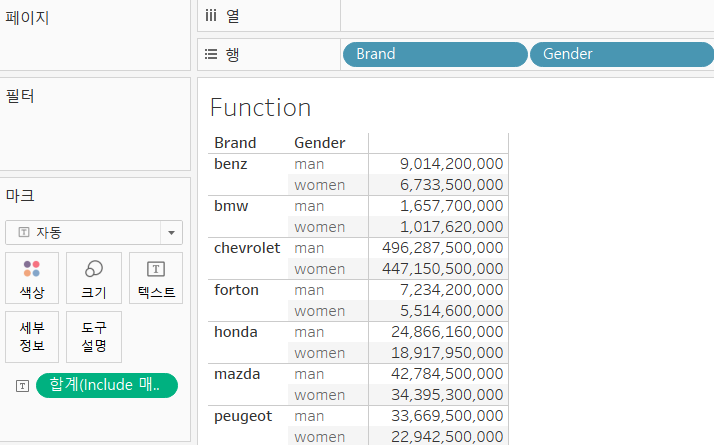
Include
- 계산된 필드를 생성
Include 매출액 합계 Mem No{INCLUDE [Mem No]:SUM([매출액])}- 행에 Brand 필드 배치
- 계산된 필드를 마크 카드 텍스트에 배치
- 행에 배치한 Brand 별로 합계가 만들어 집니다.
- Fixed는 Brand가 행이나 열에 Brand가 있더라도 적용하지 않음
- 계산된 필드의 측정 값을 평균으로 수정하고, 매출액의 평균을 출력해보면 2개는 다르게 나올 수 있습니다.
- 계산된 필드의 평균은 Mem No 별로 매출액의 합계를 구하고, 그 평균을 구한 것
- 매출액의 평균은 전체 데이터의 평균입니다.
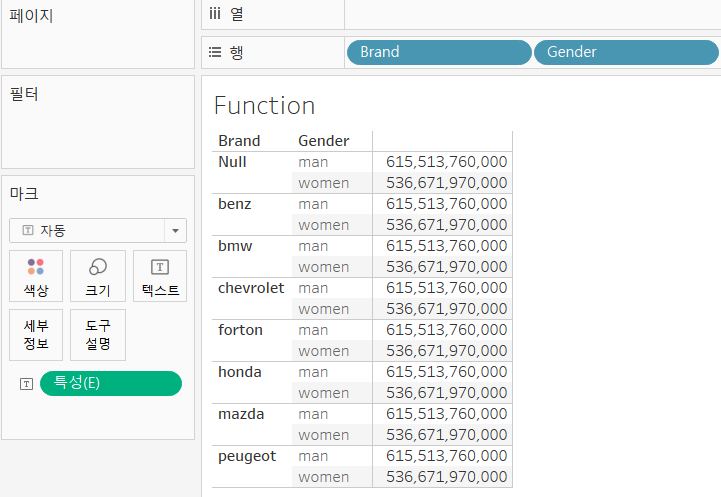
Exclude
- 뷰에 차원이 있는 경우, 집계에서 제외
- 사용 방법은 Include와 동일합니다.
- 왜 이 함수를 사용할까?
- 여러 집계를 하다보면, 이미 행이나 열 선반에 추가되어 집계가 이루어져 있는데, 계산된 필드에서 다시 계산하는 경우가 생기기 때문이다.
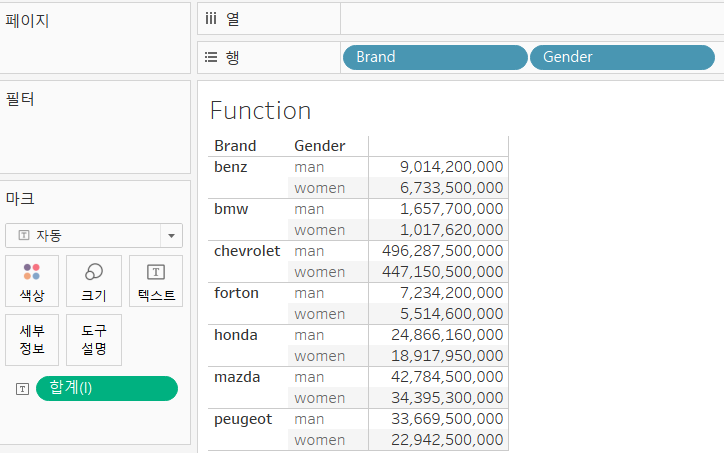
3가지 함수 차이
- Fixed를 위한 필드 생성 :
{FIXED[Brand]:SUM([매출액])} - Include 위한 필드 생성 :
{INCLUDE[Brand]:SUM([매출액])} - Exclude를 위한 필드 생성 :
{EXCLUDE[Brand]:SUM([매출액])}
- Fixed는 Brand로만 집계를 수행
- Exclude는 Brand를 제거하고 Gender로만 집계
- Include는 자신에게 없는 Gender로도 집계를 수행
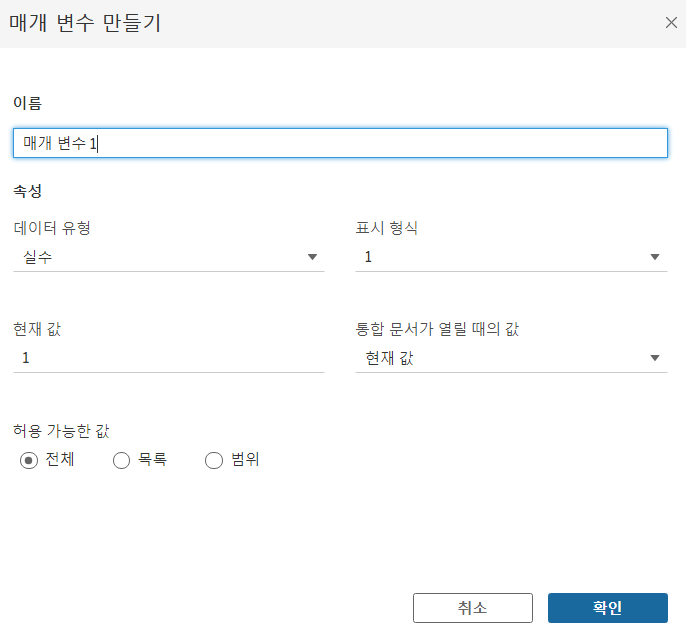
✔ 매개변수
- 뷰를 동적으로 제어하기 위해서 사용하는 Tableau의 기능
- 특정 조건에 맞는 데이터만 화면에 출력하기 위한 기능으로 필터가 있고, 매개변수가 있습니다.
