
docker설치 명령어 中
-v(볼륨): 디렉토리 설정 명령어, 공간을 만들어 주는 명령어-d: 백그라운드 설정포트번호:포트번호:
- 뒤는 프로그램 자체의 포트 번호, 밖에서 접속할 때, 앞에 설정
접속 프로그램
- db 서버를 설치하면 대부분 프로그램이 같이 설치된다.
- SQL PLUS (Oracle)
- Mongo Shell (Mongo DB)
이는 대부분 관리자들이 사용하는 용도이다.
이 프로그램으로 하는 것이 권한이 더 높아서 DB 즉시적용
여기는 데이터의 원본을 사용한다.
- DB는 외부로부터 물리적인 공격을 받지 않아하 하기 때문에, 관리자들만 사용하며, 그 외의 사람들은 외부 접속 프로그램을 사용해서 DB의 데이터에 접근한다.
- 외부 접속 프로그램을 사용한다면, 실제 데이터가 아닌 복제된 데이터를 사용하고, 이후 Commit을 하는 것이다.
CQRS
CQRS란 Command and Query Responsibility Segregation 의 약자로, 데이터 저장소로부터의 읽기와 업데이트 작업을 분리하는 패턴을 말한다. CQRS를 사용하면, 어플리케이션의 퍼포먼스, 확장성, 보안성을 극대화할 수 있다.
- 읽기는 엄청 하고 조작은 그렇게 많이 하는 것은 아니다.
- 조작에서 Lock이 걸린다는 것을 알아야 한다.
- 데이터 조작 중 다른 곳에서 조작하면 조작 정보를 잃어버릴 가능성이 존재 - 그럼 읽기는 NoSQL, 조작은 RDB(RDB는 강력한 트랜잭션, 많은 절차, 느림)
SHELL? (기억을 잘 해두자.)
- 명령어 인터페이스 이다.
✔ Mongo DB 접속해보기
- 터미널에서 MongoDB bash 셸 접속
-docker exec -it 컨테이너이름 bash - 디렉토리 확인하기
-ls
- 실행하는 파일은 binary 파일이다. bin 디렉토리를 확인하자.
MongoDB 접속을위한 프로그램이 있는 곳으로 경로 이동
- 경로를 바꾸는 명령어
-cd
-cd bin: bin 디렉토리로 이동 - 접속 프로그램
-mongosh(예전에는 mongo) IP:포트번호
- IP 생략 시, localhost:27017 로 접속함 - 작업의 단위
- Database > Collection (RDBMS에서는 Table) - 데이터베이스 확인 및 접속(없으면 생성)
명령어
show dbs: 데이터베이스 확인use 데이터베이스 이름: 데이터베이스 선택, 없다면 생성
- 단 생성 직후show dbs를 한다면, 데이터가 없어서 안보인다.*db: 현재 db확인
collection 생성
- 데이터를 삽입할 때, 컬렉션이 존재하지 않으면 자동 생성을 한다.
데이터 삽입
db.컬렉션이름.insert(객체)
- 예전 API
- insert 함수의 2번쨰 매개변수는 생략이 가능함
-ordered라는 옵션을 이용해서 싱글 스레드를 사용할 지 멀티 스레드를 이용할 지 결정할 수 있습니다.
- insert를 할 때, 배열을 대입한 경우 싱글 스레드로 작업하면 중간에 오류가 발생하면 작업을 더 이상 진행할 수 없지만, 멀티 스레드로 작업하면 중간에 오류가 발생해도 다른 작업은 계속 수행됩니다.
-언제 싱글, 언제 멀티 스레드로 작업해야 하는지 알아야 한다.
💥프로그램의 실행 단위?
- Process
- 가장 큰 단위로, 실행 중인 프로그램을 의미하며 실행 중간에 다른 프로세스를 수행할 수 없고, 데이터 공유가 안됨- Thread
- 프로세스 안에서 독립적으로 동작하는 작업단위로, 실행 중간에 다른 스레드의 작업을 수행할 수 있지만 데이터 공유는 통신을 이용하거나 공유 메모리를 사용해야 함
- 여기 공유 메모리는 전역변수
- 스레드의 등장 이유 = 속도 차이- Coroutine(Goroutine)
- Thread보다는 가볍고, 서로 간에 공유 메모리(Channel)를 이용해서 통신도 할 수 있는 경량의 Thread와 유사한 작업 단위. 이를 이용하면, 구독과 게시 시스템이나 병렬 처리를 구현하는 것이 쉬워집니다.
