
✔ Heat Map Chart
개요
- 테이블 형식의 데이터를 색상으로 표현할 수 있는 차트
- 유사한 차트로 Tree Map은 각 셀의 크기로도 데이터의 차이를 표현 가능
- 차원을 2개를 사용하는데 2개의 차원의 연관성을 파악하거나 상위 차원과 하위 차원 형태로 배치를 세부항목을 보여주는 형태로 많이 사용합니다.
- 가끔은 색상이 수치보다 더 와닿을 수 있다.
- 수치나 경향보다는 색상의 차이가 시각적으로는 효과가 뛰어나기 떄문에 값의 차이가 큰 경우에 많이 사용합니다.
tree map은 2개의 차원, 2개의 측정 값 까지 가능함
상관?
- 2개 항목의 상호 관련성
- 2개의 패턴이 존재
- 양의 상관 관계 : ↗
- 음의 상관 관계 : ↖
- 상관 관계가 높다? : 라인의 형태로 나타남 - Heat Map 색상으로도 상관 관계를 파악할 수 있다.
예시
- 항공사의 계절성 파악
- x축 년도, y축 월
- 년도별, 월별 추세를 확인할 수 있다.
월 별 그리고 요일 별 매출액의 합계를 파악해보자.
초기 설정
- 사용하고자 하는 엑셀 파일을 tableau에 연결
- 사용하고자 하는 시트를 캔버스로 이동 : 주문 시트 사용(from 절 / SQL)
- 테이블 : 차원, 테이블 밑에 있는 것 : 측정 값
- 차원 : 분류를 위한 것, 측정값 : 진짜 그냥 측정 값임
시작
- 마크 선반에서 유형
사각형으로 변경- 주문 날짜를 열, 행 두 곳에 다 배치
- 열 선반에 배치한 주문 날짜를 불 연속형의 요일로 바꾸기
- 행 선반에 배치한 주문 날짜를 불 연속형의 월로 바꾸기

- 데이터가 안들어갔을 때의 형태이다.
- 이러면 년도는 의미가 없어진다.
- 출력할 측정 값(매출액)을 Heat Map으로 표현하기 위해서, 마크 선반의 색상으로 배치
- 정확한 값을 알고자 하는 경우에는 마크 선반의 레이블에도 배치를 해주면 값을 알 수 있다.
✔ 여러 시트 조인
- Tableau에서는 시트 간에 동일한 차원이 존재하는 경우에 조인이 가능
- 동일한 차원이 없더라도 강제로 조인을 할 수 있습니다.
- Union(여러 개의 구조가 같은 시트를 합치는 것)도 가능
- Join 과 Union은 다르다는 것을 알아두자.- 기준이 되는 시트를 먼저 배치하고, 다른 시트를 배치할 때 시트 위에 배치하면 Union이고, 오른쪽이나 왼쪽에 배치하면 Join입니다.
- Tableau의 특징을 여기서 알 수 있습니다. DB에서 먼저 Join을 할 필요가 없다는 점입니다. 굳이 처음부터 Join된 데이터를 쓸 필요가 없습니다.- Join을 할 때는 공통된 컬럼을 알아야 합니다.
- DB에서 JOIN을 할 때는 순서도 중요합니다.
from emp, dept where emp.deptno=dept.deptno from emp, dept where dept.deptno=emp.deptno
- 결과는 똑같지만 과정이 매우 다르며, 속도도 다릅니다.
전부 다 찾을지 아니면 한개 찾고 바로 끝내버릴지
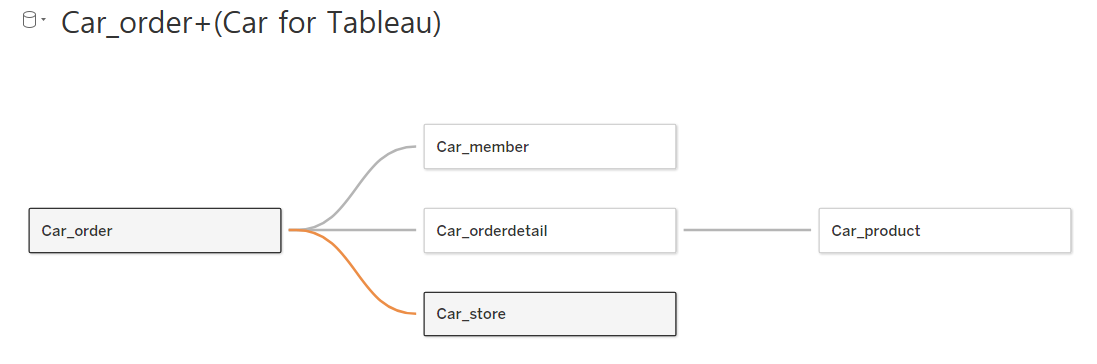
- Car_Order, Car_Member, Car_OrderDetail, Car_product, Car_store 순서로 연결
- Order에는 Member, OrderDetail, Store 조인
- OrderDetail에 Product 연결
✔ 필터
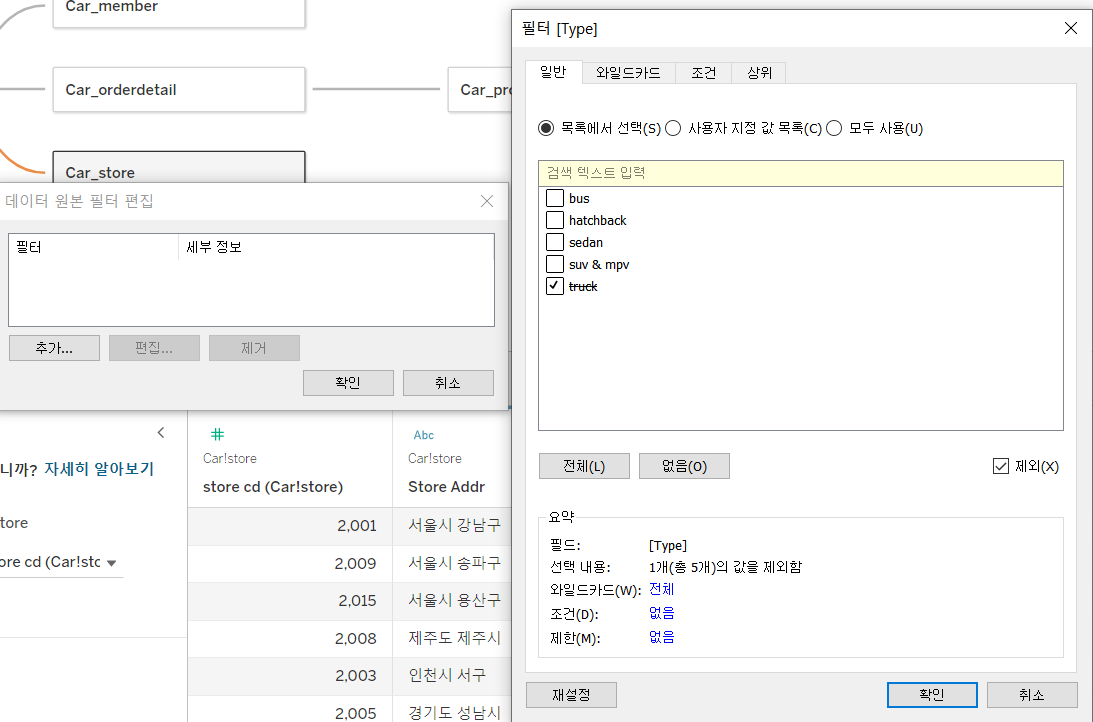
데이터 원본 필터
- 연결된 데이터 원본에 필터를 적용
- 데이터를 불러오는 단계에서 필터링이 되기 때문에 대용량 데이터를 불러올 때 활용합니다.
- 데이터 원본에서 Type에서 truck 제외
- 데이터 원본 화면의 오른쪽 상단의 필터의 추가를 클릭해 원하는 데이터만 추출
워크시트 페이지 및 필터
워크시트 페이지
- 필터 이동 및 재생을 위해 워크시트 뷰를 동적(애니메이션)으로 보이게 하는 기능
Type별 매출액을 이용한 막대 그래프 출력
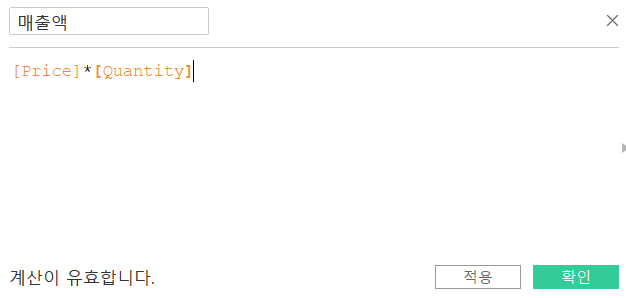
- 매출액은 존재하지 않는 측정값이다.
- 존재하지 않는 측정값은 계산된 필드를 이용해서 생성함
- 매출액은Price*Quantity로 생성
- 계산된 필드 - 파생 속성(Derived Attribute)
- 이러한 속성을 자주 사용하는 경우에는 컬럼으로 추가하는 것이 좋다.
- 이 기능은 자주 활용하는 기능인데, 대부분의 경우 RDBMS에서 데이터를 가져와서 사용하는데, RDBMS에서는 근본적으로 데이터의 중복이나 계산식으로 나오는 파생 컬럼을 만들지 않습니다.