- 필터는 계산을 수행하지는 않고 제공되는 기능을 이용하는 것이고, 매개변수는 하나를 만들어두고 여러 필드에서 사용이 가능합니다.
사용법
- 필터링 하고자 하는 조건에 맞는 자료형으로 매개변수를 생성
- 계산된 필드를 생성해서 매개변수를 활용할 수 있는 수식을 작성
- 이 수식에서는 Y나 N을 리턴하도록 작성
- Y가 리턴되는 경우는 출력 가능한 경우
- N이 리턴되는 경우는 출력 불가능 상태로 판단함 - 날짜의 범위 또는 특정 날짜보다 크거나 작거나 하는 조건에 일치하는 데이터를 찾고자 하는 경우는 날짜 형태로 2개의 매개변수를 생성
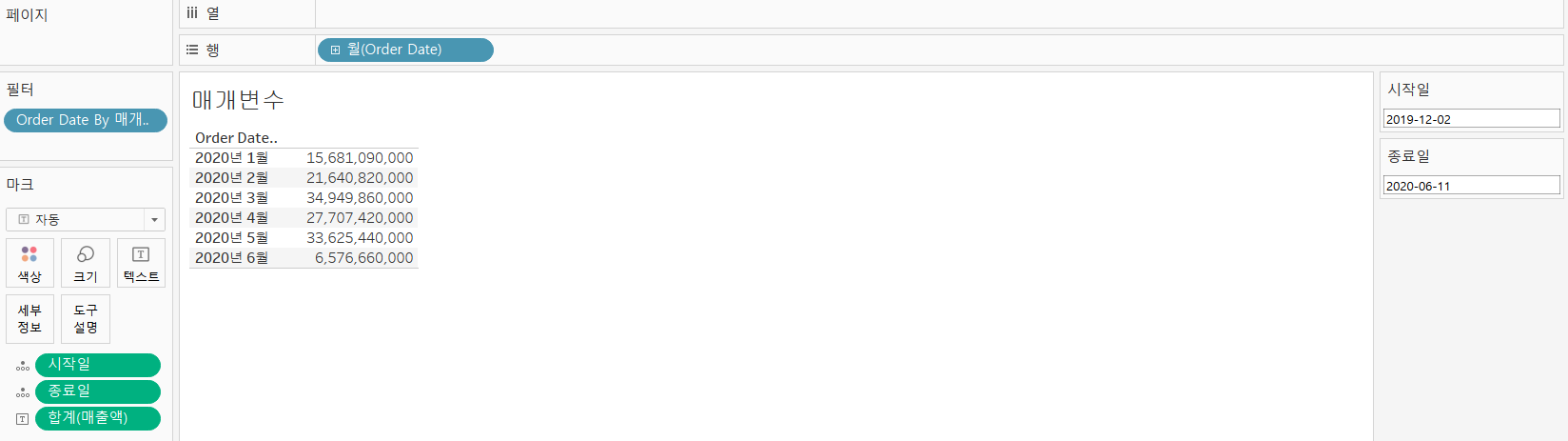
- 매개변수를 활용한 Order_date 필터링
- 날짜 형식을 갖는 시작일과 종료일 매개변수 생성
- 매개변수는 단독으로 사용될 수 없으므로 계산된 필드를 생성
- 계산된 필드를 필터에 배치하고 Y 클릭
- 행에 Order Date 배치하고, 연월 불연속형 설정
IF [Order Date]>=[시작일] AND [Order Date]<=[종료일] THEN 'Y' ELSE 'N' END
- 시작 종료일을 조절하면서 확인 가능해짐
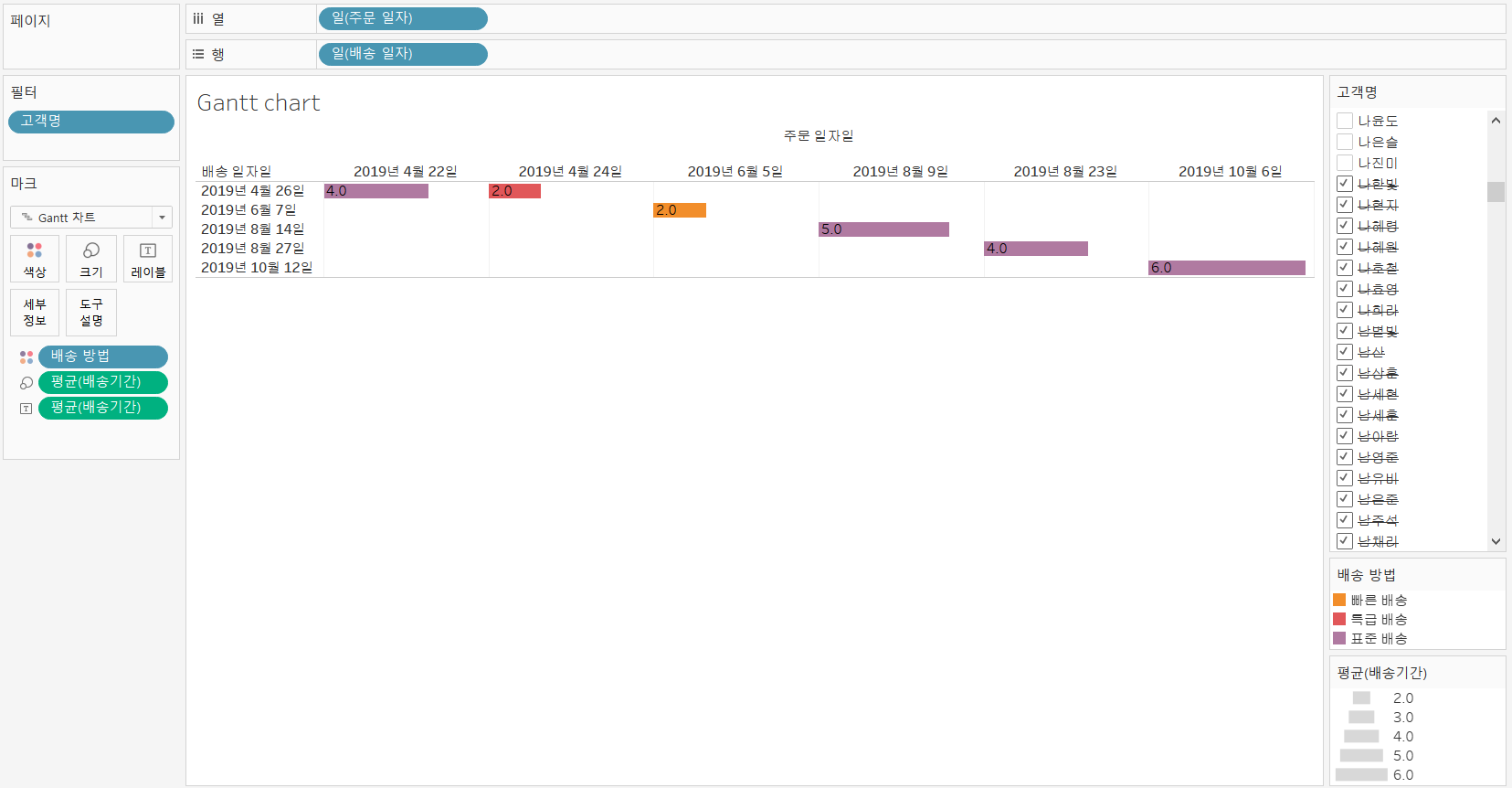
✔ Gantt Chart
개요
-
시간의 경과 또는 어떤 활동에 대한 기간을 표시하는데 적합
-
프로젝트 매니저가 프로젝트의 수행 기간을 예측하거나 표시하고자 할 때 사용
