
✔ DB 분류
SQL 사용 여부에 따른 분류
RDBMS
- 테이블 구조를 이용하는 DB
- SQL을 이용해서 질의를 수행
- 강력한 트랜잭션
- Oracle, MySQL(MariaDB), MS SQL Server, HANA DB, Postgre SQL 등
NoSQL
- 스키마를 생성하지 않고 Key-Value 형태로 데이터를 관리
- JS 기반의 함수를 이용해서 질의를 수행
- 느슨한 트랜잭션
- Mongo DB, Cassandra, Hive, Redis 등
저장 위치에 따른 분류
Disk 기반의 DB
- 데이터를 Disk에 저장하고 사용
- RDBMS
In Memory DB
- 데이터를 메모리에 저장해서 빠르게 사용할 수 있도록 해주는 방식
- ⚡빠른 속도
- 대표적으로 Redis
- 각 Cloud Vender에서 별도로 제공
Cloun Vender?
- 클라우드 컴퓨팅의 서비스 솔루션을 만드는 업체&개인
✔ Redis - REmote DIctionary Server
특징
- Key-Value 구조의 저장소
- 반 영구적으로 데이터를 저장할 수 있고, 클러스터 기능을 이용해서 데이터 백업이 가능하다.
- 비용 소모는 대단하다.
사용 사례
- 캐싱
- 세션 관리
- pub/sub(구독과 게시)
- 순위표
🍪Session & Cookie
- HTTP나 HTTPS는 무상태이다.
- 무상태는 Client의 State를 저장하지 않는 것이다.
- HTTP/HTTPS는 Client와 Server간의 지속적인 통신을 할 수 없음
- 이를 위해 나온 개념 : Cookie, Session - Cookie는 Server가 필요한 Client의 정보를 Client에 저장을 하고, Server에게 Request를 할 때, 같이 전송해서 Server가 Client의 State를 알 수 있도록 해주는 것
- Session은 Client의 정보를 Server에 저장해서 Client의 상태를 알 수 있도록 하는 것
- EX) 로그인 정보
- 하지만 너무 많이 저장하면서 부담이 커진다.
단점
- Memory DB는 비용이 많이 소모된다.
- 주 데이터 보다는 보조 데이터 저장에 이용을 해야 한다.
❗ 핵심 키워드 : Memory & Single Thread
- Memory : 빠른 속도
- Memory는 휘발성이다.
- 반 영구적으로 저장하기 위한 방법을 고려함
- RDB 방식 & AOF 방식을 이용해서 백업을 수행 - Single Thread : 일관성 있는 동작
- 한번에 하나만 처리하기에 데드락, 생산자/소비자 등의 문제가 없다.
- Event Loop
RDB 방식(스냅샷)
- 데이터 전체의 스냅샷을 작성하고 이를 디스크에 저장하는 방식
- 스냅샷 작성 이후에 변경된 데이터는 복구가 어려움
- 실시간 거래(은행 거래)를 하는 곳에는 사용하기 매우 어렵다.
AOF 방식(로깅)
- 작업 내역을 저장함
- 복구라는 측면에서 본다면, 효율적
- 로그를 기록하는 방식은 복구 속도가 느리고, 로그 크기가 커지게 된다.
- 은행 통장이 AOF 방식이라고 생각하면 편하다.
- Commit 할 때 마다 기록하기에 데이터 유실이 없음
- 특정 시점으로 돌아가려고 하면, 모든 기록을 다시 실행해야 한다...?
Event Loop
- Client들이 요청을 하면, 그 요청을 Event Queue라는 곳에 저장한다.
- 이후 해당 요청들을 Redis Core Thread가 순차적으로 처리
- Core Thread가 Single Thread 처리 방식으로 요청을 처리함
- Single Thread 기반이라 문맥 교환(Context Switching)이 거의 발생 X
- Dead Lock도 거의 발생 X
- 공유 자원의 점유 여부를 저장할 수 있어서, MSA(Micro Service Architecture)환경에서 유용하게 사용될 수 있음
Multi Thread & MSA
Multi Thread
- Thread 개수
- Processor가 Thread1, Thread2가 존재한다면 각 Thread에 Context를 만들어 작업 내용을 저장해야 한다.