- 구독과 게시를 이용해서 공장 자동화나 CQRS를 구현합니다.
- 여기 공유 메모리는 둘이서만 사용 가능한 채널이다.
db.컬렉션이름.save(객체)
- 동일한_id값을 제공하면 수정db.컬렉션이름.insertOne(객체)db.컬렉션이름.insertMany(객체)
- MongoDB는_id라는 기본키 컬럼을 기본적으로 제공하는데, 자료형은Object_ID이다.
- save는 동일한_id값을 제공하면 수정, 나머지 함수들은 예외 발생- insert 할 때, 배열을 대입하면 분할해서 수행한다.
- MongoDB는 최상위 레벨에 배열을 지원하지 않는다.
- 최상위 레벨에는 객체 형태로 해놔야 한다.
mino> db.mino.insert({name:"mino",age:25, gender:"male"})mino> db.mino.insert({name:"mino",age:25, gender:"male"})
DeprecationWarning: Collection.insert() is deprecated. Use insertOne, insertMany, or bulkWrite.
mino> db.mino.insert([{name:"mino",age:25, gender:"male"}, {name:"mino2", age:24, gender:"male"}])
배열로 해볼까?
이에 대한 결과
{ acknowledged: true, insertedIds: { '0': ObjectId("64bdcb76be2bfa32add66a88"), '1': ObjectId("64bdcb76be2bfa32add66a89") } }두개로 쪼개버린다.
신기한게, NoSQL은 구조가 정해져있지 않아서
create table을 하지 않고 insert를 해버린다.
class(Schema, Table) - RDBMS, Dict(map) - NoSQL 이렇게 비슷하다.
데이터 확인
db.컬렉션이름.find()
멀티 스레드를 이용해서 배열을 삽입하는 경우의 차이
✔ 데이터 삽입 및 조회
collection에 고유 인덱스(RDBMS의 Unique 설정)를 설정
db.컬렉션이름.createIndex({컬럼이름:정렬조건},{unique:true})db.sample.createIndex({name:1},{unique:true})db.sample.insert({name:"Lee"})db.sample.insert([{name:"Lee"},{name:"Kim"},{name:"Park"}])오류!
E11000 duplicate key error collection: mino.sample index: name_1 dup key: { name: "Lee" }
db.sample.insert([{name:"Kim"},{name:"Park"},{name:"Lee"}]) #이걸 쓰면 kim, park은 들어가고 lee는 중복에 걸린다. #하지만, db.sample.insert([{name:"Lee"},{name:"Kim"},{name:"Park"}]) #이렇게 써버리면 Lee에서 먼저 걸려서 뒤에 kim, park은 안들어간다. db.sample.insert([{name:"Lee"},{name:"Kim"},{name:"Choi"}], {ordered:false}) # 순서대로 작업하지 말아라 #멀티스레드로 작업을 실행한다면, 앞에서 중복에 걸려도 #뒤에 choi는 잘 들어갔음을 알 수 있다. #주로 로그 삽입할 때 많이 사용한다.
insert
insertOne
- 데이터 1개 삽입을 위한 새로 만들어진 API
- 두 개의 매개변수를 가지고 있음
- 삽입된 데이터의 objectID를 Return
- 매개변수 1 : 삽입할 데이터
- 매개변수 2 : Option(writeConcern을 설정)writeConcern
- data를 삽입할 때, 안정성을 위한 옵션
- mongoDB는 느슨한 트랜잭션을 사용하는데, 데이터 삽입 시 메모리에 데이터를 삽입하고 작업이 많지 않은 시간에 실제 데이터베이스로 복사를 합니다.
- 비정상적으로 종료가 된다면 MongoDB에서는 데이터가 제대로 삽입되지 않을 수 있습니다.
- 이러한 부분을 제어하기 위한 옵션입니다.