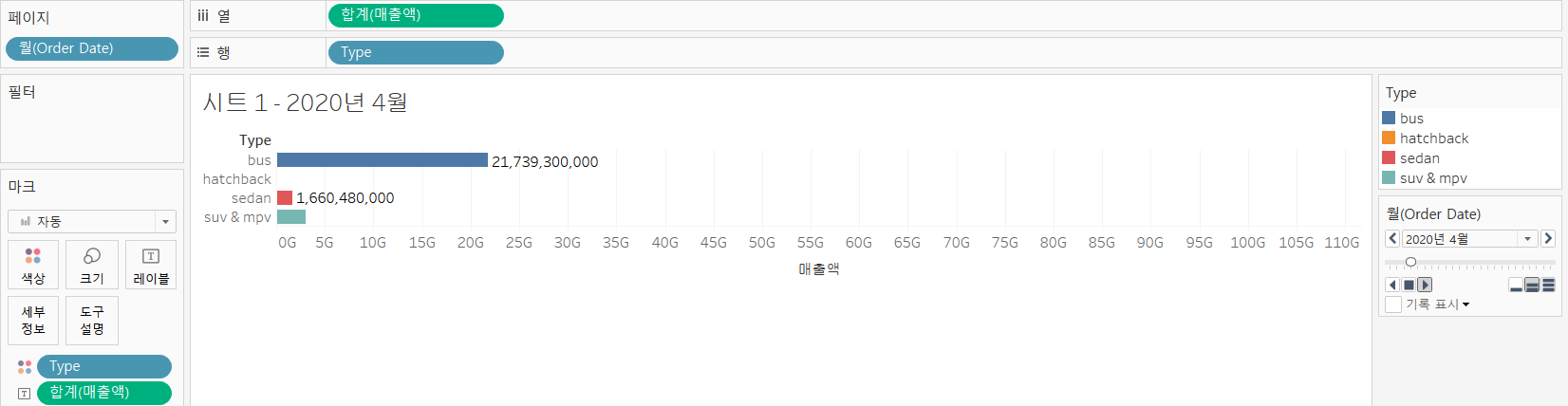
- 행과 열에 Type과 매출액 필드를 설정
- Type을 마크 선반의 색상으로 설정해 Type별로 색상을 다르게 보이도록 설정
- 매출액을 마크 선반의 레이블로 설정해서 매출액 값이 Canvas에 출력되도록 설정
- 애니메이션을 위해서 페이지에 Order Date를 드래그해서 설정하고 데이터의 형식을
yyyy년 m월로 설정
워크시트 필터
- 차원 또는 측정값 필드를 이용해서 워크시트 뷰를 필터링하는 기능
- 필터링해서 출력하는 것이지 데이터를 필터링하는 것이 아님
워크시트 필터 실습 - 모델별 매출액 막대 차트 생성
- 행과 열에 Model과 매출액을 배치
- 매출액을 마크 카드의 색상과 레이블에 배치
- 툴 바의 정렬 아이콘을 이용해서 내림차순으로 설정
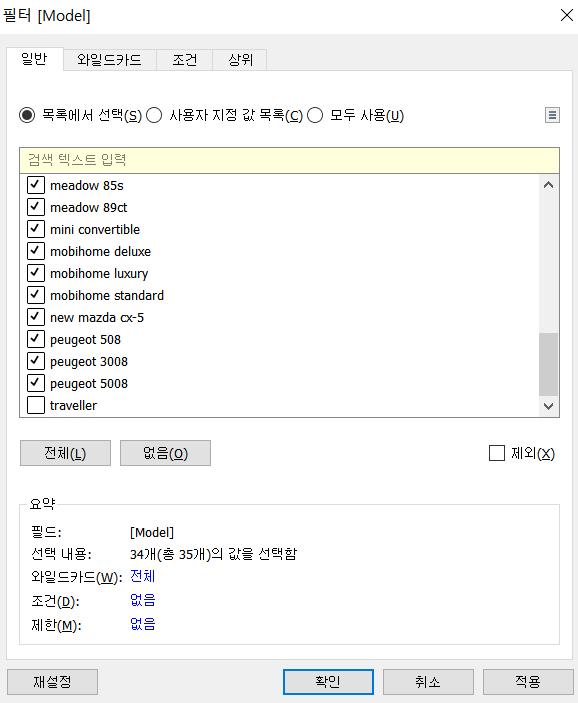
- Model을 선택하고 필터에 배치
- 일반에서는 특정한 값을 포함시키거나 제거 가능
- 와일드카드에서는 특정 문자로 시작하거나 종료되는 그리고 포함한과 정확히 일치를 설정할 수 있습니다.
- 조건에서는 직접 조건을 설정합니다.
- 상위에서는 상위 또는 하위에서 몇 개를 추출할 수 있습니다.
- 필터를 만들 때, 측정 값을 설정하게 된다면, 범위 / 최대 / 최소 / 특수 총 4가지 형태로 조건을 설정합니다.
✔ 필드 변환
- 차원 또는 측정값을 이용해서 시각화에 필요한 새로운 필드로 변환하는 것
- 만들기 / 변환 / 변경 등의 작업이 가능
- 차원과 측정값은 변환 기능이 서로 다릅니다.
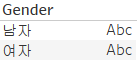
별칭
- 값에 별명을 붙이는 것
- 차원 데이터에서 값 대신에 특별한 문자열이나 값을 사용하는 것
- 문자열이 열거형(특정 값 만으로 구성된 데이터로, 범주형이라고도 함 -factor)인 경우 주로 이용합니다.
- 숫자로 된 데이터에 문자열을 표시하거나 영문이나 다른 언어로 만들어진 데이터에 한글 별명을 주는 경우가 많습니다.
- DB에서는 기본적으로 열거형을 사용하지 않기 때문에, 열거형의 경우에는 일반 문자열이나 정수로 표현합니다
- 이런 경우에는 알아보기가 어렵기 때문에 별칭을 사용합니다.
- Gender field에 별칭을 사용해보자.
↓
계산된 필드
- 함수를 사용해서 필드를 계산하는 것
- 생성할 때는, 사이드바의 빈 영역에서 우클릭 [계산된 필드 만들기] 혹은 사이드바 상단 추가메뉴에서도 생성 가능함
- Tableau가 제공하는 함수와
IF ~ ELSIF ~ ELSE END사용이 가능함
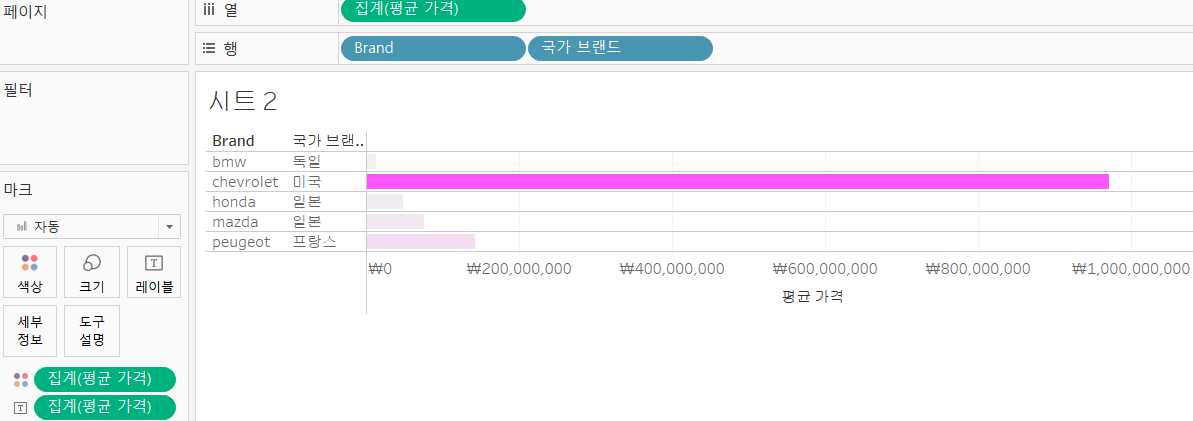
- 2개의 필드 생성
- 국가 브랜드 : Brand값이 chevolet이면 미국, bmw이면 독일, peugeot이면 프랑스, 나머지는 일본
IF [Brand] = 'chevrolet' THEN '미국' ELSEIF [Brand]='bmw' THEN '독일' ELSEIF [Brand]='peugeot' THEN '프랑스' ELSE '일본' END
- 평균 가격 : price 필드의 평균
AVG([Price])
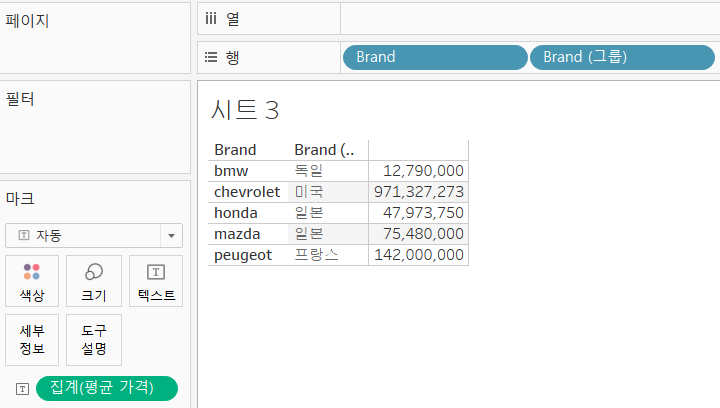
그룹
- [차원]이나 [측정값]을 그룹화할 때 사용하는데, 대부분의 경우는 차원을 그룹화하는데 사용
Brand를 그룹화
- [brand]필드 만들기 그룹
- 그룹화하고자하는 하옴긍ㄹ 선택하고 그룹을 누르고 그룹 명을 입력
↓
집합
- 데이터를 미리 선정해두고 사용하는 것
- 동적 집합과 정적 집합이 있는데, 동적 집합은 데이터의 값에 따라 변경이 될 수 있는 것으로, 단일 차원으로만 만들어 나갑니다.
- 정적(고정)집합은 데이터를 고정시켜서 선ㅌ낵하는 것으로 변경이 안되지만 여러 차원으로 만들 수 있습니다.
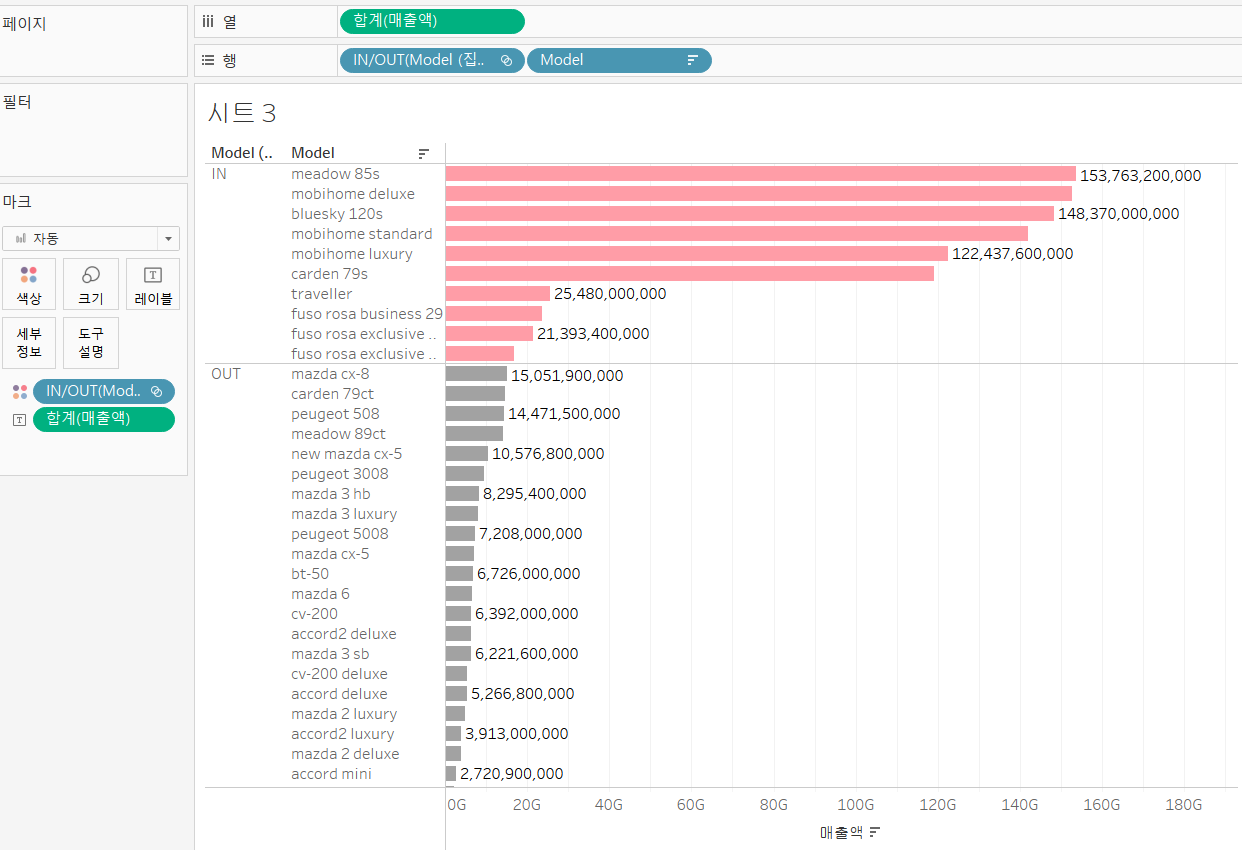
Model과 매출액을 이용해서 막대 그래프 그리기
동적 집합 만들기
- model 클릭 만들기 집합