- Thread가 많아진다면, Context Switching의 시간이 늘어난다.
MSA
- Thread가 아닌 Service로 생각하면 편한다.
- 이제 CRUD 하는 것을 다 분리하여 4개의 application의 형태로 만들자고 한다.
- 만약 금융권과 삼성SDS가 금융 데이터를 이용해 서비스를 만든다면?
- 삼성SDS는 조회(R)밖에 할 수 없다. 금융권은 조회 기능만 줘야한다.
- 즉, C, R, U, D를 나누어 만들고 R 기능만 주면 된다. - Data가 있는데, Service1, Service2가 존재하고 같이 접근을 하려면 이를 관리해야 한다.
- Front Controller가 필요하다.- 이는 Multi Thread면 안된다.
- Redis를 쓰면 되겠다.
Dead Lock
- 작업 A, B가 존재한다.
- A와 B는 T1, T2 자원이 필요하다.
- A는 T1, B는 T2 자원을 가지고 있다고 하자.
- 둘은 서로의 자원이 필요해서 무한정으로 기다리게 된다.
- 이게 Dead Lock이다.
생산자와 소비자 문제
- 구독과 게시로 해결함
- 데이터를 생산하는 쪽이 생산자, 그 데이터를 소비하는 쪽이 소비자이다.
생산자가 데이터를 생성하여 버퍼에 저장하고, 소비자가 버퍼에서 데이터를 가져와 소비하는 과정에서 발생할 수 있는 문제를 뜻한다. 대표적으로 공유 자원에 대한 임계구역 문제와 busy waiting 문제가 있다.
busy waiting(=spinning)은 프로세스 동기화 상황에서 프로세스가 자원에 대한 접근 권한을 얻기 위해, 될 때까지 접근 조건을 반복적으로 확인하는 일을 뜻한다. 보통 간단하게는 무한루프를 돌며 계속 if문의 condition을 체크하도록 설계하기 때문에 busy looping이라고도 부른다.
Semaphore
- 멀티 프로그래밍 환경에서 공유된 자원에 대한 접근을 제한하는 방법
- 세마포어 변수 S와 P 연산, V 연산으로 구성되어 있다.
- Signaling mechanism.
- 현재 공유자원에 접근할 수 있는 쓰레드, 프로세스의 수를 나타내는 값을 두어 상호배제를 달성하는 기법
Mutex
- 상호 배제
- 임계구역(Critical Section)을 가진 스레드들의 실행시간(Running Time)이 서로 겹치지 않고 각각 단독으로 실행(상호배제_Mutual Exclution)되도록 하는 기술
- 한 쓰레드, 프로세스에 의해 소유될 수 있는 Key🔑를 기반으로 한 상호배제기법
Single Thread의 단점
- 전체 데이터 조회에는 취약합니다.
- Single Thread 기반이라 게시판 같은 기능을 구현하는데는 취약함
백업과 선출
- Master와 Replica
- Master
- 실제 삽입, 삭제, 수정 작업할 수 있는 노드 - Replica
- Master의 데이터를 백업하는 용도로 사용
- Replica에 변화가 생기더라도 Master에는 영향이 없다. - Master에 문제가 발생한다면, Replica 中 하나를 Master로 선출
- 이 때, 사용되는 것이 Sentinel입니다.
- Sentienl은 다수결의 원칙으로 Master를 선출
- 그래서 Sentinel의 개수는 홀수이다.
✔ Redis 사용하기
설치
- Cloud Service 이용
- Docker에 설치
-docker run --name 컨테이너이름 -d -p 6379:6379 redis - 맨 뒤에 나오는 이름은 이미지 이름이라서 수정을 못한다.
- 버전을 기재하지 않는다면 최신 버전(Lastest)이다.
- 이미지 이름 :
redis:latest
https://redis.io/download 에서 다운로드 받아서 직접 설치
접속
docker run -it --link 컨테이너이름:이미지이름 --rm redis redis-cli -h redis -p 6379docker run -it --link redis:redis --rm redis redis-cli -h redis -p 6379
CRUD
자료형
- Strings
- 문자열- Hash
- key-value- List
- linked list이다.