- 예측을 할 때는 최적의 시간과 최악의 시간을 같이 고려하기 때문에 막대가 겹쳐서 적용됩니다. -
Gantt Chart를 만들 때는 2개의 날짜 데이터가 있어야 합니다.
(시작과 끝) -
이 차트를 이용해서 배송 기간이나 재구매 기간 들을 표시할 수 있습니다.
-
간식패턴 -> 쿠팡 자동주문하는 프로젝트? <- 커머스 관련 프로젝트로 할만해요
실습 - 배송 기간을 간트 차트로 표현해보자.
- superstore_2019.xlsx
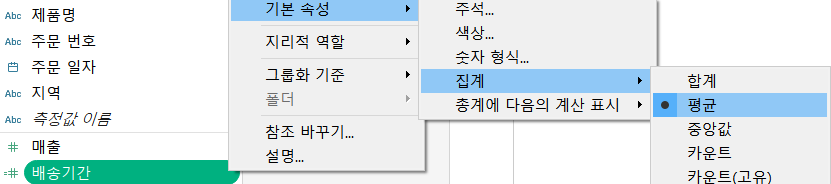
- 주문 일자와 배송 일자의 차이를 갖는 배송 기간이라는 필드 생성
- 계산된 필드 :
DATEDIFF('day', [주문 일자], [배송 일자])- 배송 기간의 집계 방식을 평균으로 수정
- 배송 기간을 선택 추가메뉴 기본속성 집계 평균 선택
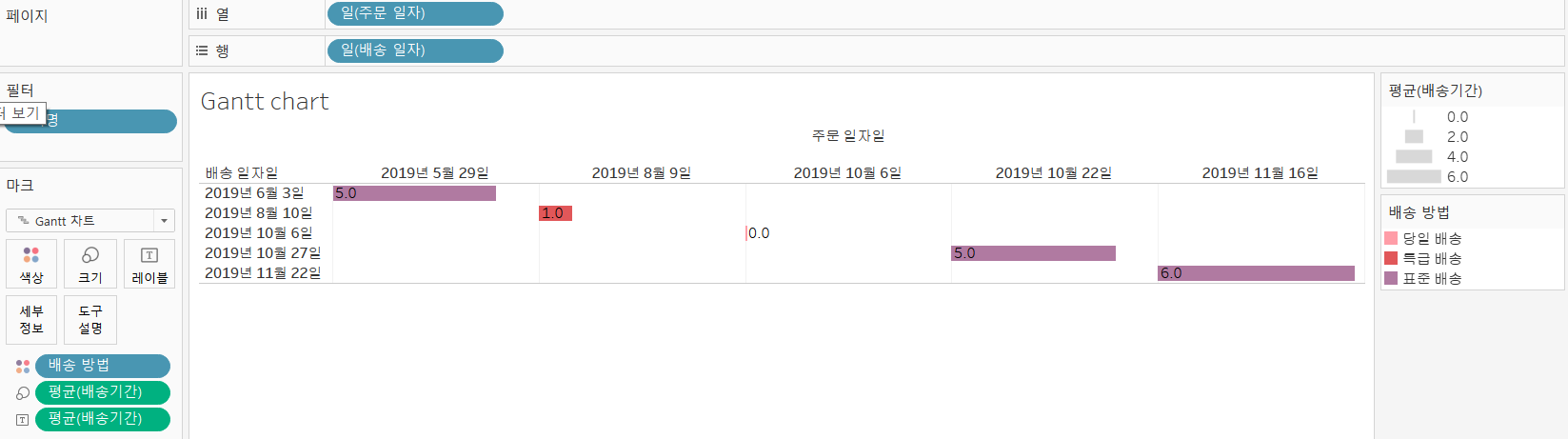
- 주문 일자를 열 선반에 배치하고 일
(YYYY-MM-DD)을 선택하고, 불연속형으로 수정- 배송 일자를 열 선반에 배치하고 일
(YYYY-MM-DD)을 선택하고, 불연속형으로 수정- 고객명을 필터 선반에 배치하고, 첫 번째 데이터만 화면에 표시
- 마크선반 유형 간트차트 설정
- 배송기간을 마크선반의 크기, 레이블에 배치
- 배송 방법 필드를 마크의 색상에 배치
- 현재는 한 고객만 봤다, 필터를 다시 해보자. 필터선반에서 걸어둔거 우클릭 필터표시하면 우측에 필터가 나온다.