- 이름은 자유롭게
- 상위 10개만 뽑자(조건)
고정 집합 만들기
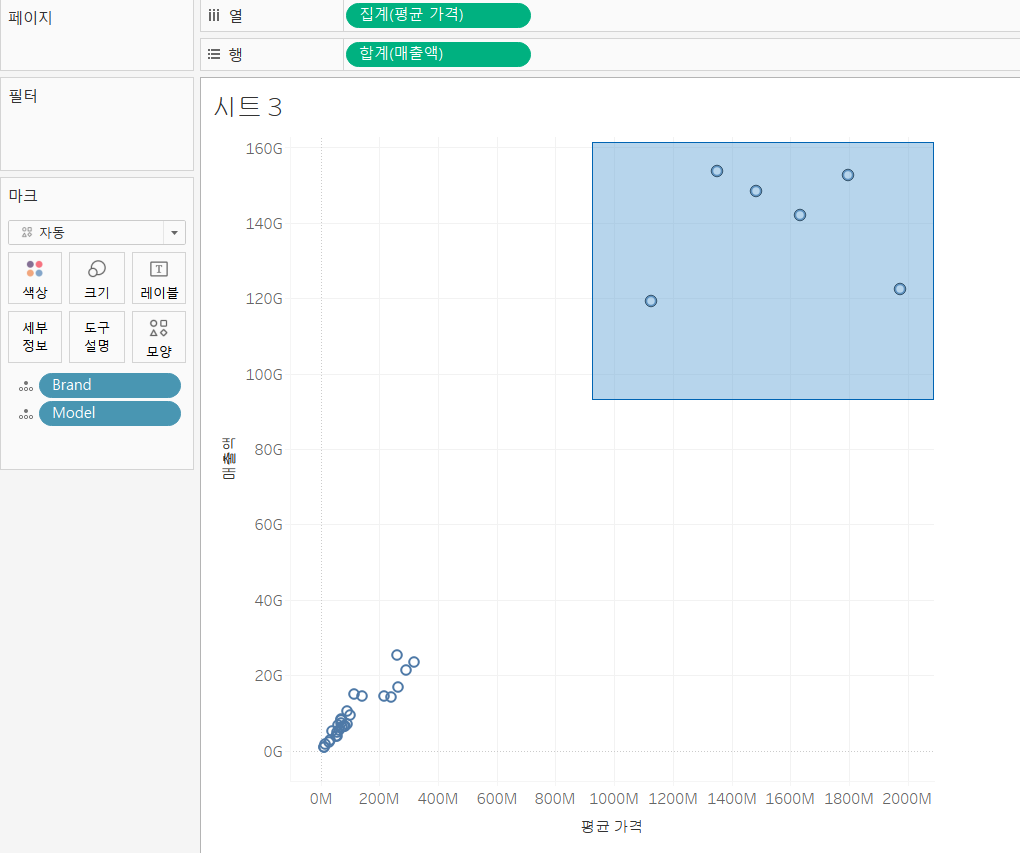
- 매출액을 행에, 평균 가격을 열에 배치 (두 숫자가 들어가면 scatter)
- brand, model을 마크카드 세부정보에 배치
- 분산형(Scatter) 차트에서 그룹화하고 싶은 데이터만 드래그해서 선택 후, 나오는 메뉴에서 [그룹화] 선택하고 그룹 이름 입력하기
구간 차원(Binning)
- 연속형 데이터를 범주(차원, Factor, 열거형-Enum)형으로 만들고자 할 때 사용
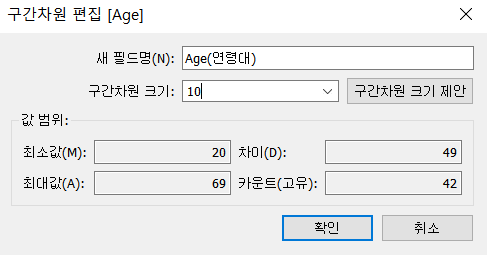
Age 를 10살 간격으로 구간화 해보기
- Age 클릭 만들기 구간차원 선택 후, 이름 입력하고 각 구간의 크기를 설정하기
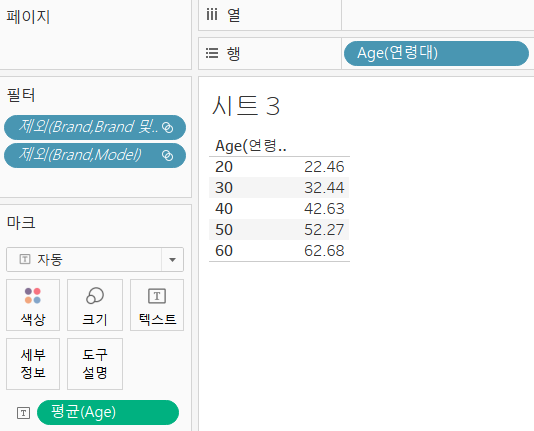
- 만들어진 필드를 행으로 배치하고 확인
- Age를 마크선반 텍스트에 배치하고 측정값을 합계가 아닌 평균으로 설정하고 봐보자.
- 원래 python으로 했다면 구간을 하나하나 나눠야 했었을 것이다.
- 범위설정이 되고, 구간의 개수 설정도 가능하다.
- 범위를 볼 때, 데이터를 확인하고 설정해야 한다.
매개변수
- 사용자가 직접 값을 설정하거나 입력해서 뷰를 필터링하기 위한 기능
- 단독으로 사용될 수는 없다.
- 차원이나 측정값 또는 계산될 필드와 같이 동작합니다.
- Tableau에서 매개변수를 만들 때는 필드의 이름은 포함되지 않고 값만 들어가기 때문에, 누가 이 값에 속해야 하는지를 모르기에 단독으로 사용될 수 없다. - 생성을 할 떄는 사이드 바의 빈 영역에서 우클릭으로 만들거나 사이드바 상단의 추가 메뉴를 클릭해서 생성이 가능하다.
날짜를 갖는 매개변수 2개를 생성(시작일, 종료일)

만든 매개변수 사용
- order date를 행에 배치 불연속형 월단위로 설정
- 매출액을 마크카드 텍스트에 배치하여 월단위 매출액을 표시
- 매개변수를 활용하기 위한 계산된 필드 생성 - 매개변수 (Order Date)
IF [Order Date] >=[시작일] AND [Order Date] <=[종료일] THEN 'Y' ELSE 'N' END
- 행에 [매개변수 (Order Date)] 필드에 배치
- 매개변수를 화면에 표시하기
- 매개변수를 선택하고 표시하기
- 계산된 필드(매개변수(Order Date))를 필터로 드래그 하고 체크 박스에서 Y 선택
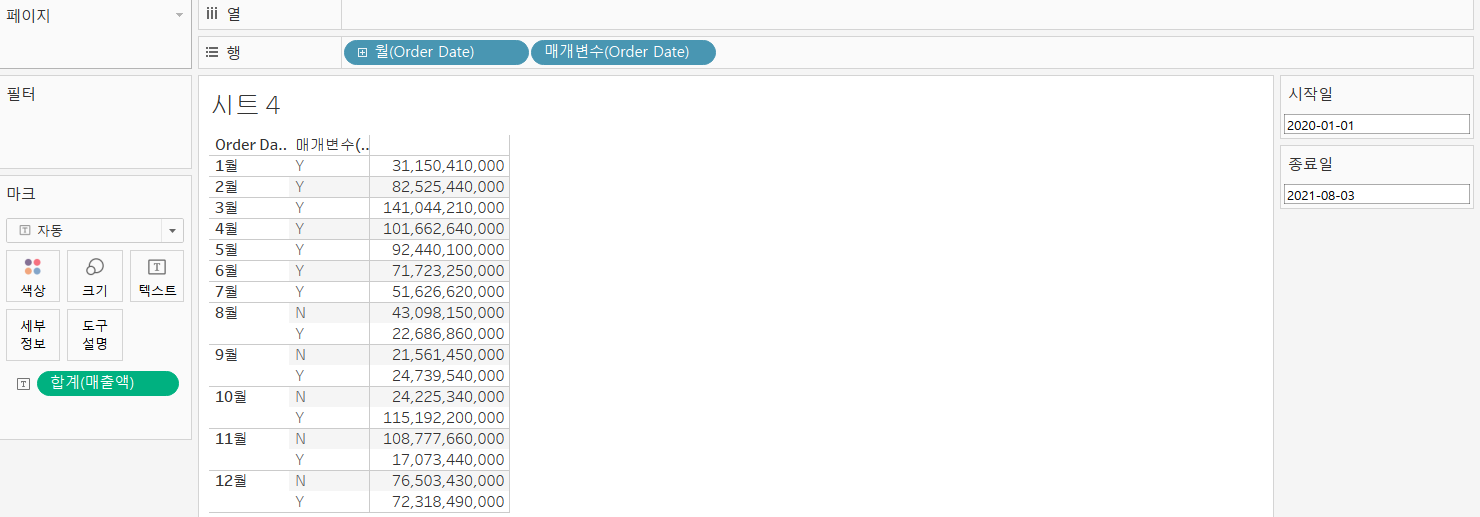
매개변수를 적절히 활용하면,
동적으로 뷰를 변경하면서 데이터를 확인하는 것이 가능합니다.
매개변수, 계산된 필드는 굉장히 많이 만들고 사용합니다. 매우 중요합니다.
변환
- 차원 필드 값을 여러 필드로 나눌 때 사용합니다.
- 1. 분할
- 2. 사용자 지정 분할 - 분할
- Tableau가 자동으로 분할
- 반복되는 패턴이 있는 경우 - 사용자 지정 분할
- 구분 기호로 직접 분할
서울시 양천구 서울시 서초구 서울시 강남구
- 분할은 Tableau가 서울시 / ~~구로 나눈다.
- 사용자 지정 분할은 "공백"을 기준으로 나누는 것
- 자동 분할
- 원하는 필드 변환 분할
- Tableau가 패턴을 찾아 분할을 해준다.
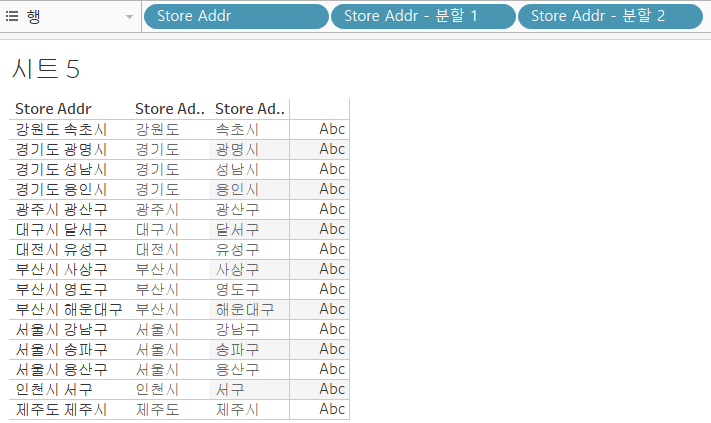
- 직접 분할
- 원하는 필드 변환 사용자 지정 분할 을 선택하고 구분 기호를 설정
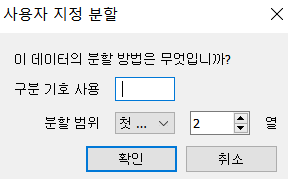
Split 은 기호가 정규 표현식인지 아니면 문자열인지 확인을 하고 한가지로 분할이 가능한지, 아니면 여러 가지 설정이 가능한지 그리고 분할할 개수를 설정할 수 있는지 확인
indexOf 나 lastIndexOf는 시작할 위치를 설정할 수 있는지 확인
계층
- 여러 차원 값들을 하나의 계층으로 만들 때 사용함(변환과 반대)
- 하나의 테이블에 상위와 하위 필드가 같이 존재하는 경우에는 계층을 미리 만들어 두는 것이 좋다.