- deque처럼 동작
- 양쪽에서 삽입 삭제가 가능함- 너무너무 중요한 Set
- 중복되는 데이터를 저장할 수 없으며 순서를 알 수 없는 데이터의 모임- Sorted Set
- 정렬- Stream
- 로그를 저장하기 위한 자료구조- Geospatial indexe
- 위도와 경도 저장을 위해 존재
- 이를 이용해서 거리 계산 가능- Bitmap
- 비트열- Bit field
- 비트열, 이제 비트를 나누어 놓은
Strings
- 문자열
- 저장방식
-set 키 값 - 읽기
-get 키 - 삭제
-del 키 - 전체 키 조회
-keys * - 여러 개의 데이터를 저장하거나 읽을 때
-mset과mget을 이용하자. - 여러 개의 데이터 조회
-scan 페이지번호
- 10개씩 조회
- 첫 번째 결과는 다음 데이터 존재 여부로, 0이면 다음 데이터가 없음
List
- "동일한 자료형"의 데이터를 "순차적"으로 여러 개 모아놓은 구조
- 왼쪽에 삽입
-lpush 키이름 데이터 나열 - 왼쪽에 데이터 조회
-lragne 키이름 시작인덱스 종료인덱스(-1이면 마지막 인덱스)
- 시작 인덱스는 0부터 시작 - 오른쪽에 삽입
-rpush 키이름 데이터 나열 lpop & rpop
- 왼쪽이나 오른쪽에서 하나의 데이터를 가져오고 리스트에서는 삭제- pop 은 지우고 꺼내는 것이다.
- 데이터 개수
-llen 키이름 - 일정 범위의 데이터만 남기고 삭제
-ltream 키이름 시작인덱스 종료인덱스
- 없는 인덱스를 사용하면, 모든 인덱스를 삭제한다. - rpush lpush는 스택과 큐를 구현할 수 있다.
❗ Set
- Redis에서는 매우 중요합니다.
- 중복된 데이터를 저장하지 않는 자료구조
- 데이터를 member라고 부르는데, 일반적으로 member의 존재 여부를 빠르게 확인하고자 할 떄 사용합니다.
- redis는 MSA 환경 같은 곳에서 많이 사용하기 때문에 공유 자원의 사용 여부를 set으로 저장하고 있다가, 누가 사용중인지 빠르게 확인하는 용도로 많이 사용합니다.
- 데이터 삽입
-sadd 키이름 데이터나열 - 모든 데이터 조회
-smember 키이름 - 데이터 존재 여부 확인
-sismember 키이름 데이터 - 데이터 삭제
-srem 키이름 데이터 - 무작위 데이터 삭제 후 가져오는
spop - 삭제는 안하고 가져오는
srandmember가 존재
sadd "printer" "mino" smembers "printer" # printer는 mino가 쓰고 있다.
- 여기에 데이터 많이 입력하는 경우
- 채팅방이다. - set이 조회는 가장 빠르다.
- set을 가지고 만든게 dict이다.
- dict의 단점은 memory 많이 쓴다.
Sorted Set
- score와 value로 구성된 set
- score로 정렬되고 score가 같으면 value로 정렬
- 실시간 순위표를 구현하고자 할 때 유용함
- 데이터 삽입
-zadd 키 score value score value ... - 인덱스를 이용한 조회
-zrange 키 시작인덱스 종료인덱스
-zrange 키 시작인덱스 종료인덱스 rev(역순) withscores(점수도 같이) - 값의 범위를 가지고 조회
-zrangebyscore 키이름 최소값 최대값 withscores limit 옵셋 개수(옵션)
-zrevrangebyscore 키이름 최대값 최소값 이후 옵션들~~: 역순
Hash
- HashTable, Dictionary와 유사한 개념
- key와 value를 같이 저장하는 자료구조
- key는 set으로 구성(중복할 수 없음)
- 저장
-hset&hmset(한개 & 여러개) - 읽기
-hget&hmget(한개 & 여러개) - 모든 데이터 조회
-hgetall - 모든 key와 value 조회
-hkeys,hvals - 삭제
-hdel - value에 한글을 넣고 hget해서 보면 encoding되어있는 것을 확인할 수 있다.
