
✔ Oracle
- 오라클은 외부에서 DESC 명령을 사용할 수 없도록 제한을 가합니다.
- DBeaver에서는 직접 확인할 수 있습니다.
계층형 조회
계층형 조회가 무엇을 위해 하는 것인지 잘 알아두자
개요
- Oracle에서 제공하는 기능
self join과 함께 하나의 테이블에 동일한 의미를 갖는 ㅋ러럼이 2개 이상 존재하는 경우에 사용이 가능함
- 인사 테이블에서 사원의 아이디와 관리자의 아이디를 하나의 테이블로 관리하는 경우
- Social Network에서 회원 아이디와 Follow ID를 하나의 테이블로 관리하는 경우
- 구매 테이블이나 장바구니 같은 곳에서 상품 정보를 각각의 컬럼에 나열한 경우
하나의 컬럼에서 연관된 컬럼을 쫓아가면서 데이터를 조회하는 것
MILLER JAMES TOM MINO 일 때(직급이),
MILLER에서 MINO까지 조회하고자 하는 경우 또는 반대인 경우
MILLERMINO, JAMESMINO 는 다르다. 즉 SQL을 다르게 짜야 한다.
기본 형식
WHERE: 조건START WITH: 계층 구조를 지정CONNECT BY: 연결 관계를 설정
연습
- EMP 테이블에는 EMPNO라는 산원 번호와 MGR이라는 관리자 사원 번호 컬럼이 존재합니다.
- MGR이 NULL인 데이터가 가장 높은 레벨의 데이터 입니다.
- EMP 테이블의 레벨이 얼마가 최대인지 확인합니다
SELECT MAX(LEVEL) FROM EMP START WITH MGR IS NULL CONNECT BY PRIOR EMPNO=MGR;CONNECT BY 가 추가되면 LEVEL이라는 컬럼이 자동으로 생성됩니다.
- EMP 테이블에서 JOB이 PRESIDENT 인 데이터부터 아래 방향으로 LEVEL과 ENAME, EMPNO, MGR을 조회해보자.
SELECT ENAME, EMPNO, MGR, CONNECT_BY_ISLEAF FROM EMP START WITH UPPER(JOB)='PRESIDENT' CONNECT BY PRIOR EMPNO=MGR;PRESIDENT 인 행의 empno가 mgr로 사용 되는 것이 있느냐?
- ORDER BY나 CONNECT BY 에 조건을 추가해서 조회하는 것이 가능합니다.
TERMINAL(LEAF NODE - 자식이 없는 노드)
- 여부 판단은 CONNECT_BY_ISLEAF 컬럼으로 조회합니다.
- TERMINAL이 무엇인지 정확하게 알고 있어야 합니다.
-- JONES부터 상관을 조회 SELECT ENAME, EMPNO, MGR, CONNECT_BY_ISLEAF FROM EMP START WITH ENAME='JONES' CONNECT BY PRIOR MGR=EMPNO;해당 시작점부터의 상관 번호를 empno로 가지는 인원이 있느냐?
Pseudo column
- 실제 테이블에는 존재하지 않지만, 인위적으로 추가한 가짜 컬럼
- ORACLE에서는
ROWID,ROWNUM이라는 컬럼을 제공합니다.
ROWID
- 데이터의 실제적인 참조 값
- ORACLE에서는 인스턴스 번호, 파일 번호, 블록 번호, 블록 내의 행 번호로 구성
- 이 값을 이용해서 조회를 하면 가장 빠르게 조회 가능
- SELECT로 조회가 가능합니다.
-- ROWID를 알아보자. SELECT ROWID, ENAME FROM EMP;
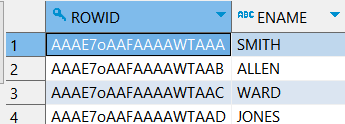
-
이거 써먹기 좋은 곳이 존재합니다.
- 중복 제거에 유용합니다.
- 여러 컬럼을 조회해야 하는데, 그 중 하나의 컬럼의 중복을 제거해서 출력하고자 하는 경우 -
EMP 테이블에서 DEPTNO별로 한 명의 DEPTNO와 ENAME을 조회해보자.