- 계층을 만들어두면 계층을 뷰에 배치할 때, + 아이콘을 만들어서 펼쳐서 보거나 전체 보기를 할 수 있도록 해줍니다.
- 연/월/일이 따로 있는 경우 같은 것은 계층을 만들어 두는 것이 좋다.
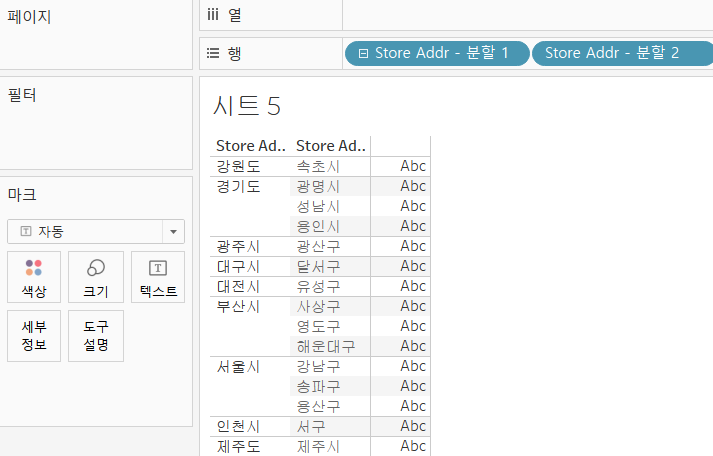
분할1과 분할2를 합쳐서 계층을 생성
- 2개의 필드를 선택하고 분할 2의 추가 메뉴 계층 계층만들기
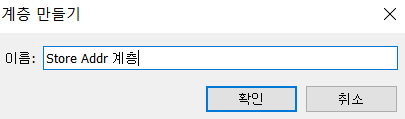
- 확인을 해보고자 한다면 만들어진 계층을 행으로 드래그 하고 + 버튼을 클릭해서 잘 만들어졌는지 확인해보기
데이터 유형 변환 및 지리적 역할
- 데이터 유형 변환 : 자료 형 변환
- 지리적 역할
- 국가나 시군구 등의 기능으로 변환 (탁월한 기능)
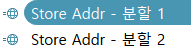
지리적 역할 실습을 해보자.
- Store Addr - 분할1 을 선택 지리적 역할 시/도
- Store Addr - 분할2 를 선택 지리적 역할 시/군/구
- 지구본 모양이다
- Store Addr 계층을 마크 카드 색상 및 세부 정보에 배치
- 이후 표현 방법에서 지도를 선택하면 나온다.
탐색적 시각화를 할 때는 Python 보단 Tableau 로 하는 것이 효율적이다.
차원 및 측정 값 변환
- 차원(Factor - 범주)을 측정값으로 변환하거나 측정 값을 차원으로 변환하는 것
차원인 Model을 측정 값으로 변환을 해보자.
- Model 필드를 행으로 배치하자.
- Model 차원을 , Model 측정값으로 바꿀 수 있다.
- 측정값(Count)를 고르게 된다면, Count를 반환합니다.(데이터의 개수)
- 물론 사이드 바에서도 바꾸기도 가능하지만, 다시 되돌려 놓는 것을 잊지 말자.
- 차원을 측정값으로 변환하는 것은 개수를 세는 것 이외에는 큰 의미가 없다.
- 문자열은 차원으로 설정되는데, 문자열을 숫자로 변경할 때는 일련번호 형태를 사용하지 않습니다.
- 문자열을 숫자로 바꾸는 것은 거리계산을 할 때 만입니다.
- 큰 의미가 없어요. - 일반적으로는 측정 값을 차원으로 변경하는 경우가 많음
- 설문조사를 하거나 DB에 data를 저장할 때, ENUM 스타일을 사용할 수 없기 때문에, 숫자로 변환해서 저장하는 경우가 있씁니다.
- 숫자로 저장하게 된다면, 읽어올 때 측정값으로 읽어오는 경우가 발생해서 측정 값으로 되돌리거나, 변환 작업들을 수행하게 됩니다.
- 예시
- 1. 대졸 이상
- 2. 대졸
- 3. 고졸
- 4. 고졸 미만- 1, 2, 3, 4로 저장하는 편이다.
✔ 뷰 편집
서식
- 글꼴 / 맞춤 / 음영 / 테두리 / 라인을 이용해서 뷰 서식 변경을 할 수 있다.
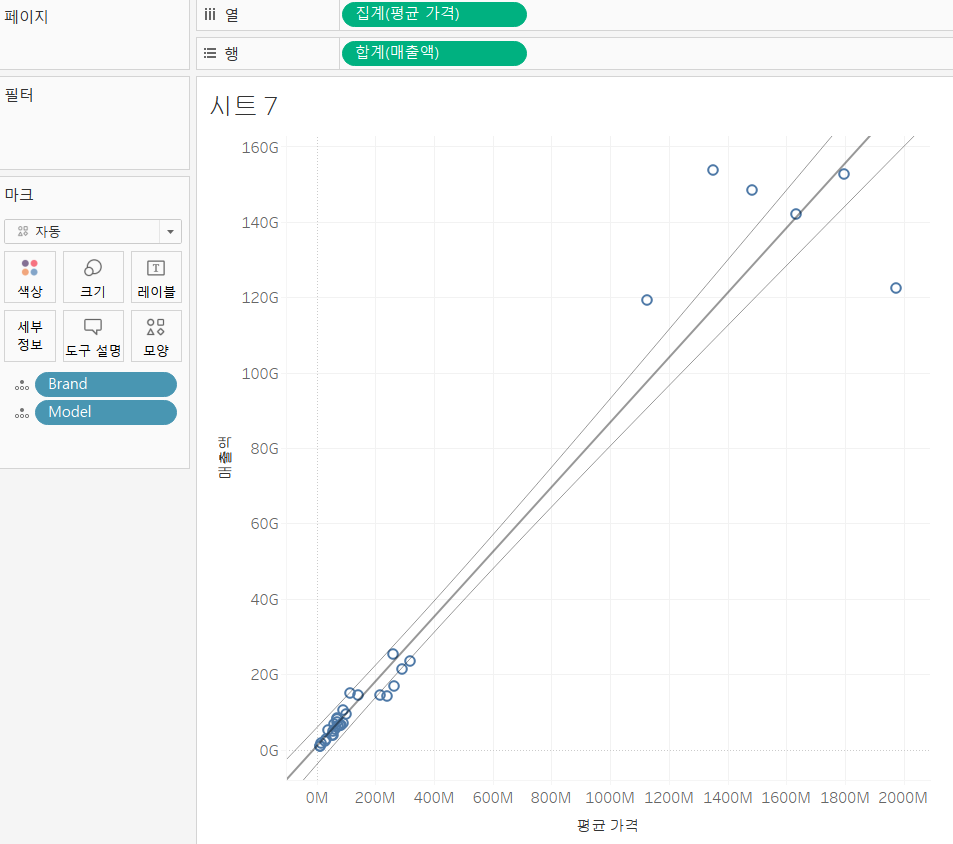
매출액과 평균 가격을 이용해서 분산형 차트(Scatter)를 만들고 서식을 변경
- Scatter 는 분포확인 , 상관 관계 파악을 하는 것이다.
- 그렇기에 얘는 측정값 2개를 가지고 생성한다.
- 매출액과 평균 가격을 행과 열에 배치
- 전체 매출 합계이기에 점은 1개만 생성
- 분류를 할 때는 마크 카드의 세부정보를 이용한다.- 마크 카드의 세부 정보에 Brand와 Model 필드를 배치
- 뷰 영역에서 우클릭 서식 실행해서 서식 변경 워크시트 선택하고 수정을 하면 X축과 Y축 모두 영향을 받고, 상단 필드에서 특정 필드를 선택하면 선택된 필드만 수정됩니다.
축 편집
- 범위나 눈금 또는 축 제목과 눈금선을 편집
- 축을 선택하고 우클릭 축 편집을 클릭하고 설정하자.
추세선
- 선형 / 로그 / 지수 / 거듭 제곱 / 다항식을 활용해서 측정 값들의 추세를 표시할 수 있다.
- 뷰에서 우클릭 추세선 추세선 표시
- 추세선 우클릭 설명 들어가면 설명도 나오고, 신뢰구간도 확인 가능
신뢰구간(Confidence Interval)
- 모수가 어느 벙위 안에 있는 지를 확률적으로 보여주는 방법 중의 하나
- 신뢰수준을 설정해 해당 구간 안에 있을 확률이 95%,99%정도 된다고 설명
선형 / 로그 / 지수 / 거듭 제곱 / 다항식 형태가 있는 이유는 기본은 선형 회귀인데, 선형 회귀는 회귀를 잘 설명하지 못하는 경우가 있어서 이런 경우에는 거듭제곱이나 다항식 등을 이용해서 회귀를 설명합니다.
- 추세선에 마우스를 올려보면 다음과 같은 정보가 나옵니다.
- 1. 회귀식
- 2. r-squared(R2 Score)
- 3. p-value- R2 Score는 결정 계수이며, 회귀 모델에서 독립 변수가 종속변수를 얼마나 잘 설명하는가를 보여주는 지표 입니다.
- 이 값이 1에 가까울 수록 독립 변수들이 종속 변수를 잘 설명한다고 합니다.- 어떤 회귀식을 사용해야 할 지 결정이 잘 안되는 경우에는 p-value(유의 확률)가 작은 값을 선택합니다.
- p-value는 우리말로는 유의확률이라 번역됩니다.
- 귀무가설이 맞다고 가정할 때 얻은 결과보다 극단적인 결과가 실제로 관측될 확률입니다.
- 이 수치는 작을 수록 결과를 신뢰할 만 합니다.

주석
- 뷰에 텍스트를 출력하는 것으로, 마크 / 지점 / 영역을 활용
- 차트 영역 안에서 우클릭 주석 추가 선택 후 설정
✔ 마크 카드
- 기본적으로 색상 / 크기 / 텍스트 / 세부 정보 / 도구 설명으로 되어있지만, 마크 유형에 따라 메뉴는 유동적입니다.
색상 / 크기 / 레이블
- 색상이나, 차트의 크기, 차트에 표시되는 문자열 입니다.
- 레이블 대신 텍스트로 나오는 경우가 있습니다.
세부 정보 / 도구 설명
- 세부 정보는 차원 내에서 세부 차원을 적용하고자 할 때 사용
- 도구 설명은 차트에 마우스를 올리면 보여지는 정보를 설정할 때 사용
세부 정보
- 행과 열에 매출액 및 Order Date 배치
- Order Date를 선택하고 추가 메뉴를 통해 범위와 연속성을 설정
- 마크 카드의 세부 정보에 평균 가격 필드를 배치해보자
- 마우스를 올리면 볼 수 있다.
