Motivation
- Collaborative Filtering (CF) based recommendation: User-Item interaction matrix를 학습 추가적인 user or item의 attribute를 고려하거나 / higher-order connectivity까지 고려하는 방법들이 연구되고 있음 (GCN-based recommender models)
- Limitations
- U-I interaction 너무 sparse한데 대부분의 기존 연구는 supervised learning paradigm을 택함
- 특히 GCN-based에선 neighbor aggregate & update과정에서 high degree node에 편향되므로 long-tail의 unpopular item의 영향력이 과하게 감소됨
- Recommendation 데이터 자체가 noise가 많기도 한데, 특히 GCN-based에선 relation 자체가 feature 학습에 큰 영향을 끼침으로써 이 noise에 영향을 많이 받게 됨 - SSL idea 도입하여 data sparsity 및 다른 limitations 해결
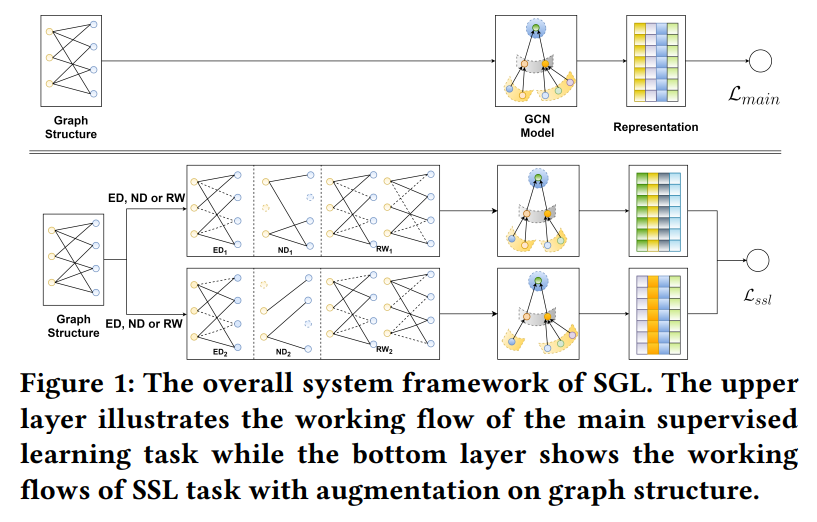
- GCN-based recommender model에 들어가는 input의 형태는 U-I graph, 직관적으로 생각하면, graph structure에 augmentation을 줘서(Node dropout, Edge dropout, Random walk)서로 다른 view를 만들어 내고, 이를 기반으로 contrastive learning을 적용할 수 있음 Pretext task: Discriminating the representation of a node itself (한 instance의 서로 다른 augmented된 view, 즉 graph structure을 사용하여 만들어진 node embedding끼리의 거리는 가깝게 / 다른 instance의 views를 사용하여 만들어진 node embedding끼리의 거리는 멀게 만듦)
- Dropout 2번 limitation에서 high degree node의 영향력을 줄여줌
- Augmentations itself 3번 limitation에서 언급한 다양한 noise에 대한 모델의 robustness를 향상시킬 수 있음
Method
Summary
- Data Augmentation: Edge dropout, Node dropout, Random walk
- Contrast Type: Node-Node
- Contrastive Objective: InfoNCE
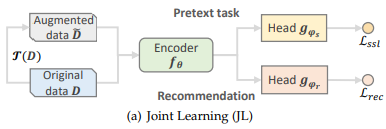
- Training Scheme: Joint learning
- Supervised loss (Recommendation): Pairwise Bayesian Personalized Ranking (BPR) loss
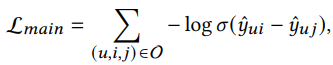 'Enforces the prediction of an observed interaction to be scored higher than its unobserved counterparts'
'Enforces the prediction of an observed interaction to be scored higher than its unobserved counterparts' - Self-supervised loss (Pretext task): InfoNCE loss & 추가적인 학습 파라미터가 없음!