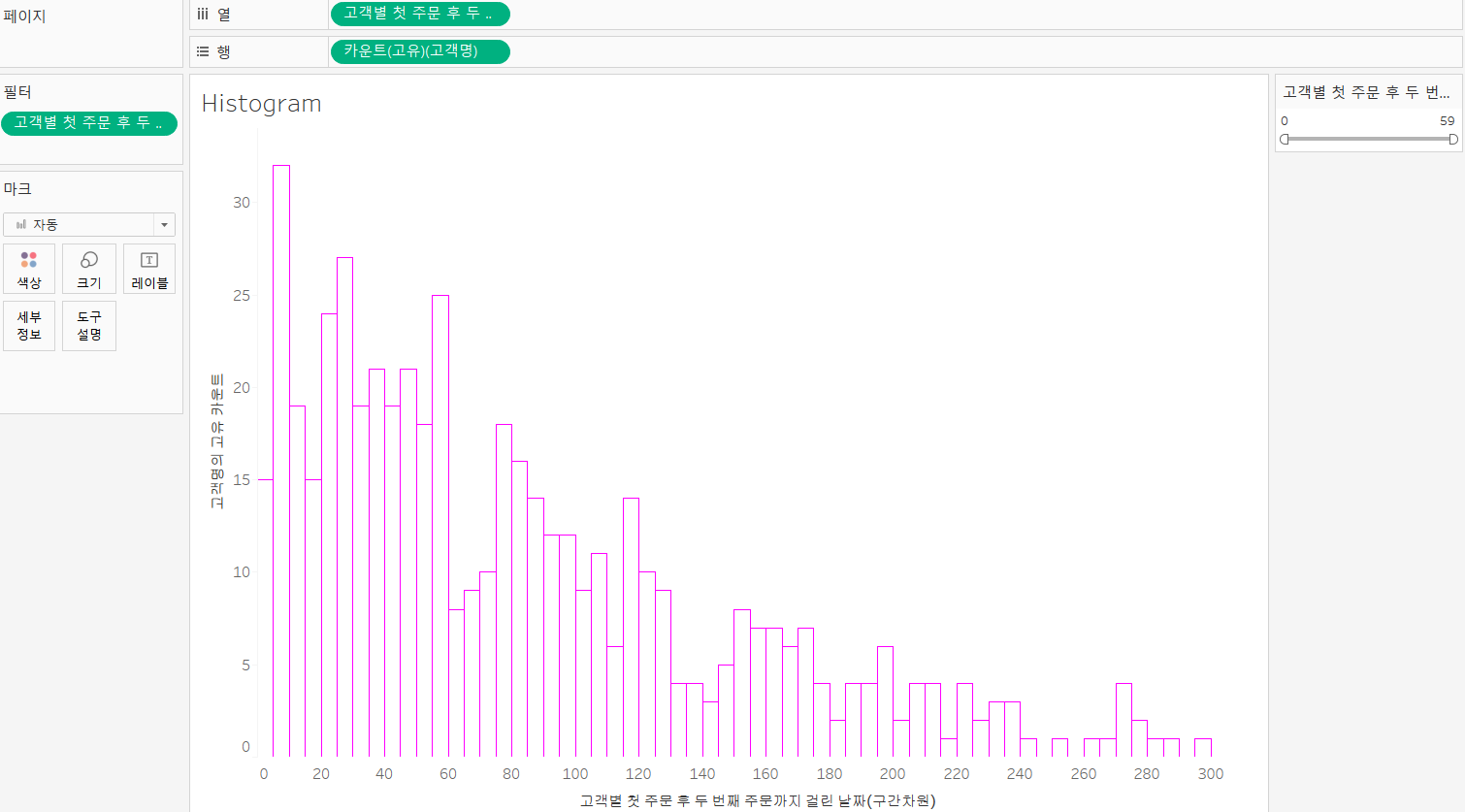
✔ Histogram
개요
- 횟수를 막대 그래프로 표현한 차트
- 재구매 이력을 이용해서 고객 세분화 분석에 이용하는 것이 가능함
고객의 재구매 이력 히스토그램
- 고객 별 첫 주문일자를 조회하기 위한 필드
-{FIXED [고객명] : MIN([주문 일자])}날짜는 DB에선 숫자 취급하니 가능함- 고객 별 재주문 일자를 조회하기 위한 필드
-IIF([주문 일자]>[고객별 첫 주문 일자], [주문 일자], NULL)- 고객 별 두번째 주문 일자를 조회하기 위한 필드
-{FIXED [고객명] : MIN([고객별 재주문 일자])}- 첫 주문과 두번째 주문까지 걸린 기간
-DATEDIFF('day', [고객별 첫 주문 일자], [고객별 두 번째 주문 일자])- 고객별 첫 주문 후 두 번째 주문까지 걸린 날짜 필드에 구간 적용
- binning
- 일정한 간격을 갖도록 만드는 것
- 만들기 구간차원, 10으로 설정해주자.