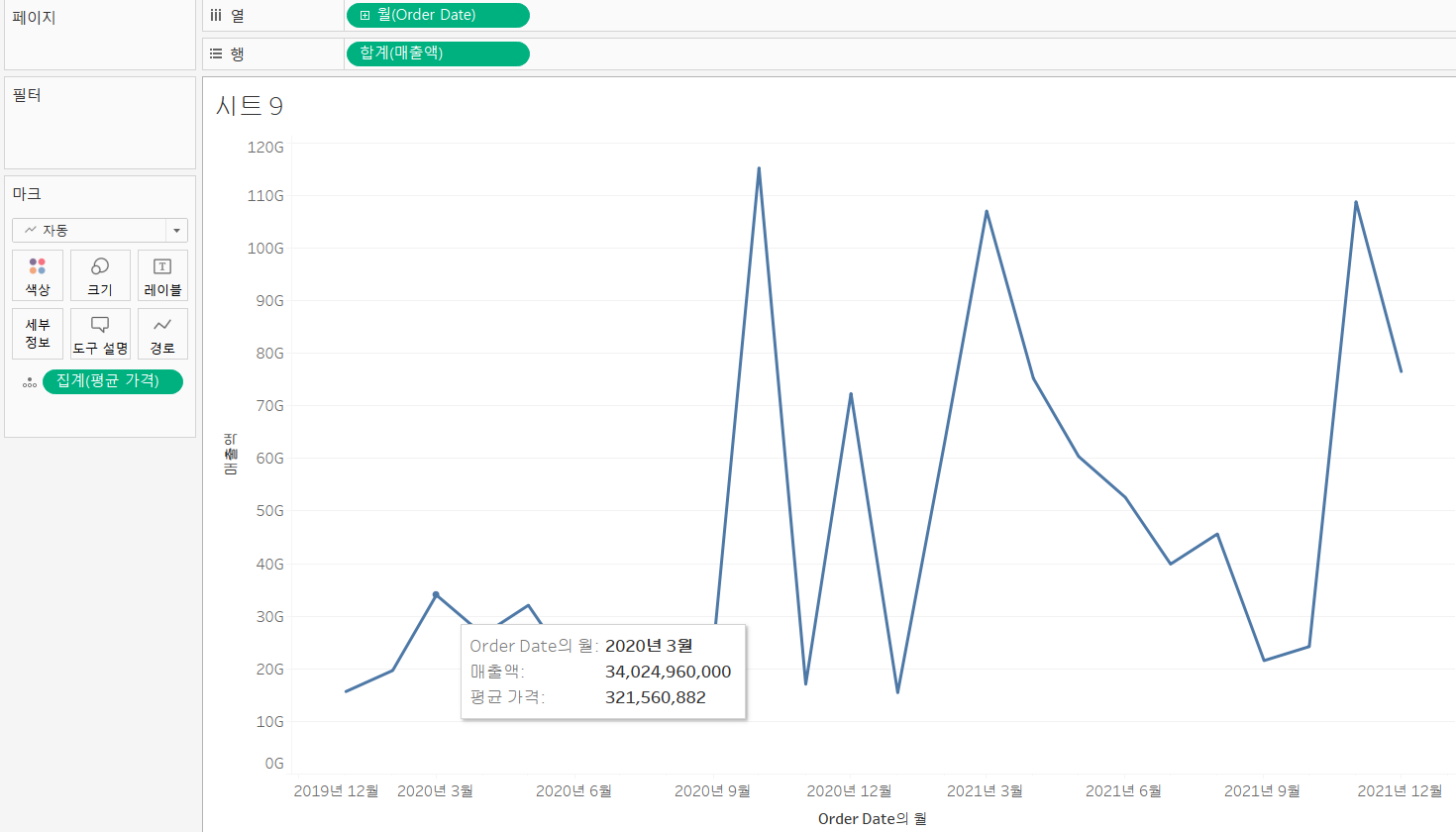
도구 설명
- 마크 카드의 도구 설명을 누르면 마우스를 올렸을 때, 확인하고 싶은 정보들을 추가로 편집할 수 있다.
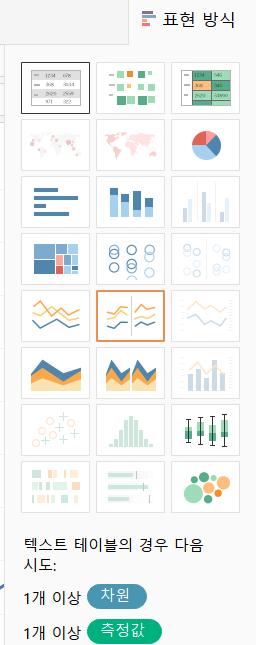
✔ 표현 방식
- 선택한 필드 값들을 기준으로 해서 적합한 뷰를 추천
- 빨간색 테두리로 되어 있는 것이 권장입니다.
✔ 요약
- 뷰 안에 라인을 출력하거나 사분위수 또는 전체 합계를 출력하고자 할 때 사용하는 기능
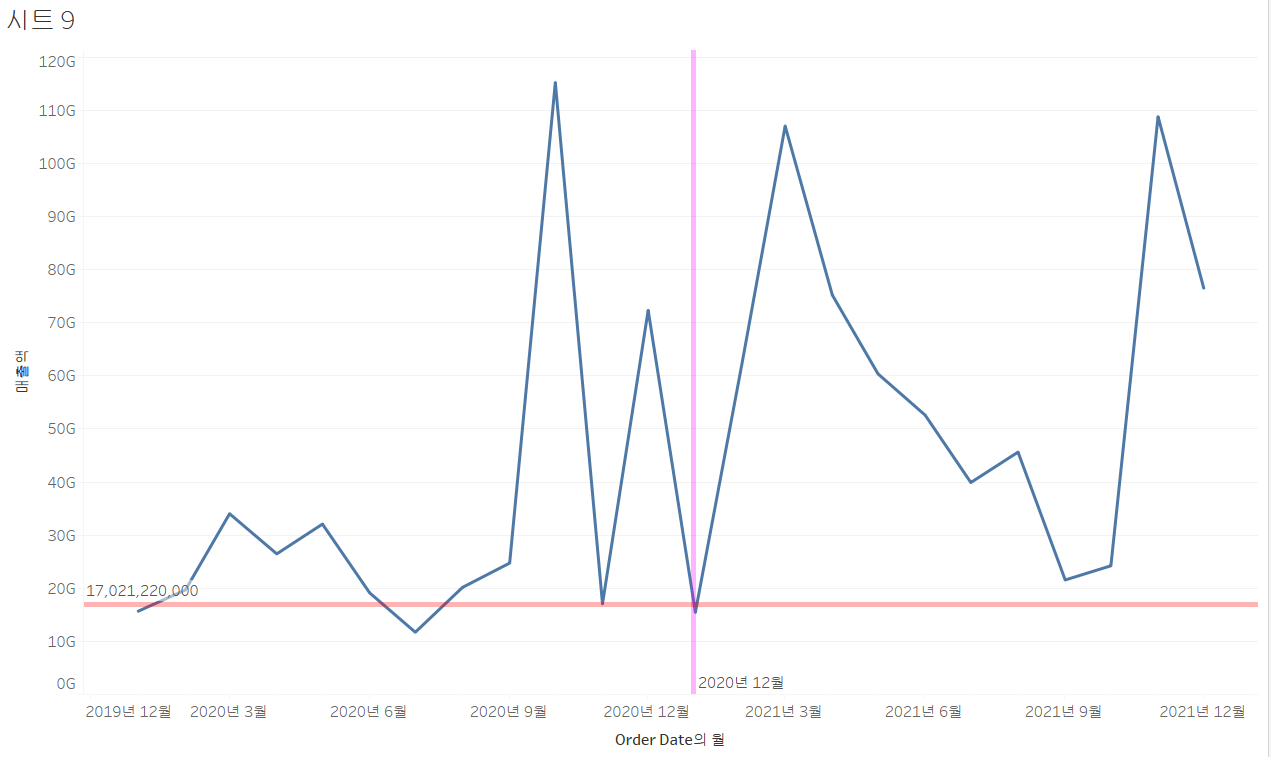
상수 및 평균 라인
- 상수 라인은 직접 선의 위치를 지정하는 것
- 값을 직접 지정하는 것임
- 기준점을 설정하고자 할 때 이용합니다. - 평균 라인은 평균에 선이 그어지는 것
- 얘는 어떻게 할 수 없음
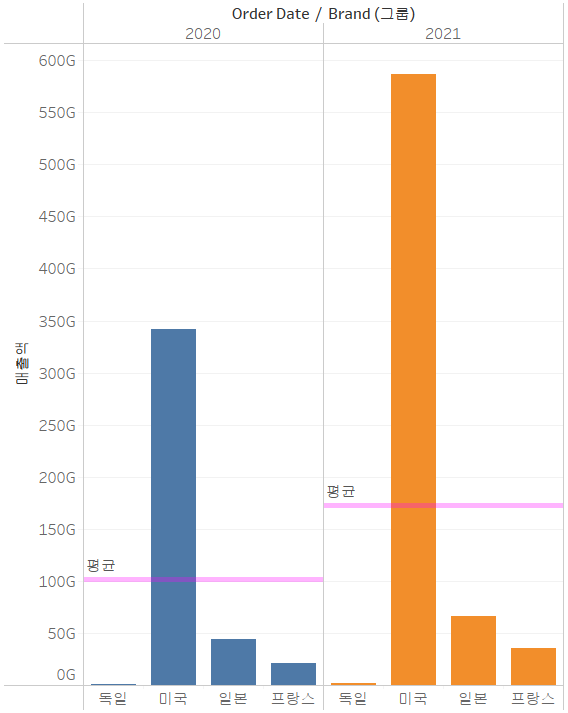
그래프에 상수 라인과 평균 라인 출력
- 행 과 열에 매출액과 Order Date를 배치하자.
- 상수 라인은 축마다 그어줄 수 있다.
- 분석 탭에서 상수 라인을 뷰로 드래그 한 뒤, 상수 라인을 설정할 항목을 결정하고 값과 서식을 설정해주자.
- 분석 탭에서 평균 라인을 뷰로 드래그 한 뒤, 라인을 설정할 항목을 결정
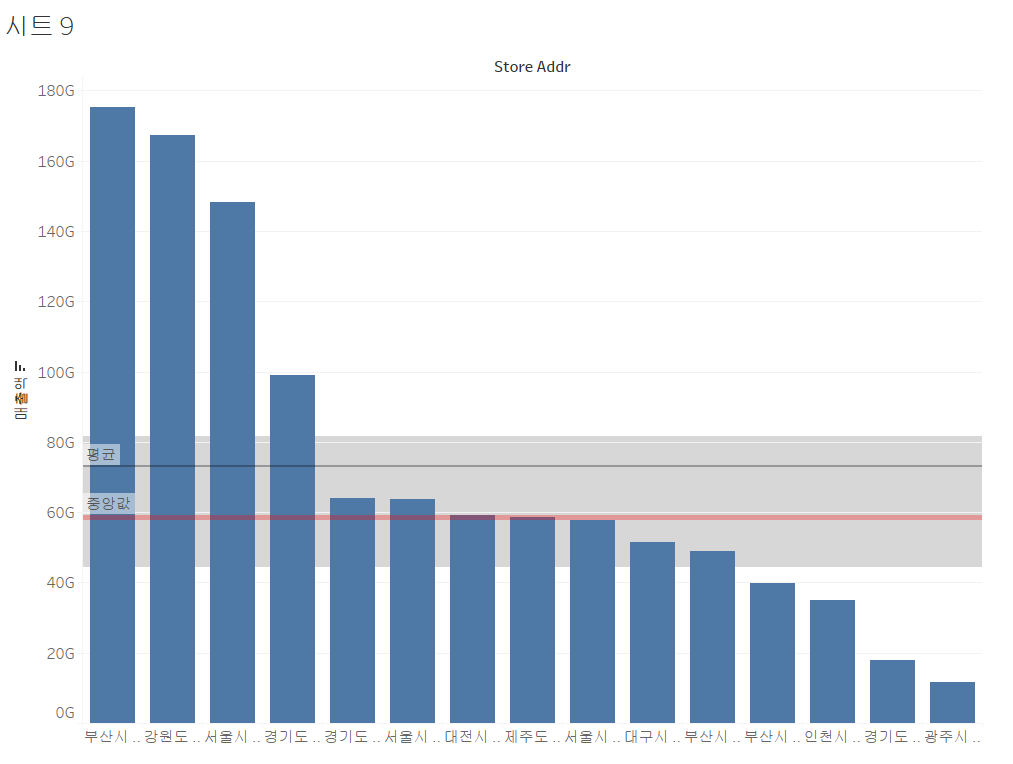
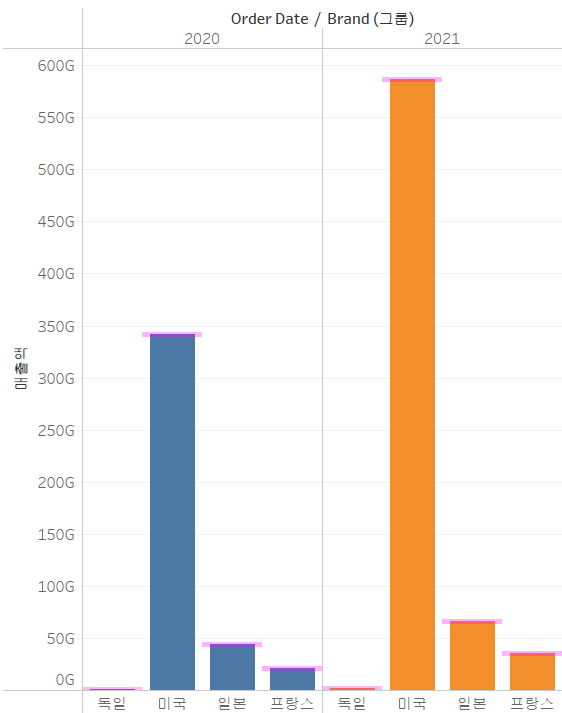
사분위 수 및 중앙값
- 사분위 수는 데이터 전체를 100%로 보고 4등분 한 뒤, 하위 25%, 50%, 75%의 값을 사분위 수라고 합니다.