- 어려운 문제야 😢
-- EMP 테이블에서 DEPTNO별로 한 명의 DEPTNO와 ENAME을 조회해보자. -- DISTINCT 는 여러 개의 컬럼이 작성된다면 모든 컬럼의 값이 같아야 제거 SELECT DISTINCT ENAME, DEPTNO FROM EMP; -- GROUPT BY는 그룹화하지 않은 컬럼을 SELECT 절에 출력할 수 없습니다. SELECT DEPTNO, ENAME FROM EMP GROUP BY DEPTNO; --ERROR -- 다른 컬럼을 사용하지 않고, 그룹화 한 후 ROWID가 가장 큰 데이터를 추출 SELECT DEPTNO, ENAME FROM EMP WHERE ROWID IN (SELECT MAX(ROWID) FROM EMP GROUP BY DEPTNO);
ROWNUM
- SELECT 구문의 결과로 만들어진 일련번호
- WHERE절의 조건을 만족해서 RESULTSET에 포함될 때 부여되는 번호
-- 행 번호 조회 SELECT ROWNUM, ENAME FROM EMP;이건 쉽지만, ROWNUM을 이용한 조건을 만들 때는 주의를 해야 한다.
-- 이건 나오지만 SELECT ROWNUM, ENAME FROM EMP WHERE ROWNUM<3; -- 이건 절대 못나온다. SELECT ROWNUM, ENAME FROM EMP WHERE ROWNUM>3;아직 WHERE절을 빠져나오지 못했는데 틀려서 계속 ROWNUM을 1번만 만든다.
행 개수 제한
- ORACLE에서는 OFFSET과 FETCH를 SELECT 구문의 마지막에 추가해서 행의 개수를 제한할 수 있습니다.
- SELECT 구문의 마지막 절에 추가하는데 OFFSET은 시작 위치이고 FETCH는 행의 개수입니다.
- ORACLE 21C 버전에서부터 가능합니다.
-- 급여가 많은 순으로 조회해보자. SELECT * FROM EMP ORDER BY SAL DESC; -- 5개만 가져오고 싶다. SELECT * FROM EMP ORDER BY SAL DESC OFFSET 0 ROWS FETCH NEXT 5 NEXT ONLY;
SYNONYM - 별명, 동의어
- 기존 객체에 별명을 붙이는 것
- 응용 프로그램과 데이터베이스를 연결할 때 이용하면 유지보수가 편리해짐
- 응용 프로그램에게는 SYNONYM을 사용하도록 하고, DB 내에서 이름 변경 시, SYNONYM만 변경해주면 응용 프로그램을 변경할 필요가 없어지기 때문입니다.
-- 생성 CREATE SYNONYM 이름 FOR 기본객체이름; -- 삭제 DROP SYNONYM 이름;
-- EMP 테이블에 사원이라는 SYNONYM을 생성 CREATE SYNONYM 사원 FOR EMP; SELECT * FROM 사원; SELECT * FROM EMP;별명이기에 새로운 이름 부여가 아니기 때문에 기존 이름도 사용 가능
SEQUENCE
- 일련 번호를 생성해주는 객체
- MySQL은 AUTO_INCREMENT를 하나의 테이블에서 하나만 사용해야 하고, 반드시 PRIMARY KEY나 UNIQUE 제약조건을 설정해야만 합니다.
- 하지만 ORACLE의 SEQUENCE는 이런 제약이 없습니다.
생성
CREATE SEQUENCE 이름 [START WITH 초기값] [INCREMENT BY 증감값] [MAXVALUE(최대값)|NOMAXVALUE] [MINVALUE(최소값)] [CYCLE|NOCYCLE] [CACHE 개수|NOCACHE];
사용
이름.CURRVAL: 현재 값, NEXTVAL을 한 번은 호출해야 사용 가능이름.NEXTVAL: 다음 값
삭제
DROP SEQUENCE 이름;
-- SEQUENCE CREATE SEQUENCE DEPT_SEQ START WITH 1000 INCREMENT BY 10; -- 값 확인하기 SELECT DEPT_SEQ.NEXVAL FROM DUAL; -- 오라클은 DUAL이라는 가짜 테이블을 써줘야함 -- SEQUENCE를 이용한 데이터 삽입 INSERT INTO DEPT(DEPTNO, DNAME, LOC) VALUES(DEPT_SEQ.NEXTVAL, '바밤바','서울'); -- 들어갔는지 확인 SELECT * FROM DEPT;
분석 및 통계 함수
ROLLUP
- 그룹 별로 집계를 하는데, 중간 집계를 조회할 때 사용합니다.