- 데이터 불일치의 경우가 종종 있습니다. 즉 insert 보단 select 작업에 쓰임
- 데이터가 정상적으로 원본에 삽입이 이루어질 때 까지 Client에게 데이터를 읽기 못하도록 하는 옵션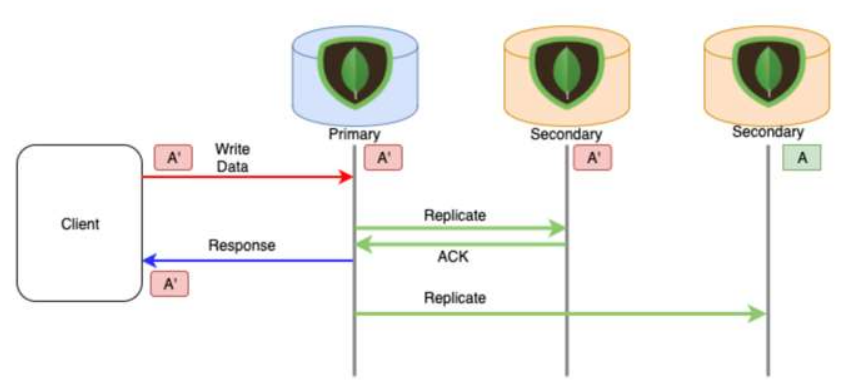
단일 장애점 문제가 있으면 안된다.
scheduler / cron job
여러 데이터 삽입 : insertMany
- insertOne에 비해서 ordered 옵션이 추가됩니다.
- JS의 반복문을 사용할 수 있습니다.
- 굳이 여러 개 넣을 때 insertMany를 안써도 되긴 하네요 그럼
var num=1 for(var i=0; i<3;i++){db.sample.insertOne({name:"user"+i,score:num})}이러면 user0, user1, user2가 입력됩니다.
데이터 조회
- 특징
- 단일 도큐먼트에서만 조회
- Join이 없음
- 여러 개의 테이블 사이의 관계를 만들 때는Linking이나 Embedding을 이용table 1(초기) table2 table3 table4 회원ID(PK) 회원ID(PK) 일련 번호(PK) 첨부파일 번호(PK) 이름(1) 이름(1) 제목(1) 첨부파일(1) 전화번호(1) 전화번호(1) 내용(1) 일련 번호(FK) 비밀번호(1) 비밀번호(1) 첨부파일(N)->분리! 이메일(1) 이메일(1) 회원ID(FK) 제목(N) 내용(N) 첨부파일(N) 정규화를 해보았어요
DB는 저장방법, 사용방법이 다른것이지 작업자체는 비슷합니다. 동일한 기능들이 있습니다. NoSQL과 RDBMS의 차이를 아는 것이 중요하지, 함수를 기억하는 것이 중요한게 아닙니다.
조회 함수 - find()
db.컬렉션이름.find()
- 컬렉션 전체 데이터 조회- 매개변수는 2개
- 매개변수 1 : 쿼리
- 매개변수 2 : 조회할 필드 이름
- return 은 cursor를 리턴함
샘플 데이터 삽입
- 외부에서 만든 json 파일을 이용해서 도커에서 샘플 데이터를 생성하기
- 터미널로 이동
- docker의 container에 파일을 복사하는 명령
-docker cp 파일경로 컨테이너이름:/복사할디렉토리/파일명
- mongodb 컨테이너의 tmp 디렉에 여러 json파일을 복사해보자
Successfully copied 3.07kB to mongodb:/tmp/primer.json
성공하면 이와 같은 메시지를 print 해준다.
- json파일에서 데이터 읽기
- mongoshell 에서 수행 mongoimport -d db이름 -c 컬렉션이름 < 파일경로
- 이렇게 수행한 뒤, db에 들어가서 확인할 수 있다.
-use db이름
-db.primer.find()이렇게 하면 된다.- 이때,
mongoexport -d db이름 -c 컬렉션이름 > 파일경로는 내보내기가 된다.