- 1사분위수 : 하위 25%
- 2사분위수, 중앙값 : 하위 50%
- 3사분위수 : 하위 75% - 3사분위 수에서 1사분위 수 까지의 범위를 IQR이라고 합니다.
- 이 범위 안에 전체 데이터의 50%가 놓이게 됩니다.
- 이 IQR을 가지고 이상치 판단을 하는 경우가 있습니다.
사분위수와 중앙값 출력
- 행과 열에 매출액 및 Store Addr 필드 배치
- 분석 탭에서 사분위수 및 중앙값을 시트에 드래그 앤 드롭해주기
- 평균라인도 그렸습니다. 이때, 평균과 중앙값이 같았으면, 정규분포이다.
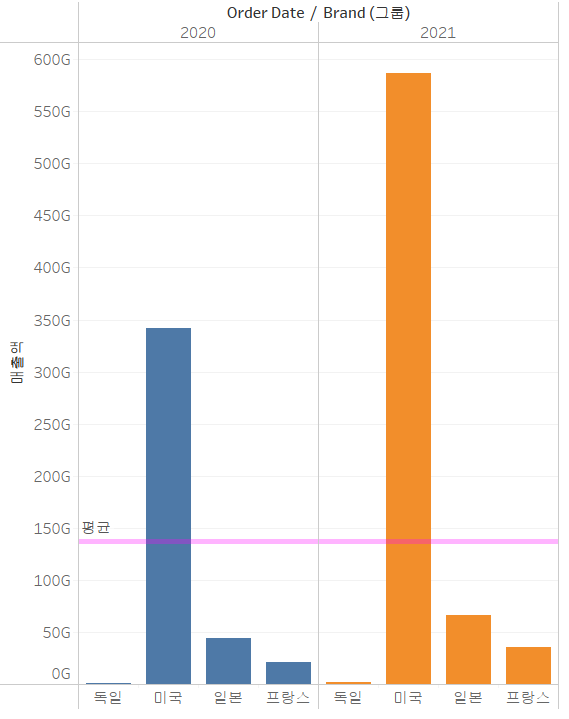
테이블 vs 패널 vs 셀
- 분석할 항목의 범위를 설정
- 테이블은 전체 데이터 기준
- 패널과 셀이 차이가 나는 경우는 차원이 2개 이상인 경우로, 첫 번째 차원 기준이 패널이고, 세부 차원 기준이 셀
행과 열에 매출액과 OrderDate, 그리고 Brand 필드가 존재하는 경우
- 테이블의 평균은 매출액의 평균입니다.
- 패널의 평균은 Order Date가 년도 별이라면, 년도 별 평균입니다.
- 셀의 평균은 년도 별 브랜드별 평균입니다.
- 테이블 평균
- 패널 평균
- 셀 평균
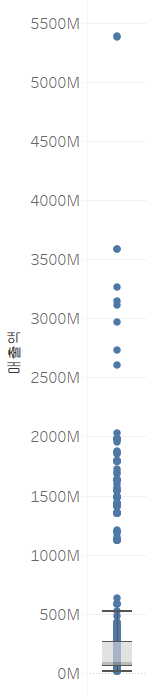
박스 플롯
- 사분위수와 중앙값 그리고 수염 정보가 박스 형태로 뷰에 표시되도록 하는 기능
- 수염은
3사분위수*1.5 그리고 1사분위수*1.5에 해당하하는 부분입니다.
- Outlier를 판단하는 가장 보편적인 방법으로, 수염 외부에 있는 데이터를 Outlier로 판정합니다.
- 실제 판단은 분석가의 몫입니다.- 얘가 일련번호 같은 것인데, 숫자로 판단하고 있다. 이럴 때 변환을 해줘야 합니다.
- 차원, 불 연속형으로 변경해줍니다.
- 현재, 밑에가 너무 촘촘히 있어서 위에 있는 데이터를 outlier로 판단한다. 이때는 분석가가 tableau에게 판단을 맡기는 것이 아닌 개입을 해야 합니다.
- 중앙 부분이 두꺼운 경우(데이터가 많은 경우) 중앙값과 별 차이가 없음에도 불구하고 Outlier가 될 수 있으므로, 이상치 제거를 할 때는 분포를 확인해서 라이브러리의 도움을 받는 것이 나을지, 아니면 분석가가 개입을 해야 하는지 고민해야 한다.

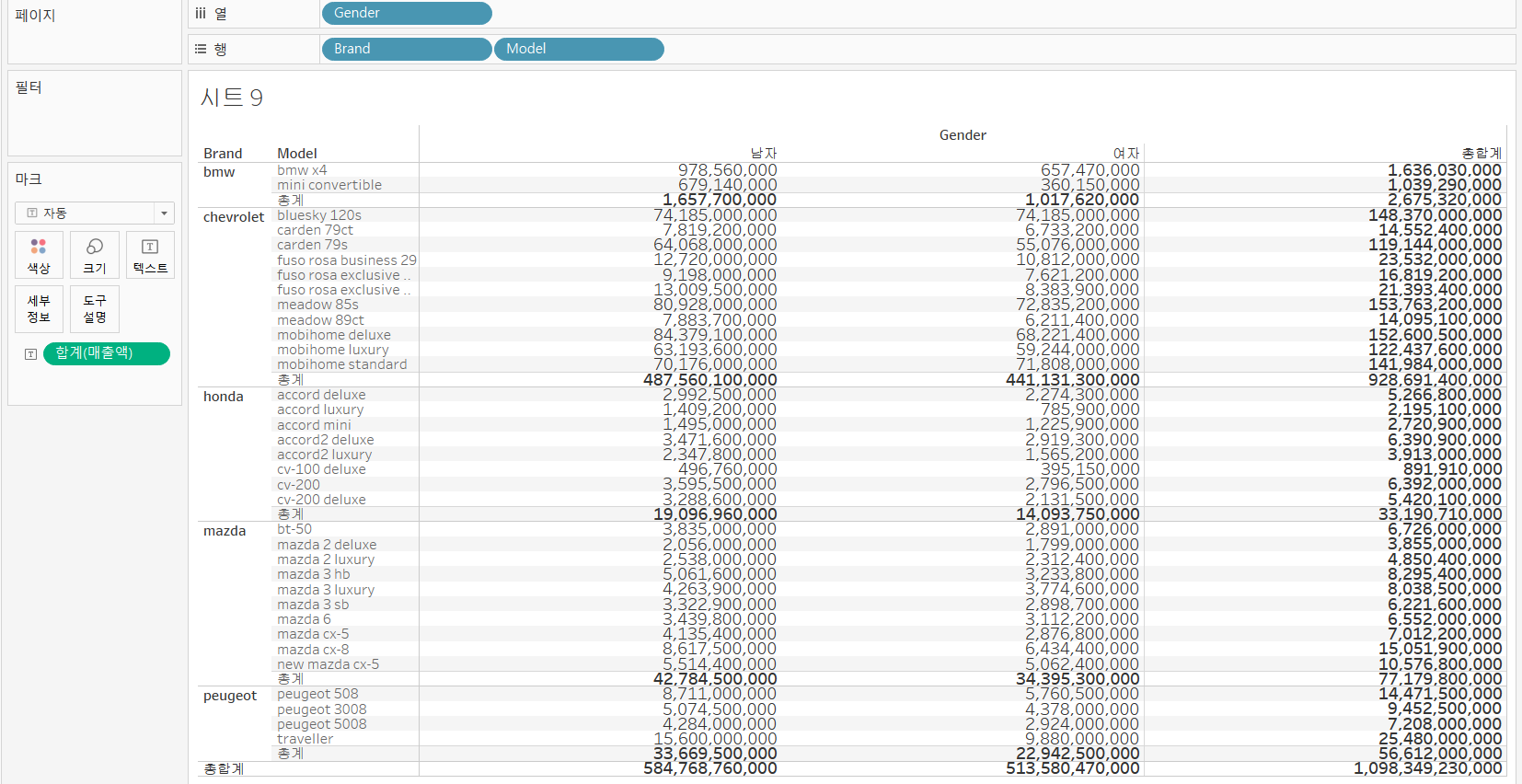
총계
- 측정값 필드의 총계를 뷰에 표시
총계 출력
- 행과 열에 Brand 와 Model 그리고 Gender 필드를 배치하자.
- 매출액 필드를 마크 카드의 텍스트에 배치
- 분석 탭에서 총계를 시트에 배치하기
- 소계, 열 총합계, 행 총합계 등을 출력할 수 있다.