- 대신, ROLLUP에 설정하는 컬럼은 숫자 데이터는 안됩니다.
- 숫자 컬럼의 경우는
DECODE함수로 감싸서 사용합니다. - GROUP BY 보다 효용가치가 높다.
-- EMP 테이블에서 JOB 별로 SAL의 평균을 조회해보자. -- 기존 GROUP BY SELECT JOB, AVG(SAL) FROM EMP GROUP BY JOB; -- 이번엔 ROLLUP , NULL로 나온다 마지막은 SELECT JOB, AVG(SAL) 급여평균 FROM EMP GROUP BY ROLLUP(JOB); -- ORACLE은 IFNULL이 아니다. NVL(A,DEFAULT) SELECT NVL(JOB, '전체') JOB , AVG(SAL) 급여평균 FROM EMP GROUP BY ROLLUP(JOB);
-- DEPTNO별로 SAL의 합계를 조회해보자. SELECT NVL(DEPTNO, '전체') DEPTNO , SUM(SAL) 급여합계 FROM EMP GROUP BY ROLLUP(DEPTNO);SQL Error [1722][42000]: ORA-01722: invalid number
숫자 컬럼이라 그냥은 안된다.
-- DECODE 값이 NULL이면 전체 그렇지 않으면 DEPTNO를 변환해서 조회 SELECT DECODE(DEPTNO,NULL, '전체', DEPTNO) DEPTNO , SUM(SAL) 급여합계 FROM EMP GROUP BY ROLLUP(DEPTNO);
-- 묶어서 처리하기도 좋다. - 전체 합계도 나옴 SELECT DEPTNO, JOB, SUM(SAL) 급여합계 FROM EMP GROUP BY ROLLUP(DEPTNO, JOB) ORDER BY DEPTNO; -- -- 이렇게도 가능하다, 전체 합계가 빠짐 SELECT DEPTNO, JOB, SUM(SAL) 급여합계 FROM EMP GROUP BY DEPTNO, ROLLUP(JOB) ORDER BY DEPTNO;
CUBE
- 가능한 모든 중간 집계를 조회
-- CUBE를 써보자. SELECT DEPTNO, JOB, SUM(SAL) 급여합계 FROM EMP GROUP BY CUBE(DEPTNO, JOB) ORDER BY DEPTNO;이렇게 작성을 했더니, 직업별로도 집계를 해줬다.
CUBE가 ROLLUP보다 많이 사용된다.
GROUPING
- 중간 집계이면 1을 그렇지 않으면 0을 리턴해주는 함수
- 조금 어려운 함수, 활용이 쉽지 않다.
-- GROUPING : 중간 집계면 1 아니면 0 SELECT DEPTNO, GROUPING(DEPTNO), JOB, GROUPING(JOB), SUM(SAL) 급여합계 FROM EMP GROUP BY ROLLUP(DEPTNO,JOB); -- -- GROUPING : 중간 집계면 1 아니면 0, 활용해보기 -- 타이틀을 만들려고 하는 거에요 주로 SELECT DEPTNO, DECODE(GROUPING(DEPTNO),1,'전체합계') AS ALLTOT, JOB, DECODE(GROUPING(JOB),1,'부서합계') AS DEPTTOT, SUM(SAL) 급여합계 FROM EMP GROUP BY CUBE(DEPTNO,JOB) ORDER BY DEPTNO;
GROUPING SETS
- ROLLUP이나 CUBE는 여러 개의 컬럼으로 그룹화를 하면 여러 컬럼을 합쳐서 그룹화 하지만, GROUPING SETS은 여러 개의 컬럼을 사용하면
각 컬럼 별 집계를 수행합니다.
-- GROUPING SET : 각 컬럼 별 집계를 보자. -- ROLLUP과 비교해보기 SELECT DEPTNO, JOB, SUM(SAL) 급여합계 FROM EMP GROUP BY ROLLUP(DEPTNO, JOB); -- 이렇게 ROLLUP하면 부서 번호별로만 한다. -- GROUPING SET SELECT DEPTNO, JOB, SUM(SAL) 급여합계 FROM EMP GROUP BY GROUPING SETS(DEPTNO, JOB);GROUPING SETS는 넣어놓은 컬럼 별로 집계를 해서 보여줍니다.