- 고객별 첫 주문 후 두 번째 주문까지 걸린 날짜 필드에 구간 적용 필드를 연속형으로 변환후 열선반에 배치
- 고객명을 행 선반에 뱇, 측정 값을 카운트(고유) 적용
- 우측하단 1null은 구매한 적은 있으나, 재구매는 하지 않은 고객임
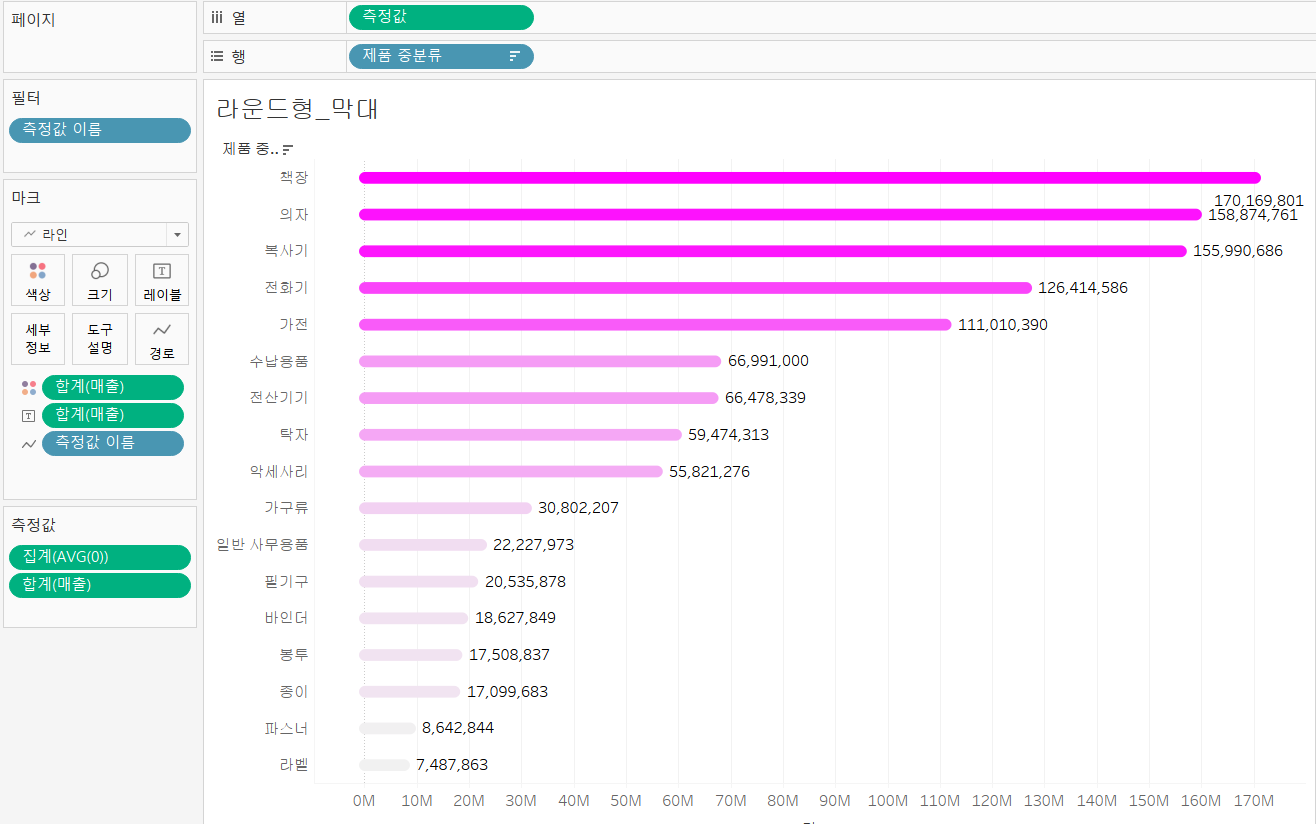
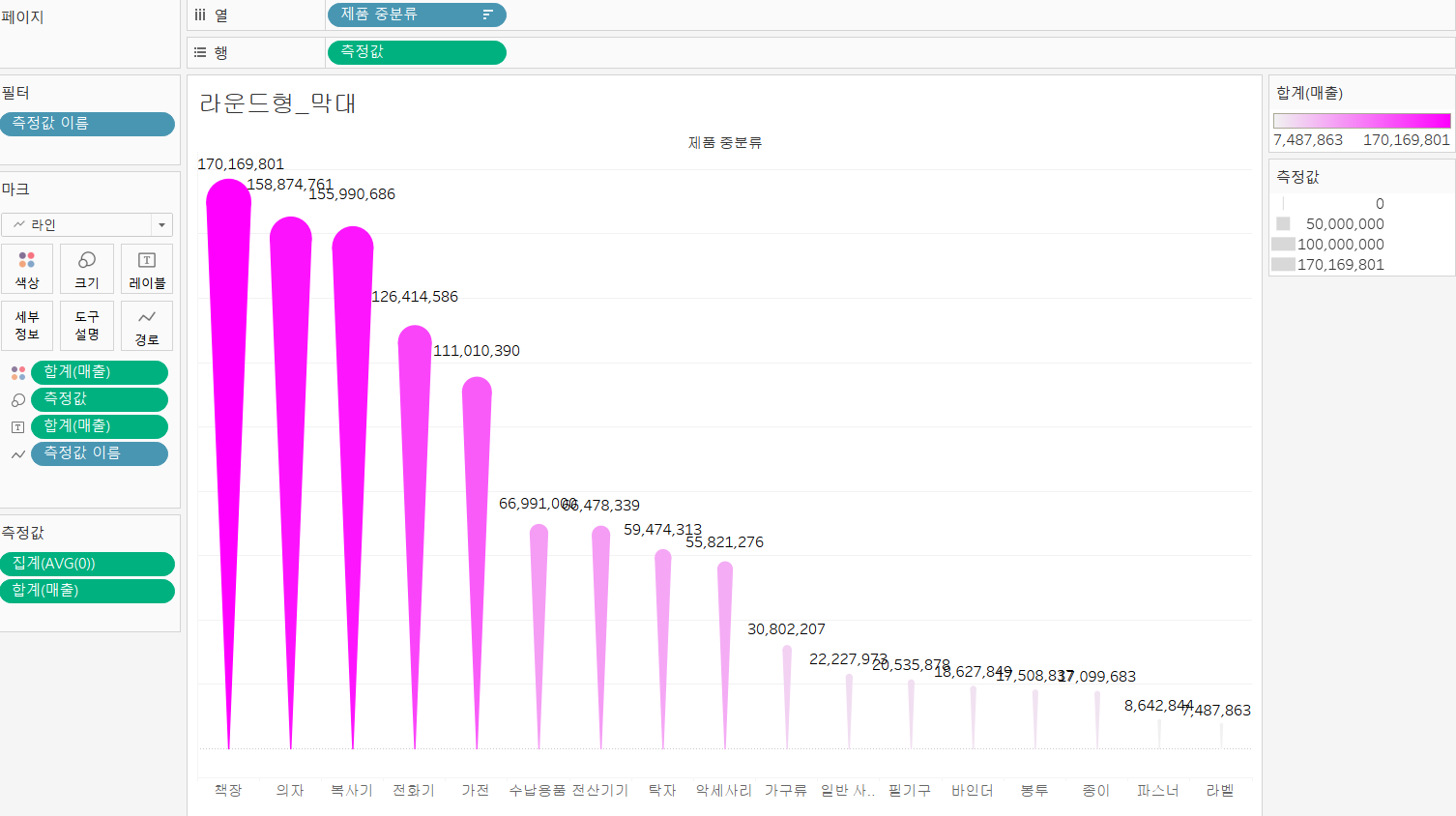
✔ 라운드 형 막대
- 매출 필드를 열 선반 배치
- 열 선반을 더블클릭해서
임시계산으로AVG(0)을 입력- 2개의 열을 단일축으로 만들기 위해 AVG(0)을 뷰 영역으로 드래그 해서 =모양이 보이면 드랍하기
- 마크 유형을 라인으로 변경
- 행 선반에 있는 측정값 이름을 마크에 있는 경로 위로 올리자.