✔ Python과 Redis 연동
준비
- driver 설치 : redis
- 접속 정보
- IP, Port, ID, PWD
- IP : 지금은 localhost(127.0.0.1)
- Port : 6379
- IP, PWD X
- Redis는 외부 접속용이 아님, Redis 데이터는 안쪽
with 구문
- 전통적인 방식의 외부 자원 방식
try: 외부 자원에 연결 execpt : 에러가 발생했을 때 처리 finally: 외부 자원 연결 해제with 구문사용
with 외부 자원에 연결 as 이름: 이름 사용with 안에서 외부 자원에 연결하면, 예외 발생 여부에 상관없이 블럭을 나갈 때 연결을 해제해 줍니다.
Connection Pool
- 데이터베이스 프로그래밍을 할 때, 직접 연결을 생성해서 해제하는 방식을 사용해도 되지만, 미리 연결을 만들어두고 빌려쓰는 방식을 이용할 수 있습니다.
- server에서 db를 사용할 때는, client의 요청이 올 때 마다, DB에 연결하고 요청을 처리하고 결과를 리턴한 후 연결을 해제하는 방식을 사용하면 오버헤드가 너무 큽니다.
- 이런 경우에는 연결을 만들어두고 사용한 후 반납을 하는 형태로 이용합니다.
- 해제를 하는 것은 아니다.
이렇게 미리 만들어둔 DB 연결을 Connection Pool 이라고 합니다.
✔ Web Programming
Web Service 구현 방식
CGI(Common Gateway Interface) 와 Application Server 방식
- CGI
- 클라이언트의 요청을 프로세스를 이용해서 처리하는 방식
- Perl이나 C로 만든 프로그램을 직접 실행시키는 방식 - Application Server
- 클라이언트의 요청을 스레드를 이용해서 처리하는 방식
- Java, Python을 이용해서 클라이언트의 요청을 처리하는 방식
Server Randering과 Client Randering
- Server Randering
- Server가 Client의 출력 내용을 만들어서 HTML로 변환해서 전송하는 방식
- 출력 내용을 서버가 만든다.
- Java의 JSP 출력이나 Template Engine을 사용하는 방식
- 또는 Python의 Flask나 Django를 이용한 방식 - Client Randering
- Server가 Client에게 data를 전송해서 Client가 직접 화면을 만들어가는 방식
- Server는 출력 내용을 만들지 않는다.
- JSON 형태의 데이터만 전송한다.
- Client는 ajax나 websocket 등을 이용해서 데이터를 전송받고 출력물 생성
- 최근에는 이런 방식으로 구현하는 경우가 많다.
요청 방식 - 반드시 알아야 한다.
- 클라이언트가 서버에게 요청을 보낼 때 어떤 방식으로 또는 무엇을 할지를 알려주는 것
get 방식
- 데이터 조회
- 데이터를 전송하고자 할 때, URL에 붙여서 전송을 하는 방식
- URL뒤에
?를 추가하고이름=값&이름=값...형태로 데이터를 전송 - 요청을 처리하는 속도가 빨라지고 자동 재전송 기능이 존재함
- ❗ 데이터의 길이에 제한이 있으며, 💥보안이 취약하다는 단점 존재
- 데이터를 전송할 때 인코딩을 해서 전송해야 한다.
- 최근에는 parameter가 1개인 경우, URL에 붙여서 전송
post 방식
- 데이터를 header에 숨겨서 전송
- 데이터 길이에 제한이 없고, 보안 기능도 존재함(안보임)
- get 방식보다는 느립니다.
- 예전에는 조회를 제외한 모든 요청 처리에 사용했음
- 요새는 삽입에만 사용하라고 한다.
put 방식
- 사용 방법은 post와 동일하다.
- 수정
delete 방식
- 삭제
patch 방식
- 일부분 수정
- 멱등성이 없어서, 되도록이면 수정에는 put 방식을 이용하는 것을 권장
멱등성?