ROLLUP은 앞에 넣은 컬럼에 맞춰 그룹화 해서 집계를 전체적으로 보여줌
WINDOW FUNCTION
- 행과 행 간의 관계를 정의하기 위해 제공되는 함수
- 순위, 합계, 평균 또는 누적 합이나 비율 등을 위한 함수
기본 형식
SELECT WINDOW_FUNCTION(매개변수) OVER(PARTITION BY 그룹화할 컬럼 이름 ORDER BY WINDOWING FROM 테이블 이름;
- WINDOW_FUNCTION : 윈도우 함수를 설정하면 되는데 ,순위, 집계 및 행 순서 등이 들어갑니다.
- 매개변수는 함수에 따라 다르게 적용
- PARTITION BY 는 생략하면 데이터 전체
- WINDOWING : 정렬 기준
실습
- EMP 테이블에서 전체 SAL에서 자신의 SAL의 비율을 알고 싶다.
-- EMP 테이블에서 전체 SAL에서 자신의 SAL의 비율을 알고 싶다. SELECT ENAME, SAL FROM EMP; -- 왜 오류야? SELECT ENAME, SAL, SAL*100/SUM(SAL) OVER() FROM EMP; -- SUM(SAL)은 1개 , SAL 은 여러개 -- SELECT에 쓰여진 애들은 CARDINALITY가 같아야 한다.SUM(SAL)을 전부 복사해서 14개의 행으로 만들어서 조회하기
- db에서 "" 는 별명, ''는 문자열이다. 원래는
범위를 설정하기 위해서 시작 위치와 종료 위치를 설정하는 것이 가능합니다.
ROWS BETWEEN 시작위치 AND 종료위치RANGE BETWEEN 시작위치 AND 종료위치- 위치 지정 방법
START UNBOUNDED PRECEDING -- 처음 부터 CURRENT ROW -- 현재 행 부터 N PRECENDING -- N 번째 행 앞부터END UNBOUNDED FOLLOWING -- 마지막까지 CURRENT ROW -- 현재 행 까지 N FOLLLOWING -- N 번째 행까지
- EMP 테이블에서 EMPNO, ENAME, SAL, 현재행까지의 SAL 합계를 조회
-- EMP 테이블에서 EMPNO, ENAME, SAL, 현재행까지의 SAL 합계를 조회 -- OVER 는 14개 다 맞추는거임 SELECT EMPNO, ENAME, SAL, SUM(SAL) OVER(ORDER BY SAL ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS "현재 까지 누적 SAL 값" FROM EMP; -- -- EMP 테이블에서 EMPNO, ENAME, SAL, 현재행부터 마지막 행까지의 SAL 합계를 조회 -- OVER 는 14개 다 맞추는거임 SELECT EMPNO, ENAME, SAL, SUM(SAL) OVER(ORDER BY SAL ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS "현재 까지 누적 SAL 값" FROM EMP;SQLD에서는 별칭 없이 쭉 쓰면 된다. 이거 외워서 써야 한다.
OVER 안에 PARTITION BY 컬럼이름을 기재하면 그룹화해서 집계를 수행한다.
부서별 급여 평균을 구해보자.
-- 부서별 급여 평균을 구해보자. SELECT EMPNO, ENAME, SAL, ROUND(AVG(SAL) OVER(PARTITION BY DEPTNO),2) "부서별 급여 평균" FROM EMP;
순위를 구해주는 함수
ROW_NUMBER()
- 동일한 순위가 존재하지 않는 일련번호 형태의 순위DENSE_RANK()
- 동일한 순위는 동일한 순위로 출력하고 다음 순위를 건너뛰지 않고 연속해서 순위를 부여RANK()
- 동일한 순위는 동일한 순위로 출력하고 다음 순위를 건너뛰고 부여
-- 부서별 급여 순위 SELECT DEPTNO,ENAME, SAL, RANK() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) "RANK급여 순위", DENSE_RANK() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) "DENSE급여 순위", ROW_NUMBER () OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) " RM급여 순위" FROM EMP;
행 순서 관련 함수
- FIRST_VALUE(컬럼 이름) : 그룹의 첫번째 행
- LAST_VALUE(컬럼 이름) : 그룹의 마지막 행
- LAG(컬럼이름) : 이전 행
- LEAD(컬럼이름, 인덱스) : 인덱스 만큼 건너뛴 행
비율 관련 함수
- CUME_DIST() : 누적 분포 상의 비율, 0~1 사이의 값
- PERCENT_RANK()
- 시작 위치를 0으로 종료 위치를 1로 했을 때의 누적 비율 - NTILE(분할할 개수) : 분할 한 후 위치를 조회
- RATIO_TO_REPORT(): 합계에 대한 컬럼 값의 백분율
PIVOT
SELECT 필드목록 FROM 테이블 PIVOT(집계함수 FOR 컬럼이름 IN(컬럼 값 나열) ); 별명
-- PIVOT SELECT JOB, DEPTNO, SAL FROM EMP PIVOT(MAX(SAL) FOR DEPTNO IN(10,20,30);
MERN중 M : mongoDB를 알아보자.