-
Augmentation Types
- Node Dropout(ND): (-) nodes, (-) their connected edges (Masking으로 구현, layer에 무관하게 고정된 mask 사용)
- Edge dropout(ED): (-) edges (Masking으로 구현, layer에 무관하게 고정된 mask 사용)
- Random Walk(RW): ED의 확장, layer마다 서로 다른 mask를 쓴다는 점만이 다름
-
Contrastive Learning
-
Node-Node간의 contrast를 위해 node의 서로 다른 views를 만듦
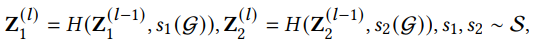
, : Node의 view (윗첨자: layer)
, : Two stochastic selections independently applied on graph G
H: Neighborhood aggregation function -
InfoNCE Loss 도입
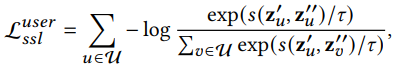
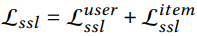
cf. 여기서 negative sampling을 진행하지 않고 그래프에 존재하는 모든 노드를 negative sample node로 사용했음에 주의하기!
s: Cosine similarity
: Temperature -
- Joint Learning (Joint Training)
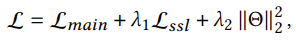 하나의 objective으로 supervised task와 self-supervised pretext task를 동시에 학습시킴
하나의 objective으로 supervised task와 self-supervised pretext task를 동시에 학습시킴
Experiments
-
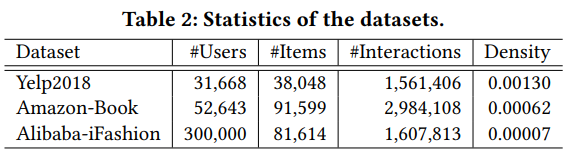
Benchmark Datasets: Yelp2018, Amazon-Book, Alibaba-iFashion
-
Evaluation Metrics: Recall@K, NDCG@K (K=20), all-ranking protocol
-
Implementation Details: LightGCN 기반으로 세가지 variants, SGL-ND, SGL-ED, SGL-RW를 구현함
-
Analysis
- 비교적 denser dataset (Yelp2018): SGL-ED
- 비교적 sparser dataset (Amazon-Book, Alibaba-iFashion): SGL-RW , 워낙 interaction이 sparse한데, RW에서는 앞 layer에서 drop된 connection도 뒷 layer에서 복구할 가능성이 있기 때문임
- SGL-ND는 다른 두 variants보다 좀 더 unstable, 노드 자체까지 drop하는거라 high degree node를 drop할때 드라마틱한 변동이 있을 수 있기 때문
- InfoNCE loss를 도입하여 기존에 둘 사이의 차이만 학습하던 supervised BPR loss에 비해 모델의 perception field를 증가시키는 효과를 줌
- Temperature 를 너무 크게 하면 hard negative mining이 제대로 되지 않아서 별로고, 반대로 너무 작게 하면 몇개의 찐 hard negative의 contribution에 온통 치중되기 때문에 InfoNCE loss에서 다양한 negative sample을 사용하는 이점이 없어짐
Pros(Contributions) and Cons(Possible Future Works)
Pros
- SSL InfoNCE loss에서 negative sampling을 안했었지? 사실, SSL loss를 접목시킬 때 (softmax temperature)를 도입하고 이를 조절함으로써 여러 negative sample간 gradient에 기여하는 contribution을 다르게 할 수 있다는 이점이 있다는 것을 수식적으로 증명함. 즉, 한마디로 말하자면, 를 감소시킬수록 negative sample 중에 positive node와 유사성이 높은 hard 케이스 노드들의 영향력이 커짐
'Hard negative nodes offer much larger gradients to guide the optimization, thus making node representations more discriminative and accelerating the training process' & 'Hence, properly setting enables SGL to automatically perform hard negative mining'