- 마크카드의 크기로 차트 크기를 크게 키우자.
- 하나로 되어있는 선을 나누기 위해서 [제품 중 분류] 필드를 행선반에 올려보자.
- 데이터 정렬을 위해 행 선반에 있는 제품 중 분류 필드를 선택 후 우클릭하고 정렬, 내림차순, 정렬기준 필드, 필드명 선택
- 막대에 값을 표시하기 위해서 매출 필드를 레이블에 올리기,
- 2개가 나오는데?
- 당연히 2개를 합쳤으니까
- 양쪽에 출력된 레이블을 마크카드 레이블에서 설정 변경
- 툴 바에 있는 행과 열 바꾸기가 존재함. 차트 방향 반전도 가능함
- 행 선반에 있는 측정값을 ctrl 누른 채 마크카드 크기에 배치하면 라운드형 막대 완성!
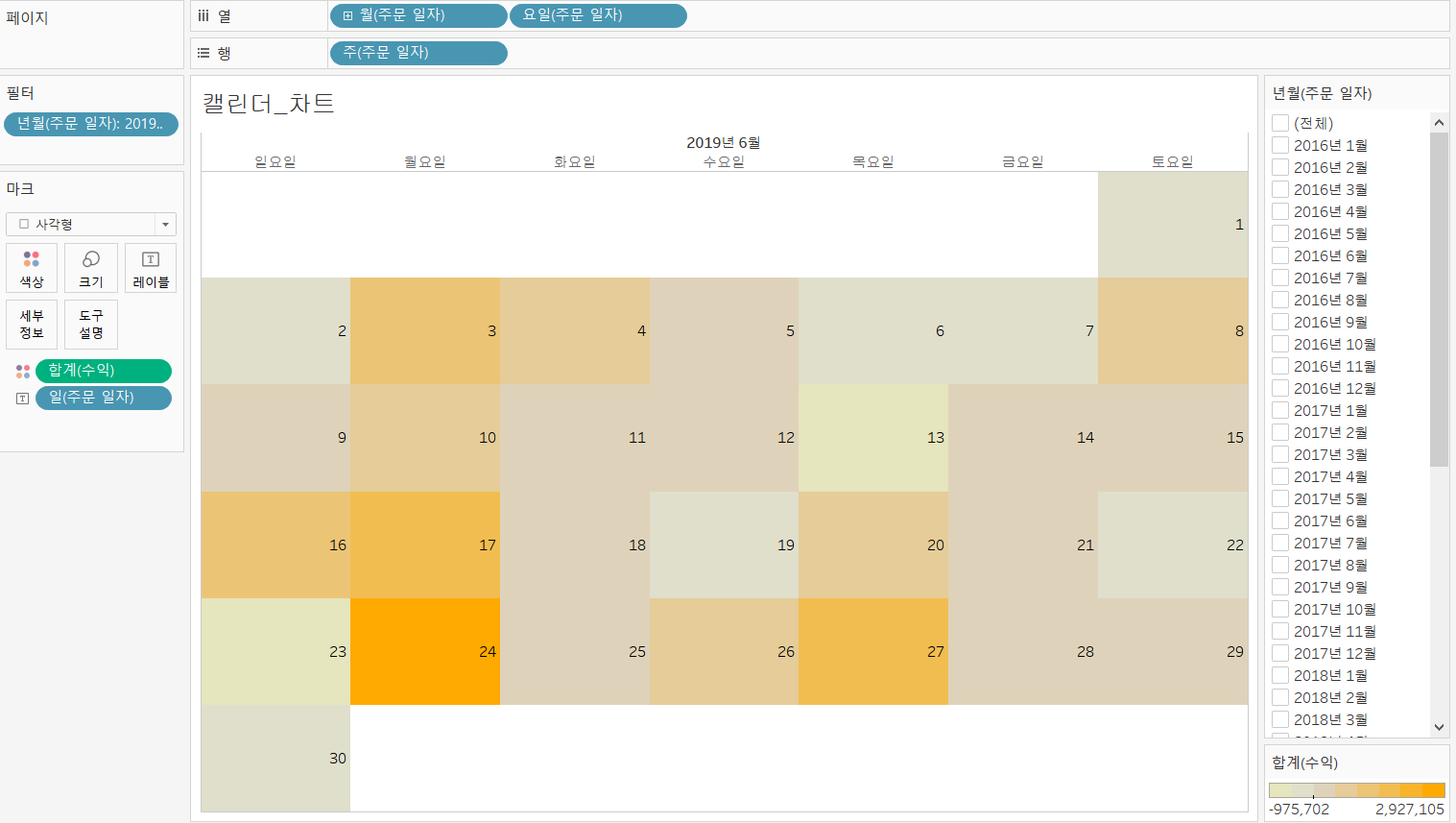
✔ 캘린더 차트
개요
- 캘린더 차트는 없는 날짜를 열과 행에 배치해서 서식을 변경해 캘린더처럼 생성
- 캘린더 차트를 이용하게 된다면, 월 단위 내의 날짜 별 또는 요일 별 패턴을 찾을 수 있습니다.