CQRS 중요한데...
✔ Mongo DB
왜써?
-> js로 모든것을 다해보자구
Docker에 Mongo DB 설치
Docker
l 이미지 다운로드: docker pull mongo
l 컨테이너 실행: docker run --name 컨테이너이름 -v ~/data:/data/db -d -
p 27017:27017 mongo
u -v ~/data:/data/db는 호스트(컨테이너를 구동하는 로컬 컴퓨터)의 ~/data
디렉터리와 컨테이너의 /data/db 디렉터리를 마운트시키는 옵션으로 이처럼
볼륨을 설정하지 않으면 컨테이너를 삭제할 때 컨테이너에 저장되어 있는
데이터도 삭제되기 때문에 복구할 수 없음
l bash shell 접속: docker exec -it mongodb-container bash
Mongo DB JSON Document - Binary JSON
- Mongo DB의 데이터 표현법
- JS 객체 표현 방식으로 표현
장점
- 경량
- 각 필드는 데이터 타입과 길이가 먼저 저장되기 때문에 복잡한 처리과정 없이 빠르게 저장이 가능하다.
- 기본 데이터 타입으로 C언어의
primitive 타입
(데이터 참조가 아닌 실제 값)을 사용하기에, 빠르게 인코딩과 디코딩이 가능함
다양한 자료형을 지원
- ObjectID
- 데이터를 저장할 때 데이터를 구별하기 위해서 Mongo DBㅏ 삽입하는 데이터의 자료형
- Oracle에서의 ROWID와 비슷하다.
데이터 표현
-
객체
-{"key":value,"key":value,...}
- key는 중복될 수 없다.
- key의 순서도 기억한다.
-{"name":"mino","job":"student"}와{"job":"student","name":"mino"}는 다른 데이터 입니다.
- key에 공백을 포함할 수 없습니다.
-.과$도 key에 포함할 수 없습니다.
- key는_로 시작하지 않습니다.(관례, 예약어가_로 시작하기 때문)
- key는 대소문자 구분합니다. -
배열
-[데이터 나열] -
Mongo DB에서는 하나의 데이터를 Document라고 합니다.
-
Mongo DB는 데이터의 모임을 collection으로 관리하는데, 스키마가 없기 때문에 하나의 collection에 어떠한 종류의 데이터라도 삽입이 가능합니다.
작업 단위
- database > collection > document 순서입니다.
데이터베이스 작업
- 데이터베이스 목록 확인
-show dbs - 데이터베이스 설정
-use db이름
- Mongo DB는 없는 이름을 사용하면 생성 - 현재 사용중인 데이터베이스 확인
-db - 현재 사용 중인 데이터베이스 삭제
-db.dropDatabase()
데이터베이스 접속 방법
Mongo DB는 기본적으로 계정과 비밀번호가 없습니다.
- Mongo DB가 설치된 셸에 접속해서 사용
- 컨테이너 셸에 접속 하는 것이라서 명령어가 중요합니다.
- 터미널을 열고
- bash shell에 접속하기
- docker exec -it 컨테이너이름 bash
- 프롬프트가 #으로 끝나는 것을 확인하고 bin 디렉토리로 이동
-cd bin
- mongo shell 실행mongosh
- 이걸로 작업 가능함
- 접속 프로그램 이용
- https://robomongo.org/download
- new connection -> manual-> connection 이름 아무거나-> local : port 27017- 명령어는 intellishell에서
명령어 실습
- db확인
-show dbs - mino라는 db가 없으면 생성하고 연결
-use mino
- `switched to db mino라고 나온다. - 현재 사용중인 db 확인
-db
- 이때, 새로 생성된 mino가 있는데도show dbs하면 mino는 안보인다.