- 몇번을 실행해도 동일한 결과가 나오는 것
기타
- head
- options
- trace
- connect
그렇게 많이 사용은 x
상태 코드
- 클라이언트가 서버에게 요청을 하면, 서버가 처리를 한 후 알려주는 코드
1xx
- 임시적인 응답
- 현재 클라이언트의 요청까지 처리됨
2xx -기억하자
- 정상 응답
3xx - redirection 중
- 정상 처리한 후 다른 요청으로 이동
4xx - Client 오류
- 401 : 권한 없음
- 403 : 권한 처리 이외의 사유 발생
- 404 : 요청을 처리할 수 없음, URL이 잘못됨
5xx - Server 오류
- 500 : 내부 서부 오류
- 503 : 서비스 불가
Web Client 와 Server의 통신 방식
ajax
- 클라이언트에서 비동기적으로 서버에게 요청을 전송하는 방식
- 가장 많이 사용
web socket
- 클라이언트와 서버가 연결형 통신을 수행하는 방식
- 직접 close하지 않는 이상 계속 연결되어 있음
- 채팅 같은 기능때 사용
SSE(Server Sent Evnts- Web Push)
- 서버가 클라이언트의 요청이 없어도 데이터를 전송하는 방식
- 구독 / 게시 와 비슷한 형태이다.
✔ Python Web Framework
Flask 와 Django 의 차이
- 프로젝트 레이아웃이 다름
- Flask는 하나의 프로젝트에 하나의 애플리케이션을 사용
- Django는 하나의 프로젝트에 여러 개의 애플리케이션 생성 가능
RDBMS 사용
- Flask는 내장된 DB 활용 라이브러리가 없으므로, 별도의 라이브러리를 이용해서 데이터베이스를 사용
- Django는 ORM을 내장하고 있으며, 별도의 라이브러리 없이 데이터베이스 사용이 가능함
Flask는 마이크로 프레임워크라서 편하게 확장할 수 있으며, 유연하다.
Django를 권장하는 경우
- Web App이나 API 백엔드의 크기가 큰 경우
- 빠르게 개발해서 배포하고 업데이트 하고자 하는 경우
- CSRF, XSS, SQL Injection, 클릭 재킹 등 기본보안을 쉽게 적용하고자 하는 경우
- Scale up, Scale down(서비스의 개수를 늘리거나 줄이는 것)을 자유자재로 하고자 하는 경우
- SQL에 익숙하지 않은 상태에서 RDBMS를 사용하고자 하는 경우
Flask를 권장하는 경우
- APP이 작은 경우
- 설계가 가능한 경우
- Python에 익숙하지 않은 경우 (애매함)
- NoSQL을 사용하는 경우
Django
개요
- Python의 Web Application Framework
- Open Source : http://djangoproject.com