- 시간이나 날짜 별 패턴을 양 방향으로 적용해서 찾을 때는 HeatMap을 많이 이용
- HeatMap은 직사각형 형태로만 생성가능
- 날짜 별로 패턴을 찾고자 할 때는 다양한 방법으로 시각화를 해봐야 합니다.
캘린더 형태로 데이터를 출력
- 열 선반에 주문 일자를 2개 배치
- 첫 주문 일자는 불연속형 연월
- 두 번째 주문 일자는 불연속형 요일로 설정
- 행 선반에 주문일자를 배치하고 불연속형 주 번호 선택
- 주문 일자를 마크카드 텍스트에 배치 후 불연속형 일 선택
- 현재는 주문이 없는 경우에는 표시가 안됩니다.
- 주문 일자를 필터에 배치하고 특정 연도 월만 보면 될 것 같다.- 마크 카드의 유형을 사각형으로 변경
- [수익] 필드를 색상 마크에 배치
- 필드 레이블을 숨기거나 머리글 안보기에 하면 좀 더 깔끔해진다.
- 월부터 하고싶으면 데이터 날짜 속성을 주시작을 월요일부터 하면됩니다.
✔ 도넛 차트
- 파이차트에 구멍 뚫린 것 처럼 생김
- 파이차트 2개 합치면 됩니다.
- 안쪽을 흰색으로 하고, 추가 정보를 해당 부분에 넣으면 됩니다.
- 비교 카테고리가 너무 많으면 효율적인 차트는 아니다.
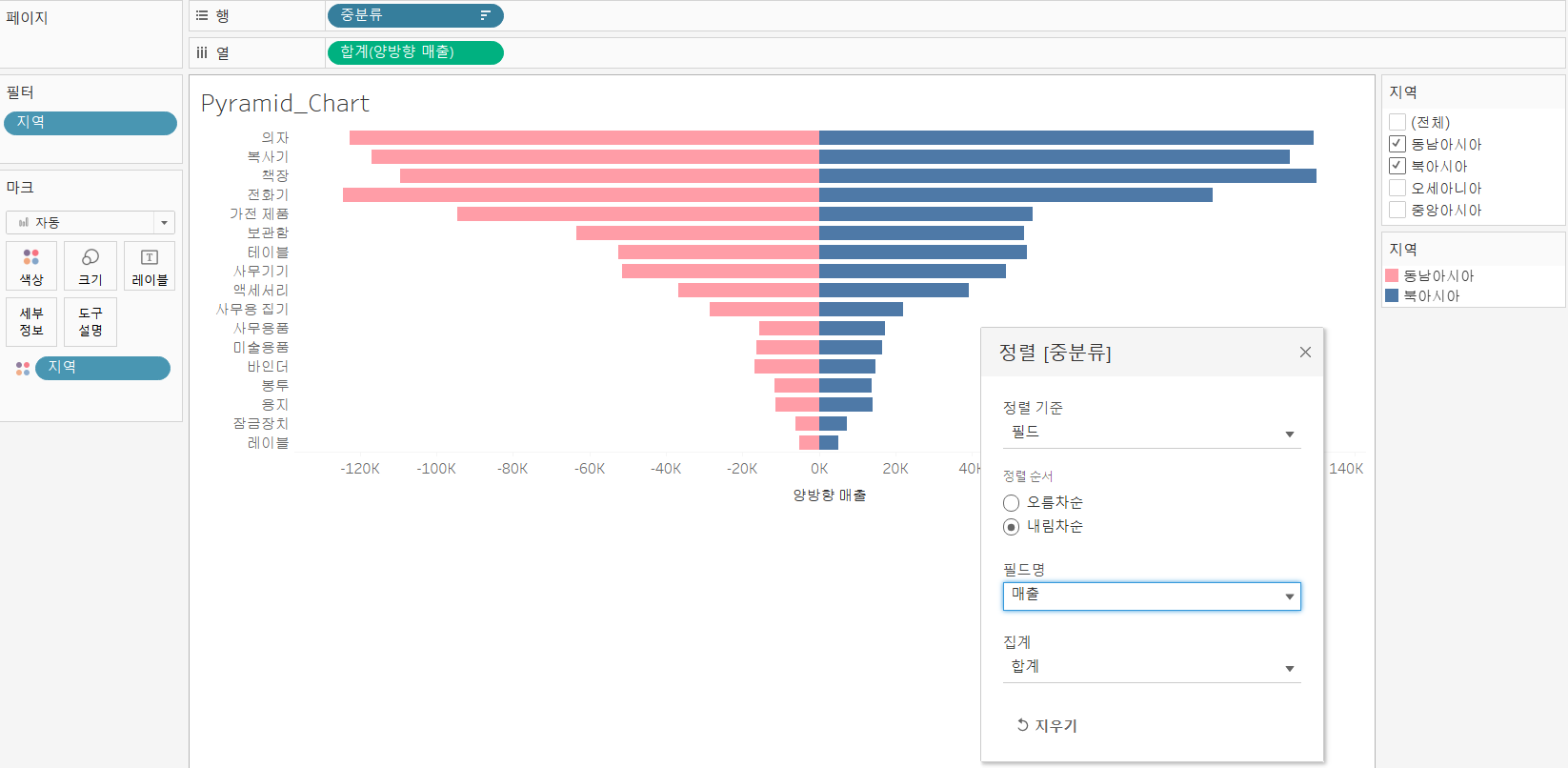
✔ Pyramid Bar & Diverging Chart
- 축이 왼쪽이면 피라미드 가운데면 양방향 차트
데이터
- 슈퍼스토어 샘플 파일의 주문 시트(old)
필터링
- 동남아시아와 북아시아 데이터만 이용하기 위한 필터링
- 지역 필드를 필터 선반에 배치
양방향 차트를 만들기 위한 필드 생성
- 수식 :
IF[지역]='동남아시아' THEN [매출]*-1 ELSE [매출] END
필드 배치
- 양방향 매출을 열 선반에 배치
- 중분류를 행 선반에 배치
- 지역을 마크카드 색상에 배치
- 중분류 정렬을 때려주자
- 차트를 양방향으로 만들 때, 좌우의 값이 최대나 최소가 차이가 난다면, 차트가 한쪽으로 치우치기 때문에 값의 범위를 맞추어서 균형잡힌 형태로 만들기 위해 x축을 선택후 우클릭하고 [축 편집] 선택하고 [범위] 에서 고정을 선택하고
시작과종료값을 설정해주자.- 축에 값을 설정하면 그래프에 값을 표기를 하면 거추장스럽고, 그래프에 표기하면 축이 거추장스럽다.