- 데이터가 없어서 크기 할당이 안되어서 없는 것 처럼 보인다.
- 데이터 넣으면 된다. - 데이터 삽입 후 확인
-db.mycollection.insertOne({Name:1})
-show dbs이러면 mino db가 보일거야.
collection
- 데이터의 집합(Document의 집합)
- Mongo DB에서는 스키마를 만들지 않고 JOIN을 하지 않는 것을 기본으로 하기 때문에, 하나의 collection에 모든 종류의 데이터를 삽입하는 것이 가능합니다.
- 실무에서는 많은 양의 데이터를 collection에 저장하면 실행 속도가 느려지기 때문에, 데이터를 분할 저장하고 하나의 collection에 여러 종류의 데이터가 있으면 어떤 종류의 데이터를 저장하는 collection인지 알기 어렵기 때문에 대부분 동일한 종류의 데이터를 하나의 collection에 삽입 합니다.
- RDB에서는 table을 먼저 생성 - 스키마를 생성
- 회원 - 아이디, 이름, 비밀번호를 저장
- 회원 테이블에는 위의 정보를 갖는 인스턴스만 저장이 가능 - NoSQL에서는 테이블을 생성하지 않음 - 스키마를 생성하지 않는다
- 회원 -[]
-[{id:"!",name:"Lee",pw:"!234"},{boardnum:1,title:"제목",content:"내용"}]이렇게 막 넣기는 가능하지만 아무도 이렇게 안한다.
- 얘는 수정을 해도 괜찮다. RDB는 수정하려면 테이블을 아마 버리고 다시 만들었을 것이다.
Collection 작업
collection 생성
db.createCollection("이름")
collection 이름을 조회
db.getCollectionNames()show collections
collection 제거
db.이름.drop()
이름 변경
db.이름.renameCollection(새로운 이름)
Capped Collection
- Collection의 용량을 정해두고, 용량 이상의 데이터가 삽입이 된다면 가장 오래된 데이터를 삭제하면서 삽입하는 Collection
- 대표적 예시 : CCTV, 블랙박스
-db.createCollection(이름,{capped:true, size:크기})
// collection 생성 db.createCollection('cappedCollection',{capped:true,size:10000}) // 데이터 1개 삽입 db.cappedCollection.insertOne({x:1}) // 데이터 확인 db.cappedCollection.find() // 많은 양의 데이터 삽입 for(i=0;i<1000;i++){ db.cappedCollection.insertOne({x:i}) } // 데이터 확인, 1000개를 넣었는데 어림도 없다. db.cappedCollection.find()
- 데이터를 1000개를 삽입하면 647번부터 데이터가 존재합니다.
- 용량이 초과되어서 이전에 저장된 데이터를 삭제하기 때문입니다.
- 한정된 공간을 사용하는 시스템(IoT와 Embedded System)에서는 새로운 데이터를 저장하기 위해서 과거의 데이터를 지우면서 저장합니다.
CRUD (Create, Read, Update, Delete)
- 삽입 , 읽기, 수정, 삭제
Document 생성 (Create)
특징
- 하나의 Document는 하나의 Collection에 삽입해야 합니다.
- 데이터를 삽입할 때,
_id라는 속성에 값을 설정하지 않으면, Mongo DB가_id라는 속성을 만들어서 값을 대입합니다.
- 이 값이 기본 key값입니다.
삽입 함수
db.컬렉션이름.insert(객체)
- 동일한_id를 사용하면 에러를 발생db.컬렉션이름.save(객체)
- 동일한_id를 사용하면 수정합니다.db.컬렉션이름.insertOne(객체)db.컬렉션이름.insertMany(객체)- 초창기에는 insert함수를 이용해서 1개 또는 여러 개의 데이터를 삽입했는데, 최근에 insert는 deprecated
- insertOne과 insertMany를 사용하는 것을 권장합니다. - 최근 DB들은 여러 개의 데이터를 삽입할 때, 중간에 오류가 발생하더라고 다음 작업을 계속 진행할 수 있는 옵션을 제공합니다.

좋은 글 감사합니다!