일치하는 데이터 조회
db.컬렉션이름.find({속성이름:값,속성이름:값...})- 속성이름 여러개 나열하면
AND 조건입니다. - ex) users 컬렉션에서 name이 mino인 데이터 조회
-db.users.find({name:"mino"}) - ex) inventory 컬렉션에서 category가 clothing인 데이터 조회
-db.inventory.find({category:"clothing"})
샘플 데이터 삽입
db.containerBox.insertMany([ {name:'bear', weight:60, categori:'animal'}, {name:'bear', weight:10, categori:'animal'}, {name:'cat', weight:3, categori:'animal'}, {name:'phone', weight:1, categori:'electronic'}])찾는거는 위에 코드처럼 해보자.
db.containerBox.find({name:'bear'})한 곳에 같이 쓰면 AND 연산으로 들어간다고 했다.
db.containerBox.find({name:'bear'}, {category:'animal'})
특정 속성(컬럼)만 추출
db.컬렉션이름.find({조건}, {컬럼이름:true or false,...}) #true를 설정하면 조회가 되고 false는 조회x #1, 0으로 설정 가능함 db.containerBox.find({}, {_id:false, name:1}) #이는 아이디는 안보고 이름만 보겠다는 거에요이번에는 비교 연산자를 사용하자.
# $ep : 같다. # $ne : 같지 않다. # $gt : 크다. # $gte : 크거나 같다. # $lt : 작다. # $lte : 작거나 같다. # $in : 배열의 요소 중 하나 # $nin : 배열의 요소가 아닌사용방법은
{컬럼이름:{연산자:값,연산자:값...},...}이다.db.containerBox.find({name:{$eq:'bear'}})배열의 경우에는 표현식 사용이 가능하다.
1. inventory 컬렉션에서 item 컬럼의 값이 hello인 경우를 조회해보자.
2. inventory 컬렉션에서 tags 컬럼의 값이 blank나 blue인 경우를 조회하자.#1. db.inventory.find({item:{$eq:'hello'}}) db.inventory.find({item:'hello'}) #2. db.inventory.find({tags:{$in:['blank','blue']}}) # :을 잊지 말자!!배열에 정규식을 사용하는 것도 가능하다.
1. 영문 소문자로 시작해서 la로 끝나는 문자열
2. 영문 소문자 b로 시작하지 않는#1. db.inventory.find({tags:{$in:[/^[a-z]la/]}}) #2. db.inventory.find({tags:{$nin:[/^b/]}})논리 결합 연산자가 있어요
$not, $or, $and, $nor : 주어진 조건 중 하나도 만족하지 않는 데이터 조회
- inventory 컬럼에서 qty가 2보다 크지 않은 데이터 조회
- inventory 컬럼에서 qty가 100보다 크거나 10보다 작은 데이터 조회
#1. db.inventory.find({qty:{$not:{$gt:2}}}) #2. or, and는 이렇게 쓴다는 것을 생각하자. db.inventory.find({$or:[{qty:{$gt:100}},{qty:{$lt:10}}]})문자열 조회
$regex : 정규 표현식으로 조회 $text : 문자열 검색db.users.insert({name:'paulo'}) db.users.insert({name:'patric'}) db.users.insert({name:'pedro'}) # r이 포함된 문자열 검색 db.users.find({name:/r/}) # pa로 시작하는 문자열 검색 db.users.find({name:/^pa/}) # ro로 끝나는 문자열 검색($임) db.users.find({name:/ro$/})배열 연산자
- NoSQL들은 객체 안에 배열을 저장할 수 있습니다.