- 최상단의 [분석] 메뉴의 총계를 선택하면 표시위치나 계산 값 변경이 가능함
모델
- 95% CI의 평균, 중앙값, 추세선, 예측, 클러스터를 활용해서 뷰를 모델화 하는 것
- CI는 (Confidence Interval - 신뢰수준)
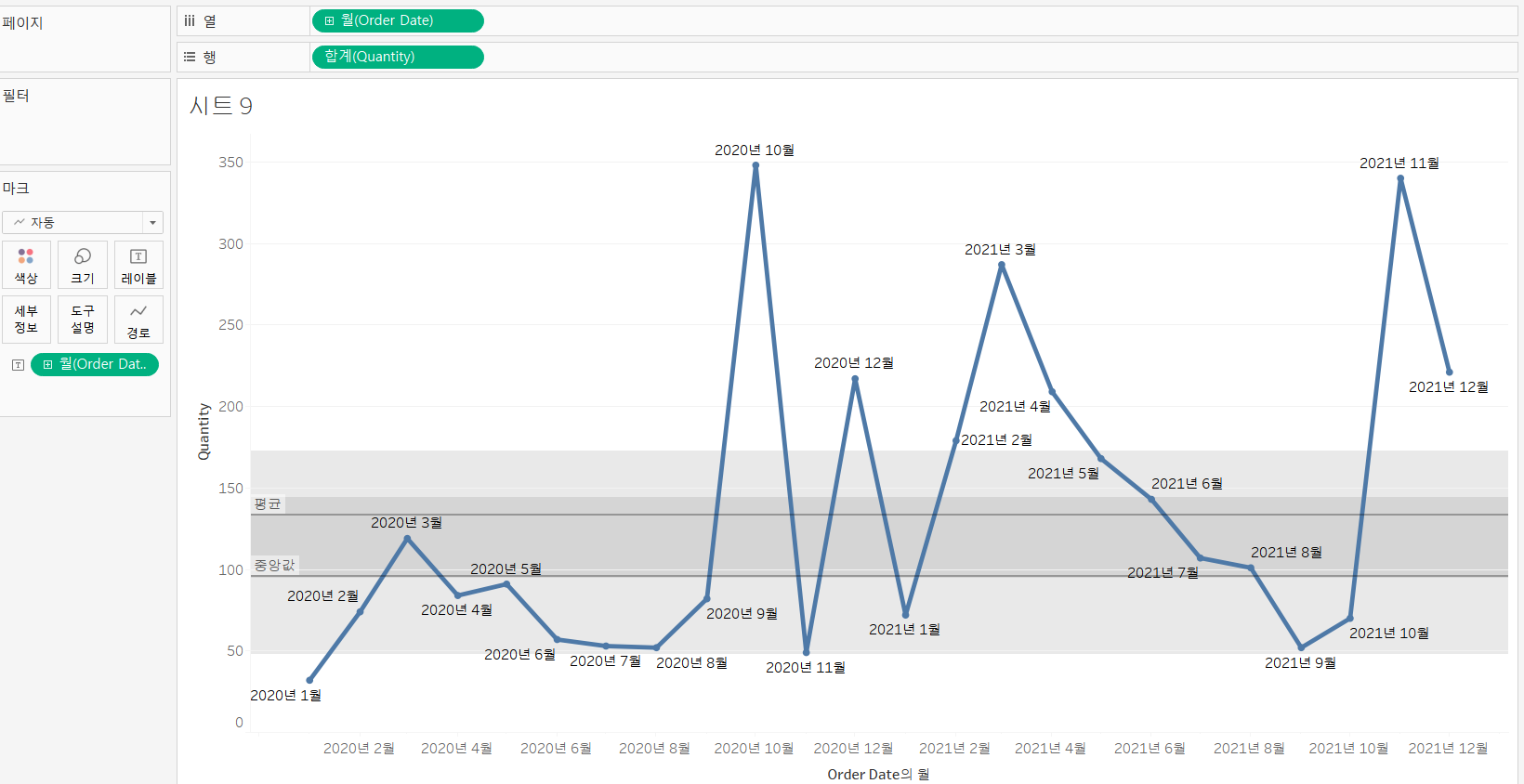
모델을 표시
- 행과 열에 Quantity와 Order Date 배치
- 마크 카드에 원하는 것 배치
- 분석 탭에서 95% CI의 평균 과 중앙값을 뷰에 추가
- 이번엔 중앙값이 더 밑에 가있다.
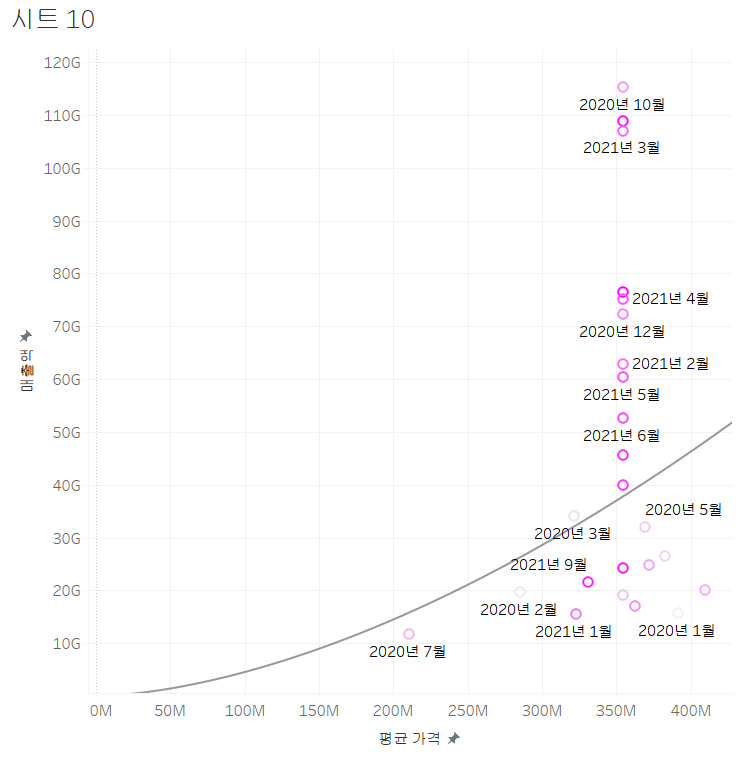
추세선
- 2개의 측정 값의 상호 관련성을 선으로 표시
- 측정값이 항상 2개가 있어야 합니다.
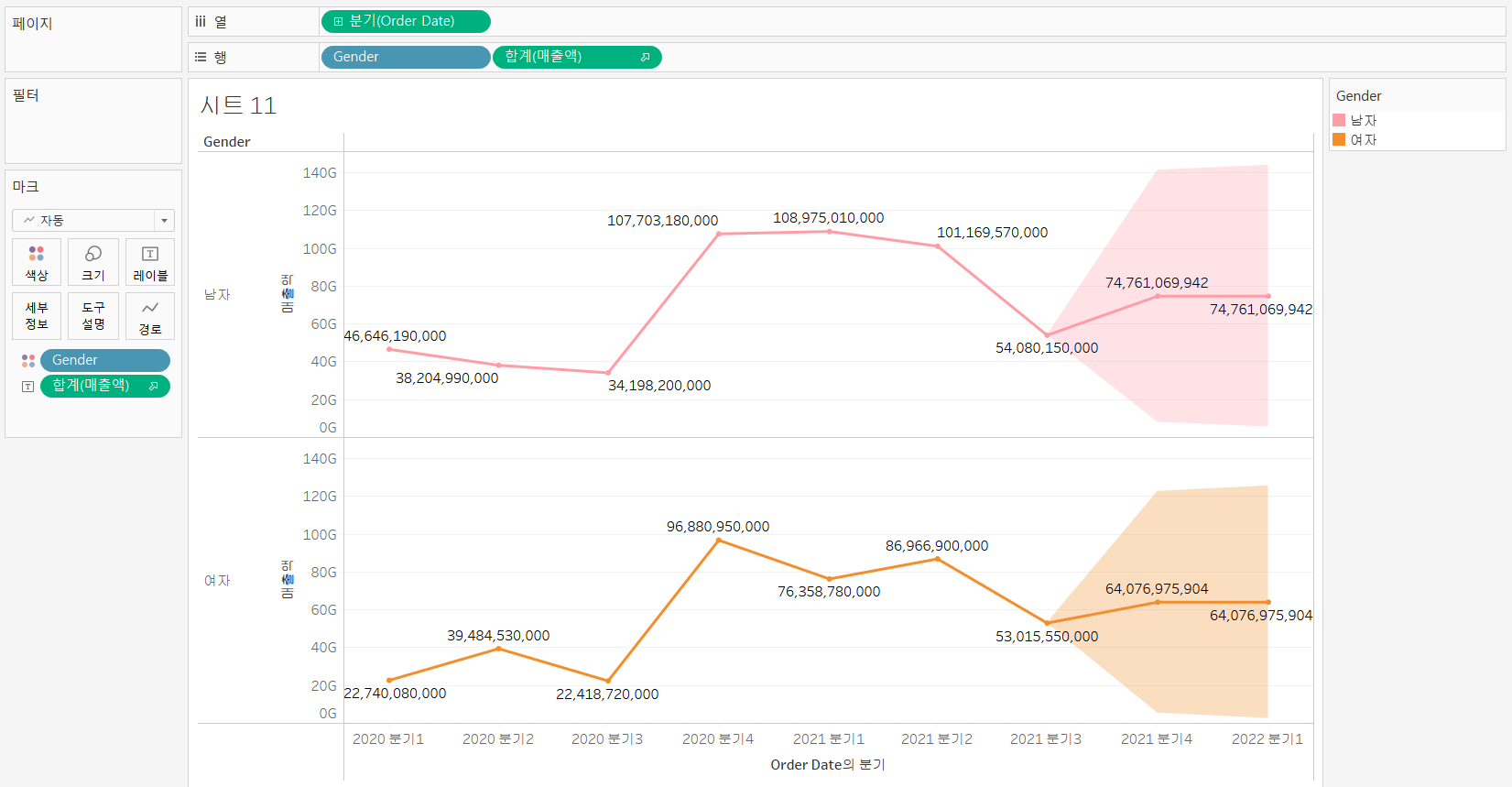
예측
- 날짜 필드를 활용하여 측정한 필드의 예측을 표시
- 행에 Gender와 매출액 배치
- 열에 Order Date 배치
- 색상 Gender적용, 레이블은 매출액
- 불연속형은 예측 안될것이다.
- 마크 카드의 예측 표시기 없애면 선 연결
- 하지만 너비가 너무 넓은 것을 확인할 수 있다.
- 데이터의 기간이 너무 짧습니다.- 예측 옵션도 설정할 수 있다.
- Tableau가 예측에 사용하는 방법은 지수 평활법이다.
- 시계열 예측을 할 때, 주가 예측은 과거의 데이터 비중을 낮추고 최근의 데이터 비중을 높여서 예측을 합니다.
- 가중치를 설정해서 예측을 합니다.
-(1-가중치)데이터1+(1-가중치^2)데이터2+...+(1-가중치^N)데이터N,가중치<1
- 단순 선형회귀가 맞는 경우는 진짜 거의 1도 없습니다.