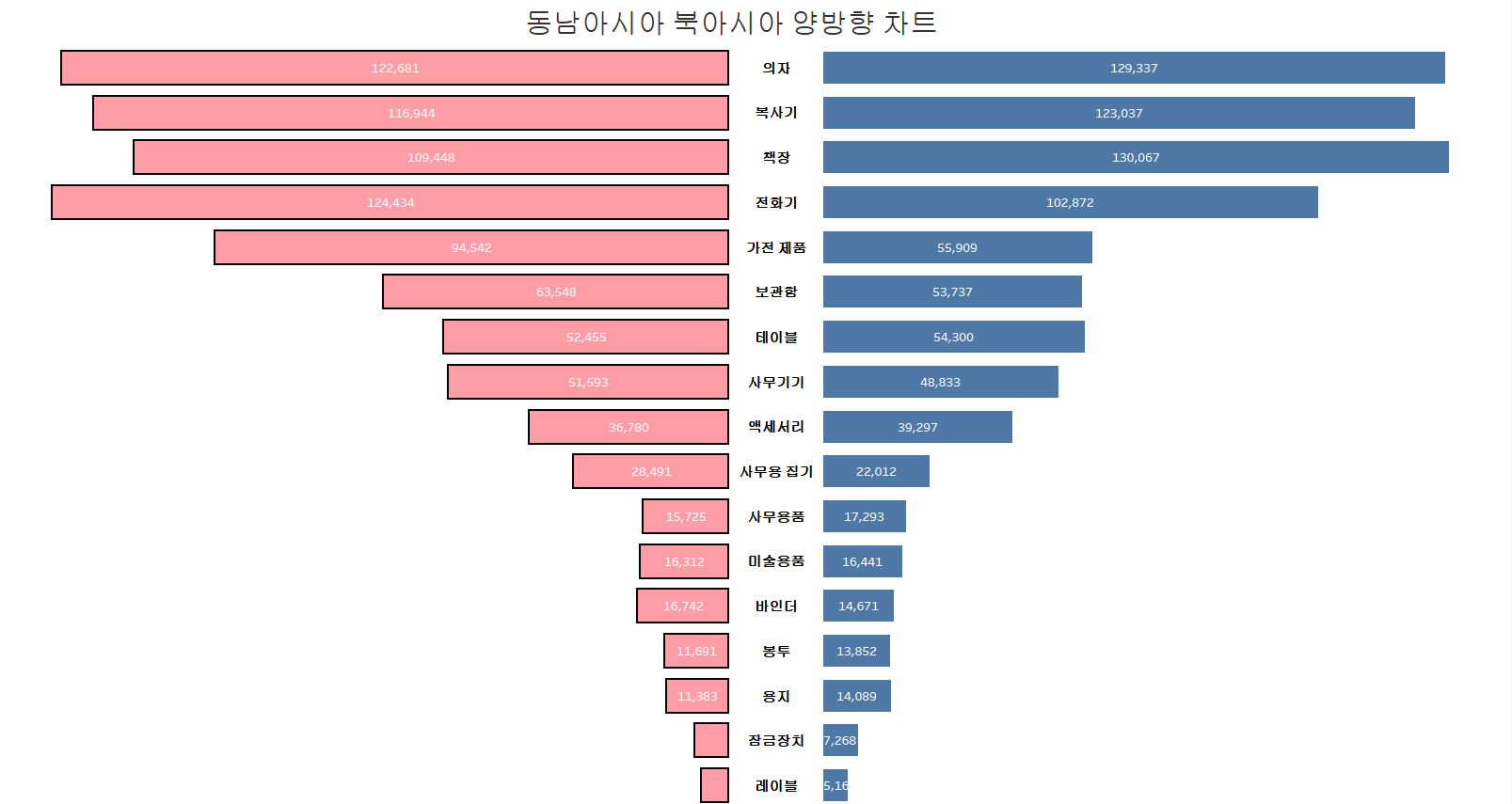
시트를 2개 복제하자(동남아시아랑 북아시아로 설정)
동남아시아 시트 작성
- 열 선반에 있는 합계(양방향 매출) 추가메뉴 머리글 표시 선택
- 우측을 없애기 위해서 x축 선택 우클릭 축편집 [범위] 고정 시작-140000, 끝은 0 이러면 우측 있던게 안보임
- x축과 y축을 선택 우클릭 머리글 표시 해제
- 이러면 데이터만 남음
북아시아 시트 작성
- 열 선반에 있는 합계(양방향 매출) 추가메뉴 머리글 표시 선택
- 우측을 없애기 위해서 x축 선택 우클릭 축편집 [범위] 고정 시작0, 끝은 140000 이러면 우측 있던게 안보임
- x축을 선택 우클릭 머리글 표시 해제
- 이러면 데이터랑 Y축만 남음, Y축 서식 가운데 정렬까지
대시보드 작업
- 대시보드는 여러 개의 뷰를 화면에 배치할 수 있는 개체
- 여러 시트들에 작업한 것을 하나의 화면으로 만들고자 할 때 이용합니다.
- 실제 보고서가 대시보드입니다. (시트 x)
- 대시보드는 기본적으로 세로 방향으로 개체를 배치하는데, 이를 가로 방향으로 하고자 한다면 왼쪽 하단의 개체에서 가로 컨테이너를 드래그해서 뷰에 배치
동남아시아 시트를 왼쪽, 북아시아 시트를 오른쪽에 드래그
- 북아시아 부분의 중분류 누르고 행에 대한 필드 숨기기 실행
- 레이아웃 작업 여백

밀가루 귀여워요