- 설치 : django
개발 방식
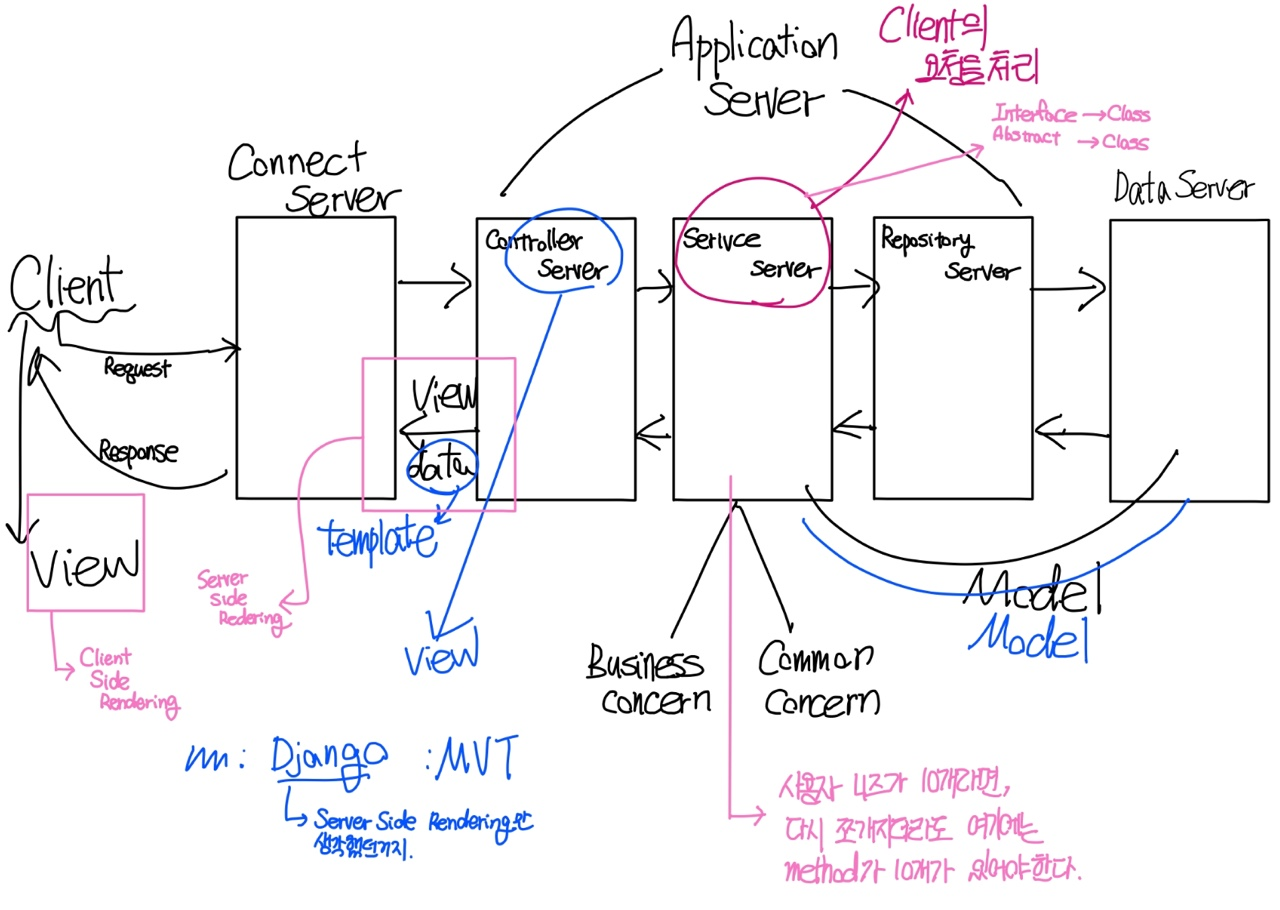
- MVC가 아닙니다.
MVC(Model View Controller) : 일반적인 프로그래밍에서의 개발 방식
- Model
- 데이터와 관련된 부분- Controller
- Model과 View를 제어
- 클라이언트의 요청이 오면, 필요한 Service Logic을 호출하고 그 결과를 받아서 View에게 전송하는 역할- View
- 화면 출력
web 서버
socket 서버 : 코딩을 해야해
- MTV(Model Tamplate View, 이것이 Django의 개발 방식입니다.)
- Model
- 데이터와 관련된 부분 - Template
- 모델이 생성한 데이터를 화면에 출력하기 위한 엔진(문법) - View
- Controller의 역할을 합니다.
- Client의 요청을 처리할 로직을 호출하고 그 결과를 가지고 template을 이용해서 출력하는 역할
ORM - Object Relation Mapping
-
관계형 데이터베이스의 row와 객체 지향 언어의 Instance(Object)를 1:1로 매핑시켜서 SQL없이 관계형 데이터베이스를 사용하는 기술입니다.
-
데이터베이스 종류가 변경되는 경우에는 설정만 변경해서 사용이 가능합니다.
✔ 프로젝트 생성 및 실행
가상 환경 생성
- 가상 환경
- 현재 프로젝트만의 python 실행 환경
- python은 module을 가져와서 자신에게 포함시켜서 실행하는 구조입니다
- python application 사용하는 모듈은 전부 Application에 포함시켜야 Application이 정상적으로 동작합니다.
- python이 설치된 환경에서 python application을 개발해서 배포하면 배포된 곳에 동일한 형태로 python이 설치되어 있어야 합니다.
- 가상 환경을 만들고 그 안에서 모듈을 설치하고 사용하면, 이 환경을 가지고 배포를 하면, 배포된 곳에 파이썬이 설치되어 있을 필요가 없습니다.
- 생성 명령 :
python3 -m venv 가상환경이름 - 가상 환경 활성화 :
soucre 가상환경이름/bin/activate - pycharm이라면 자동 venv 생성으로 할 필요 없다.
django 설치
pip install django
django project 생성
django-admin startproject 프로젝트이름 디렉토리경로
django application 생성
- django는 하나의 project에 여러 application 생성이 가능하다.