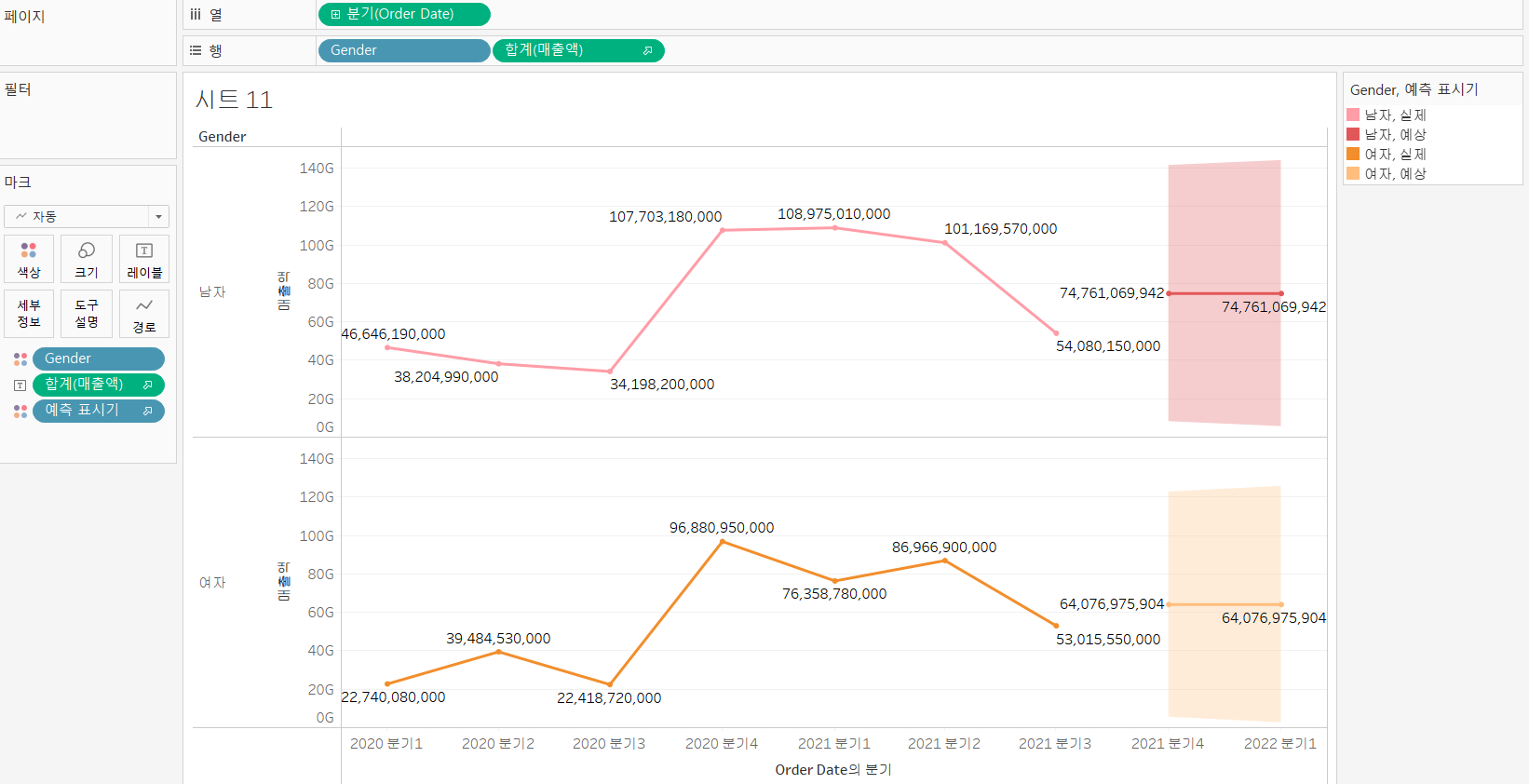
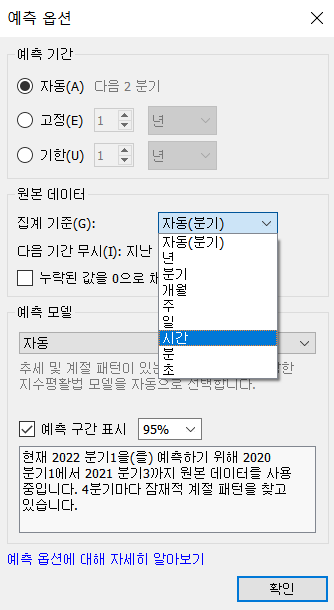
예측은 이어지는 연속형(다음이 있는 경우)만 가능합니다.
클러스터
- 그룹화 기능입니다.
- 그룹이 없는 데이터를 그룹화하는 작업을 클러스터링이라고 하고, 이를 수행할 때 사용하는 분석 방법을 군집 분석이라고 합니다.
- 이렇게 답이 없는 데이터를 가지고 답을 찾아가는 머신러닝을 비지도 학습이라고 합니다.
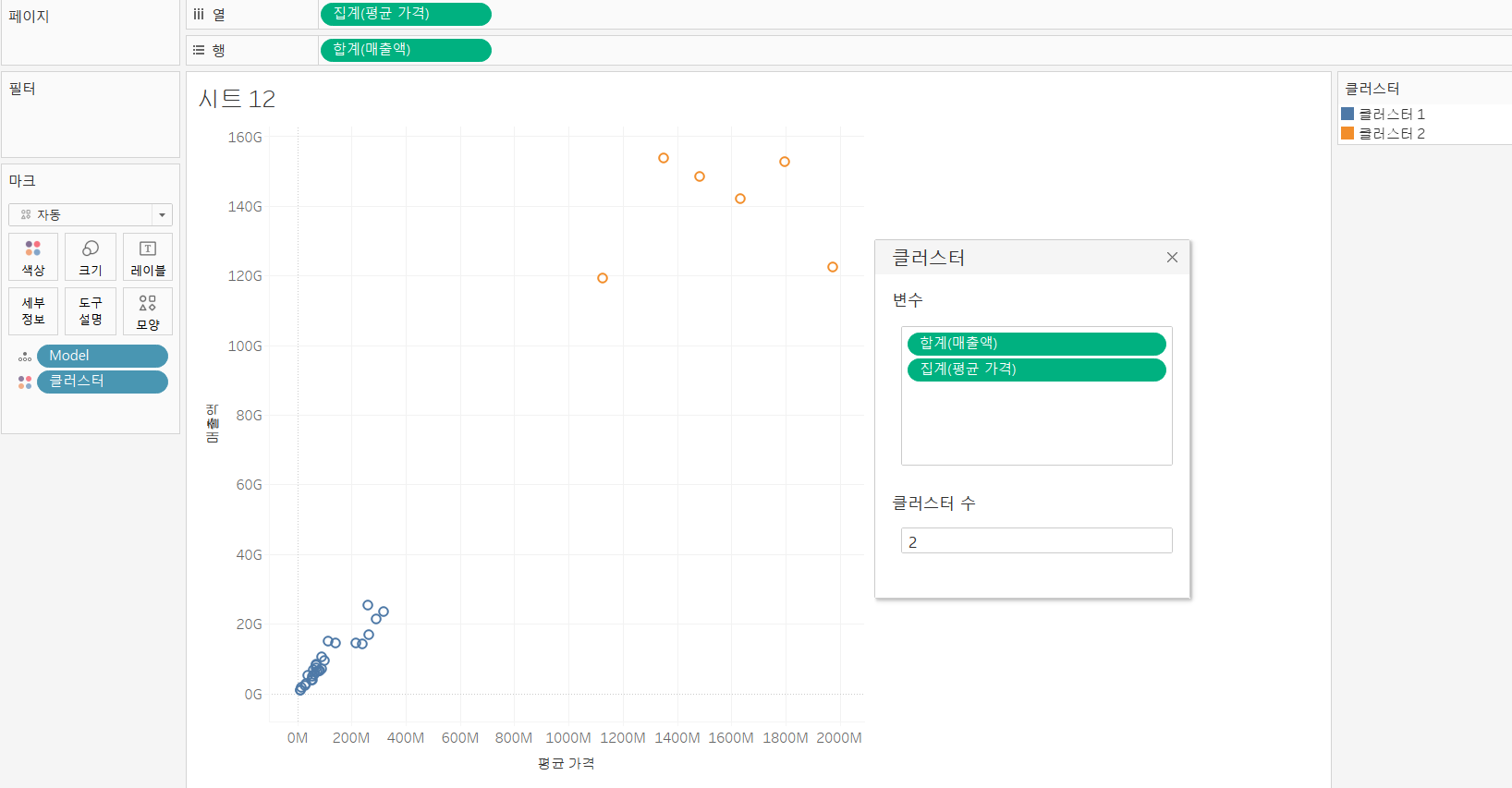
실습
- 행과 열에 매출액 및 평균 가격을 배치
- 마크 카드의 세부 정보에 Model 필드 배치
- 분석 탭에서 클러스터를 뷰로 배치
- 자동으로도 할 수 있고, 수동으로 그룹 수를 바꿀 수 있습니다.
- 클러스터는 측정값이 아닌, 차원으로 컬럼을 만들 수 있습니다.
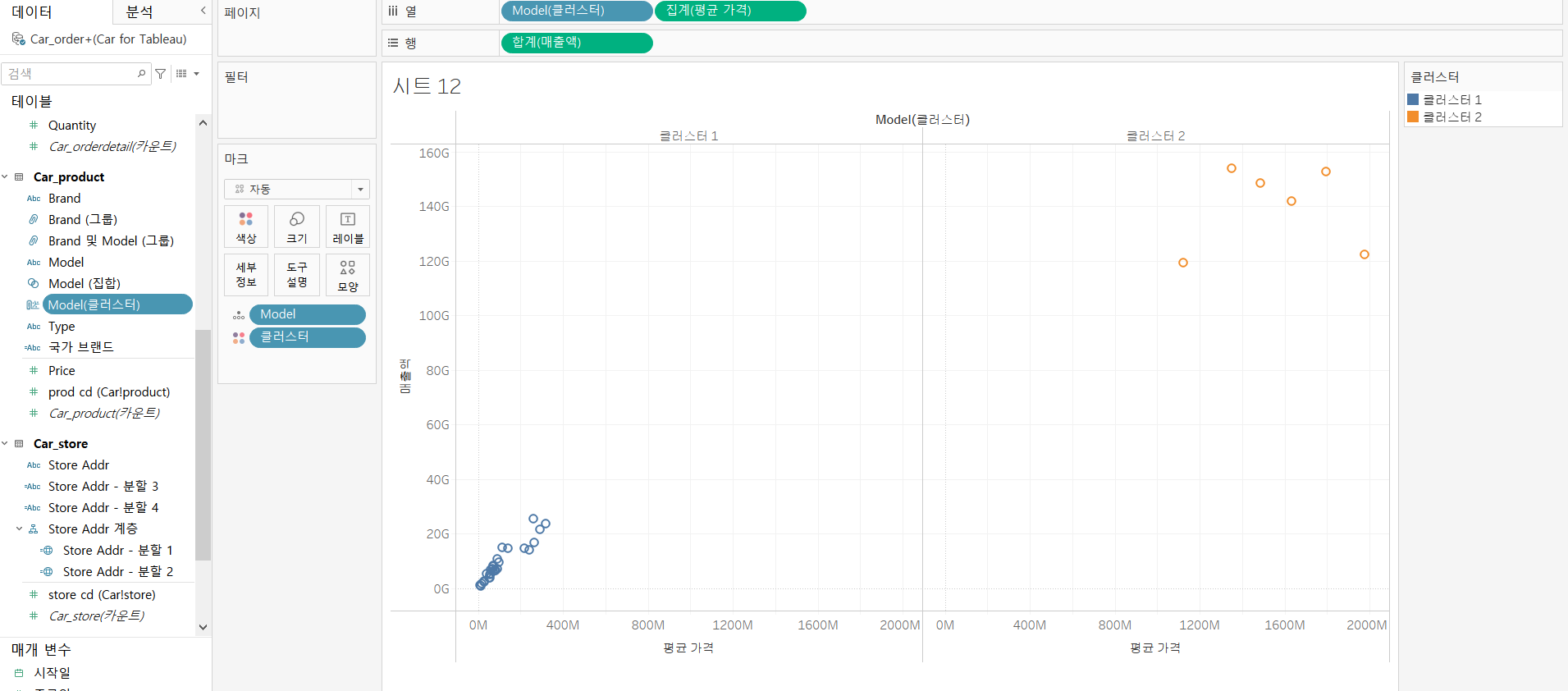
사용자 지정
- 분석 정보를 직접 설정하는 것
실습 환경
- 행과 열에 매출액 및 Model(클러스터) 필드를 배치
✔ Quick Table 계산
- 데이터 시각화에 필요한 계산식(누계 / 구성 비율 / 순위 / 전년 대비 성장율..)을 빠르게 정요할 수 있는 Tableau의 기능
- 측정 값을 가지고 하기도 하고, 계산된 필드를 만들어서 적용하기도 합니다.

밀가루 귀여워요