- 객체 안에 존재하는 배열을 이용한 조회를 할 수 있습니다.- $all : 순서와 상관없이 배열 안의 모든 요소가 포함되면 조회
- $elemMatch : 조건과 맞는 배열 속 요소를 선택
- $size : 해당 배열의 크기가 같은 Document 선택
# inventory에서 tags에 red가 포함된 데이터 조회 db.inventory.find({tags:"red"})조건에 or/in/nin 없이 배열을 사용한다면, 순서도 일치해야 한다.
# blank red 순서면 조회가 절대 안된다. db.inventory.find({tags:['red','blank']}) # 이렇게 써야 순서 상관이 없다. db.inventory.find({$or:[{tags:'red'},{tags:'blank'}]})특정 인덱스의 데이터를 조회 - 슬라이스를 이용함
{$slice:인덱스}: 인덱스번째 데이터를 조회함{$slice:[시작위치, 종료위치]}: 시작위치부터 종료위치 데이터까지 조회{$slice:음수}: 뒤에서 음수 개수 만큼 조회db.inventory.find({},{tags:{$slice:1}}) db.inventory.find({},{tags:{$slice:-2}}) db.inventory.find({},{tags:{$slice:[1,3]}})데이터 추가
db.users.insert({name:"matt", scores:[79, 85, 93]})
db.users.insert({name:"lara", scores:[91, 74, 63]})# 이렇게 쓰면 score의 모든 값이 80보다 크고 90보다 작아야함 db.users.find({scores:{$gt:80,$lt:90}}) # 이런 데이터가 한개라도 나왔으면 좋겠어요 #match안에 중괄호는 AND 처리가 됨 db.users.find({scores:{$elemMatch:{$gt:80,$lt:90}}}) # 배열을 all과 함께 기재하면 데이터 순서 상관없이 포함하고 있으면 조회 db.inventory.find({tags:{$all:['red','blank']}}) # 얘는 순서까지 고려해야 한다. 완전 AND db.inventory.find({tags:['red','blank']})
- tags
- 항목에 데이터를 가지고 있지 않으면 조회db.inventory.find({tags:{$size:0}})
- exists
- 연산자에 true나 false를 설정해서 컬럼의 존재 여부 조회 가능
- NoSQL은 하나의 컬렉션에 존재하는 데이터의 모양이 다를 수 있음
- 각 객체가 가지고 있는 컬럼이 다를 수 있습니다.
- 이 연산자는 RDBMS가 가지고 있을 수 없습니다.db.inventory.find({tags:{$exists:1}})
- 데이터 개수 제한
- limit 함수.limit()- offtset 위치변경은 skip 함수(limit과 같이 사용 가능)
- 데이터 1개 조회는 find 대신 findOne 함수
- 정렬은 sort 함수
- 컬럼 이름과 1 또는 -1을 설정
- 1을 설정하면 오름차순이고 -1을 설정하면 내림차순
cursor
- MongoDB는 조회 성능을 높이기 위해서 find함수의 결과로 cursor를 리턴
- cursor는 쿼리 결과를 가리키는 포인터입니다. - RDBMS는 쿼리의 결과로 실제 데이터를 리턴합니다.
- cursor를 이용하는 것보다 비효율적인 경우가 발생할 수 있습니다. - cursor의 메서드로는 데이터의 존재 여부를 리턴하는
hasNext()와, 데이터가 존재하는 경우 다음 데이터를 리턴하는next가 있습니다. - 포인터 리턴과 테이블 리턴
- 나온 결과를 모두 다 사용한다 : RDBMS가 효율적
- 일부만 사용한다 : NoSQL이 효율적(필요하면 하나씩 불러오기)
cursor.hasNext() cursor.next() # hasNext가 True면 next를, 아니면 null을 cursor.hasNext() ? cursor.next():null
- cursor와 유사한 형태가 프로그래밍에서는 iterator(반복자) 또는 enumerator이고, 이를 쉽게 사용할 수 있도록 만든 제어문이 python의 for입니다.
데이터 집계
- 데이터를 가지고 그룹화를 하거나 연산을 수행하는 것
- 구현 방법
- 애플리케이션을 이용해서 집계
- map-reduce (연산 뒤, 결과를 모으는 방식)
- 데이터베이스 파이프라인
여러 속성들입니다. 애플리케이션을 이용해서 집계(초기) map-reduce (연산 뒤 결과를 모으는 방식) 데이터베이스 파이프라인 자유도 높음 높은 편 나쁨 처리속도 나쁨 보통 가장 좋음 램 사용량 매우 많이 사용 높음 낮음 처리 위치 애플리케이션 JS 엔진 MongoDB 내부 중요하니까 잘 알아보자...