- django project 내부의 경로로 이동 한 뒤,
-python manage.py startapp 앱이름
django application 실행
python manage.py runserver
- 기본적으로 현재 컴퓨터의IP:8000 번 포트로 Web Application이 실행됨
- 같은 네트워크 대역이면 다른 컴퓨터에서도 접속이 가능합니다.python manage.py runserver ip주소:포트번호이렇게도 가능
- 이렇게 한다면 해당 ip와 해당 포트번호로 외부에서 접속해야 한다.
- 이 경우는 하나의 컴퓨터에 NIC(Lan Card)가 여러 개 있어서 IP가 여러 개인 경우, 직접 IP 주소와 포트번호를 입력합니다.
python manage.py를 더이상 안치고 싶을 때
file$\rarr$settings$\rarr$Languages&Frameworks$\rarr$Django 에서 settings.py의 경로를 설정해주자. 루트 디렉을 설정하고, settings.py있는 경로 설정
✔ 프로젝트 구조 및 설정
프로젝트 디렉토리의 settings.py
- 프로젝트 설정 파일
DEBUG = True
- 실행모드에 관련된 설정
- True를 설정하면 개발 모드이고, False를 설정하면 운영 모드
- 개발 모드로 설정하면 로그가 전부 출력되지만, 운영 모드로 설정하면 로그는 출력되지 않습니다.
ALLOWED_HOSTS = []
- 배포를 할 때 외부에서 접속할 수 있는 IP를 설정하는 부분
- 내용이 없다면 local에서만 접속이 가능합니다.
- IP를 기재하고 실행할 때,
python manage.py runserver ip:포트번호이러면 외부에서 해당 IP로 접속이 가능함
INSTALLED_APPS
- 앱을 등록하는 부분
- 프로젝트 안에 애플리케이션을 생성한 경우, 여기에 등록을 해주어야 정상적으로 동작하게 됩니다.
INSTALLED_APPS = [ "django.contrib.admin", "django.contrib.auth", "django.contrib.contenttypes", "django.contrib.sessions", "django.contrib.messages", "django.contrib.staticfiles", 'myweb' # 생성한 애플리케이션을 등록해야 합니다. ]
MIDDLEWARE
- django에서 여러가지 기능을 추가하기 위해서 설정
- 기본적으로 보안에 관련된 라이브러리들이 등록되어 있습니다.
- 요청을 처리하기 전이나, 처리한 뒤에 동작하는 SW입니다.
MIDDLEWARE = [ "django.middleware.security.SecurityMiddleware", "django.contrib.sessions.middleware.SessionMiddleware", "django.middleware.common.CommonMiddleware", "django.middleware.csrf.CsrfViewMiddleware", "django.contrib.auth.middleware.AuthenticationMiddleware", "django.contrib.messages.middleware.MessageMiddleware", "django.middleware.clickjacking.XFrameOptionsMiddleware", ]
ROOT_URLCONF
- 요청이 왔을 때, 처리할 모듈을 설정
- 해당 url을 입력하였을 때, 처리할 함수를 연결할 파일
ROOT_URLCONF = "mysite.urls": mysite의 urls파일
TEMPLATES
- Template 파일의 위치를 설정
❗ DATABASES
- database 사용 설정
- 기본은 SQLite3를 사용하도록 설정되어 있습니다.
DATABASES = { "default": { "ENGINE": "django.db.backends.sqlite3", "NAME": BASE_DIR / "db.sqlite3", } }
LANGUAGE_CODE & TIME_ZONE
LANGUAGE_CODE = "ko-kr" #ko-kr 쓰면 한국 TIME_ZONE = "Asia/Seoul"이렇게 설정해주자.
STATIC_URL
- 정적 파일의 위치를 설정함
- 정적파일
- 실행 중에 변하지 않는 파일로 CSS, JS, HTML, 이미지, 사운드 파일 등.. - 동적파일
- 실행 중에 변하는 파일로 template(데이터를 출력하는 파일)이 있다.
Urls.py
- url과 처리할 뷰의 메서드 또는 함수를 연결해주는 파일
- 내용은 이 파일에 전부 작성해도 되고, 여러 파일에 나누어 작성해도 됩니다.
from django.contrib import admin from django.urls import path urlpatterns = [ path("admin/", admin.site.urls), ]admin/ 요청이 오면, admin모듈에 있는 site모듈에 urls 함수가 처리하겠다.
Data Migration
- Django는 ORM을 사용하는데 기본적으로 sqlite3와 연결되어 있습니다.
- 프로젝트 내의 Model에 변화가 생긴 경우, migration을 해주면 db에 자동으로 반영이 됩니다.
make migration migrate물론 python manage.py 생략(tools에서 task열기)
테이블이 없으면 생성도 해줍니다.
관리자 생성
create superuser
- 관리자의 id와 pwd를 입력하고 만들면 끝난다.
- /admin 가서 로그인 확인해보기
views.py
- view 로직을 처리하는 코드를 작성하는 파일
- 일반 함수로 작성할 수 있고, 클래스로 작성할 수 도 있습니다.
- django에서는 클래스로 작성하는 것을 권장합니다.
처리 흐름
- 클라이언트 요청
- django는 settings.py 설정에 따라 project 내의 urls.py 파일을 읽어서 클라이언트의 요청을 처리할 url이 정의되어 있는지 확인합니다.
url이 정의되어 있지 않다면 404 코드
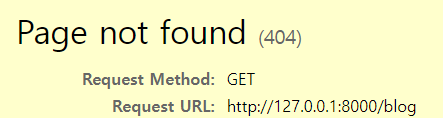
- url과 매핑된 함수나 메서드가 있으면 실행하고 결과를 확인합니다.
- 이때 동작하는 것이 view입니다. - 결과를 가지고 Template을 이용해서 출력하거나 다른 요청으로 redirect합니다.
redirect & forwarding
- redirect
- 작업의 흐름을 중지시키고 새로운 곳으로 이동
- 함수로 생각해보면 return이 없는것처럼 한다. - forwarding
- 작업의 흐름을 중지하지 않고 계속 이어나가기 위한 페이지 이동 - 새로고침 하면, forwarding은 작업을 새로하고, redirect는 결과만 다시 출력
요청 처리 과정 정리
- 요청 urls.py views.py
기본 요청을 했을 때 출력 내용을 설정
- 프로젝트의 urls.py를 수정합시다.
<프로젝트.urls.py>
from myweb(해당 애플리케이션 이름) import views urlpatterns = [ # admin/요청이 오면 admin.site.urls 함수가 처리하겠다고 남김 path("admin/", admin.site.urls), # 기본 요청은 ""이다. 이걸 누가 처리하면 좋을까? path("",views.index) # myweb에 있는 views 모듈의 # index 함수가 처리할거야~ ]이곳에서는 원하는(내가 생각하는) url 요청에 대한 처리 함수를 설정하는 거라고 생각하자.
- 이제 애플리케이션의 views.py 파일에 요청을 처리하는 index함수 생성
<애플리케이션.views.py>
from django.http import HttpResponse def index(request): return HttpResponse("<h1>Hello Django</h1>")태그도 넣어진다
- HttpResponse를 이용하면 HTML을 출력하는 것이 가능합니다.
- 하지만 이를 가지고 복잡하게 만들어서 출력하는 것은 어렵다. - 이번에는 HTML 파일을 출력해보자.
HTML 파일 출력
- 많은 내용을 출력하려면 HTML 파일을 만들고 HTML 파일의 내용을 출력하도록 해주어야 한다.
- 이 경우는
django.shorcuts.render함수를 이용합니다.
- 이 함수의 첫 매개변수는 client로부터 전달된 requset
- 두 번째 매개변수는 출력할 HTML 파일 이름
- 세 번째 매개변수는 HTML 파일에서 출력할 데이터이다.
from django.http import HttpResponse from django.shortcuts import render def index(request): # HTML을 직접 작성해서 출력하기 # return HttpResponse("<h1>Hello Django</h1>") # HTML 파일을 가져오기 return render(request, 'index.html')html은 templates 안에 있어야 하기에 해당 application direc 하위에 templates direc 생성해주자.
- 어 그런데 /templates/index.html이라 안해도 되는건가요?
- settings.py에서 설정되어 있답니다.