- map-reduce

형식
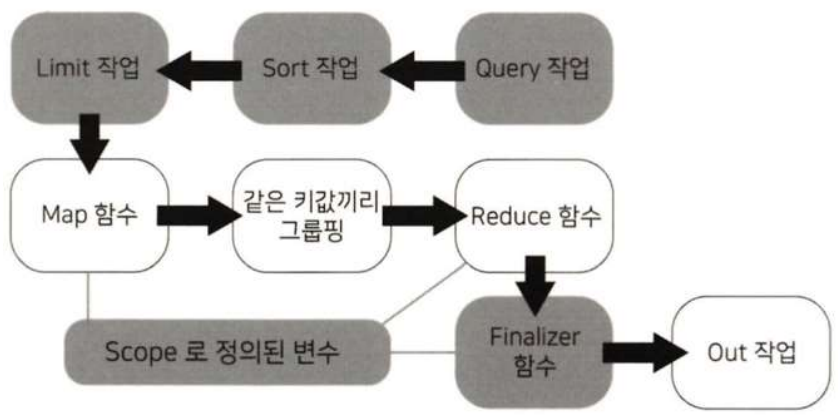
db.collection.mapReduce( <map>, <reduce>, { out: <collection>, query: <document>, sort: <document>, limit: <number>, finalize: <function>, scope: <document>, jsMode: <boolean>, verbose: <boolean> } )
- map: 어떤 정보 들끼리 서로 묶일 수 있을지 정하는 함수
- reduce: 수행할 연산 함수
- out: 출력된 정보를 데이터베이스 내에 기록으로 남기도록 설정
- query: map을 수행하기 전에 필터링할 조건
- sort: map을 수행하기 전에 어떤 데이터를 가지고 정렬할 지 설정
- limit: 선택적. map 과정을 실행전에 함수에 넣을 도큐먼트의 수를 제한
- finalize: reduce 과정이 끝난 뒤, 호출될 함수
- scope: 전역 변수 설정
- jsMode: map 과 reduce 사이의 정보를 자바스크립트로 남길 지 여부
- verbose: 연산 처리에 걸린 시간 출력 여부
동작 과정
- 데이터를 전처리 할 것이 있다면 필터링 하기 전에 다 잘라내 버리자.
- 함수 내에서 변수를 만들면 this로 해줘야 하는 것을 잊지 말자. 파이썬에서도 그랬다.
map 함수
var mapper = function(){ emit(this.rating, this.user_id) #그룹할 항목과 넘겨줄 항목을 작성 }reduce 함수
var reducer = function(key, values){ return values.length} #key에 해당하는 values 배열이 온다.
out
out: { <action>: <collectionName>, db: <dbName>, sharded: <boolean>, nonAtomic: <boolean> }
- action
- replace: 저장할 컬렉션 이름
- merge: 저장할 컬렉션 이름 – 동일한 _id가 있으면 덮어씌움
- reduce: 저장할 컬렉션 이름 – 동일한 _id가 있으면 더해서 적용- db: 저장할 데이터베이스 이름
- shared: true로 설정하면 컬렉션을 새딩하면서 저장
- nonAtomic: action 값이 merge 나 reduce 일 때만 사용되는 옵션으로 MapReduce 의 결과로 저장될 때 해당 데이터베이스는 잠금 상태가 되는데 true로 설정하면 잠기지 않음
Map-Reduce 진행
db.rating.mapReduce(mapper, reducer, {out: {inline: 1}})
결과{ results: [ { _id: 4, value: 2 }, { _id: 3, value: 2 }, { _id: 2, value: 1 }, { _id: 1, value: 1 }, { _id: 5, value: 4 } ], ok: 1 }
✔ Python과 Mongo CRUD 작업
작업 절차
- 필요한 패키지 설치 :
pymongo - 데이터베이스 연결 객체 생성 : 데이터베이스 서버, 포트번호, 계정, 비밀번호
- MongoDB는 로컬에서는 계정과 비밀번호 없이 사용 가능 - DB 연결
- Collection 연결
- Collection에 CRUD 작업 수행
MongoDB는 프로그래밍 언어와 연동할 때, 거의 대부분의 함수가 MongoDB에서의 이름과 동일합니다.
- 삽입, 삭제, 수정의 경우는 수행 결과를 리턴하기 때문에, 수행하고 리턴된 객체를 확인하면 성공 여부를 확인할 수 있습니다.
조회에서 여러 개의 데이터를 리턴하는 경우는 Cursor를 리턴하므로 for를 이용해서 순회를 해서 읽어야 합니다.
수정
- update_one과 update_many
- 첫 번째 매개변수 :
삭제
- delete_one과 delete_many 함수에 조건을 설정
- 지우는 거라$set을 할 필요가 없음
✔ 현재 작업 중인 도커 이미지 저장 및 복원
이미지 저장
docker save -o 이름.tar 이미지이름docker save -o mongo.tar mongo:latest
이미지 복원
docker load -i 이미지파일경로docker load -i mongo.tardocker run관련 명령어 다시 하면 사용 가능합니다.

좋은 글 감사합니다. 자주 올게요 :)